이번에 리뷰할 것은 오차역 전파(BackPropagation)이다.
딥러닝에서 중요한 개념이며 모르면 딥러닝의 전반 과정을 이해할 수 없다고 생각한다.
왜 중요한지를 알기 위해서 언제 쓰이는지를 알아야한다.
오차역전파는 학습 과정에서 사용한다. 딥러닝도 학습이라는 뜻인데,
뭘 학습하는가? 물론 모델마다 아주 약간은 다르겠지만 가중치를 학습하는 것이다.
모든 모델은 가중치를 학습한다. 가중치를 다시 한번 정리해보자면,
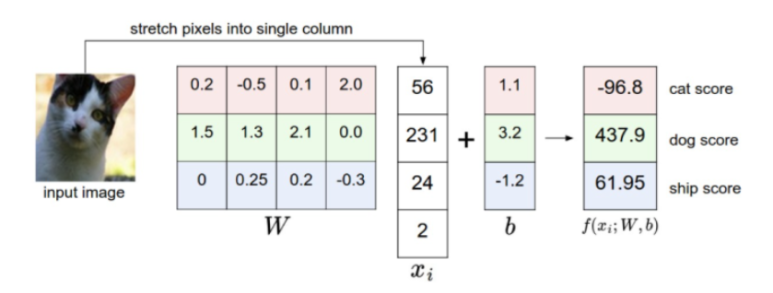
위 처럼 하나의 이미지값이 고양이일 값, 강아지일 값, 배일 값 각각을 계산하기 위해서 주어지는 영향력이다.
정말 잘만들어진 가중치는 고양이 이미지에 대해서 고양이 점수를 압도적으로 높게 계산하며 나머지 점수는 낮게 부여할 것이다. 우리는 학습을 통해 이런 좋은 가중치를 구해내고 싶다.
그럼 어떻게 구해낼 것인가? 이게 관건인데, 우리는 loss 값(loss fuction 참조)이 낮은게 좋은 모델이라는 것을 안다. 그래서 loss fuction를 최소화하는 가중치를 점차 찾아나가면 된다.
무슨 말이냐, 우리는 이 복잡한 딥러닝을 아주 간단하게
f(w1,x1,w2,x2) = loss
로 표현해볼 수 있다. 이 모델은 가중치 2개 x input이 2개이다.
이때 dL(loss의 약자 이하 L로 씀 )/dw1을 구하면 된다.
w1이 h만큼 변했을 때 loss가 얼마나 변하냐? 를 구하면 되는 것이다.
근데 우리가 쓸 모델들은 파라미터가 적게는 수십만 많게는 억단위인데
계산하기란 쉽지않다. 근데 이걸 해내게 하는것이 back propagation이다.
아래 그림을 보자
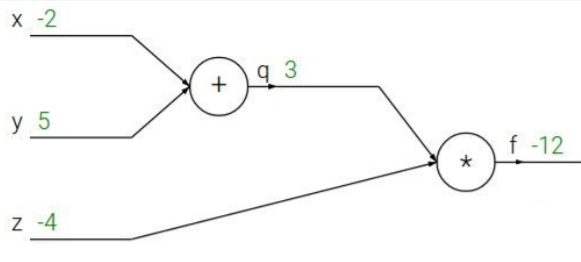
f = z(x+y) 라는 함수이다. 이때 x,y,z가 f값에 가지는 변화량을 궁금하다면 우리는 어떻게 해야할까?
우리가 쉽게 구할 수 있는건 dq/dx , dq/dy, df/dz, df/dq 이다.
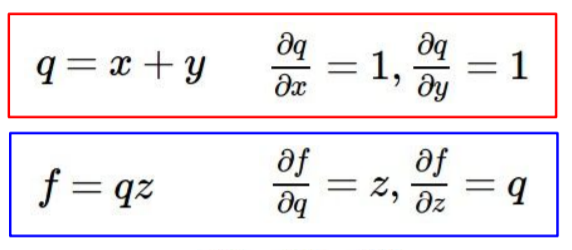
그런데 소위 chain rule에 의해서
df/dx = df/dq * dq/dx가 되고 df/dx를 구할 수 있다.
위는 너무 간단한 식이라 이런게 왜 필요하나 싶을 텐데 아래의 그림을 보자.
아래는 2개의 가중치 2개의 input data, 하나의 bias를 가진 노드에 시그모이드 함수를 취하는 함수이다.
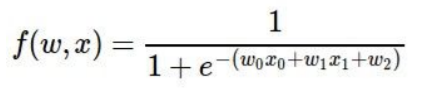
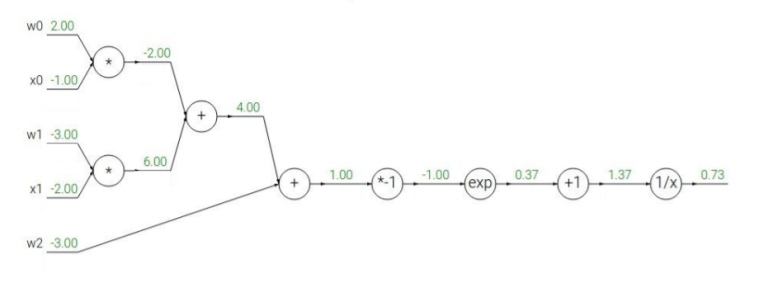
이렇게 복잡할 때 우리는 chain rule을 활용하여야지만 w0,w1,w2의 gradient를 각각 구할 수 있다.
오차역 전파는 이름부터 그렇듯 가장 끝 노드에서 시작한다.
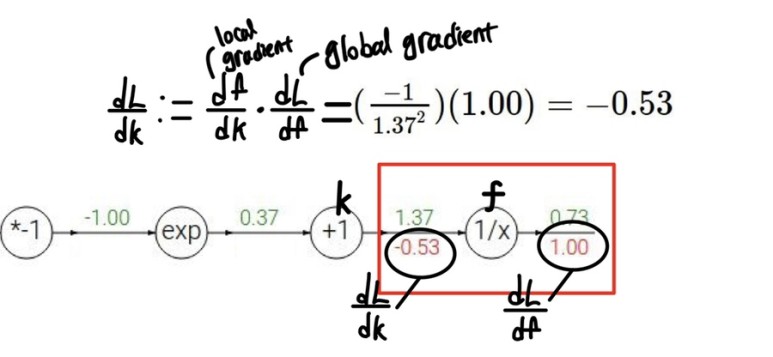
마지막 두개의 노드를 각각 k와 f라고 이름지어보자. 위에 초록색으로 표시된 값은 각 노드를 지난 후에 값이다.
그리고 아래 붉은색이 각 k와 f의 L(우리는 결국 loss fuction에 대한 변화량을 구하는 것이다 그래서 L로 쓴다)에 대한 gradient값이다.
dL/df 은 마지막 노드이기에 무조건1이다. 또한 우리는 k의 식을 알기 때문에 df/dk를 구할 수 있다.
그리고 dL/dk를 구해야하는데
이때 chain rule에 의해
dL/dk = df/dk(local gradient) dLdf(global gradient)로 표현된다.
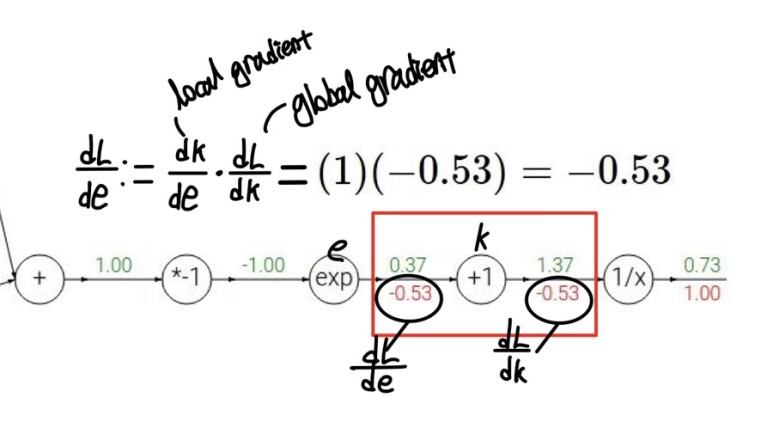
이번엔 exp함수를 e라고 했을 때 앞서와 똑같이 dL/de을 구하는 과정이다 이런과정을 반복했을 때,
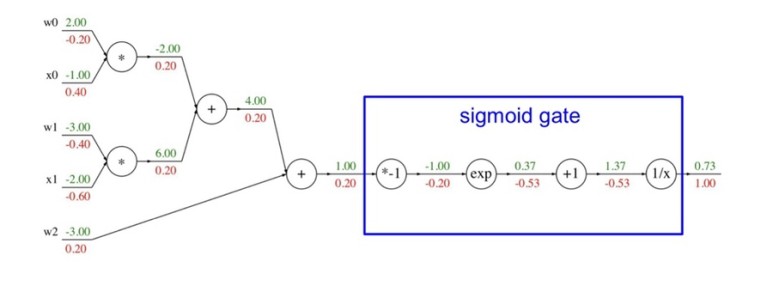
위 그림처럼 우리가 관심을 가지고 있던 가중치의 gradient값을 구할 수 있게된다.
여기까지가 딥러닝의 주된 계산 중 하나인 오차역전파(back propagation)이다.
수식이 많아서 그렇지 결국 정리를 해보자면, 우리는 좋은 가중치를 찾아서 손실함수를 최소화 하고싶다.
좋은 가중치를 찾는 과정이 곧 학습인데 학습의 지표가 될 것이 각 가중치의 손실함수에 대한 gradient이다.
이 gradient를 구하기 위해서 맨 끝의 노드에서부터 chaine rule을 사용해 천천히 계산해 오는 것이 오차 역전파다.
이 오차역전파를 실제 구현할 때 관건이 되는 부분은
각 함수의 연산과 함수의 input값을 저장하고 있어야 한다는 것이다.
dL/dL = 1부터 시작해서 모든 함수와 변수에 대해서 chain rule을 적용하기 위해서는 모든 변수와 함수를 저장해야할 것이다
