[Text Analytics] 4-1강: Count-based Text Representation

Document Representation
하나의 문서(document)를 어떻게 구조화된 방식으로 표현할 것인가?,
Vector space를 기반으로 머신러닝 알고리즘을 적용하기 위해 비구조적인 text를 어떻게 구조적인 vector/matrix로 변환할 것인가?
Bag of Words, Word Weighting, N-Grams이 있음
Bag of Words(BoW)
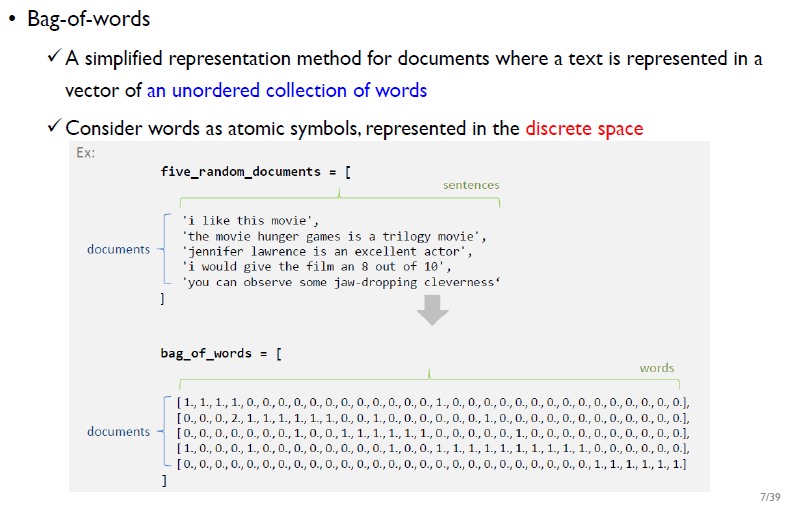
문서는 단어들의 집합인데, BoW는 문서를 표현할 때 단어의 순서는 고려하지 않고 표현하는 방법이다. 단어를 벡터로, 이산 공간(discrete space)에 표현한다.
위의 사진에 주어진 문서는 5개의 문장으로 구성된다.
이를 BoW로 표현하면: 각각의 문서에서 words에 해당하는 단어의 빈도수가 된다. 여기서 words는 5개의 문서에서 등장한 모든 단어를 말한다. 1행 3열의 '2'는 "movie"의 빈도수에 해당한다.
Bag of Words: Term-Document Matrix(TDM)
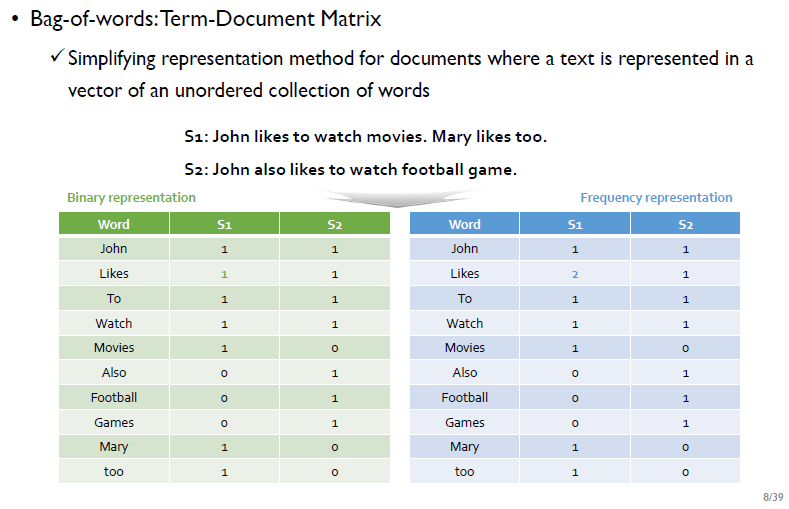
Bag of Words는 Term-Document Matrix(TDM)이라고도 하며, 행과 열을 바꿔서 DTM을 사용하기도 한다. 항상 TDM에는 frequency representation, binary representation 2가지 표현방법이 있는데, 항상 특정 방법이 좋은 것은 아니며, task에 따라 달라진다.
- 왼쪽의 binary representation : 특정 단어가 문서에서 등장 했는지/ 안 했는지(등장 여부)를 표현
- 오른쪽의 frequency representation : 특정 단어가 문서에서 몇 번 등장했는지를 표현

벡터 공간상에서 문서를 BoW로 표현하기
BoW를 통해 단어의 빈도수로 문서의 문맥(내용)을 추론할 수 있다. 하지만 BoW는 단어의 빈도수만 고려할 뿐, 단어의 순서는 고려하지 않는다.
Bag of Words의 문제점
1) 의미가 다른 두 문장이 같은 형식으로 표현될 수 있다.
- "John loves Mary?" 와 "Mary loves John?" 은 서로 다른 문장이지만 BoW로 표현하면 결과가 같음
2) 재구성(reconstruction)이 불가능하다.
- BOW 결과인 (John, loves, Mary)를 가지고 만들 수 있는 문장은 "John loves Mary?" 와 "Mary loves John?" 두가지가 있기 때문에 original text를 다시 만들 수 없다.
- Original text -> term-document matrix는 가능하지만 반대는 불가능
Stop Words
전처리 과정에서 불용어(stop words) 제거도 수행한다. 불용어를 제거하는 알고리즘도 있지만, 일반적으로 언어마다 불용어를 미리 정의해 놓은 불용어 사전을 사용해 불용어를 제거한다.
Word Weighting
Word weighting이란 특정 문서에서 특정 단어가 얼마나 중요한지 판단하는 방법이다.
Document Frequency(DF)
- 특정 단어 t가 전체 corpus에서 몇 개의 문서에 등장했는지(전체 문서에 대해서)
- "문서에 자주 등장하는 단어는 중요도가 떨어진다" 에 근거해 DF값이 작을수록 중요도(가중치)를 더 부여함 -> DF에 역수를 취한 IDF개념이 나옴
- common한 단어보다는 rare한 단어에 weight를 더 많이 주어야 한다.
Term Frequency(TF)
특정 문서에 대해 특정 단어 t가 몇 번 등장했는지(개별 문서에 대해서)
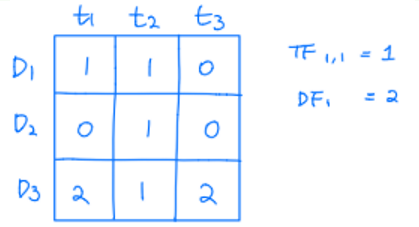
위의 예시에서 D1, D2, D3은 각각 문서를 의미하며, t1, t2, t3은 각각 단어를 의미한다.
- doc 1에 대한 t1의 TF값 = 1
-> doc 1에서 t1이 1번 등장했기 때문- 전체 doc에 대한 t1의 DF값 = 2
-> t1이 doc 1, doc 3 총 2개의 문서에서 등장했기 때문
Inverse Document Frequency(IDF)
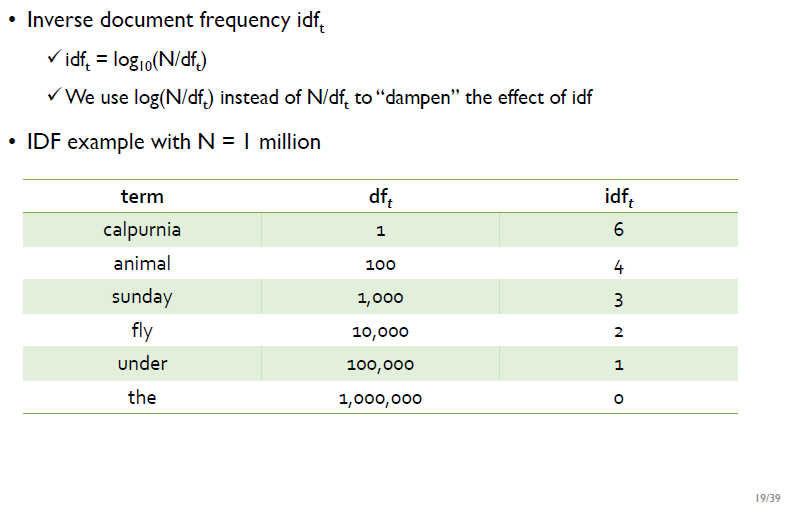
IDF는 DF의 역수를 취한 값이다. N/df가 아닌 log(N/df)로 계산하는데, 이는 기하급수적으로 증가하는 DF값을 선형적으로 만들기 위함이다.
위의 초록색 표를 보면 DF 값은 기하급수적으로 증가하는 반면, IDF값은 log를 취했기 때문에 선형적으로 감소하는 모습을 볼 수 있다.
TF-IDF

특정 term(단어)이 특정 문서에서 얼마나 중요한가? 라는 질문에 TF와 IDF를 곱한 값인 TF-IDF값이 커야 해당 term의 중요성이 커진다고 말할 수 있다.
단어의 중요성은
1) 문서에서 많이 등장할수록(TF값이 클수록)
2) 전체 corpus에서는 적게 등장할수록(DF값이 작을수록, IDF값이 클수록) 증가한다.
예를 들어, 전체 문서 중 특정 문서1에만 단어t가 많이 등장하면 TF값도 크고, IDF값고 크기 때문에 TF-IDF값이 커진다. 즉, 중요한 문서가 된다.
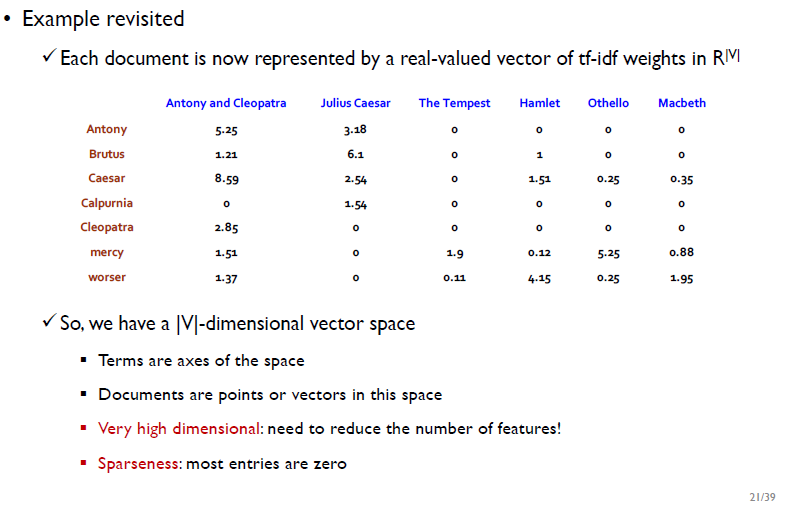
V는 vocabulary, |V|는 해당 문서에서 쓰인 총 단어의 개수를 의미한다.
하나의 문서를 표현하기 위해서는 v차원 vector space가 필요한데, 이 v차원 vector space에서 term은 축, 문서는 점으로 표현된다.
- 문서를 v차원의 벡터공간으로 표현하는 방법의 한계점:
1) 문서를 표현할 때 고차원
2) 고차원 벡터 안의 값이 sparse(대부분 0)하기 때문에 낭비가 자원낭비가 심함

- 위의 예시에서 Doc 1에서 가장 중요한 term은 term 1이다.
-> term 1은 doc 1에서 가장 많이 등장하고, doc 2, doc 3에서는 적게 등장하기 때문이다- Doc 1에 대한 term 1~5의 중요도(TF-IDF를 기준으로) : term 1> term 5> term 2 > term 3 = term 4

TF, DF, IDF 에도 다양한 변종이 있으며, 위의 표에 나온 TF-IDF가 일반적으로 가장 많이 쓰인다.

Paltoglou and Thelwall의 연구에서는 TF-IDF의 조합에 따라 성능이 어떻게 달라지는지 알아보기 위해 2가지 감정분석 task에 적용해보았다.
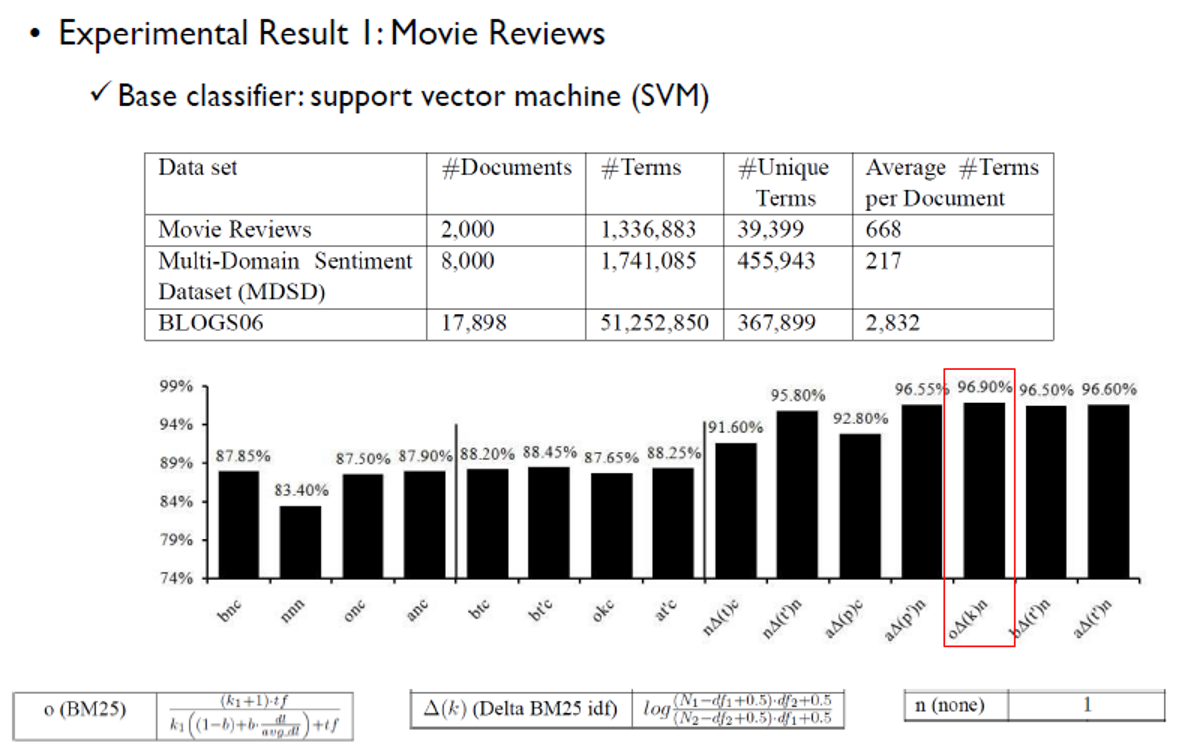
이 연구에서는 BM25, Delta Bm25 idf, n의 조합일 때 96.9%로 성능이 가장 좋았다. 하지만 96.9%라는 수치가 통계적으로 유의미한 결과인지 알 수 없으며 항상 이 조합이 좋은 성능을 내는 것은 아니다.
-> 이 연구를 통해 "문서를 어떻게 표현하는지에 따라 성능 차이가 있을 수 있다"를 알 수 있다.
N-Grams

n-gram 모델은 (n-1)개의 단어를 보고 다음에 오는 n번째 단어를 예측하는 방법으로, 여러 단어가 묶여 하나의 관용구/단어로 쓰이는 경우에 유용하다.
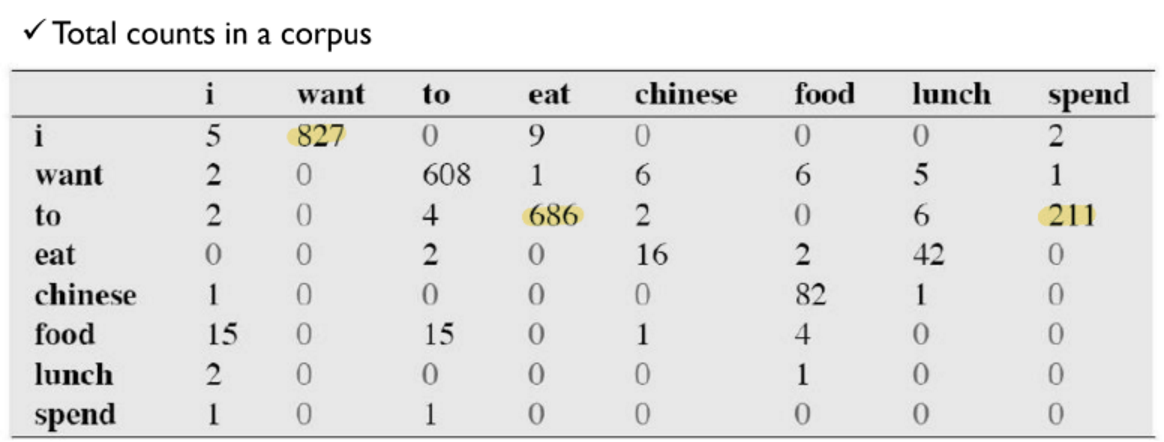
위의 Bigram example을 통해 i-want, to-eat, to-spend가 자주 등장하는 것을 알 수 있다.
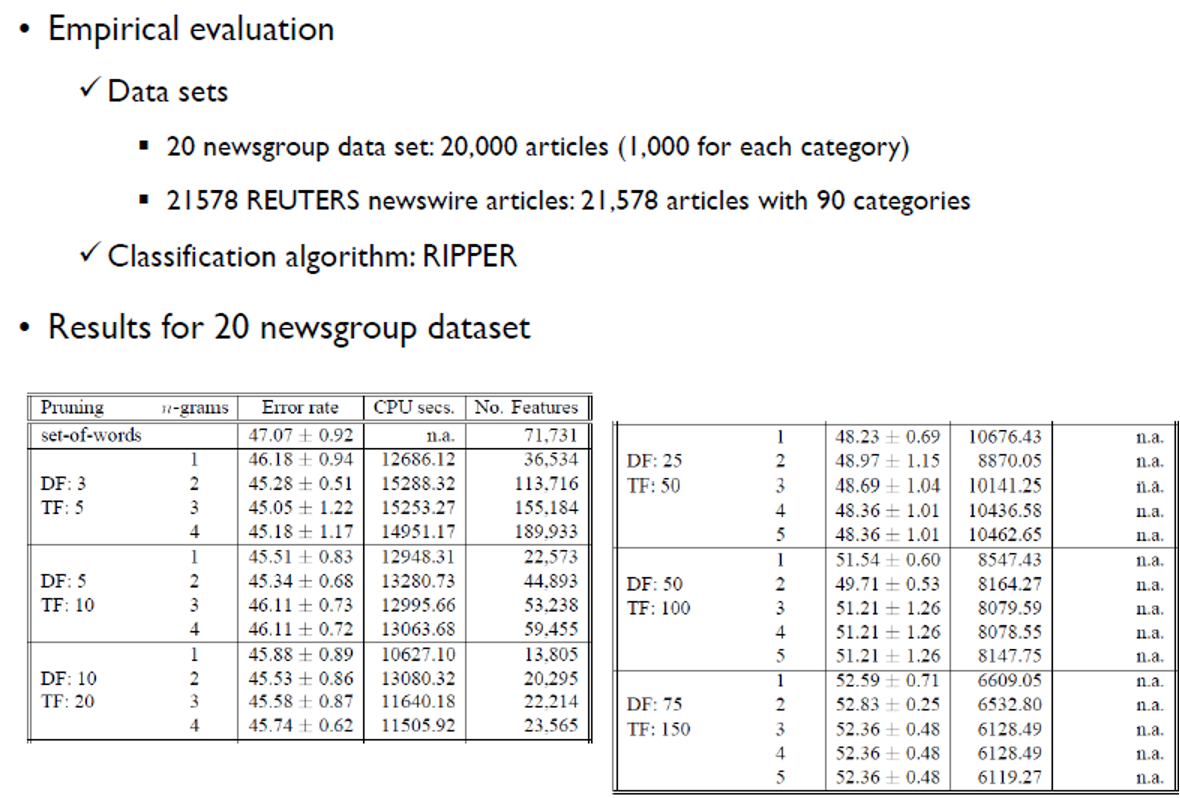
-
구텐베르크 프로젝트 : 세상의 모든 책을 스캔해 n-gram 데이터셋을 만들면 번역을 더 잘 할 수 있을 것이다-> neural net이 더 좋은 성능을 보여 실패함.
-
n-gram의 n값이 커짐에 따라 error가 조금 줄어들거나 변화가 없다-> n값에 따라 성능 차이도 별로 없고, 가장 성능이 좋은 n값을 찾는데 걸리는 수고로움이 너무 크다.
