
자연어 처리에서 우선적으로 고민해야할 문제는 자연어를 어떻게 컴퓨터가 처리할 수 있도록 만드는가이다. 쉽게 말해 자연어 자체를 컴퓨터가 이해할 수 없으니 인코딩해야하는데 어떤 방식을 취하냐이다. 결국 이 인코딩을 word to vector라고 생각해볼 수 있다.
이 문제가 어려운 이유는 자연어 자체가 굉장히 복잡하고 이해하기 어려우며 맥락 의존적이기 때문이다. 같은 말이라도 다양한 의미가 있고 같은 의미라고 하더라도 맥락에 따라 해석이 달라질 수 있다.
과거 사용된 방법은 wordnet과 같은 동의어 사전을 활용하는 방식이다. 하지만 결국 사전식에 의존한 방식은 모든 맥락을 다루지 못할 뿐더러, 신조어에 대처할 수 없다.
또 다른 방식으로 원핫 인코딩을 생각해볼 수 있다. 각 단어의 개별성을 인정하는 방식으로 원핫인코딩을 하는 것인데 이때 문제는 단어별 유사성과 맥락을 전혀다루지 못한다는 것이다. 왜냐면 원핫 인코딩은 각 벡터간 orthogonal 하기 때문이다.
어떤 자연어를 벡터화 한다고 했을 때, 좋은 벡터는 결국 유사한 의미를 지니고 있는 또는 비슷한 맥락에서 쓰이는 벡터들 간 유사성을 보이는 성질을 가지고 있을 것이다. 가령 모텔과 호텔이라는 단어가 있을 때 둘은 분명 다른 말이지만 굉장히 유사한 의미와 맥락을 지니므로 각 단어를 벡터화 했을 때, 벡터간 유사성이 높을 때 잘 벡터화했다고 볼 수 있다.
이렇게 자연어를 바라보는 것이 distributional semantics 관점이다. 해당 관점에서는 자연어의 의미는 그것의 맥락에 의해서 결정된다고 바라본다.
You shall know a word by the company it keeps”
(J. R. Firth 1957: 11)
아래 사진에서 banking의 의미를 어떻게 해석할 것인가는 그 단어 자체가 본질적으로 가지고 있는게 아니라 주변 맥락 단어들에 의해서 결정된다.
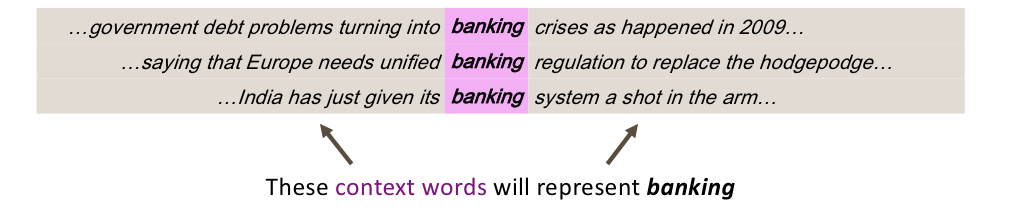
이러한 맥락을 반영해서 아래와 같이 8차원으로 벡터화 해볼 수 있다.

이런 방식으로 비슷하게 벡터를 2차원으로 벡터화했다고 가정해보자. 이때 2차원 평면상에 벡터들을 그린다고 하면 아래와 같이 표현될 수 있다.

