
NoSQL?
NoSQL(원래 의미: non SQL 또는 non relational)
데이터베이스는 전통적인 관계형 데이터베이스 보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공한다.
NoSQL 데이터베이스는 단순 검색 및 추가 작업을 위한 매우 최적화된 키 값 저장 공간이다.
Redis란?
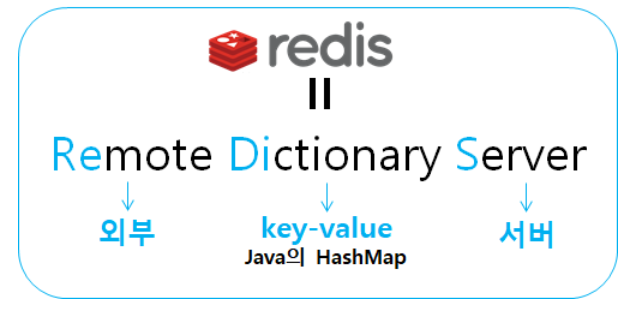
Redis의 풀네임에서 알 수 있듯이 dictionary 구조, 한마디로 key-value 형태로 데이터를 저장하고 관리하는 서버를 말합니다.
Cache
Cache란 나중에 요청할 결과를 미리 저장해둔 후 빠르게 서비스해 주는 것을 의미한다. 즉, 미리 결과를 저장하고 나중에 요청이 오면 그 요청에 대해서 DB 또는 API를 참조하지 않고 Cache를 접근하여 요청을 처리하는 기법이다. 이러한 cache가 나온 배경에는 파레토 법칙이 있다.
파레토 법칙이란 80%의 결과는 20%의 원인으로 인해 발생한다는 뜻이다.
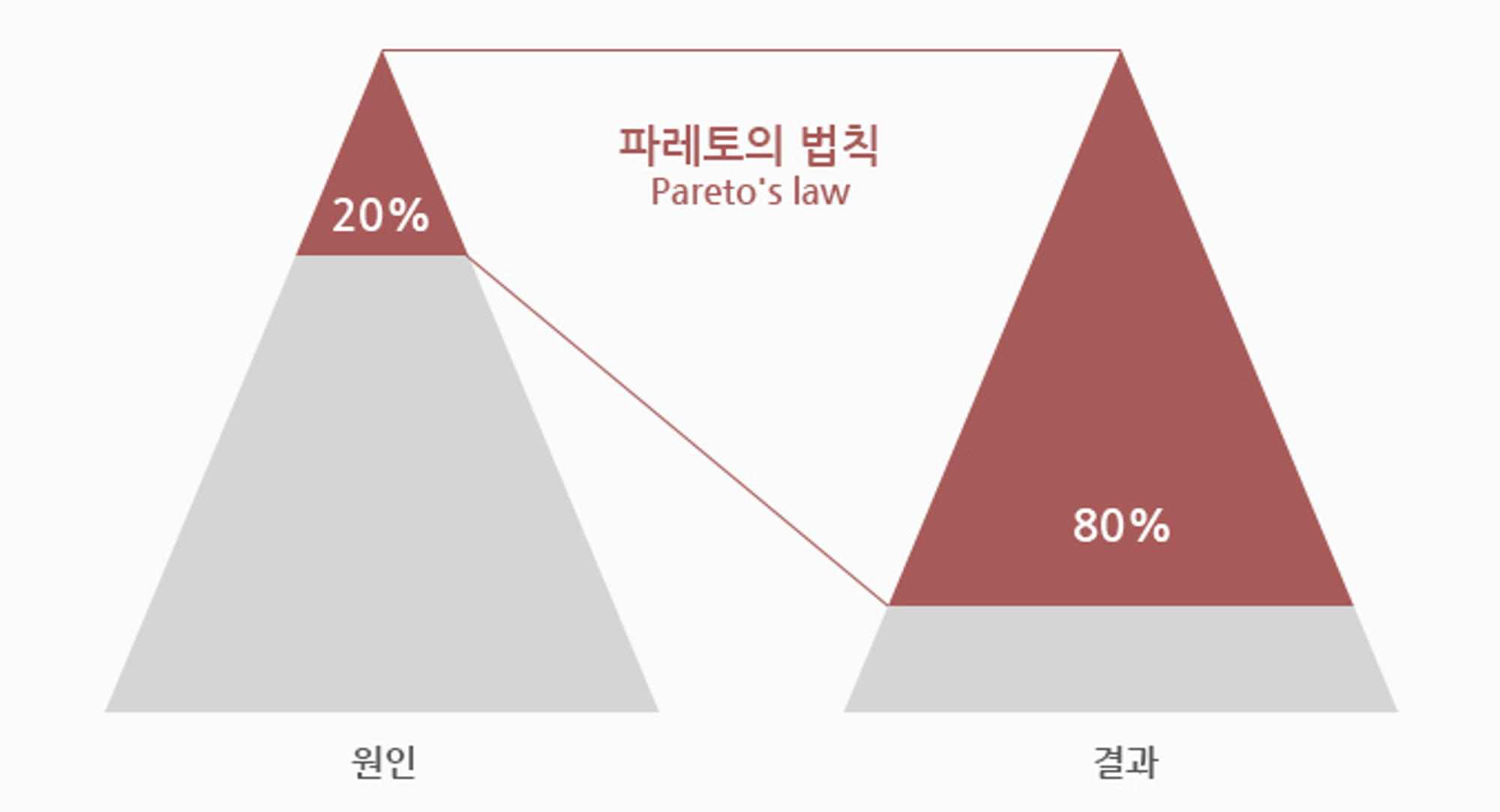
Cachce 사용 구조
look aside cache
look aside cache은 cache에 접근하여 데이터가 존재하는지 판단하고 cache에 존재하지 않는다면 db, api를 호출합니다. 대부분 cache를 사용한 개발이 이 프로세스를 따르고 있습니다.
- 캐시에 데이터 존재 유무 확인
- 데이터가 있다면 캐시의 데이터 사용
- 데이터가 없다면 캐시의 실제 DB 데이터 사용
- DB에서 가져 온 데이터를 캐시에 저장
write back
- 모든 데이터를 캐시에 저장
- 캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장 (배치)
- DB에 저장한 데이터를 캐시에서 제거
write back은 주로 쓰기 작업이 굉장히 많아서, INSERT 쿼리를 일일이 날리지 않고 한꺼번에 배치 처리를 하기 위해 사용한다.
DB에서 디스크를 접근하는 횟수가 줄어들기 때문에 성능 향상을 기대할 수 있지만, DB에 데이터를 저장하기 전에 캐시 서버가 죽으면 데이터가 유실된다는 문제점이 있다.
인메모리?
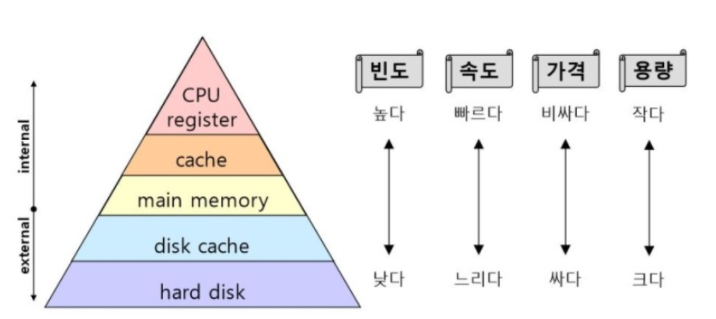
장점
- 컴퓨터의 주기억장치인 RAM에 데이터를 올려서 사용한다.
- RAM에 데이터를 저장하여 메모리 내부에서 처리가 되므로 데이터를 저장하고 조회할 때 하드디스크를 오고 가는 과정을 거치지 않아도 된다.
- 그래서 속도가 매우 빠르다.
단점
- 용량으로 인해 데이터 유실이 발생할 수 있다!
Redis는 인메모리 방식이므로 서버의 메모리 용량을 초과하는 데이터를 redis에서 처리할 경우, 서버 자체에도 문제가 생기며, RAM의 특성인 휘발성에 따라 RAM에 저장되었던 레디스의 데이터들은 유실될 수 있습니다. 때문에 메인 DB로 사용하기에는 무리가 있습니다.
Redis 특징
- List, Set, Sorted Set, Hash 등과 같은 Collection을 지원함.
- 영속성을 지원하는 인 메모리 데이터 저장소
- 다양한 자료 구조를 지원함.
- 싱글 스레드 방식으로 인해 연산을 원자적으로 수행이 가능함.
- 읽기 성능 증대를 위한 서버 측 리플리케이션을 지원
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
- 다양한 서비스에서 사용되며 검증된 기술
Redis의 영속성
Redis는 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있다. 서버가 내려가더라도 디스크에 저장된 데이터를 읽어서 메모리에 로딩한다. 데이터를 디스크에 저장하는 방식은 크게 두 가지가 있다.
- RDB(Snapshotting) 방식
- 순간적으로 메모리에 있는 내용 전체를 디스크에 옮겨 담는 방식
- AOF(Append On File) 방식
- Redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태
싱글 스레드를 사용하는 Redis
Redis는 싱글 스레드를 사용하므로 연산을 원자적으로 처리하여 Race Condition이 거의 발생하지 않는다. 예를 들어, 친구 리스트의 친구를 추가하는 연산을 시도해 보자. 아래와 같이 정상적인 상황에서는 유저 각각의 트랜잭션이 순서대로 잘 행해지고 있으므로 문제가 없다.

그러나 동시에 친구 리스트에 B,C를 추가하면 어떨까?

두 트랜잭션이 동일한 최종 상태인 A를 자신의 메모리로 읽어 들이고, 그 상태에서 각자 B 또는 C를 추가하게되면 최종 상태가 (A, B) 혹은 (A, C)가 된다. (A, B) 혹은 (A, C)라고 한 이유는 컨텍스트 스위칭에 따라 두 트랜잭션 중 누가 먼저 끝날 지 예측할 수 없기 때문이다.
이러한 Race Condition을 해결하기 위해 여러 가지 기법이 있지만, Redis는 싱글 스레드를 사용하므로 하나의 트랜잭션은 하나의 명령만 실행할 수 있으므로 다수의 Race Condiotion을 해결할 수 있다.
