1. 논리연산자
not : true는 false로, false는 true로
a < x < b 이런 연산도 가능
2. 조건문
조건문을 사용하는 이유
- 리스트같은 객체에서 각 요소를 반복문 for로 돌아다니면서 제어하기 위해 사용
- 조건문 = 제어문
if else문
if 조건문:
조건문이 참일 때 실행하는 동작 1
조건문이 참일 때 실행하는 동작 2
...
else:
조건문이 거짓일 때 실행하는 동작 1
조건문이 거짓일 때 실행하는 동작 2
...if else는 깔끔하게 흑백논리로 떨어질 때 사용
모 아니면 도
0 아니면 1로 떨어지는 경우
number = 3
if number % 2 == 0:
print("짝수 입니다.")
else:
print("홀수 입니다.")이 경우 보통은 not연산자를 주로 사용한다.
n = int(input('숫자 입력: '))
if not n % 2:
print("짝수입니다.")
else:
print("홀수입니다.")- 2로 나눈 나머지가 0 => False
not 0 = True - 2로 나눈 나머지가 1 => True
not 1 = False
즉, 조건문을 만족할 경우(True일 경우) = 짝수
그 외의 경우는 홀수.
단축평가를 활용해서 에러 회피(?)
a = [1,2,3]
if len(a) < 3 and a[4] != 4:
print("if 통과")
else:
print("else 통과")
# else 통과- if문 조건절에 논리연산자 and의 단축평가를 활용한다.
- and 왼쪽은 False를 리턴하는 조건, 오른쪽은 에러가 나는 조건이다.
- 왼쪽 조건에서 False를 리턴하면 오른쪽은 검증하지 않는 것을 활용해 에러가 날 만한 조건을 and절 오른쪽에 둔다.
중첩조건문 : elif 활용
3. 컨테이너 자료형
순서가 있는 컨테이너 : 인덱싱 가능
순서가 있다 != 요소가 정렬되어있다
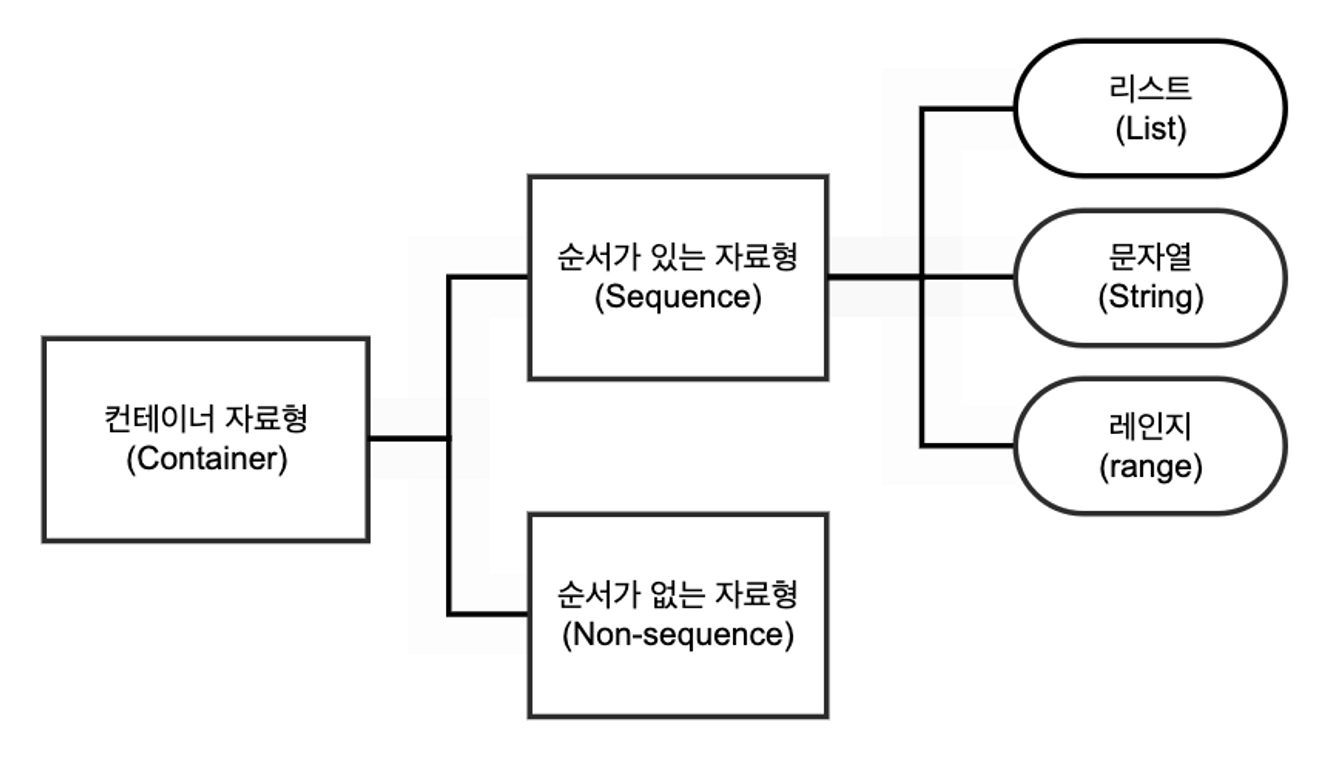
리스트 자료형
- 0개 이상의 데이터를 순서 있게 저장 - 빈 리스트도 있다.
- 온갖 자료형이 원소로 저장될 수 있다.
리스트 연산
+
두 개 이상의 리스트를 합칠 수 있음
리스트의 요소로 다른 리스트 자체가 들어오는게 아니라
두 리스트의 요소가 한 리스트 안에 합쳐짐
*
- 리스트 원소를 여러 번 반복해서 생성 가능.
- 이때 리스트 곱셈은 객체 복사이다.
a = [[0]*3]*3
# a = [[0,0,0],[0,0,0],[0,0,0]]이런식으로 복사해서 만들게 되면 객체 a는 [0,0,0]이라는 똑같은 리스트 3개를 요소로 갖는 2차원 리스트가 된다.
a[0][0] = 99
# a = [[99,0,0],[99,0,0],[99,0,0]] 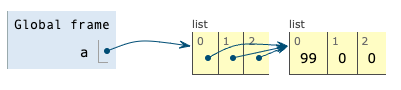
- 이 경우 [0,0,0]이라는 객체를 3개 복사한 것이다.
- 즉, 동일한 주솟값을 갖는 새끼 리스트([0,0,0] 하나) 3개를 요소로 갖는 것이다.
- 값을 수정할 경우 3개의 요소가 전부 다 바뀌게 되는 문제가 발생한다.
이런 식으로 2차원 리스트를 만들면 안된다.
<1차원 리스트와 2차원 리스트의 얕은복사 비교>

mutable 자료형
- 변경/수정이 가능한 객체
- list, dict
- immutable : 변경 불가능한 객체 (일반적 자료형, 튜플)
iterable 자료형
- 반복 가능한 객체
- list, tuple, str, set, dict, range 등
- 여러 데이터가 합쳐져 있다 = 반복문을 통해 그 요소를 하나씩 꺼내볼 수 있다.
- 리스트는 수정과 반복이 둘 다 가능한 객체이다.
- 튜플을 순서가 있어서 반복이 가능하지만(iterable), 수정이 불가능한 객체(immutable)이다.
리스트 메서드
(1) .append()와 .pop()
- .append()는 return값이 없음 -> None
- .pop()은 return값이 있다
(2) .sort()와 함수 sorted()
- .sort() -> 메소드 : 원본 자체를 정렬
- sorted() -> 함수 : 정렬된 객체를 새로 생성(주솟값 재배정 = 분리). 주솟값이 다름. 원본은 전혀 변하지 않는다.
- .sort()는 기본적으로 렉시코그래픽 정렬이다.
- 렉시코그래픽 : 올림픽 메달순위 기준과 같음. 제1기준으로 먼저 정렬, 그 다음 제 2기준으로 정렬 ...
정렬의 기준
익명함수 lambda를 활용한다.
#2차원 리스트 정렬
a = [[4, 4, 16], [6, 1, 6], [4, 3, 12], [1, 12, 12], [5, 4, 20], [2, 3, 6], [3, 4, 12]]
#문자열 정렬
b = ['hi', 'bonjour', 'hello', 'greetings']
a.sort(key=lambda x: (x[1], x[2]))
b.sort()
print(a, b)
# a = [[6, 1, 6], [2, 3, 6], [4, 3, 12], [3, 4, 12], [4, 4, 16], [5, 4, 20], [1, 12, 12]]- a의 정렬기준으로 제 1 기준은 요소의 1번째 요소(x[1]), 제 2 기준은 요소의 2번째 요소(x[2])로 설정한 것이다.
(3).extend(iterable한 객체)
- 리스트 끝에 여러 값 추가
- 리스트 합치기
+연산으로도 리스트 합치기 가능
리스트 슬라이싱
- [n:m] : n이상~ m미만
리스트 슬라이싱으로 리스트 복사/삭제/삽입
- 원본은 변하지 않음(id값 분리)
nums = [3, 5, 1, 4, 2]
sliced_nums = nums[2:4] # 인덱스 2 ~ 4 중 마지막 4를 제외한데까지 도려냄.
print(nums, sliced_nums)리스트 슬라이싱으로 리스트 전체 카피시 주의점
-
[:]
-
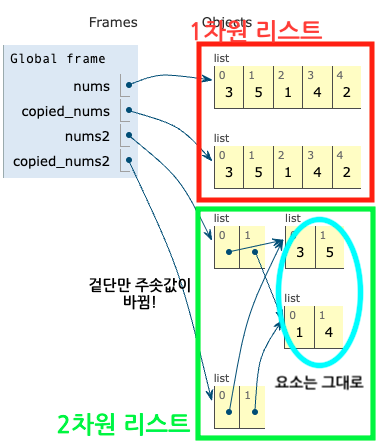
얕은 복사가 발생해서 1차원 리스트에서는 주솟값이 분리가 되어 문제가 없지만, 2차원 이상에서는 문제가 있다.
-
2차원 이상의 리스트에서부터는 가장 겉의 리스트는 주솟값이 분리가 되지만, 그 요소가 되는 리스트는 주솟값이 변하지 않는다.
-
따라서 요소가 되는 새끼 리스트의 값이 수정되면 복사한 리스트에서도 값이 수정되는 문제가 발생한다.
-
요소인 새끼 리스트의 id값도 분리해서 복사하려면 deep copy(깊은 복사)를 해야한다.
(deep copy 메소드는 추후에..)
슬라이싱으로 리스트 특정부분에 삽입하기
nums = [3, 5, 1, 4, 2]
nums[1:2] = [9, 10, 11]
print(nums)
# [3, 9, 10, 11, 1, 4, 2]- 원본이 바뀐다(주솟값 재배정X)
- 특정 부분을 빈 리스트로 삽입할 경우 깔끔하게 도려낼 수 있다.
