[Text Analytics] 5-3: Glove & FastText

Glove

2014년 스탠포드에서 발표한 논문에 나온 알고리즘으로 Word2Vec의 한계점을 지적하면서 Glove를 소개했다.
Neural network는 자주 사용되는 단어를 학습하는데 너무 많은 시간을 소비한다.
예를 들어 "the + 단어" 형태일 때 "the"가 가진 gradient를 계속 학습한다.
예시 문단에서 다른 단어들이 1번 나오는 반면 the는 12번 나오는데, 이러한 데이터를 학습 데이터로 사용하면, 학습의 불균형이 발생할 수 있다.

Skip-gram과 달리 Glove는 matrix factorization에 기반을 둔 방법론이다.
X : 동시 발생 행렬, vocabulary 크기만큼 행, 열을 가진 크기가 매우 큰 행렬
X_ij : 단어 i와 단어 j가 동시에 발생한 빈도
X_i : corpus(전체 단어)에서 단어 i가 등장한 횟수
P_ij : 단어 i가 등장했을 때 단어 j가 함께 등장할 조건부 확률
W : 워드 임베딩
W(~) : 워드 임베딩에 대응되는 context (W 틸다 라고 읽음)

P(k|ice): 단어 ice가 등장했을 때 단어 k의 빈도 라고 한다면,
단어ice는solid와 연관성이 크기 때문에P(solid|ice) > P(gas|ice)이다.
P(k|steam): 단어 steam이 등장했을 때 단어 k의 빈도 라고 한다면,
위와 같은 이유로P(solid|ice) < P(gas|ice)이다.
=> k = water, fashion일 때 P값이 비슷한 것을 통해 조건부에 상관없이 P가 유사함을 보여준다.
어떤 단어 k가 ice와는 연관성이 높지만, steam과는 연관성이 낮은 경우(solid) : P_ik / P_jk값이 크다.
어떤 단어 k가 steam과는 연관성이 높지만, ice와는 연관성이 낮은 경우(gas) : P_ik / P_jk값이 작다.
=> 분자와 연관성이 높으면 P_ik / P_jk이 커지고, 분모와 연관성이 높으면 P_ik / P_jk는 작아진다.
=> 둘 다 연관성이 높거나 water, 둘 다 연관성이 낮으면 fashion P_ik / P_jk값은 1에 가까워진다.

W_i : ice
W_j : steam
W_k(~) : solid -> 상대적으로 두 단어와 관련성이 있는지 없는지 판단하게 될 단어(context word)에 해당함
위의 3 단어의 관계를 나타내는 함수 F는 조건부확률 P로 나타낼 수 있다.
F(ice, steam, solid) = P(solid|ice) / P(solid|steam)
W_i와 W_j간의 관계는 substraction으로 표현할 수 있다.
또한 W_i와 W_j간의 차이가 context word W_k(~)와는 어떤 관계를 가지는지를 표현하기 위해서 내적을 사용한다. (스칼라 값을 가짐)

위에서 설명한 것처럼 함수 F를 조건부 확률값 P로 나타낼 수 있다.
위에서 정의한 식을 사용해 P(solid|ice) / P(solid|steam)과 역수값 P(solid|steam) / P(solid|ice)를 정의하면 다음과 같다.
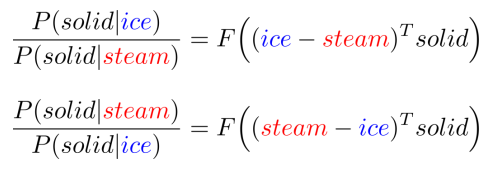

입력에서 단어의 위치를 바꾸면, 출력에서 역수값이 된다.
덧셈에 대해 항등원이다 -> a = -a
곱셈에 대해 항등원이다 -> a = 1/a
입력을 덧셈의 항등원으로 바꾸면 출력은 곱셈에 대한 항등원으로 나온다.
덧셈에 대해 항등원인 입력은 출력에서 0보다 큰 공간에서 곱셈에 대한 항등원으로 표현된다. -> (R, +) to (R>0, x)

- 수식 (1)에서 좌변의 식에서 W_j를 뺐다가 더하면 우변과 같이 표현할 수 있다.
- 수식 (1)의 양변에 함수 F를 취하고, homomorphism에 의해 입력에서의 덧셈은 함숫값의 곱셈으로 표시되기 때문에 수식 (2)에서 두 함숫값의 곱으로 표현된다.
- 수식 (2)에서 양변을 하늘색 박스의 식으로 나누면 마지막 식처럼 표현할 수 있다.
f(a+b) = f(a) x f(b)을 만족하는 f를 원한다. -> 가장 간단한 f는 exp(), 지수함수이다.
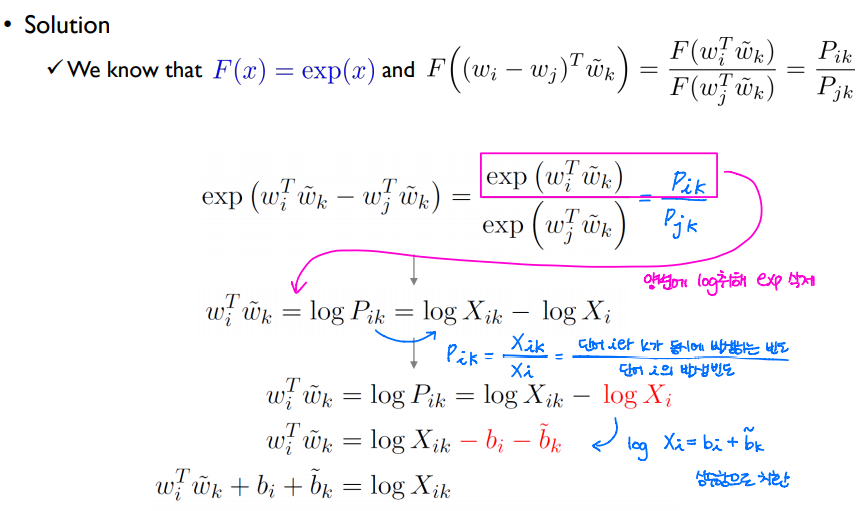
F(x) = exp(x)임을 통해 이전 슬라이드에 구한 식을 exp()을 사용해 표현할 수 있다. P_ik = exp(W_i^T * W_k(~))이다.
분홍색 박스의 양변에 log를 취해 exp()함수를 삭제한다.
P_ik = X_ik / X_i이기 때문에 log(P_ik) = log(X_ik) - log(X_i)로 표현할 수 있다. 나눗셈에 로그를 취하면 뺄셈이 된다.
이 때 log(X_i)를 상수항 b_i + b_k(~)로 나타내면, 마지막 식을 얻을 수 있다.

Glove의 목적함수는 첫 번째 J식과 같으며, 파란색 부분은 학습해야하는 값이고, 빨간색은 실제 관측값에 해당한다. 학습한 값과 실제값의 차이가 작아지는 것을 목표로 한다.
빈도수가 높은 단어에는 가중치를 작게 주기 위해서 f(X_ij)를 사용한다.

알파(a)는 하이퍼 파라미터에 해당하며, 빈도수가 높은 단어에는 가중치를 작게 주기 위해 사용한 f(X_ij) 값을 보면 일정 값을 지나면 커지지 않는다.

Glove를 학습한 임베딩의 결과를 보면 벡터가 잘 유지되는 것을 볼 수 있다.
FastText

FastText는 facebook에서 개발했으며, 언어의 morphology(형태학적 특징)를 관여하지 않는 NNLM, Word2Vec, GloVe의 한계를 보완하기 위한 방법이다.
morphologically rich한 언어에는 터키어, 핀란드어가 있는데 한국어에 비유한다면 형태소의 어미변화가 너무 다양해 똑같은 형태의 단어가 많이 등장하지 않는다고 볼 수 있겠다.
지금까지는 단어나 토큰 level에서 임베딩을 수행했지만, FastText는 character(문자) level에서 임베딩을 수행한다.

FastText의 목적함수는 J와 같이 정의된다.
기존에는 단어 "apple"의 임베딩은 "apple"만을 사용해 수행했지만, FastText에서는 a, ap, app, appl, apple을 사용해 단어를 임베딩한다.
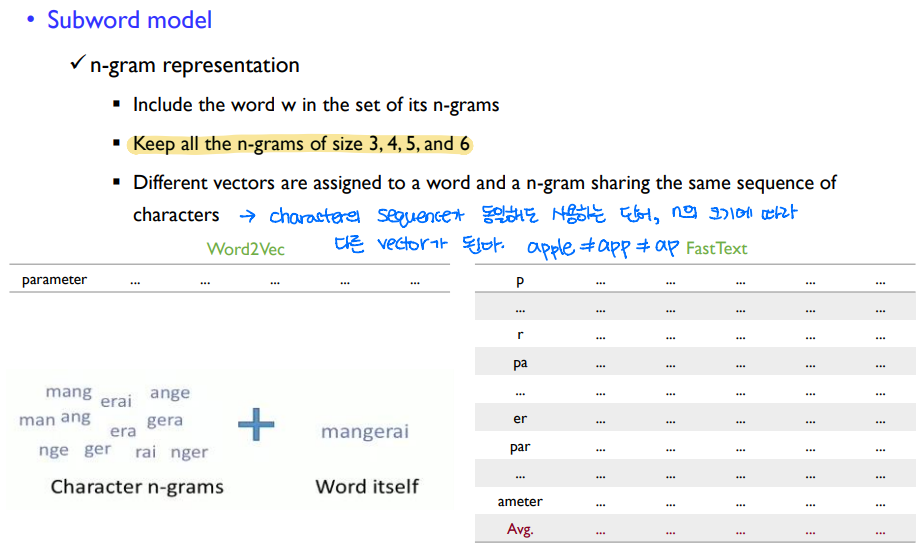
임베딩 할 때 사용하는 문자의 순서가 동일해도, 사용하는 단어와 n의 크기에 따라 임베딩이 달라진다.
a의 임베딩, ap의 임베딩, app의 임베딩, apple의 임베딩은 모두 다르다.
