Abstract
wav2lip 이전의 모델들은 정적 이미지나 동영상에 대한 정확한 입의 움직임을 생성하는 데 능숙하다. 즉 동적이고 unsconstrained(제약이 없는) 영상에 대해서는 정확한 움직임을 만들어내지 못한다.
→ 이를 powerful lip-sync discriminator(판독기?)를 활용해 해결하고자 한다.
또한 unconstrained한 영상에 대해서 lip synchronization을 평가할 수 있는 새로운 지표를 제안한다.
이런 방법들을 통해 wav2lip은 실제 영상과 유사한 입의 움직임을 만들어낸다.
Introduction
다양한 언어로의 영상 제작들을 목표로 하며 lip-syncing에 대한 필요성이 대두되었고, 관련 연구들이 관심을 받고 있다.
Initial work : 한 명의 발화자에 대한 몇 시간짜리 영상을 통해 speech와 lip landmark 간의 mapping을 딥러닝 모델을 통해 학습한다.
→ 더 일반적으로 화자들에게 적용될 수 있는 모델이 필요했고, speaker-independent speech to lip generation model로 이동한다.
하지만 이는 정적인 이미지나 영상에서 사용이 가능하고 → 동적 영상, unconstrained 영상에서 사용하지 못한다.
또한 speaker-specific data 없이 동작 가능하도록 하고 싶다.
이전 모델이 잘못된 입 모양을 충분히 penalize하지 못한다. (약간 강화 학습 느낌인가?) → 강력한 discriminator를 사용하고 새로운 평가 지표를 활용하겠다.
ReSyncED(Real-world lip-Sync Evaluation Dataset)라는 데이터 셋을 공개한다. (현실적인 동영상 세트 → 실제로 어떻게 수행되는지 확인 가능)
Related Work
Constrained Talking Face Generation from speech
기존 연구는 특정 발화자에 한정되어 학습되었다. 그리고 해당 발화자의 몇 시간 이상의 영상이 필요하다. → two-stage approach를 통해서 화자의 독립적 특징을 학습한 후 5분 정도의 데이터를 사용하여 렌더링 매핑을 학습함으로 약간의 극복. 하지만 역시나 정제되어 있는 데이터의 필요성이 있다. 그리고 또한 이전까지의 연구에서 사용된 단어들이 1000 단어 정도의 데이터셋에 한정되어 있다는 점에서 아쉬운 부분들이 존재한다.
→ 해당 모델에서는 이러한 문제들을 극복하고 화자, 목소리, 단어와 상관 없이 unconstrained video에 대해서도 영상을 제작할 수 있도록 하고자 한다.
Unconstrained Talking Face Generation
from Speech
speech-drive face generation에 대한 연구는 많이 이루어지고 있지만 임의의 화자, 목소리, 언어에 대해서 작동 가능한 연구는 많지 않다.
lipgan 또한 임의의 화자에 대해서는 가능하지만 정적 이미지에 대해서만 적용 가능하다는 문제점이 있다.
→ 이런 문제들을 사전 학습된 discriminator를 활용해서 해결하고자 한다.(매우 정확한) 그리고 이게 매우 중요한 지점이다.
ACCURATE SPEECH-DRIVEN LIP-SYNCING FOR VIDEOS IN THE WILD
해당 논문의 중심 아키텍쳐는 ‘Generating accurate lip-sync by learning from a well-trained lip-sync expert’이다. 이 구조를 정확하게 이해하기 위해서는 기존의 모델들이 왜 부정확한 영상을 만들어내는지에 대한 이해가 필요하다.
그리고 그 첫 번째 이유는 L1 reconstruction loss가 해당 태스크에 적절하지 않고, 따라서 잘못된 생성을 충분하게 penalize하지 못하기 때문이다.
Pixel-level Reconstruction loss is a Weak
Judge of Lip-sync
face reconsruction loss는 전체 이미지에 대해 계산이 되고, 입의 경우 전체 이미지에서 4% 정도밖에 차지하지 않기 때문에 주변 이미지에 대한 최적화가 먼저 이루어지게 된다. 그래서 LipGAN과 같이
A Weak Lip-sync Discriminator
LipGAN의 Discriminator는 LRS2 셋에 대해서 56% 정도의 정확도 밖에 보이지 못하고, 해당 논문에서 사용할 expert discriminator는 91% 정도의 정확도를 보인다. 그 첫 번째 이유는 LipGAN은 single frame을 활용하는데, 작은 시각적 맥락이 입 싱크 감지에 큰 도움이 된다. 그리고 GAN 설정에서 훈련시키기 때문에 노이즈로 생성된 시각적 아티팩트에 더 중점을 두게 되어 오디오-입술 매칭에 덜 집중하게 된다고 볼 수 있다. 해당 논문은 실제 비디오 프레임에서 가져온 실제 lip-sync를 더 정확히 판별하는 데에 사용할 수 있을 것이라고 주장한다.
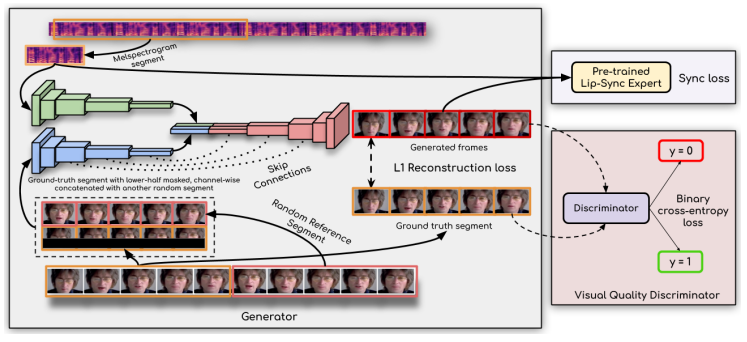
A Lip-sync Expert Is All You Need
위 근거들을 바탕으로 해당 논문에서는 새로운 학습된 expert discriminator를 제안한다. 그리고 추후 파인튜닝의 필요성도 없다?(진짜로?)
large lip-sync dataset을 만든다? → 이 과정에서 에러들을 수정하는 데에 사용하는 모델이 SyncNet이다.
결국 lip-sync expert를 학습하는 데에 syncnet을 수정하여 사용한다. 우선 컬러 이미지를 입력으로 넣고, residual skip connection을 사용하여 더 깊다. 또한 코사인 유사도와 binary cross-entropy loss를 활용한다.
Generating Accurate Lip-sync by learning
from a Lip-sync Expert
generator는 LipGAN과 유사하다. 가장 중요한 점은 expert discriminator를 사용한다는 점. (i) Identity Encoder, (ii) Speech Encoder, (iii) Face Decoder 세 가지 블록으로 이루어진다.
그리고 discriminator를 활용하여 부정확한 생성 값들에 대한 penalizing을 한다. 시간적으로 일치하는지 등. 그리고 프레임 별로 생성이 되기 때문에 해당 값들이 time-step으로 쌓이게 된다.
Generating Photo-realistic Faces
expert discriminator를 활용하는 과정에서 blurry 해지거나 artifact가 생기는 등의 문제가 있었고, 이를 해결하기 위해 quality discriminator를 활용한다.
