😂 머신러닝
😭 CNN 실습
- 이전 실습에서 활용했던
sign-language-mnist데이터셋을 다시 활용해 실습을 진행해 보았다. - 우선 kaggle에서 데이터를 받아 사용했기 때문에 나의 토큰값을 입력해주면 된다.
- 그 다음으로 사용할 데이터셋을 받아와 unzip 해주도록 하겠다.
!kaggle datasets download -d datamunge/sign-language-mnist
!unzip sign-language-mnist.zip- 이번 실습에서 사용하게 될 패키지를 import하도록 하겠다.
- 이전 실습과 달리 아래의 패키지들을 추가적으로 사용하였다.
Conv2D: convolution 연산 진행MaxPooling2D: sub-sampling에 사용Flatten: 2차원의 데이터를 1차원으로 펴주기 위해 사용ImageDataGenerator: image augmentation 진행
- 이전 실습과 달리 아래의 패키지들을 추가적으로 사용하였다.
from tensorflow.keras.models import Model
# conv2D : convolution 연산 / MaxPooling2D : sub-sampling에 사용/ Flatten : 2차원을 1차원으로 만듦
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
# ImageDataGenerator : image augmentation 진행
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder- 사용할 패키지까지 import하고 난 뒤, 여느때와 같이 내가 사용할 데이터셋들의 구성을 확인하도록 하겠다.
- 두 데이터셋 모두 잘 들어와 있는 것을 확인할 수 있고, 테이블의 크기가 같은 것을 보아 두 데이터셋의 모양을 맞추기 위한 reshape은 진행하지 않아도 무방할 것이라는 생각이 든다.
train_df = pd.read_csv('sign_mnist_train.csv')
train_df.head() # 기본 5개로 나옴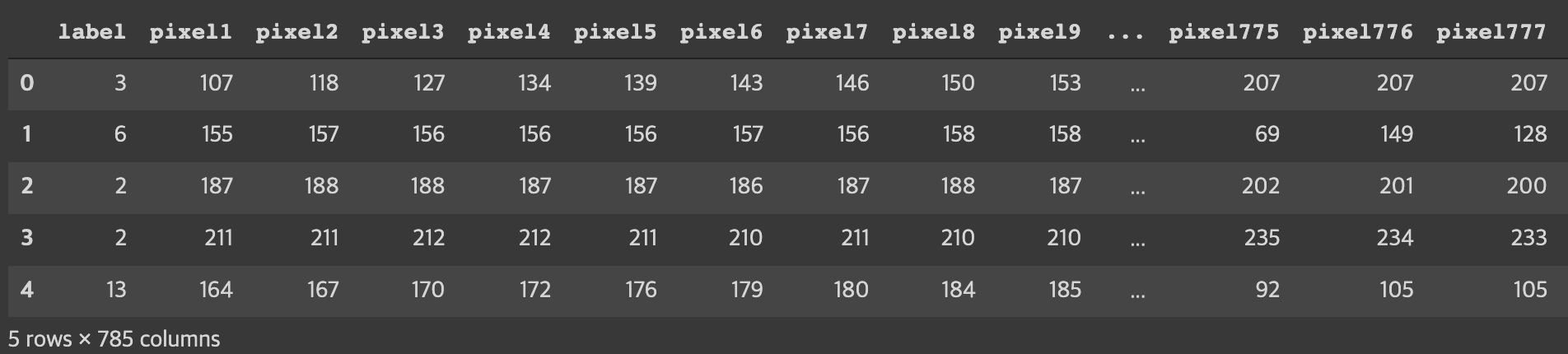
test_df = pd.read_csv('sign_mnist_test.csv')
test_df.head()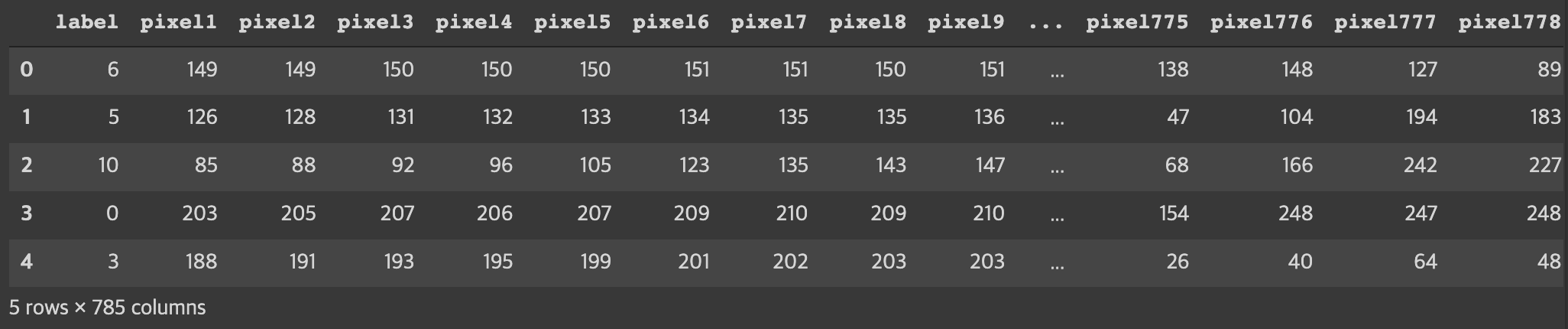
- 우리가 결과적으로 제시해야 하는 것은 이미지에 맞는
알파벳이기 때문에 어떻게 구성되어 있는지그래프를 통해 확인해보도록 하겠다.- seaborn의 sns를 사용하였고,
countplot을 사용해 각 요소별 개수를 확인하였다. 9=J와 25=Z는 동작이 들어가 제외되었으므로 24개가 잘 나온 것을 알 수 있다.
- seaborn의 sns를 사용하였고,
plt.figure(figsize=(16, 10)) # plot의 사이즈
sns.countplot(train_df['label'])
plt.show()
- 데이터를 다 확인하였으니, 데이터에 대한 전처리를 진행하도록 하겠다.
우선, 각 train data와 test data를 나누어 보도록 하겠다.x_train.reshape((-1, 28, 28, 1))의 경우, convolution 연산에 필요한 2차원 데이터를 만들기 위해 reshape을 통해 3차원의 데이터를 만들어 준 것이다.- x_train.reshape((데이터 크기, 이미지 크기, 이미지 크기, 그레이 스케일 이미지=1))
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
# convolution 연산을 하려면 2차원의 데이터가 필요하기 때문에 reshape을 통해 3차원 데이터를 생성해줌!
# x_train = x_train.reshape((데이터 크기, 이미지 크기, 이미지 크기, 그레이 스케일 이미지라서 1))
x_train = x_train.reshape((-1, 28, 28, 1))
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
x_test = x_test.reshape((-1, 28, 28, 1))
y_test = test_df[['label']].values
print(x_train.shape, y_train.shape) # (27455, 28, 28, 1) (27455, 1)
print(x_test.shape, y_test.shape) # (7172, 28, 28, 1) (7172, 1)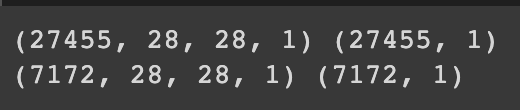
- 데이터가 어떤 형식으로 출력되는지 확인해보도록 하겠다.
index = 1
# y_train의 값을 해당 그림의 타이틀로 지정하고
plt.title(str(y_train[index]))
# x_train의 값을 이미지 형태로 바꿔서 그레이 스케일로 보여줘라
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
plt.show()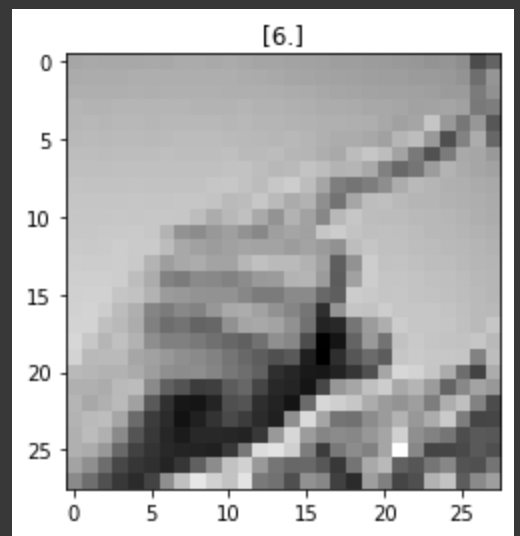
- 결과값인
label을 의미하는 y 값에 대한OneHotEncoding을 진행하도록 하겠다.- 알파벳의 개수가 24개이기 때문에 shape에 24가 나온다.
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
y_test = encoder.fit_transform(y_test).toarray()
print(y_train.shape) # (27455, 24)- 일반화를 진행하도록 하겠다.
- 이전 실습과 다르게
ImageDataGenerator를 사용해 일반화를 진행하였다. 이미지 데이터의 픽셀이 0~255 사이의 정수로 되어 있기 때문에 255를 나눠 이미지 데이터의 픽셀값이0~1사이에 있도록 조정하였다. - 위에서 진행한
OneHotEncoding으로 인해 label의 값이 변한 것을 알 수 있으며,shuffle을 적용했기 때문에 매번 코드를 실행할 때마다 다른 종류의 이미지가 나오는 것을 알 수 있다. ImageDataGenerator의__getitem__method를 통해 이미지를 미리보기할 수 있다.
- 이전 실습과 다르게
# 저번과 다르게 ImageDataGenerator를 사용해 더 쉽게 일반화를 할 것이며
# 모든 이미지 데이터의 픽셀을 255로 나누어 rescale할 것이다.
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
)
# datagen = data generator
# flow 라는 method를 사용해서 각각의 데이터를 입력해 준다.
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
# batch size를 256으로 작게 나누어 학습시키겠다.
batch_size=256,
# 27455개의 train data를 셔플링해준다. -> 약간의 성능 향상에 도움을 준다.
# train data를 통해 model을 학습시키기 때문에 모델의 성능 향상을 위해 여기서는 shuffle을 해준다.
shuffle=True
)
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
# 랜덤성을 주지 않는다. 성능 향상을 위한 데이터가 아닌 모델의 테스트를 위한 것이라 굳이 shuffle을 주진 않는다.
shuffle=False
)
index = 1
# ImageDataGenerator에서는 __getitem__ 라는 method를 통해 이미지 미리보기가 가능하다.
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label)) # OneHotEncoding이 진행된 라벨을 보여줌
plt.show() # show()할 때마다 train_datagen의 shuffle로 인해 랜덤한 그림이 나온다. 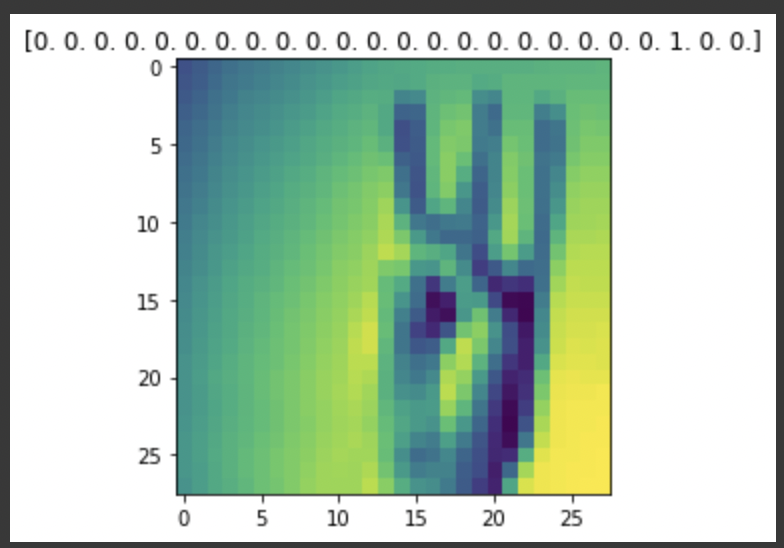
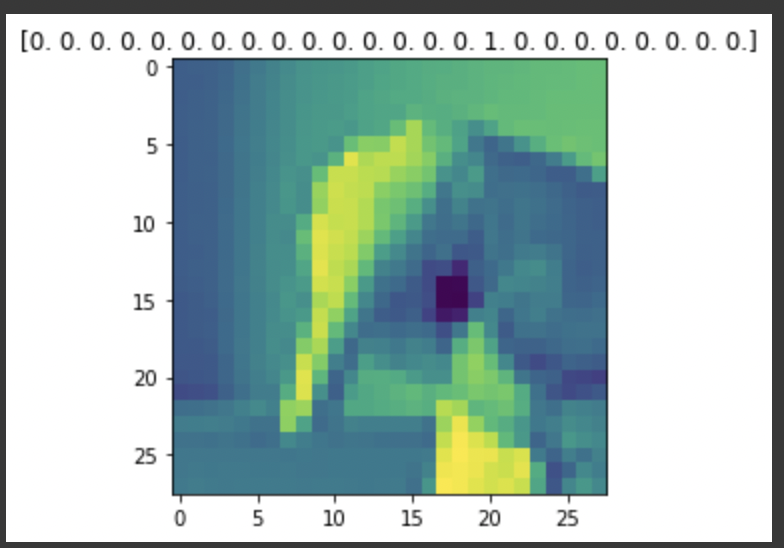
- 그 다음으로 CNN의 네트워크를 구성하도록 하겠다.
Conv2D와 MaxPooling2D는 세트로 진행되고 있다. 해당 계산이 끝나게 되면 Dense layer에서의 계산을 위해Flatten으로 1차원 값을 만들어 준다.filter의 값은 정해진 것이 아니라 튜닝을 하면서 맞춰가는 것이다.output에서는 우리가 반환하는 알파벳이 24가지이기 때문에 Dense layer에 24를 넣어줘야 한다.
input = Input(shape=(28, 28, 1))
# 간단하게 CNN 적용하기^^
# Conv2D로 convolution 연산을 진행하는데, 필터의 개수는 32개, kernel의 사이즈(필터 크기)는 3x3인데 줄여서 3이라 함
# strides(한 번에 필터가 옮겨가는 크기)는 1, padding을 똑같이 주어 input과 output의 featuremap의 크기를 똑같게 하라
# 활성화 함수로는 Relu 사용
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
# Conv2D를 사용하게 되면, MaxpPooling2D를 거쳐야 됨
# pool_size와 strides를 사용해서 차원을 절반으로 줄여줌
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
# 위와 같은 과정이지만, filter의 개수는 다름 -> 튜닝하면서 맞춰가야 되는 부분
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
# Dense layer와의 연산이 필요하므로 위의 hidden을 1차원으로 펴줘야 한다. 그래서 Flatten 사용!
hidden = Flatten()(hidden)
# fully connected layer인 Dense layer는 512개의 노드를 가지고 있으며, 활성화 함수는 relu 사용
hidden = Dense(512, activation='relu')(hidden)
# overfitting을 피하기 위해서 Dropout을 사용하게 된다.
# 30%의 노드를 랜덤으로 빼준다(탈락시킨다).
hidden = Dropout(rate=0.3)(hidden)
# 알파벳 24개
output = Dense(24, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
# softmax 함수를 사용했으므로 categorical_crossentropy 사용
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()
# 3*3*32 = 288
# dropout 에서는 trainable parameter가 없음을 알 수 있다.
# Dense layer의 개수를 줄일수록 parameter의 크기를 줄일 수 있다. 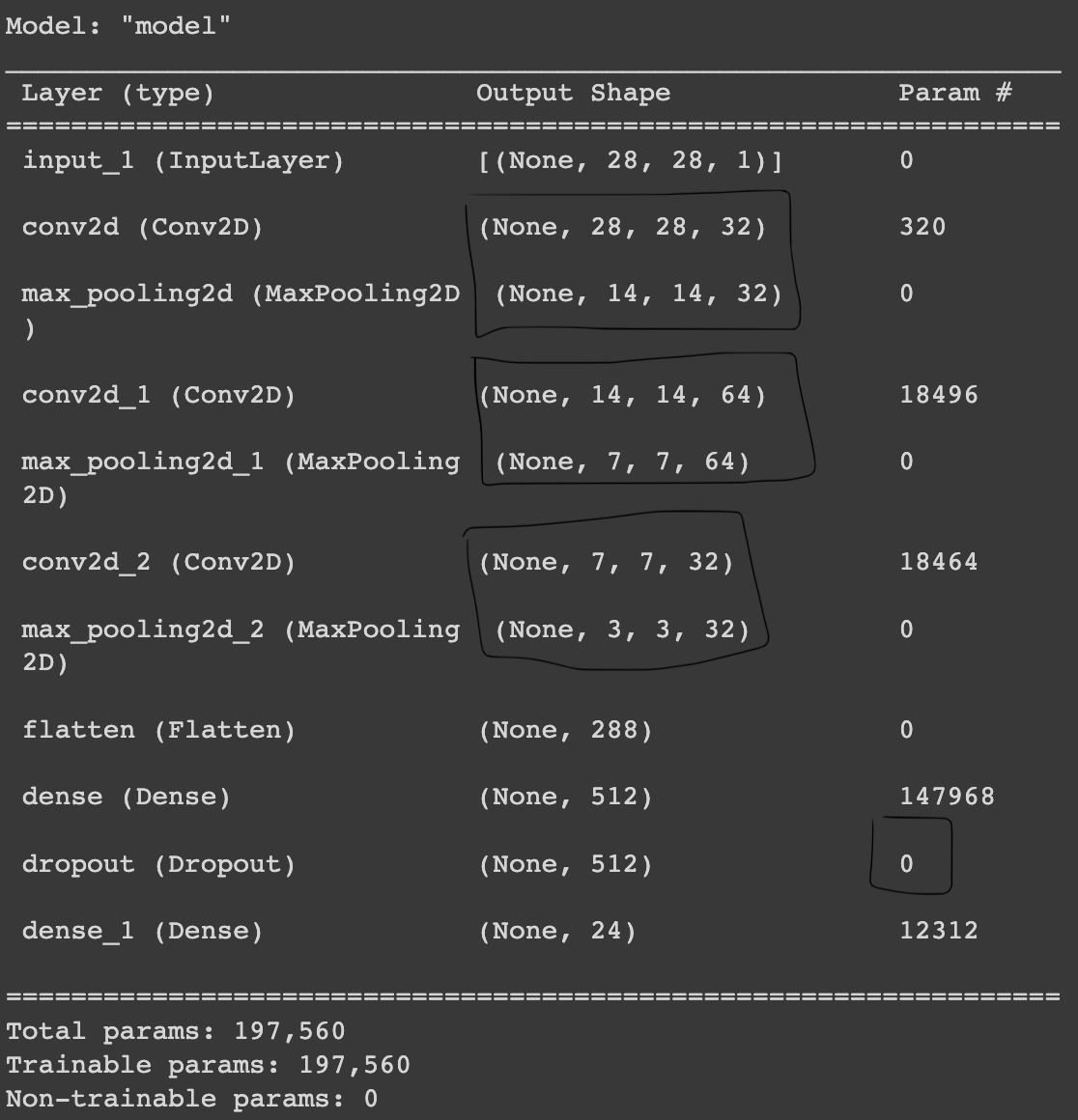
- 위의 정보들을 바탕으로 모델을 학습시키도록 하겠다.
history = model.fit(
train_datagen,
validation_data=test_datagen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
# val_acc: 0.9559 로 정확도가 괜찮게 나옴!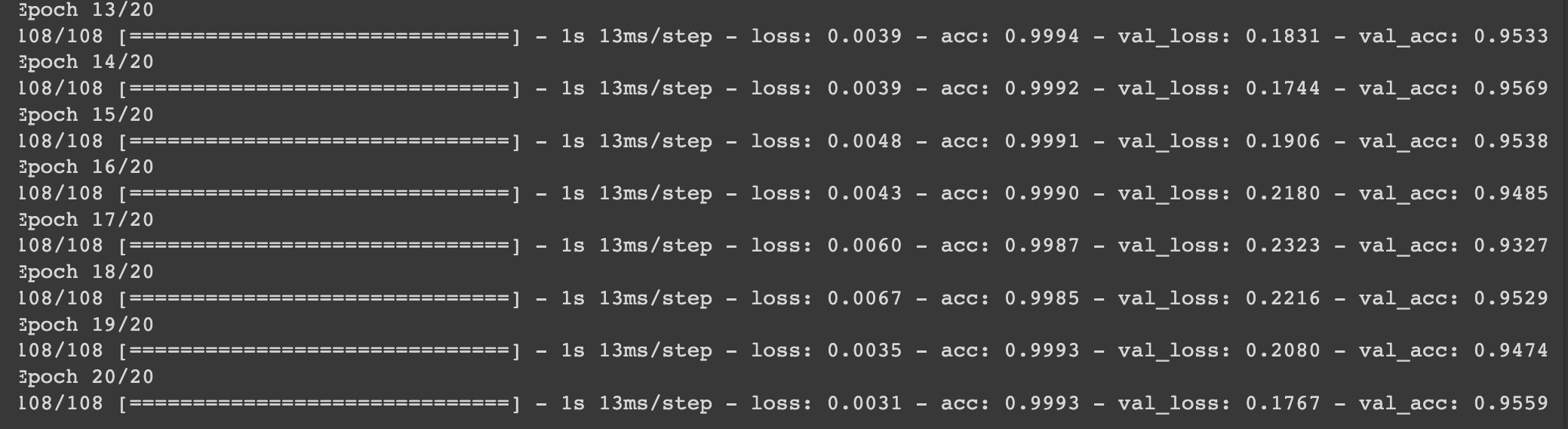
- 그래프를 그려 loss와 acc를 확인해보도록 하겠다.
fig, axes = plt.subplots(1, 2, figsize=(20, 6))
axes[0].plot(history.history['loss']) # 파랑
axes[0].plot(history.history['val_loss']) # 주황
axes[1].plot(history.history['acc'])
axes[1].plot(history.history['val_acc'])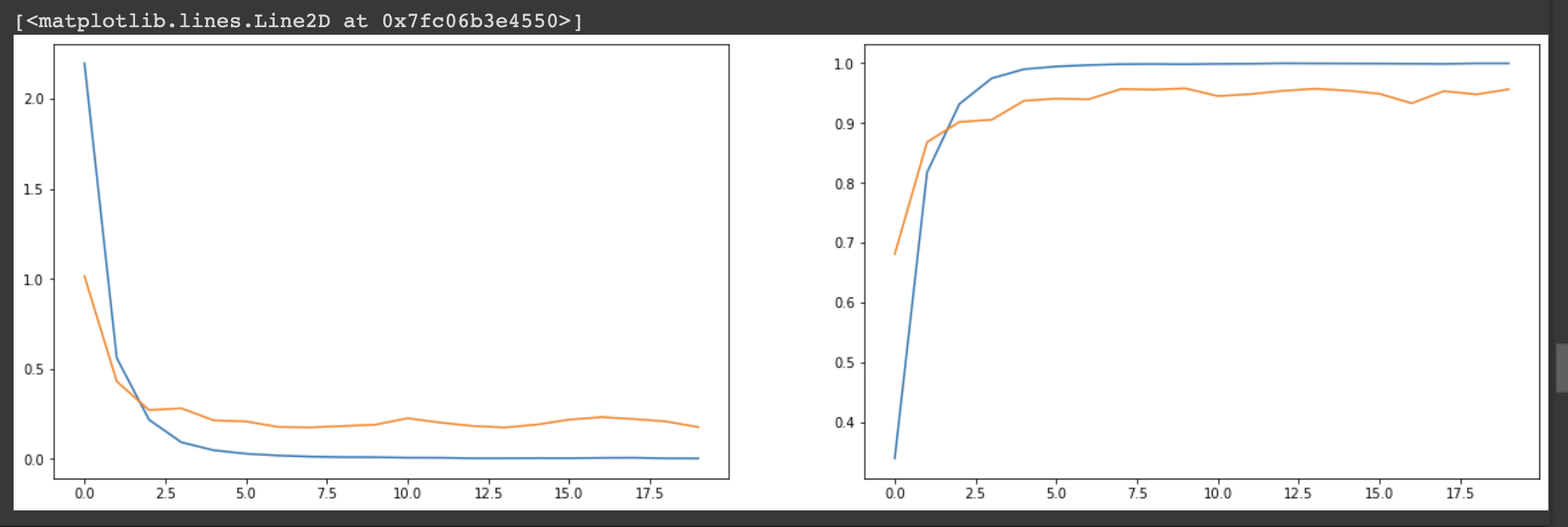
😭 이미지 증강기법 실습
- 위의 실습과 동일한 데이터셋을 사용하며, 이미지를 그대로 사용하는 것과
image augmentation기법을 사용하는 것 중 어느 것의 정확도가 더 높은지 판단해보도록 하겠다. image augmentation을 적용하도록 하겠다.
# ImageDataGenerator에서 imgae augmentation을 쉽게 할 수 있다.
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # -10도에서 10도까지 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 0~10%까지 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 0~10%까지 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 0~10%까지 랜덤하게 이미지를 수직으로 이동 (%)
)
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
shuffle=True
)
# 검증에는 augmentation이 들어갈 필요가 크게 없다. 만약 들어가면 검증을 할 때마다 결과가 다르게 나오게 된다.
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False
)
index = 1
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label))
plt.show()
- 네트워크는 CNN 실습과 동일하게 구성한다.
input = Input(shape=(28, 28, 1))
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Flatten()(hidden)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dropout(rate=0.3)(hidden)
output = Dense(24, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()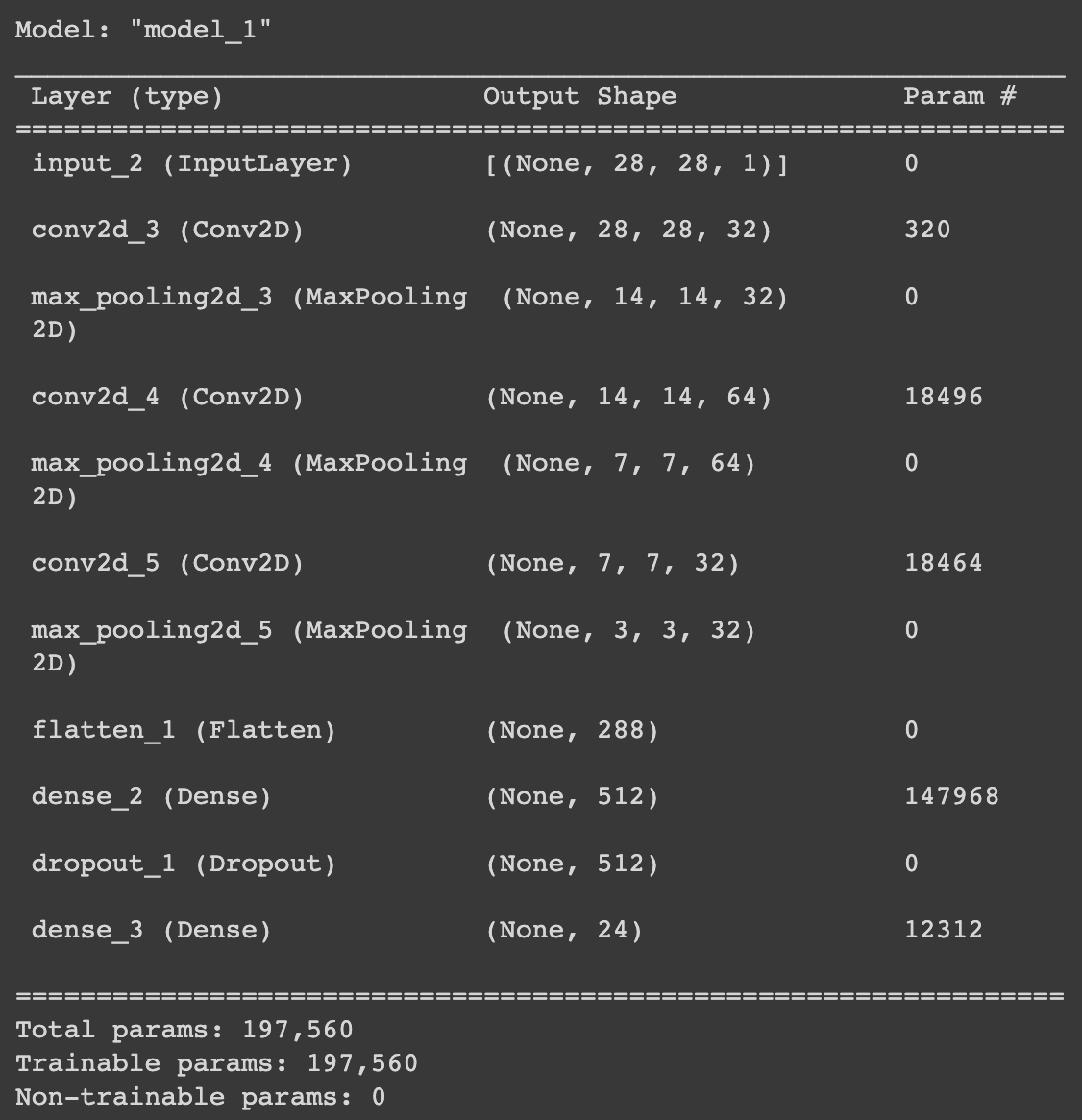
- 위의 정보들을 바탕으로 모델을 학습시키도록 하겠다.
history = model.fit(
train_datagen,
validation_data=test_datagen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
# data augmentation을 통해 95.59 -> 99.05로 정확도를 올릴 수 있게 되었다. 
- 마지막으로 모델의 loss와 acc를 그래프를 통해 확인하도록 하겠다. 보다시피, 이전 실습보다 정확도 측면에서 더 좋은 성능을 보이는 것을 알 수 있다.
fig, axes = plt.subplots(1, 2, figsize=(20, 6))
axes[0].plot(history.history['loss'])
axes[0].plot(history.history['val_loss'])
axes[1].plot(history.history['acc'])
axes[1].plot(history.history['val_acc'])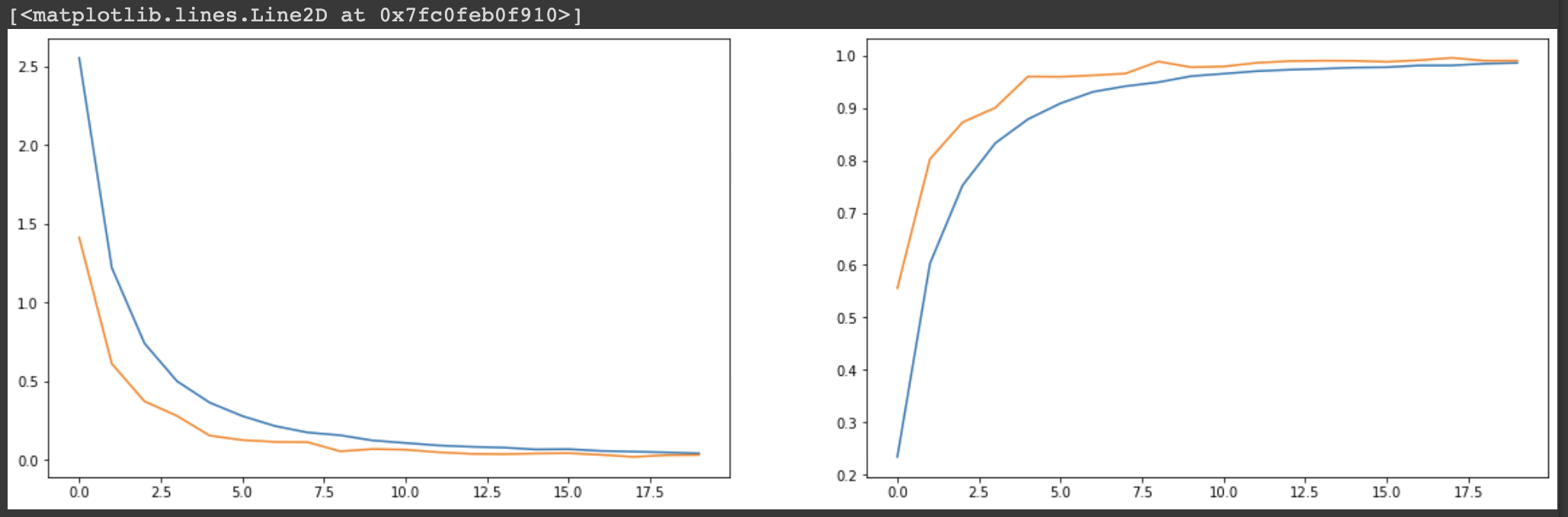
😭 전이학습 실습
- 과일의 종류를 예측하는 실습을 진행해보도록 하겠다.
- 먼저 kaggle에서 가져온 데이터셋의 압축을 풀도록 하겠다.
!kaggle datasets download -d moltean/fruits
# -q : 데이터셋의 크기가 너무 크기 때문에 압축을 푼 것에 대한 결과가 나오지 않도록 조치
!unzip -q fruits.zip- 전이학습에 사용할 패키지를 다운받도록 하겠다.
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoderflow_from_directory메소드를 사용하여 데이터셋이 저장된 폴더에서 직접 데이터를 읽어오도록 하겠다.- 파일이 저장되어 있는 경로를 제대로 설정해주지 않아 오류가 났었다. 주의 필요!
- 테스트셋에 대해서는
augmentation을 하지 않는것을 주의해야 할 것 같다.
train_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # -10도에서 10도까지 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # -10%에서 10%까지 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 10%만큼 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 10%만큼 랜덤하게 이미지를 수직으로 이동 (%)
horizontal_flip=True # 랜덤하게 이미지를 수평으로 뒤집기(좌우반전)
)
# 테스트 결과의 일관성을 지키기 위해서 augmentation은 하지 않고 일반화만 진행
test_datagen = ImageDataGenerator(
rescale=1./255 # 일반화
)
# flow_from_directory : 폴더 안의 이미지들을 자기가 알아서 다 읽어오고 클래스별 분류까지 해줌
train_gen = train_datagen.flow_from_directory(
'fruits-360_dataset/fruits-360/Training',
target_size=(224, 224), # 이미지의 크기(height, width)
batch_size=32,
seed=2021, # 랜덤시드
class_mode='categorical', # 라벨이 여러 개일 때는 categorical 사용, 이진 분류일 때는 binary 사용
shuffle=True # 이미지를 랜덤하게 꺼내줌
)
test_gen = test_datagen.flow_from_directory(
'fruits-360_dataset/fruits-360/Test',
target_size=(224, 224), # 이미지의 크기(height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=False # 테스트를 위한 것이기 때문에 셔플하지 않음
)- pprint를 사용해 train_gen의 각 class를 출력해주면서 각각의 번호를 부여해주었다.
- pprint : 데이터를 보기 좋게 출력해주는 모듈(pretty print)
from pprint import pprint
pprint(train_gen.class_indices) # train_gen의 class 출력. 번호를 각각 매겨줌
- 배치 중 0번 배치를 가져와 이미지와 라벨을 출력해보도록 하겠다.
preview_batch = train_gen.__getitem__(0) # 0번 배치의 아이템들을 가져와라
preview_imgs, preview_labels = preview_batch # 0번 배치의 아이템은 이미지와 라벨로 이루어져 있다.
plt.title(str(preview_labels[0])) # 0번의 라벨은 문자열의 형태로 출력하고 (원핫인코딩 적용되어서 나옴)
plt.imshow(preview_imgs[0]) # 0번 이미지를 imshow를 통해서 출력
# 과일의 이미지가 화면 안에 다 나오지 않고, 좀 회전된 것 같기도 하고 이동한 것 같기도 함 -> augmentation 진행됨
- keras에서 만들어 놓은
InceptionV3모델을 import해와 사용해보도록 하겠다.
# keras에서 만들어 놓은 모델을 사용하게 되면, 이미 학습이 된 pretrained model을 받아서 사용하게 됨
from tensorflow.keras.applications.inception_v3 import InceptionV3
# 이미지의 크기 = 224*224 / color scale을 사용하기 때문에 3
input = Input(shape=(224, 224, 3))
# InceptionV3 모델을 베이스 모델로 사용할 것이다(back-born 모델이라고도 함; 중심이 되는 모델)
# weights는 이미지넷(imagenet)이라는 모델 사용하며, 자동으로 웨이트를 다운받아줌
# include_top : 마지막 출력 레이어를 이미 있는 것으로 사용할 것이냐, 좀 버릴 거냐 -> 우리는 출력 레이어를 우리가 만들 것이기 때문에
# 출력 레이어를 좀 빼고 주세요(False)
# input_tensor : 위에서 정의한 input을 넣어줌
# pooling : max pooling을 사용하는 모델을 쓰겠다.
base_model = InceptionV3(weights='imagenet', include_top=False, input_tensor=input, pooling='max')
# include_top을 False로 주었으니 출력 레이어를 우리의 입맛대로 조정
# base model의 출력값을 x에 저장
x = base_model.output
# x의 값의 25%만큼의 노드를 랜덤으로 버림
x = Dropout(rate=0.25)(x)
# 256개의 Dense layer를 연결해 줄 것이고, relu를 활성화함수로 사용하겠다.
x = Dense(256, activation='relu')(x)
# 마지막에는 클래스의 개수가 131개이고, 다중분류를 하니 softmax 사용
output = Dense(131, activation='softmax')(x)
# inputs에는 base_model의 input을 넣어주면 되고, outputs에는 바로 위의 output 입력
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()- 모델의 학습을 진행하도록 하겠다.
- 학습을 진행한 모델을 저장했다가 다시 쓸 수 있도록 해주는 기능인
ModelCheckpoint를 통해 callback을 정의했다. - 모델을 다 저장하게 되면 colab의 왼쪽 파일 창에 저장한 모델이 생성되게 된다.
- 모델의 선정 기준은
monitor를 통해 저장할 수 있고, 선정 기준을 가장 높게 충족하는 모델 하나만을 저장할 수 있다.
- 학습을 진행한 모델을 저장했다가 다시 쓸 수 있도록 해주는 기능인
# 모델을 저장했다가 다시 로드해서 쓸 수 있는 callback 정의
from tensorflow.keras.callbacks import ModelCheckpoint
history = model.fit(
train_gen,
validation_data=test_gen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20, # epochs 복수형으로 쓰기!
callbacks=[
# ModelCheckpoint를 사용해 모델을 저장하게 되면, 해당 모델의 weights나 network 등을 저장할 수 있음
# validation_accuracy가 가장 높은 하나만을 골라서 저장하게 됨
# verbose=1을 통해서 학습 결과를 출력하라고 함
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
]
)-모델의 학습 결과를 그래프로 표현해 보겠다.
fig, axes = plt.subplots(1, 2, figsize=(20, 6))
axes[0].plot(history.history['loss'])
axes[0].plot(history.history['val_loss'])
axes[1].plot(history.history['acc'])
axes[1].plot(history.history['val_acc'])
# loss와 관련된 값들은 전부 떨어지는 것을 볼 수 있고, acc 관련 값들은 전부 높아지는 것을 볼 수 있음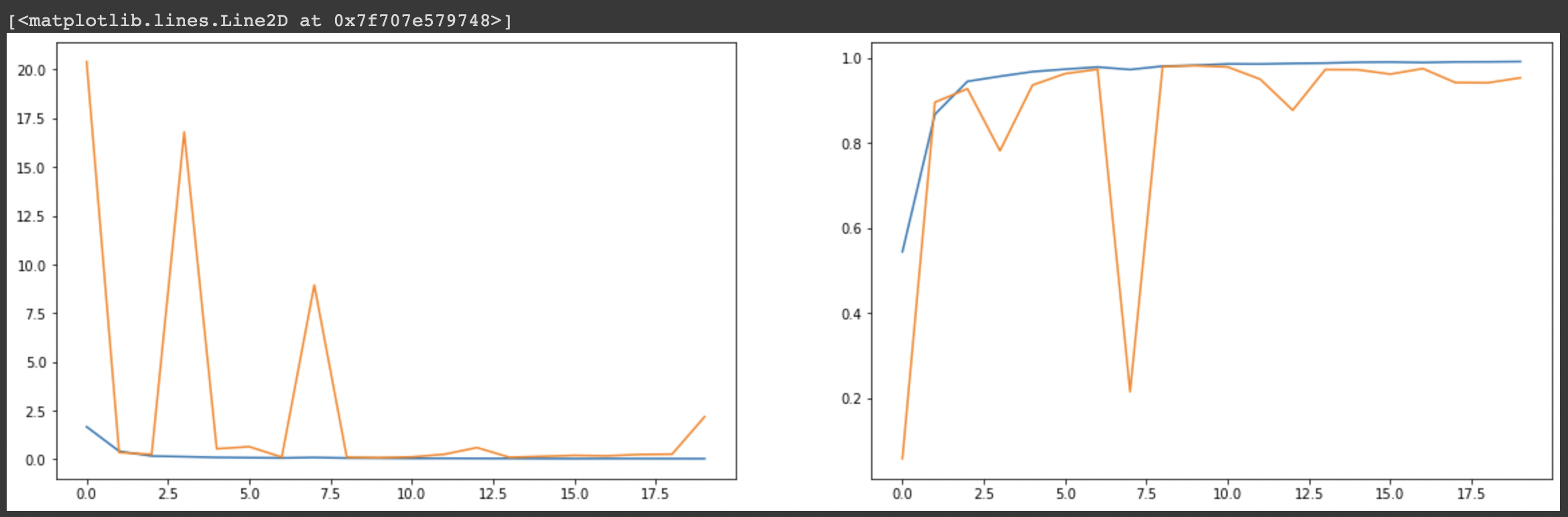
- 앞에서 저장했던 모델을 다음과 같이 불러올 수 있다.
- keras의
load_model을 사용하면 된다.
- keras의
# 학습시켰던 모델이 model.h5에 저장이 되면은 화면 왼쪽의 파일 창에 모델이 생성되는 것을 볼 수 있음
# keras의 load_model 함수를 사용해 저장된 모델을 불러와서 사용할 수 있음
from tensorflow.keras.models import load_model
model = load_model('model.h5')- 저장했던
model.h5에 대한 테스트를 진행해 보았다.- numpy의
argmax함수를 OneHotEncoding이 되어 있던 인덱스들을 원래의 형식으로 돌려주었다. - 아래의 바나나를 예측하는 결과는 예측이 잘 되지 않은 것을 보여주는 예시이다. 모든 것이 정확하게 예측되지는 않는다는 것을 알 수 있다.
- numpy의
# 100번째 배치에 있는 아이템의 이미지와 라벨을 가져와라
test_imgs, test_labels = test_gen.__getitem__(90)
# test_imgs를 모델에 넣어 예측값 y_pred를 얻음
y_pred = model.predict(test_imgs)
# OneHotEncoding을 한 클래스의 인덱스들을 다시 원상태로 돌려주기 위한 코드
classes = dict((v, k) for k, v in test_gen.class_indices.items())
fig, axes = plt.subplots(4, 8, figsize=(20, 12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
# numpy의 argmax 함수 : OneHotEncoding이 된 것을 다시 class의 index로 바꿔줌
# softmax에서 가장 높은 확률값을 받은 인덱스를 확률이 아닌 진짜 index로 뽑아주는 역할 -> [0.9 0.01 0.09]라면 0.9를 가지고 있는 인덱스인 0 출력
test_label = classes[np.argmax(test_label)]
pred_label = classes[np.argmax(pred_label)]
# GT : Ground Truth(정답값) / PR : prediction(예측값)
# 아래 예시는 예측을 잘 못한 예시
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)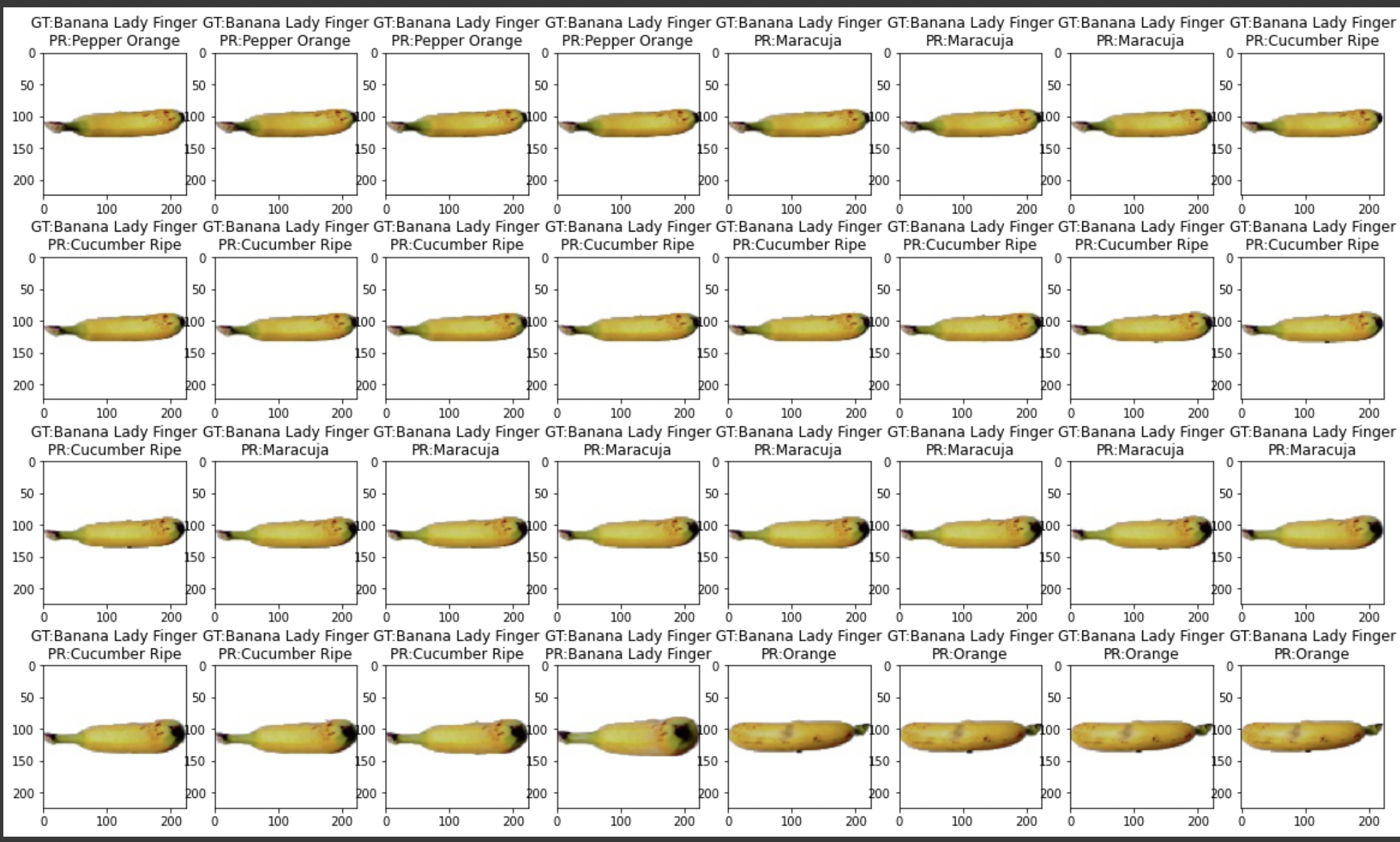
😭 4주차 숙제


https://github.com/nikevapormax