Numpy의 ndarray를 활용하면 다양한 데이터를 행렬이나 벡터로 변환할 수 있다.
1) Table, Spreadsheet
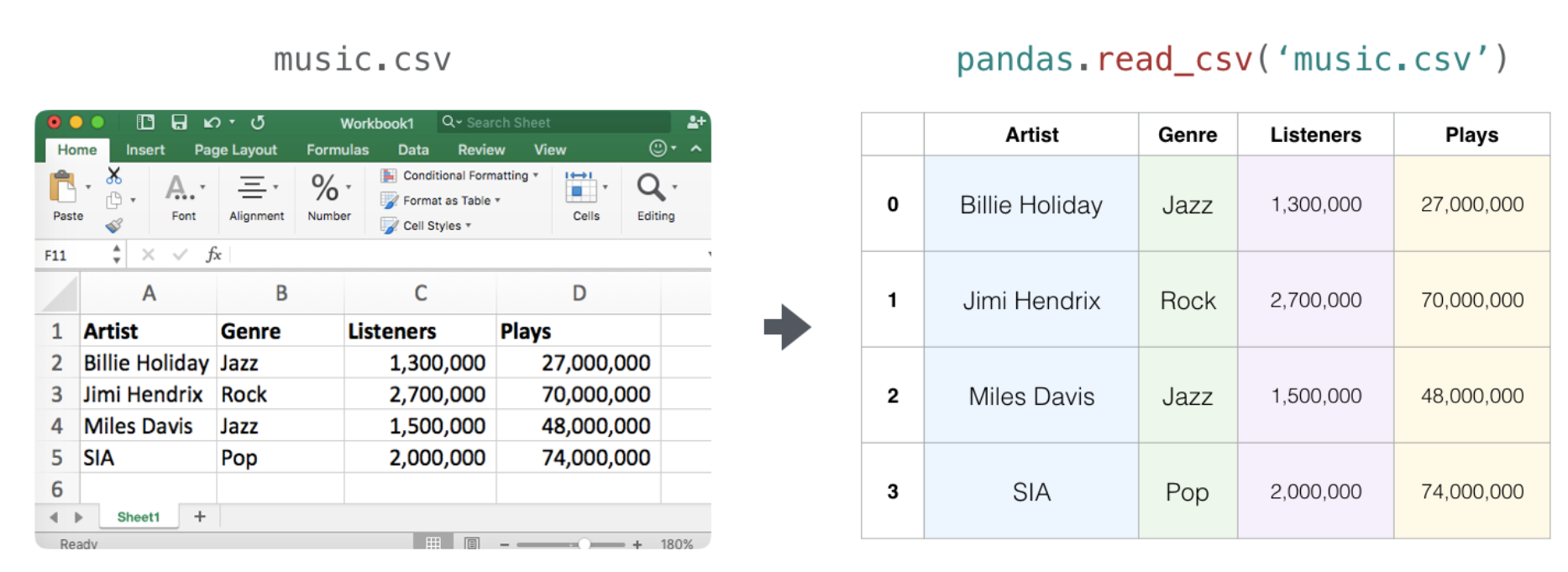
- pandas의 DataFrame 데이터 타입으로 변환할 수 있다.
2) Audio, 시계열 데이터
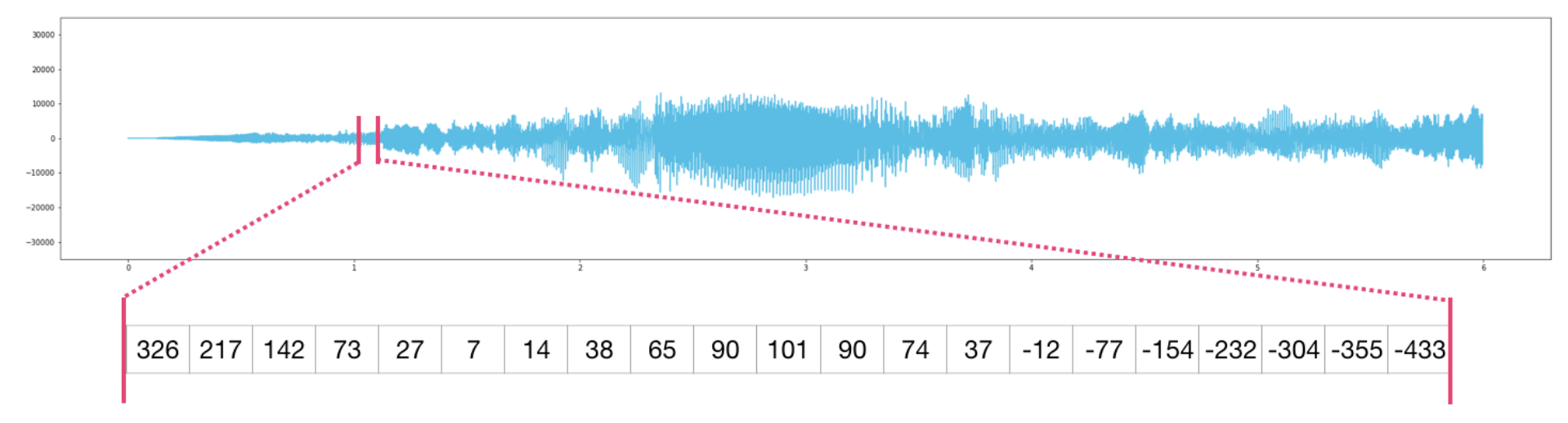
- 위와 같이 1차원 배열로 표현할 수 있다.
- .wave 확장자를 가진 44.1kHz 레이팅의 음원 파일은 각각 -32767 ~ 32768 사이의 값을 가진 배열로 표현된다.
- 샘플링 레이팅이 44.1kHz이므로 10초 길이의 음원은 총 441,000 개의 데이터를 갖는다.
(e.g. 첫 1초의 오디오 데이터에 접근하려면audio[:44100]을 사용) - 시계열 데이터도 마찬가지 방식으로 표현할 수 있다.
3-1) 흑백 이미지 데이터 (grayscale)
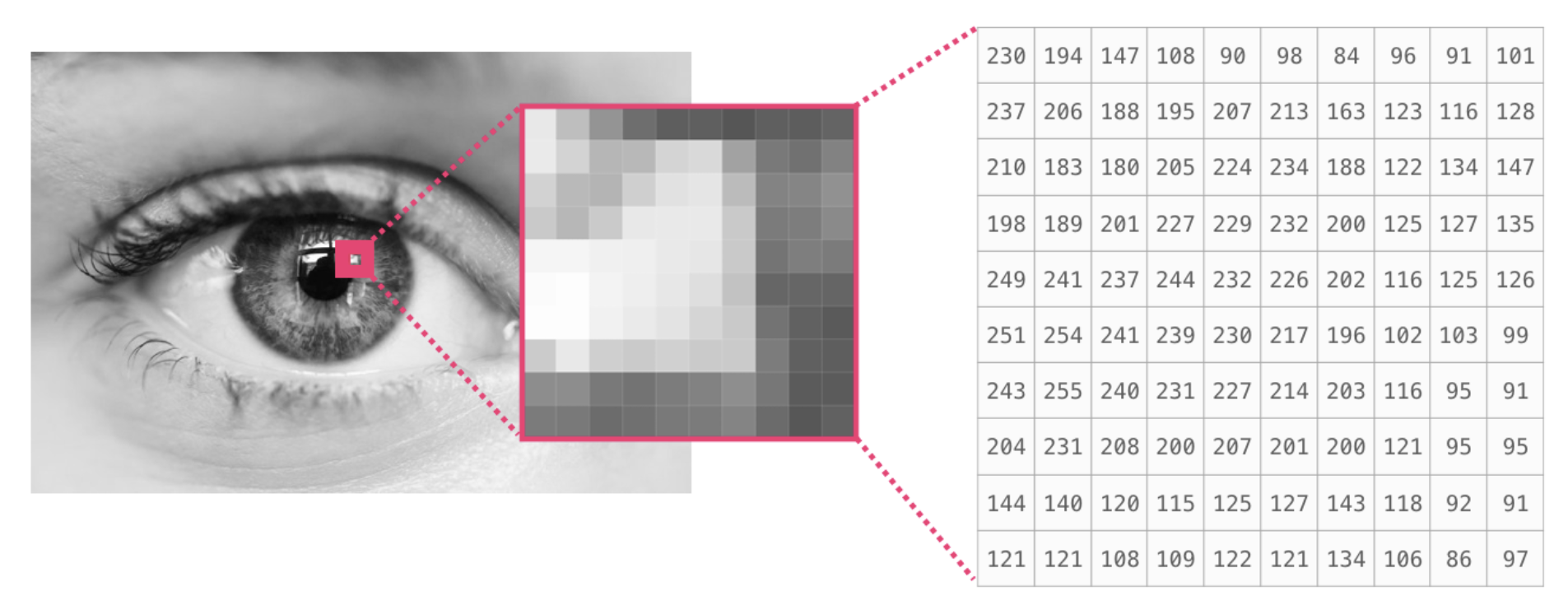
- 픽셀 사이즈에 기반한 2차원 행렬로 표현할 수 있다. (height * width)
- 일반적으로 각 픽셀은 0(black)부터 255(white) 사이의 값을 갖는다.
(e.g.image[:10, :10]: 전체 이미지에서 좌상단 10x10 크기의 이미지 crop)
3-2) 컬러 이미지 데이터
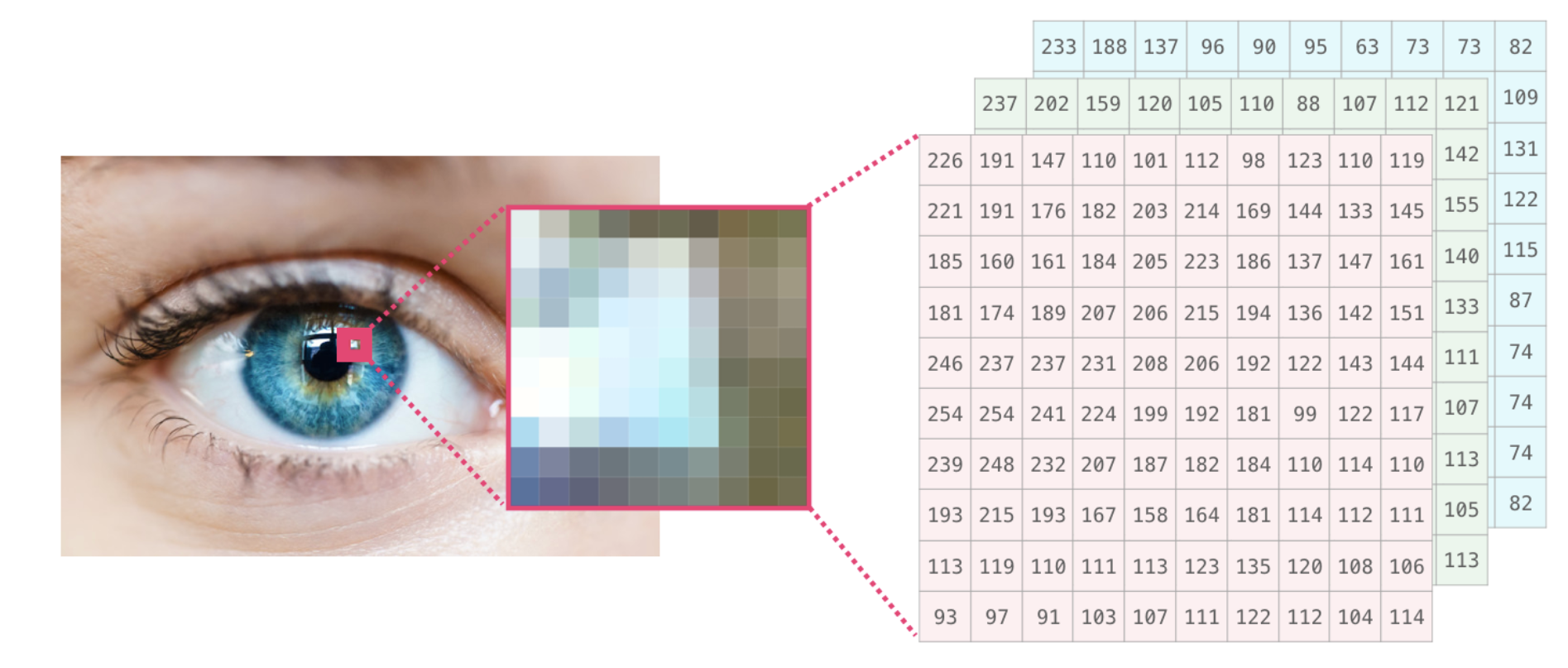
- 컬러 이미지는 흑백 이미지 데이터에 R, G, B를 표현하는 채널 값이 추가된다.
- 따라서 3차원 배열 데이터의 구조를 갖는다.
4) 자연어 처리 (NLP)

- 자연어 처리는 '분포 가설'에 따른 임베딩 과정을 거친다.
- 일반적으로 각 단어를
token이라는 객체로 변환하고, 해당 토큰과 인덱스를 1:1 매칭시킨 '단어사전'을 만들어 사용한다.

- 해당 단어사전을 기반으로 위와 같은 문장을 아래와 같이 인덱스로 대치시킨다.

- 하지만 위와 같은 단어 인덱스는 엄밀히 말해 컴퓨터가 '알아듣지 못하는' 데이터이므로 아래와 같이 단어 벡터 값으로 변환한다.
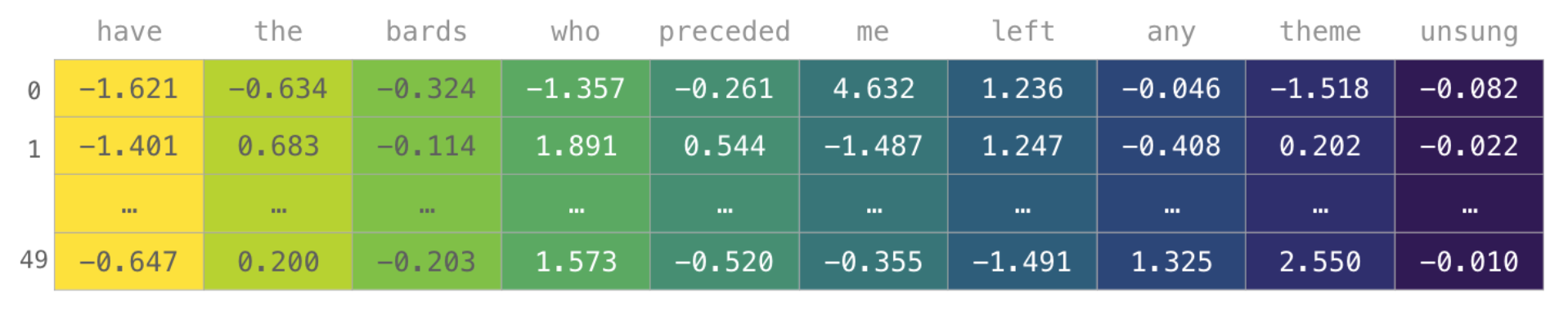
-
변환된 단어 벡터는 코사인 유사도 등을 통해 추론에 사용할 수 있게 된다.
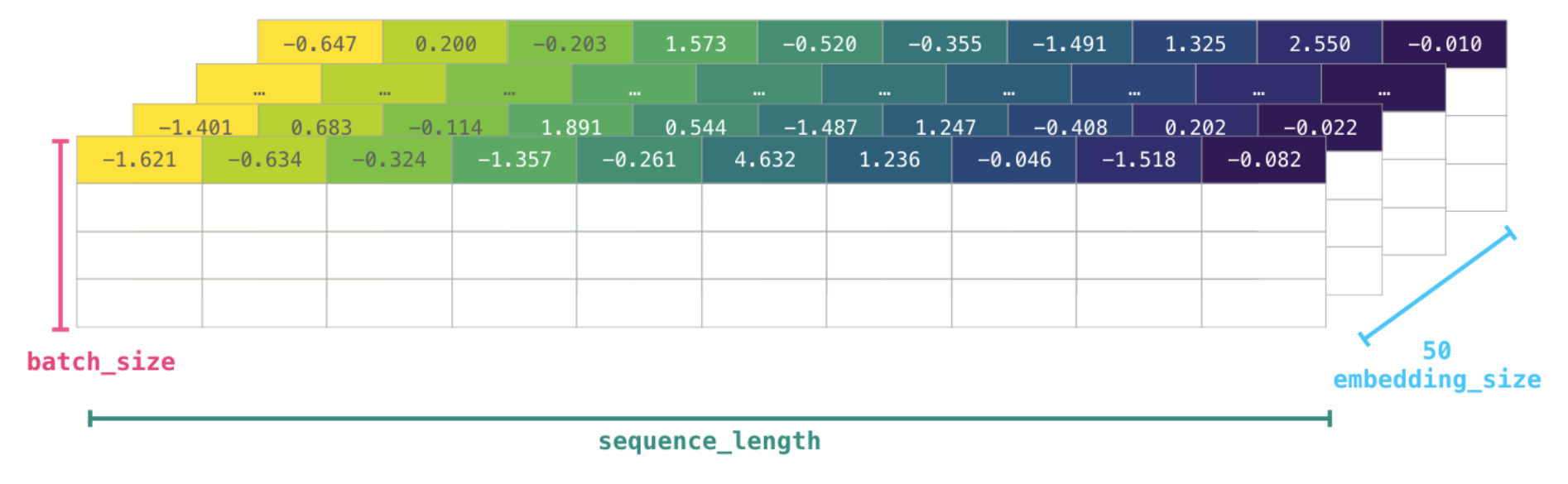
-
BERT같은 모델은 아래와 같은 shape를 가진 데이터로 예측을 진행한다.

재미있게 살고 싶은 대학원생