😂 머신러닝
😭 선형회귀
- Tensorflow를 활용한 실습
- 실습을 위해 아래의 방식을 사용했지만, Tensorflow에서도 아래의 방식은 추천하지 않음!
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x_data = [[1, 1], [2, 2], [3, 3]] # 입력값
y_data = [[10], [20], [30]] # 출력값, 각각 대응하는 값들
X = tf.compat.v1.placeholder(tf.float32, shape=[None, 2]) # 텐서플로우에서는 placeholder에 변수를 저장하며, 변수의 타입을 지정해야 함.
Y = tf.compat.v1.placeholder(tf.float32, shape=[None, 1]) # 입력되는 변수의 모양도 지정해줘야 함. x는 2개의 값이 들어가고 y는 1개의 값이 들어감. None은 배치 사이즈.
W = tf.Variable(tf.random.normal(shape=(2, 1)), name='W') # weight와 bias variable은 랜덤하게 이니셜라이징해줌(초기화), (2,1) 사이즈의 행렬
b = tf.Variable(tf.random.normal(shape=(1,)), name='b') # 1차원행렬. 이름은 아무거나 해주면 됨hypothesis = tf.matmul(X, W) + b # Wx + b를 표현한 것. 가설을 세운다
cost = tf.reduce_mean(tf.square(hypothesis - Y)) # cost function을 세운다. (hypothesis - Y)의 제곱을 한 것의 평균을 낸 것.
optimizer = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost) # optimizer를 설정한다.
# iteration을 진행할 때 0.01 스탭씩 진행하며, cost를 최소화하는 것을 목적임with tf.compat.v1.Session() as sess: # Tensorflow에서는 Session을 사용하는데, Session은 Tensorflow에서 사용하는 모든 변수들과 그래프들을 저장하고 있는 저장소
sess.run(tf.compat.v1.global_variables_initializer()) # 모든 변수들을 초기화하라는 명령(규칙이므로 외워야 함)
for step in range(50): # 머신러닝에서는 반복학습이 필수적임. 여기서는 총 50번의 스텝을 밟음.
c, W_, b_, _ = sess.run([cost, W, b, optimizer], feed_dict={X: x_data, Y: y_data}) # cost, W, b가 결과로 나오게 되고, cost가 낮아야 학습이 잘된 것!
# cost 값을 계산하게 되는데, W/b.optimizer를 모두 포함에서 계산
# 데이터 셋을 입력(이걸 feeding이라함), feed_dict(feeding하는 과정)
# X와 Y는 위에서 우리가 생성했던 placeholder, 이곳에 데이터들을 넣어줌
print('Step: %2d\t loss: %.2f\t' % (step, c)) # 각 스텝에 따라서 cost를 출력해라 (\t : 출력 시 문자열 사이에 탭간격을 줘라)
print(sess.run(hypothesis, feed_dict={X: [[4, 4]]})) # 위의 모델이 꽤 의미가 있다고 값이 나오지만(cost의 크기가 작음), 이것은 검증을 꼭 거쳐봐야 함.
# 우리가 처음에 생각했던 것과 같이 [4, 4]를 넣으면 40이 나올 수 있는지 확인해 보는 것!
# 위에서 보면 우리가 모델 학습을 위해 데이터셋에 X와 Y를 모두 넣었는데, 우리가 필요한거는 Y가 X에 따라 어떻게 나오는지이므로
# 여기서는 X의 값만 가설에 입력. 즉, 가설의 식 중에서 우리는 W와 b의 값을 바로 위에서 구했으니까 X를 넣으면 Y가 나오겠지?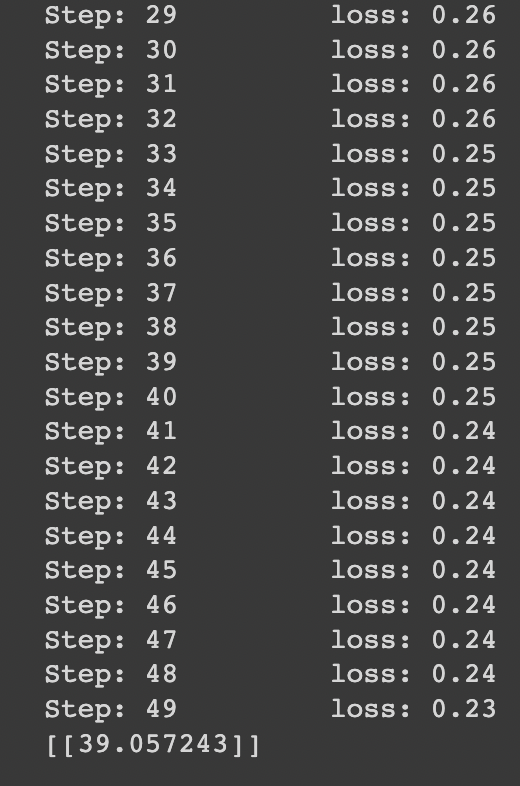
결과값을 확인해 보면, 우리가 생각했던 것과 같이 40 근처로 잘 나왔기 때문에 모델의 학습이 잘 된것을 알 수 있다.
- keras를 활용한 실습
- 위의 코드보다 훨씬 간결함을 알 수 있었고, 좋은 점은 진행상황을 눈으로 볼 수 있도록 출력해 주는 것이 있었다.
import numpy as np
from tensorflow.keras.models import Sequential # Sequential : 모델을 정의할 때 쓰는 클래스
from tensorflow.keras.layers import Dense # Dense : 가설을 구현하는 데 사용
from tensorflow.keras.optimizers import Adam, SGD # SGD : Stochastic Gradient Descent
x_data = np.array([[1], [2], [3]]) # keras는 입력값으로 numpy array를 받음
y_data = np.array([[10], [20], [30]])
model = Sequential([ # 모델을 정의하는데, Sequential은 말 그대로 모델을 순차적으로 쌓아갈 수 있도록 해주는 구조
Dense(1) # 선형회귀에서는 레이어가 하나이기 때문에, 출력이 하나임! 그래서 Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1)) # 컴파일 구성을 하는데, loss function은 다음과 같이 적고, 수식은 적지 않아도 됨
# optimizer로는 SGD를 사용할 것이며, learning rate(학습률)은 0.1로 지정함
model.fit(x_data, y_data, epochs=100) # 모델을 학습시켜주기 위해서 단순히 fit을 사용하면 됨(fit : 가설이 정답값을 맞춘다)
# 몇 번을 반복시킬 것인지 작성(epochs; 에폭)하며 복수형으로 쓰기!
- loss의 값이 0.0160으로 충분히 의미가 있다고 생각되지만, 그에 대한 검증을 진행해야 하므로 아래와 같이 진행
y_pred = model.predict([[5]]) # 위에서 우리가 성립한 모델을 예측(predict)
print(y_pred)
예측값을 확인해 보면, 우리가 처음에 생각했던 것과 비슷하게 5를 넣으면 50이 완벽하게 나오지는 않았지만 근삿값으로 잘 나왔기 때문에 모델의 학습이 잘 된것을 알 수 있다.
😭 kaggle의 데이터셋을 받아 예측
- kaggle의
advertising.csv파일을 받아 예측 진행 - kaggle을 쭉 사용할 것이므로 아래와 같이 아이디/패스워드 기입
import os
os.environ['KAGGLE_USERNAME'] = 'username'
os.environ['KAGGLE_KEY'] = 'key'- 광고 데이터 예측 (Single-variable linear regression)
- TV 광고 금액으로 Sales 예측
#### 이렇게 4개는 기본적으로 계속 사용 #########
from tensorflow.keras.models import Sequential # Sequential : 모델을 정의할 때 쓰는 클래스
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
########################################
import pandas as pd # csv 파일을 읽어올 때 사용
import matplotlib.pyplot as plt # 그래프 그릴 때 사용
import seaborn as sns # 그래프 그릴 때 사용
from sklearn.model_selection import train_test_split # 머신러닝할 때 사용. 트레인셋과 테스트셋을 분리해주는 기능
df = pd.read_csv('advertising.csv')
df.head(5) # 맨 앞의 5줄만 출력 / df.tail(n) : 맨 뒤에서 n개 만큼 출력 -> 데이터셋이 어떻게 생겼는지 체크하기 위해 함
⬆️ advertising.csv 의 형태를 파악할 수 있다.
print(df.shape) # 200개의 로우와 4개의 컬럼을 가지고 있다. 즉, 200개의 데이터셋이 있다.
# pairplot : 모든 데이터셋을 넣은 뒤, 내가 보고싶은 variable에 대해서만 상관관계를 출력해줌 / x축은 TV, Newspaper, Radio이고 y축은 Sales
sns.pairplot(df, x_vars=['TV', 'Newspaper', 'Radio'], y_vars=['Sales'], height=4) 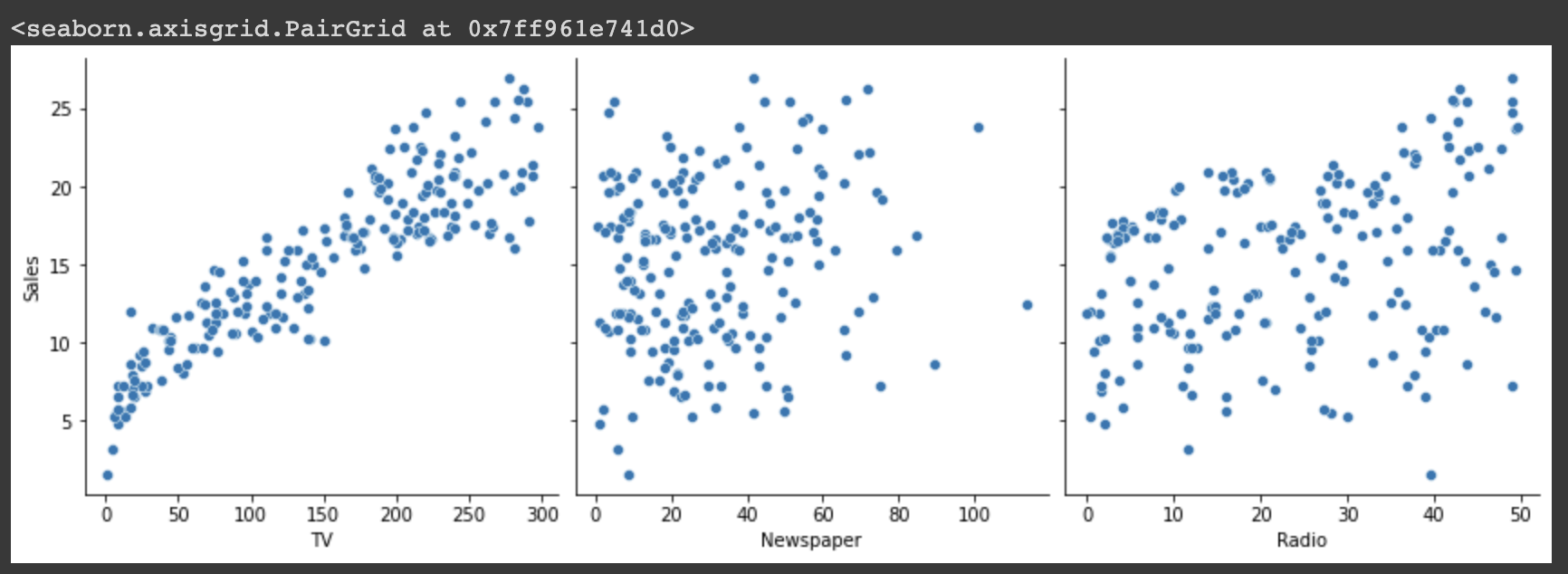
⬆️ 그래프를 보면, TV와 Sales 간의 상관관계가 제일 높은 것을 알 수 있다.
# 데이터 가공을 위해 우리는 항상 input과 output data를 받아와야 함
# 데이터프레임(df)이라는 변수로 받아온 csv 파일 중에서 TV와 Sales의 정보를 꺼내고, keras를 돌려야 하니 keras에서 취급하는 numpy array로 변형시켜주는 것
x_data = np.array(df[['TV']], dtype=np.float32) # input data, Tensorflow는 floating point 32bit를 사용하므로 데이터 타입을 다음과 같이 세팅
y_data = np.array(df['Sales'], dtype=np.float32) # output data
print(x_data.shape) # 데이터타입의 크기를 출력
print(y_data.shape) # 지금 보면 x와 y 데이터의 형식이 맞지 않음
# 데이터의 형식이 맞지 않으므로 keras가 인식하기 편하도록 다음과 같이 reshape을 진행하여 형식을 맞춰줌
x_data = x_data.reshape((-1, 1)) # (-1, 1)에서 1은 뒤의 형식을 무조건 1로 맞춰준다는 뜻! 이 경우는 원래 뒤가 1이라서 노상관
# -1은 남은 수만큼 알아서 변형해라라는 뜻! 앞에가 200이므로 200 적용
y_data = y_data.reshape((-1, 1)) # 뒤를 1로 맞춰주고 앞에는 200으로 맞춰줘라
print(x_data.shape)
print(y_data.shape)⬆️ 데이터의 shape을 (200, 1)로 맞춰주어 keras가 예측을 편하게 할 수 있도록 조정한다.
# 강의에서는 편의를 위해 train_set(80) : validation_set(20)으로만 나눔
# train_test_split 기능을 사용해 데이터셋을 나누며 test_set의 사이즈를 0.2로 정해 80:20의 비율로 나눔.
# random_state로 랜덤변수를 지정하며, 데이터셋을 나눌 때 사용하는 시드의 역할을 한다.
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape) # x의 train_set의 크기는 160이고, validation_set의 크기는 40
print(y_train.shape, y_val.shape)데이터셋의 분리는 원래 아래와 같이 진행해야 한다.

model = Sequential([ # Sequential : 모델을 정의할 때 쓰는 클래스
Dense(1) # Dense : 가설을 구현하는 데 사용 / 여기서는 출력이 하나 밖에(Sales만 예측하니까) 나오지 않으므로 Dense의 괄호 안에 1이 들어가게 됨
])
# loss function으로는 mse를 사용하고, optimizer로는 Adam 사용(보편적으로 성능이 좋아 많이 쓰임)하며, learning rate는 0.1
model.compile(loss='mean_squared_error', optimizer=Adam(lr=0.1))
model.fit( # 모델 학습시에는 fit을 사용
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)y_pred = model.predict(x_val) # 데이터 검증에는 model.predict 사용
plt.scatter(x_val, y_val) # 정답값을 그려줌
plt.scatter(x_val, y_pred, color='r') # 예측값을 그려주며, 색을 빨간색으로 변경
plt.show()
# 우리의 모델은 선형회귀식이었기 때문에 직선으로 결과가 나온 것을 알 수 있고, 꽤 오밀조밀하게 모여있기 때문에 학습이 잘 된 것으로 판단됨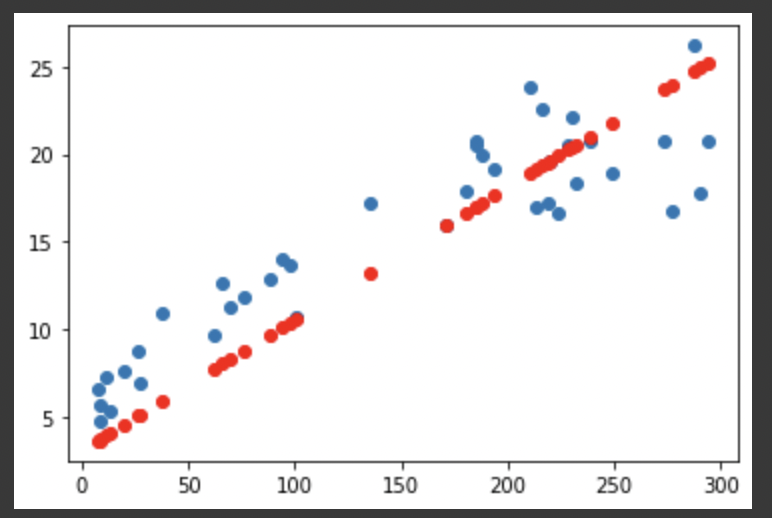
- 광고 데이터 예측하기 (Multi-variable linear regression)
- 위에서 진행했던 그대로 진행
- 이번에는 TV 뿐만 아니라 Newspaper, Radio와 Sales 간의 상관 관계도 확인할 것이기 때문에 다음과 같이 scatter plot 확인
plt.scatter(x_val[:, 0], y_val) # 0번째 값이므로 TV에 해당하는 값이고, 정답값
plt.scatter(x_val[:, 0], y_pred, color='r') # 예측값이고 빨간색
plt.show() # 데이터의 경향이 비슷하므로 예측을 잘 했다.
plt.scatter(x_val[:, 1], y_val) # 1번째 값이므로 Newspaper
plt.scatter(x_val[:, 1], y_pred, color='r')
plt.show() # 경향이 데이터셋 자체가 적었기 때문에 이정도면 잘 나온듯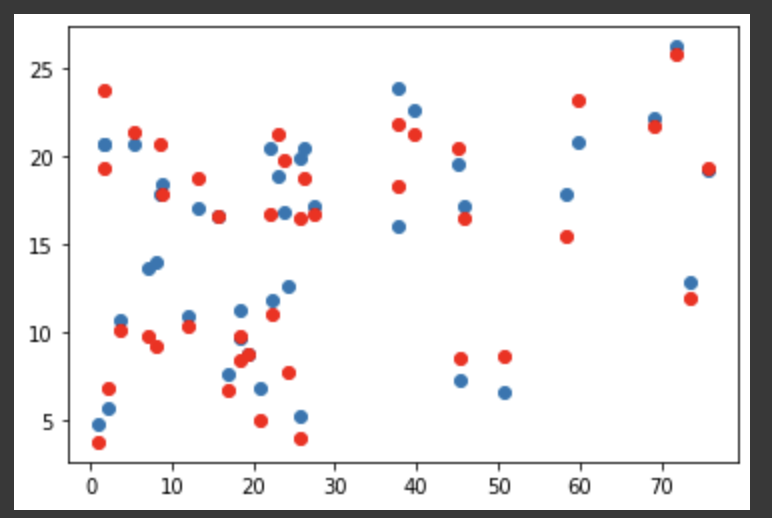
plt.scatter(x_val[:, 2], y_val) # 2번째 값이므로 Radio 값
plt.scatter(x_val[:, 2], y_pred, color='r')
plt.show() # 선형관계가 있으나 좀 덜하다.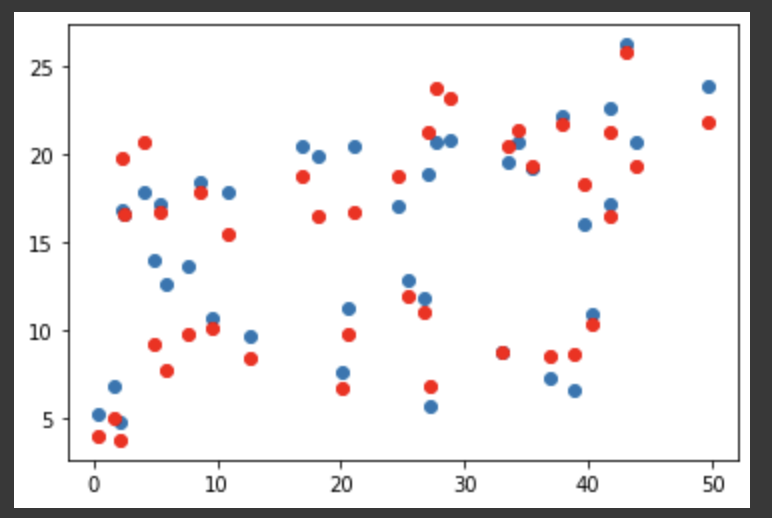
😭 1주차 숙제
- url
- learning rate를 0.01이 아닌 0.3으로 해보았는데, 어떤 옵티마이저를 사용해도 선형관계가 나오지 않았다.
- 나의 예상으로는 데이터셋의 크기가 35개 밖에 되지 않아서 어떤 옵티마이저를 사용해도 결과가 비슷했을 것이라 생각한다. (아닐 가능성이 크다 ㅋ)
- loss function의 종류도
mean_squred_error와mean_absolute_error를 모두 사용해 보았는데, loss 값과 vla_loss 값의 차이는 있었으나 마지막에 모델 예측에서는 둘 다 선형 관계를 보여주었다. - 선형 관계는 거의 유사하게 나온 것 같다.

😭 논리 회귀(Logistic regression)
- 타이타닉 생존자 예측하기(이진 논리 회귀)
- 타이타닉에 탔던 사람들의 정보를 통해 생존 여부를 예측해보았다.
- 타이타닉에 탔던 사람들의 정보를 사용하기 위해 해당 정보가 있는 csv 파일을 불러왔다.
!kaggle datasets download -d heptapod/titanic
!unzip titanic.zip- 사용할 패키지 import
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler- 정보를 불러온 뒤 어떠한 형태로 불려왔는지 확인하였다.
df = pd.read_csv('train_and_test2.csv')
df.head(5)
- 표 아래의 숫자를 보면 표의 크기가 보인다. 우리에게 필요하지 않은 정보를 버리기 위해 다음과 같이 사용할 정보를 지정해 저장했다.
df = pd.read_csv('train_and_test2.csv', usecols=[ # usecols: 사용하는 컬럼의 이름들
'Age', # 나이
'Fare', # 승차 요금
'Sex', # 성별
'sibsp', # 타이타닉에 탑승한 형제자매, 배우자의 수
'Parch', # 타이타니게 탑승한 부모, 자식의 수
'Pclass', # 티켓 등급 (1, 2, 3등석)
'Embarked', # 탑승국
'2urvived' # 생존 여부 (0: 사망, 1: 생존)
])
# 여기서 입력값은 Age ~ Embarked이고, 출력값은 2urvived 이다.
df.head(5)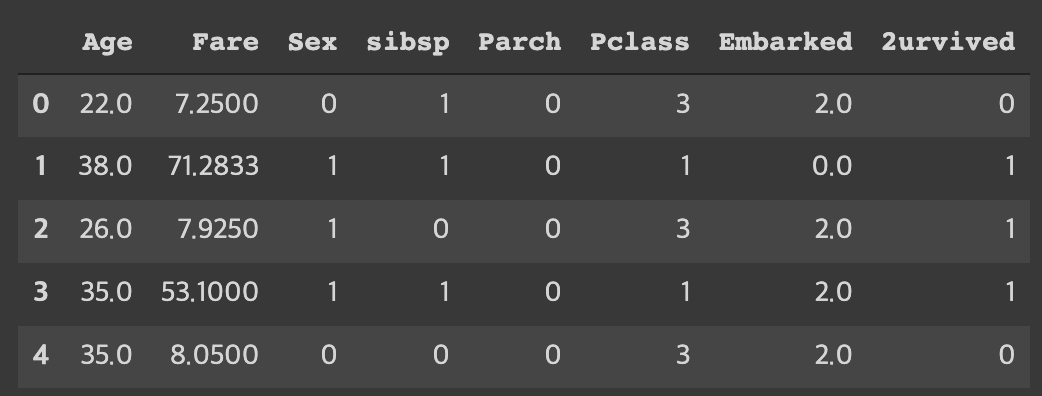
- 필수적인 과정은 아니지만, 다음과 같이 확인하고 싶은 정보를 확인할 수 있다.
# countplot: seaborn의 숫자를 셀 때 사용하는 그래프
# 성별 생존여부 (0: 남자, 1: 여자)
sns.countplot(x='Sex', hue='2urvived', data=df)
# 0: 사망자 수, 1: 생존자 수
sns.countplot(x=df['2urvived'])- 전처리를 진행해 데이터를 우리가 학습시킬 모델이 이해하기 쉬운 형태로 만들어 주는 것이 좋다. 전처리를 하게 되면
outlier를 잡아낼 수 있어 데이터를 분석하다가 오류가 나는 일을 예방할 수 있다.
# isnull(): 데이터의 값 중 비어있는 값이 얼마나 있는지 알아내는 함수
print(df.isnull().sum())
우리는 isnull() 함수를 사용해 비어 있는 값들을 캐치하기로 했다. 그러므로 Embarked에 있는 2개의 비어 있는 값들을 제거해줄 필요가 있다.
# 비어있는 값을 지우기 전의 길이를 알아내 값이 제대로 삭제되었는지 알아보기 위함
print(len(df))
# dropna(): na 값을 지워주는 함수
df = df.dropna()
# 지워준 후의 개수
print(len(df))여기서 길이를 사용한 것은 저 2개의 null 값들이 삭제되었는지 알아내기 위함이다. 물론 직접 뜯어보기 전까지는 정확하지 않다고 생각하지만, 삭제가 잘 이루어졌다고 본다.
- 우리의 목적은
타이타닉에 탄 사람들의 생존여부를 알아내는 것이다. 그러므로 원 데이터셋에 있던2urvived를 따로 분리해야 한다.
# 입력값 중에는 2urvived가 필요하지 않기 때문에 x_data에서 삭제해야 함
# drop() 함수를 사용해 필요없는 값 삭제 / 우리는 column을 지워야 하기 때문에 axis=1을 써준다.
# axis=0 (index; row), axis=1(column)
x_data = df.drop(columns=['2urvived'], axis=1)
# 삭제한 후 타입을 float32로 맞추어 keras를 사용할 수 있도록 함(astype : 데이터프레임 안의 모든 데이터의 타입이 같을 때 한 번에 타입을 바꿔줌 / 만능이 아님
# 만약 데이터 타입이 다른 것이 껴져 있다면 구글링해서 찾아봐~ ㅋ)
x_data = x_data.astype(np.float32)
x_data.head(5)
# 출력값에 필요한 2urvived만 사용하면 되기에 다음과 같이 세팅하고, keras 사용을 위해 float32로 타입 변경
y_data = df[['2urvived']]
y_data = y_data.astype(np.float32)
y_data.head(5)
- 이제 분리된 테이블의 데이터 값들을 자세히 보다보면 뭔가 숫자들이 중구난방인 테이블이 있을 것이다. 그렇다. 바로 우리가 x_data에 넣을 분리된 첫 번째 테이블이다. 이 상태로 넣으면 결과가 이상해질 수도 있으니, 이를 줄이기 위해 최대한 비슷한 형태로 만들어 줘야 한다. 그래서
표준화를 진행할 것이다.
scaler = StandardScaler() # sklearn의 표준화 장치 사용
x_data_scaled = scaler.fit_transform(x_data) # fit_transform을 통해 표준화하며, x_data의 범위가 모두 다르기 때문에 해당 셋만 진행
# 표준화하기 전 : 모두 다 제각각
print(x_data.values[0])
# 표준화 후 : 값이 모두 비슷한 범위 안에 존재하고 있음
print(x_data_scaled[0])
위의 숫자들이 표준화를 통해 아래와 같이 비슷한 범위 안에 들어오게 되었다.
- 학습과 검증을 위해 이제 데이터들을 테스트셋과 밸리데이션셋으로 나눠줘야 한다. 아래의 결과와 같이 잘 나눠진 것을 볼 수 있다.
# 학습 데이터와 검증 데이터를 80:20의 비율로 나눔 / seed를 랜덤하게 지정
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape) # (1045, 7) (262, 7)
print(y_train.shape, y_val.shape) # (1045, 1) (262, 1)- 이제 나누어진 데이터를 바탕으로 모델을 학습시키도록 하겠다.
model = Sequential([
Dense(1, activation='sigmoid') # 이진 논리회귀는 선형회귀와 다르게 sigmoid 를 Dense에 입력해주어야 함
])
# keras에서는 0인지 1인지 구분하기 위해 사용하는 crossentropy를 사용하기 위해 binary_crossentropy를 입력해주어야 함
# 로지스틱 리그레션은 loss 값만 보고 얼마나 잘 학습이 되었는지 파악하기 힘들기 때문에 metrics를 사용!
# acc는 '정확도'이고, 분류문제를 풀 때 많이 사용됨! 0~1 사이의 값으로 나타내주며 1에 가까울수록 정확도가 100%임
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
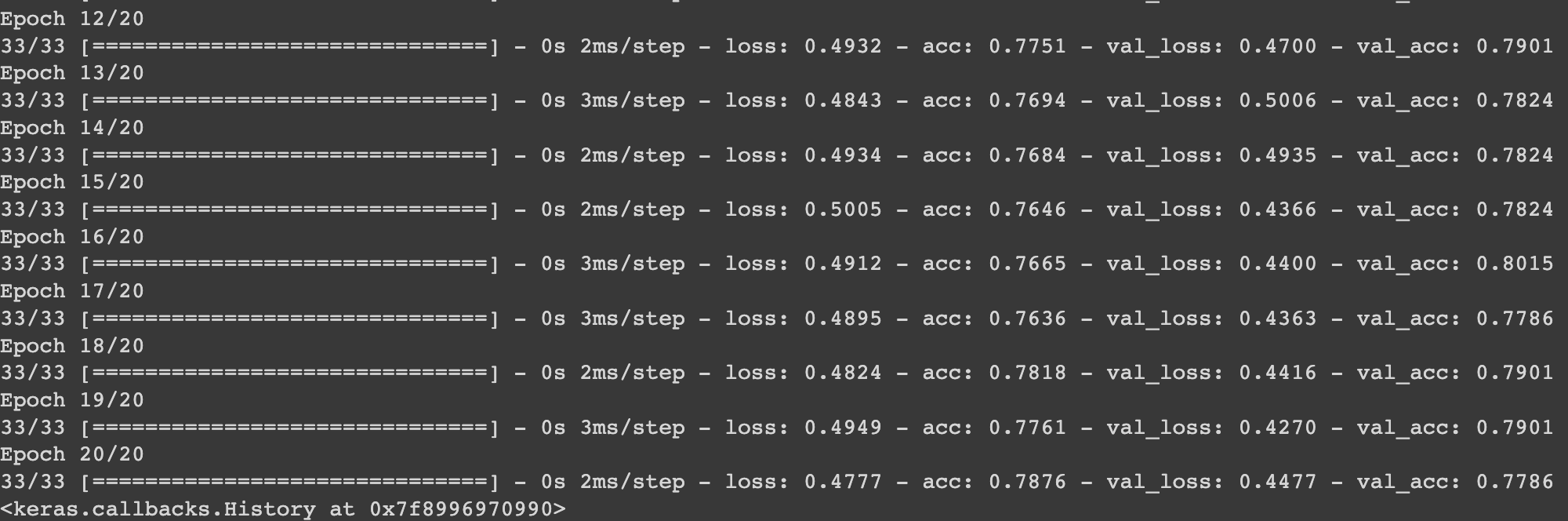
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!앞의 선형 모델과 다른 점은 sigmoid함수를 사용한다는 것이다. 따라서 activation='sigmoid'를 입력하였다. 또한 loss function으로 선형 모델의 mean_squared_error 또는 mean_absolute_error와 달리 binary_crossentropy를 사용하게 된다. 여기서 그치지 않고 더 정확한 학습 정도를 알아내기 위해 metrics=['acc']를 같이 사용해야 한다. (accuracy의 acc)
- 와인 종류 예측(다항 논리 회귀)
- 와인의 정보가 들어있는 Wine.csv 파일을 받아 예측 모델을 만들어 보았다.
- Wine.csv 파일을 dataframe으로 받아오고, 구조를 알아보았다.
df = pd.read_csv('Wine.csv')
df.head(5)
파일을 까고 봤더니 헤더에 이름이 제대로 작성되어 있지 않아 이름을 직접 채워보았다.
# 표의 헤더에 내용이 없으므로 수동으로 헤더에 이름을 붙여줌
# 우리는 와인의 특성을 통해 와인의 이름을 불러와야 하므로 name이 결과값, 나머지가 입력값이 된다.
df = pd.read_csv('Wine.csv', names=[
'name'
,'alcohol'
,'malicAcid'
,'ash'
,'ashalcalinity'
,'magnesium'
,'totalPhenols'
,'flavanoids'
,'nonFlavanoidPhenols'
,'proanthocyanins'
,'colorIntensity'
,'hue'
,'od280_od315'
,'proline'
])
df.head(5)
- 우리가 찾고자 하는 와인의 종류는
name을 통해 확인할 수 있다. 어떤 종류로 이루어져 있는지df.head(5)로는 판별이 힘들기 때문에 아래와 같이seaborn의countplot을 활용해 종류와 각 종류별 개수를 알아보았다.
# seaborn의 countplot을 사용해 column 명이 name인 데이터들을 각각의 이름에 따라 카운팅
sns.countplot(x=df['name'])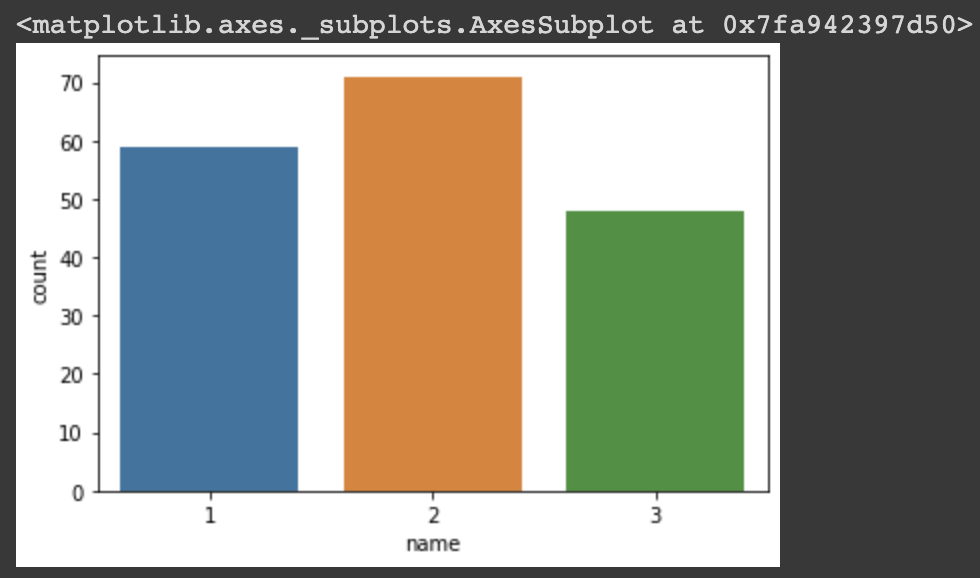
해당 plot을 통해 와인의 종류는 3가지가 있다는 것을 알 수 있었다.
- 원하는 기본 정보를 얻었으니, 본격적인 모델 생성 이전에
데이터 전처리(preprocessing)을 하고 가도록 하겠다. 무조건 명심해야 하는 부분으로 데이터는 반드시 깔끔해야 한다. 모델 만들고 구멍 찾으면 진짜 화난다.
# isnull() 함수를 사용해 전처리를 위해 비어 있는 행을 확인
# 비어 있는 데이터가 없음!
print(df.isnull().sum())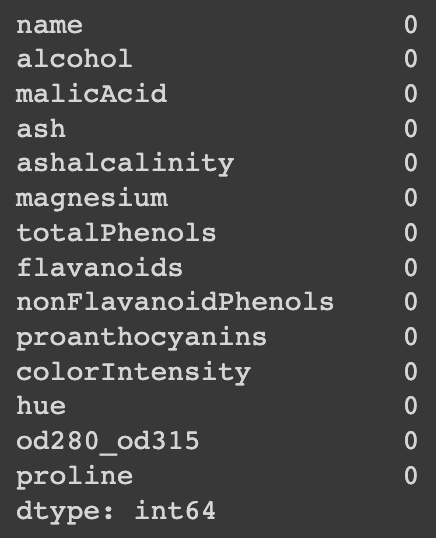
처음에는 헤더가 없어서 맘에 안들었지만 데이터가 너무 깔끔한게 이뻐 죽겠다.
- 데이터에 구멍이 없으므로 바로 데이터를 분할하기로 했다.
# name column을 빼고 모두 입력값이므로 입력값을 정할 때 name을 drop 해줌
x_data = df.drop(columns=['name'], axis=1)
# 데이터의 타입을 astype을 통해 한 번에 float32로 변경해줌(단, 데이터의 종류가 원래 같았어야 함)
x_data = x_data.astype(np.float32)
x_data.head(5)입력값으로 넣을 x_data를 분할하였다. 맨 처음의 데이터에서 결과값으로 사용될 y_data를 없애주기만 하면 된다.
그 다음으로 결과값인 y_data를 선언해 주었다.
# 결과값으로 사용할 name을 받아옴
y_data = df[['name']]
# astype을 사용해 name 의 모든 값을 float32로 바꿔주며, 이 또한 원래 name 요소들의 타입이 같았어야 함
y_data = y_data.astype(np.float32)
y_data.head(5)- 내가 쓸 데이터도 목적에 맞게 잘 분리했으니, 이제 데이터의 값을 보고 마음에 들지 않는다면 표준화를 진행하도록 하겠다.
# 데이터의 표준화 진행
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
# 표준화를 진행하여 값의 차이를 많이 줄였다. 컴퓨터가 좋아하게
print(x_data.values[0])
print(x_data_scaled[0])
표준화를 통해 값의 차이를 많이 줄이게 되었다.
- 결과값으로 사용할 y_data을
OneHotEncoding을 통해 각 와인의 종류를 다음과 같이 변환시켜 준다. - 1번 와인 -> [1, 0, 0]
2번 와인 -> [0, 1, 0]
3번 와인 -> [0, 0, 1]
# one-hot encoding
# sklearn의 OneHotEncoder 라는 클래스를 사용해 인코딩하고, fit_transform을 통해 y 데이터에 반영하고 array로 바꿔줌
# 우리에게는 지금 3개의 라벨이 있다. (와인 1,2,3)
# 이것을 one-hot encoding을 통해 아래와 같이 변환시킨다.
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0])
print(y_data_encoded[0])마지막에 출력한 값은 OneHotEncoding을 통해 변환되어 아래와 같이 출력된다.

- 데이터에 대한 클린징이 마무리되었으니, 이제 모델 학습을 위해 train_set 과 val_set을 분리하도록 하겠다.
# 8:2의 비율로 트레인셋과 밸리데이션셋을 나눔
# 앞에서와 다른 점은 x 데이터는 스케일, 즉 표준화가 진행된 데이터이고, y 데이터는 인코딩, 즉 원핫 인코딩이 진행된 데이터이다.
# test_size = 0.2 -> train_set이 80%의 비율을 가진다.
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape) # (142, 13) (36, 13) -> 13은 와인 특성 열 세개
print(y_train.shape, y_val.shape) # (142, 3) (36, 3) -> 3은 와인 종류 세 가지- 이제 Sequential을 통해 모델을 생성하도록 하겠다.
- Dense에 3이 들어가는 이유는 3개의 출력값이 있기 때문이다. 이것보다 더 중요한 것은
softmax함수가 사용된 것이다.
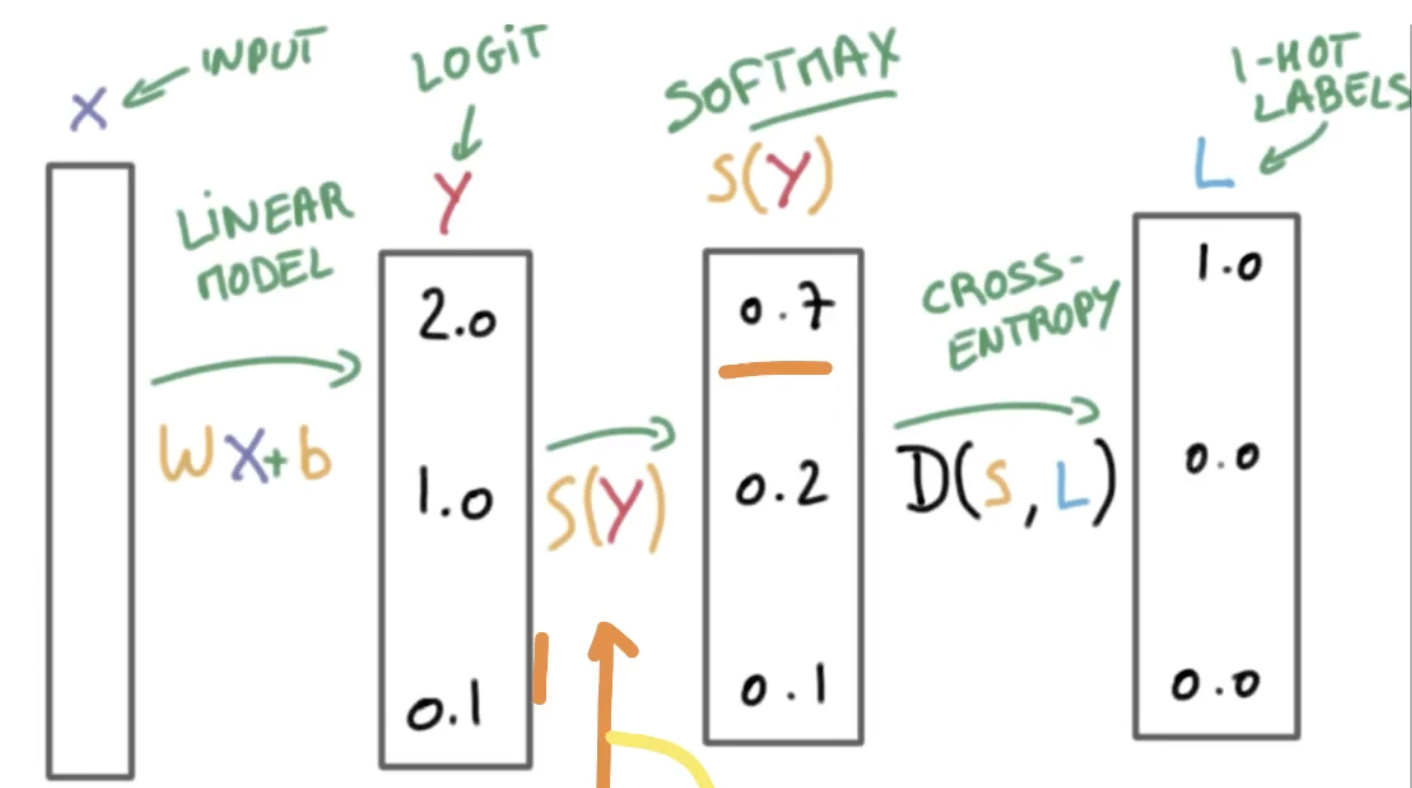
- 이진 논리 회귀와 다르게
categorical_crossentropy를 사용하게 되며, 이진 논리 회귀와 마찬가지로metrics=['acc']를 사용하여 더 정확한 평가를 진행한다.
- Dense에 3이 들어가는 이유는 3개의 출력값이 있기 때문이다. 이것보다 더 중요한 것은
model = Sequential([
# 이진 논리 회귀와 다른 점으로 출력이 3개 이므로 Dense 값이 3이 된다.
# 다항 연산이기 때문에 sigmoid가 아니라 softmax를 사용해야 한다.
Dense(3, activation='softmax')
])
# 이진 논리 회귀와 다르게 loss function에 categorical_crossentropy를 사용한다.
# 옵티마이저는 Adam을 사용하며, learing rate는 0.02를 주고
# logistic regression의 특성상 loss function 하나로는 모델에 대한 판단이 힘들기 때문에
# mertics=['acc'], 즉 정확도를 사용해 평가를 진행한다. (0~1 사이의 값이 나오게 되고, 1에 가까울수록 정확도 100%에 가까움)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.02), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기! 20번 반복!
)
# loss 값은 점점 줄어들고 acc 값은 점점 높아지므로 모델의 학습이 잘 된 것을 알 수 있다. 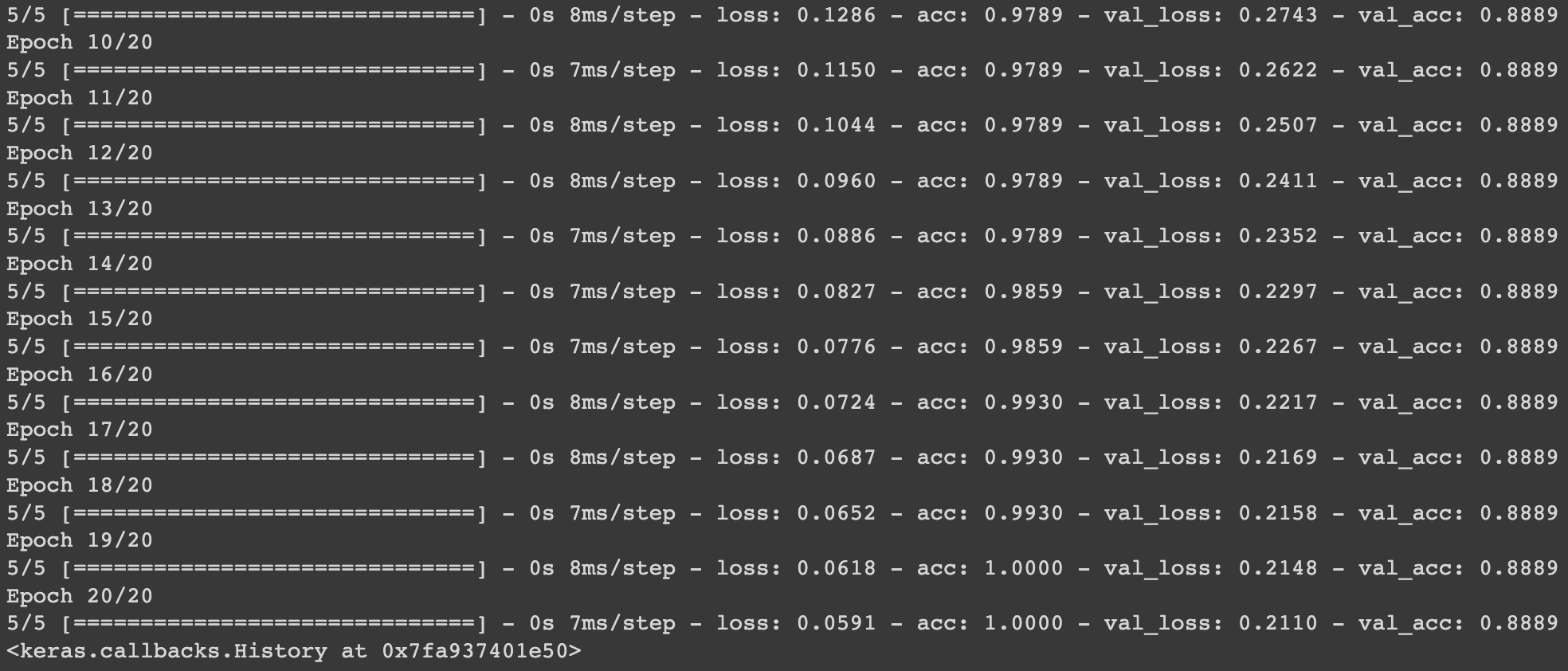
😭 2주차 숙제
