[openAI] Whisper 논문 리뷰
1. Introduction
Whisper 가 등장하기 이전 가장 대표적인 speech recognition model 은 wav2vec 이었다.
1.1. wav2vec 의 등장과 맹점
wav2vec 은 facebook 에서 발표한 speech recognition model 로,
pre train 은 unsupervised learning 으로, 대규모 음성 데이터 (60,000 H)를 기반으로 학습했고
fine tuning 은 적은 수의 labeled 데이터로 supervised learning 으로 진행되었다.
이런 방식의 학습은 decoder 가 text 와 audio representation 을 매핑할 수 없다.
따라서 이런 방식으로 pre trained 만 된 모델이 실제로 STT 기능을 하기 위해서는 반드시 fine tuning 을 해야 한다.
이런 구조의 모델은 다음과 같은 단점을 갖는다.
- fine-tuning 자체가 복잡해짐
- fine-tuning 데이터셋을 구성하는 과정이 성능을 좌지우지 할 가능성이 높음
- open AI 연구진은 데이터셋이 모델의 성능을 크게 결정 짓는 경우에는 dataset-specific quirks (특정 데이터에서만 잘 작동하는 "괴짜" 모델) 가 될 가능성이 높다고 말한다.
결과적으로 다양한 distribution 을 갖는 audio dataset 에 대해서 speech recognition 을 수행하는 경우에는 fine-tuning 시에 사용한 dataset 에서 검증된 성능보다 실제 성능이 좋지 않을 수 밖에 없는 것이다.
robust 하고, general 한 speech recognition 모델은 현재까지 선행된 연구에서는 실현할 수 없는 개념이었다.
1.2. 새로운 희망을 발견한 openAI 연구진
이러한 고민을 갖던 연구진은 몇가지 연구를 발견하게 된다.
-
speech recognition 의 pre-train 과정에서, wav2vec 과는 다르게 적은 수의 dataset 으로 supervised learning 을 했는데 모델의 성능이 좋았다.
Narayanan et al. (2018), Likhomanenko et al. (2020), and Chan et al. (2021) -
CV (computer vision) 분야에서 대량의 weakly supervised 데이터로 모델을 학습시켰더니, robustness 와 generalization 이 증가했다.
Mahajan et al. (2018) , Kolesnikov et al. (2020)
위 두 종류의 연구들은 openAI 연구진들에게 모종의 확신을 가질 수 있게 만들어줬던 것 같다.
연구진들은 곧바로 모델을 학습시키기 위한 dataset 을 만들기 시작했다.
2. Approach
2.1. dataset 수집
open AI 연구진이 최종적으로 모델 학습에 사용한 데이터셋은 다음과 같았다.
- 총 시간 : 680,000 시간 (wav2vec 은 60,000 시간이었다..!)
- label 여부 : weakly-supervised
- pre-train & fine-tuning 여부 : fine-tuning 하지 않음.
- 특이사항 : 680000 시간 중 117000 시간은 96 개의 언어 음성이고, 125000 시간은 이를 영어로 번역한 데이터까지 포함함.
한눈에 봐도 기존의 model 들보다 엄청나게 많은 양의 데이터를, 그것도 supervised 로 모았다.
2.2. data processing
openAI 연구진은 audio data 와 text 에 대해 pre-processing 을 거의 하지 않았다.
그 이유에 대해 논문에서는 다음과 같이 설명한다.
- seq2seq 모델이 standardization 을 거치지 않은 raw text 와 audio 의 expressiveness 를 충분히 학습하여 utterance 자체와 transcribe form 간의 관계를 이해하게 하기 위해서!
- ITN (inverse text normalization) 을 거치지 않아서 speech recognition pipeline 을 단순화 시키기 위해서!
whisper 논문을 읽으면서 가장 신기했던 부분은 이런 부분이었는데, 이런식으로 기존의 speech recognition 모델이 일반적으로 dataset 을 구성할 때 당연하게 거치는 과정들을 "고의"로 빼버렸다는 것이다.
어찌됐든 이런식으로 만들어진 dataset 은 모델 학습시에 장-단점이 있다.
-
장점 : dataset 이 diverse environments, recording setups, speakers, and languages 를 포함하게 된다.
→ robust -
단점 : diversity in transcript quality
→ not beneficial, can cause harm to model performance
사실 단점으로 명시된 데이터 퀄리티에 대한 문제는 어찌보면 당연한 것이므로 openAI 연구진이 이 문제에 대해 엄청난 우려를 했다기보다는, 개중에 "매우 특수한 상황" 에 대한 처리를 중요하게 여겼다.
그것은 바로 Machine-Generated transcription data 였다.
기존 선행 연구들에서 훈련 데이터에 mixed human and machine-generated data 가 있으면 "significantly impair the performance of translation systems" 라는 것이 널리 알려져 있었기 때문이다.
따라서 몇가지 filtering method 를 통해 이러한 상황을 최소화하고자 하였다.
- all-uppercase or all-lowercase 제외
- some level of inverse text normalization 을 찾아서 rule base 로 제외
- never including commas.
- 언어 감지 모델 이용, audio 와 text 언어 다르면 제외
- 각 segment 에 대한 WER 수치와 segment 의 길이의 combination 이 높은 순서대로 정렬하고, 들어보면서 수동으로 low quality 데이터는 삭제함
2.3. model
whisper 의 모델 구조는 transformer 의 인코더-디코더 구조를 그대로 차용하였기 때문에 크게 할말은 없지만, 따로 문서를 통해서 정리하도록 하겠다!
2.4. multitask format
speech recognition 에는 단순 audio - word prediction 외에도 voice activity detection, speaker diarization, inverse text normalization 과 같은 태스크가 있다.
일반적으로 하나의 목적에 맞게 fine-tuning 되는 모델들은 동시에 여러 task 를 수행하지 못한다.
하지만 whisper 에서는 이를 동시에 모두 처리하기 위해 task 와 conditioning information 을 decoder 의 Input 에 sequence 정보로 제공해줌
또한 앞에서 생략되긴 했지만, whisper 는 training data 가 모두 30s 단위로 잘려있다. 따라서 길거나 ambiguous 한 audio 에 대한 inference 성능이 저하될 것으로 우려한 연구진들은 모델이 longer range 의 텍스트 맥락을 사용하게 하기 위해 일부 audio 에 대해서는 text history 를 함께 제공했다.
decoder 훈련에 사용되는 input token 종류는 다음과 같다.
- Text token
- special token
- < no speech >
- < transcribe >
- < translate >
- < start of transcription >
- < no timestamps >
- < end of transcript >- timestamp token
앞서 설명했던 부분 중 task 와 conditioning information 을 제공해주는 special token 이 눈여겨볼만한 부분인 것 같다.
3. Experiments
3.1. zero shot evaluation
whisper 는 기존의 일반적인 speech recognition 모델들 처럼 train - test set 을 분리시켜서 model evaluation 을 하지 않고 모델 훈련에 사용되지 않은, 기존에 open 되어있던 speech processing dataset 들에 대해 zero-shot setting 에서 model evaluation 진행하였다.
3.2. evaluation metrics
STT 모델의 일반적인 성능 평가 지표인 WER (Word Error Rate) 은 string edit distance 이다.
기존 speech model 의 경우 특정한 distribution 에 대해서만 fine tuning 되어있기 때문에 zero-shot evaluation 을 하면 minor 한 formatting difference 가 계속 생길 수 밖에 없음
Whisper 는 robust model 이므로 이에 영향을 최소한으로 받긴하지만, 정확한 성능 비교를 위해 연구진들은 non-semantic difference 는 제외하고 WER 을 비교하였다.
3.3. Whisper 에게 연구진이 기대한 바
whisper 가 개발되던 2022 년 경에 나와 있던 기존 speech recognition 모델들의 성능은 나쁘지 않았다.
해당 모델들은 fine-tuned 데이터셋에서 추출한 test set 을 통해 evaluation 을 하면 WER 평균 약 5% 인 사람보다 훨씬 좋은 성능인 1% 대를 기록하며 superhuman performance 을 보여줬다.
하지만 훈련된 데이터셋이 아닌 데이터, 즉 out-of-distribution 에서 모델 평가를 진행하면 subhuman performance 를 보여주었다.
그럼 왜 이런 차이가 발생하는걸까? 이런 모델을 정말 "사람보다 잘한다" 라고 말할 수 있는걸까?
사실, 차이는 train 과정에서 온다
사람이 transcription task 를 받게 되면, 사전에 해당 audio 가 속해있던 distribution 에 대한 이해(어떤 특성을 갖는지, 어떻게 분포하는지, 등등) 를 하지 않고 작업을 수행하게 된다.
따라서 human performance 는 out-of-distribuition preformance 으로 생각해야한다. 사람들은 모든 transcription task 에 대해 out-of-distribution 성능을 기록하고 있는것이다.
하지만 machine learning 모델은 train 과정에서 test 에 쓰이는 데이터의 distribution 을 이해하게 되므로 훈련된 데이터셋에 대해서 superhuman performance 를 내는 것처럼 느껴지는 것이다.
하지만 whisper 는 robust 하게 train 과정이 설계 되었으므로 transcription 도 가장 human behavior 과 비슷하게 수행할 것을 openAI 연구진들은 기대했다.
3.4. English Speech Recognition
3.3 에서 제시한 가설, 즉 whisper 가 가장 사람과 비슷한 transcription 성능을 보여줄 것이라는 가설을 확인하기 위해 연구진은 모델의 성능 평가에 가장 흔하게 사용되는 libri speech dataset 의 dev-clean 데이터를 reference 데이터로 삼고, 이에 대한 성능(WER)을 x 축에 도시하였다.
또한 이를 기반으로 훈련된 여러 모델들의 성능을 libri speech 가 아닌 다른 데이터셋의 test set 에서 측정하고, 이 성능(WER)의 평균값을 y 축에 도시하였다.
결과는 다음과 같다.
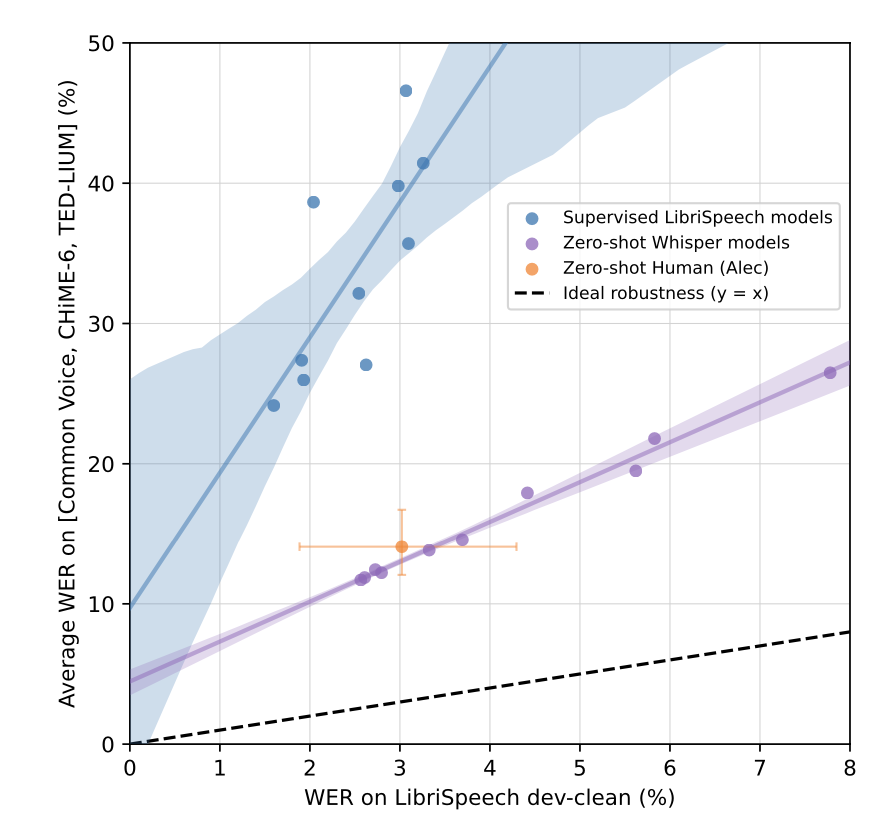
[ description ]
- 노랑 점 : 사람
- 보라 점들 : whisper models 점수
- 파랑 점들 : 기존 models 점수
- 좌 상단에 있을수록 robust 하지 못한 모델
보다시피, Whisper 모델의 성능 지표가 사람이 기록한 성능지표와 가장 유사하였다.
3.5. multilingual speech recognition
whisper 는 다국적 언어에 대해서도 speech recognition task 를 수행하도록 만들어진 multitask model 이다.
따라서 14 개 정도의 언어를 포함하는 두개의 dataset, MLS & VoxPopuli 에 대해 여러 multilingual model 과 성능 비교를 진행하였다.
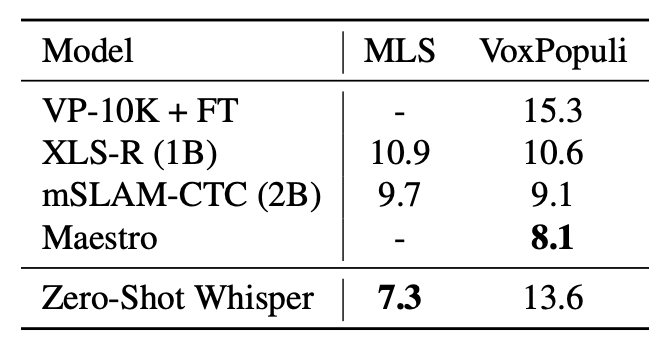
아쉽지만, whisper 가 몇몇 모델보다 낮은 성능을 보였다.
whisper 보다 성능이 좋은 모델들은 pre train 과정에서 해당 dataset 의 distribution 을 이미 학습했기 때문에, zero-shot evaluation 이 제대로 적용되지 못하였다고 볼 수 있다.
아쉽지만 (?) whisper 만큼 다양한 언어 (75 개 +) 에 대해 speech recognition 을 동시 수행할 수 있는 모델이 없어서 성능비교가 어렵기 때문에, 각 언어별로 whisper 가 학습한 pre-train data 의 절대적인 양과 whisper 의 해당 언어별 WER 간의 상관관계를 파악해보니 R^2 = 0.84 정도로 높은 상관관계 보임.
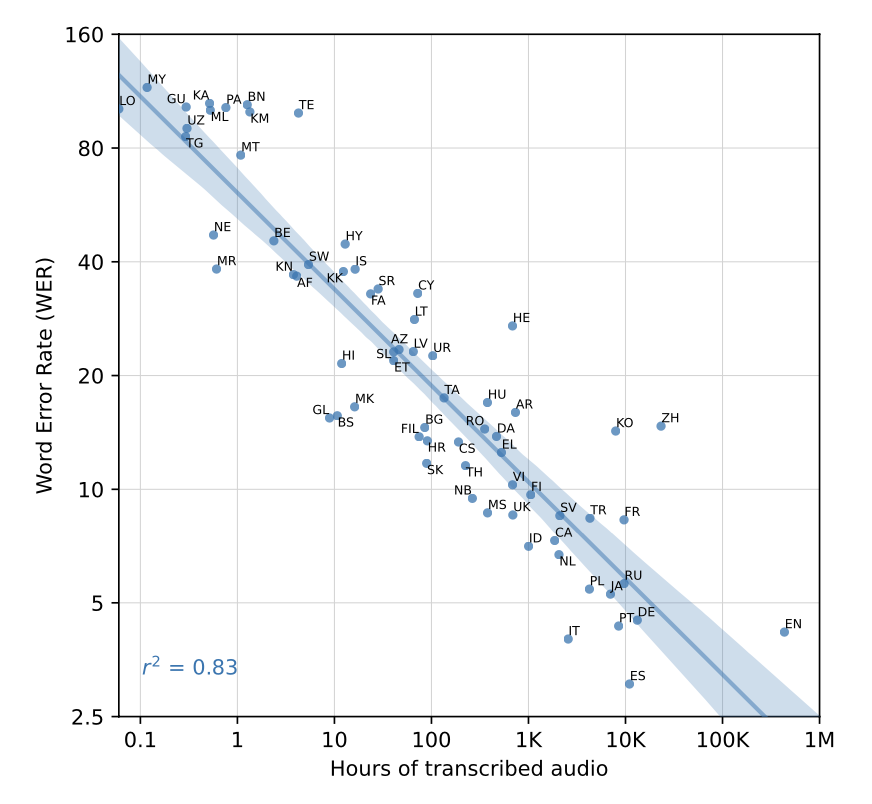
[ description ]
- x 축 : pre train dataset 의 크기 ( log 10 )
- y 축 : WER ( log 2 )
- point : 각 언어
여기서 연구진들은 매우 흥미로운 결과를 도출하는데, WER 은 training data 가 16 배 씩 늘어날 때마다 1/2 배 감소한다. 라는 것이다. 이 결과가 general 하게 적용될 수 있는 건 아니겠지만, 비슷한 모델을 설계하는 사람들에게 큰 도움이 될 수 있을 것 같다.
이 외에도 whisper 는 매우 다양한 task, 예를 들어 voice activity detection 이나 translation 과 같은 task 를 수행하지만 가장 중요한 task 인 transcript 까지의 whisper 논문에 대한 리뷰를 마치도록 하겠다. (절대 귀찮아서가 아니다..... )
p.s.
Whisper 논문은 회사에서 논문 리뷰 세션을 진행하기 위해 제대로 읽어본 몇 안되는 논문 중 하나였는데, open AI 연구진들이 문제를 정의하고 이를 해결하기 위한 방법을 설계해나가는 과정이 매우 흥미로웠던 것 같다.
기존에 사람들이 관습처럼 행해오던 방법론을 하나씩 깨나가면서 더 좋은 해결책을 만들어나가는 것, 어쩌면 생각보다 훨씬 큰 용기가 필요하고 여러 기회비용을 감수해야 되는 일이겠지만 분명 기술의 발전을 위해서 필요한 일이라고 생각한다.

글 재미있게 봤습니다.