4주차
이번 주차는 5일 모두 머신러닝에 대해서 배우는 시간이었습니다. 사실 강의 속도에 대해서 약간은 느리다는 생각이 들어서 아쉬운 부분도 있었지만, 그만큼 기초적으로 알아야 하는 부분들을 확실히 배워나가는 시간이 될 수 있었습니다. 머신러닝을 위한 기본적인 코딩 기법들 그리고 다양한 모델들의 알고리즘에 대해서 배웠지만 그 중에서 평가지표에 대한 이야기를 조금 해보고자 합니다.
평가 지표
케글 등을 나가보면 해당 대회는 r2 score를 사용합니다. 혹은 해당 대회는 accuracy를 사용합니다 등의 멘트를 볼 수 있습니다. 사실 그럴 때마다 그냥 모델 잘 만들면 어떤 지표를 사용하더라도 잘 나오는거겠지 하고 넘겼습니다. 하지만 우리의 목적은 케글에서 좋은 점수를 받는 게 아닌 실제로 어떤 태스크를 잘 해결할 수 있는 모델을 만들수 있는 사람이 되는 것이고 그러기 위해서는 평가 지표에 대한 이해도 어느 정도는 필요하다는 생각을 하게 되었습니다.
과제에 따른 분류
평가 지표를 이해하기 위해서는 머신러닝을 통해서 해결할 수 있는 태스크의 과제에 따른 분류를 조금 알아야 합니다. 그냥 간단하게 회귀 아니면 분류겠구나 라고 생각합니다. 물론 클러스터링 같은 비지도 학습의 과제도 존재하지만 대부분 머신러닝으로는 지도 학습을 많이 처리하는 추세이기 때문에 여기서는 그 과제를 분류 또는 회귀로만 나누어서 볼 예정입니다. 분류 문제는 말 그대로 타겟 데이터가 범주형 변수라고 생각을 하시면 될 것 같습니다. 예를 들어 타이타닉 데이터와 같이 이 승객의 생존 여부(0, 1) 과 같은 범주형 변수를 맞추게 되는 태스크를 분류라고 할 수 있습니다. 그리고 회귀는 연속된 값 사이에서 예측을 하는 태스크를 회귀라고 할 수 있습니다. 생존하냐 생존하지 않냐가 아닌 판매량이 얼마나 된다와 같은 예측이라고 할 수 있습니다. 그리고 분류와 회귀에서는 서로 다른 평가지표를 사용하게 됩니다.
회귀 모델 성능 평가 지표
회귀 모델은 연속된 값에서 예측을 하는 것이기 때문에 100% 정확한 값을 예측한다는 것은 거의 불가능에 가깝습니다. 그래서 회귀 모델은 대부분 오차를 측정하고 해당 오차를 줄여나가는 것을 기준으로 성능을 평가하게 됩니다. 따라서 회귀 모델의 성능 평가 지표에서 가장 중요한 것은 해당 오류를 어떻게 측정하고 수치화할까라고 보면 될 것 같습니다.
오차(Error)
회귀 모델에서 오차는 실젯값과 예측값의 차이 즉 y(real) - y(pred)로 정의가 됩니다. 하지만 이런 오차는 양수와 음수가 모두 존재하기 때문에 평균을 내기 위해서 합을 낼 때 제대로 차이들이 반영되지 않는 경우가 많고, 이런 문제를 해결하기 위해 절댓값 혹은 제곱 등이 사용되게 됩니다.
MAE(Mean Absolute Error)
이번 주의 수업에서 강사님께서 가장 애용하셨던 지표 중 하나입니다. 오차(Error)에 절댓값을 씌운 뒤 평균 내서 사용하는 지표입니다.
MAPE(Mean Absolute Percentage Error)
MAPE의 경우 절댓값을 씌우는 것은 MAE와 동일하지만 절댓값을 씌운 오차를 다수 y값으로 나누어 오차가 차지하는 퍼센티지를 나타내는 지표입니다.
MSE(Mean Squared Error)
오차를 절댓값을 씌우게 되면 부호로 인한 오류들은 해결할 수 있지만 이후 모델을 만들면서 경사하강법 등의 방법들을 사용하기 위해서는 미분을 할 필요성이 생기게 되는데 절댓값의 경우 미분이 쉽지 않다는 단점이 있습니다. 그리고 이를 해결하기 위해 제곱을 사용하는 MSE의 필요성이 대두됩니다.
RMSE(Rooted Mean Squared Error)
하지만 MSE와 같이 제곱을 하게 되면 어쩔 수 없이 전체적인 오차의 값이 커지게 되고 이를 해결하기 위해서 제곱한 오차값들을 평균 낸 후 다시 루트를 씌우는 RMSE도 사용됩니다.
R2 스코어
r2 스코어는 쉽게 표현하면 모델이 만들어낸 회귀값이 평균보다는 얼마나 설명력이 좋은가를 표현하는 지표라고 할 수 있습니다. 위에서 언급된 지표들은 모두 오차의 값을 계산한 지표이기 때문에 값이 작을수록 해당 모델의 성능이 좋다는 의미가 된다면 r2 스코어만이 값이 클수록 해당 모델의 성능이 뛰어나다는 의미가 됩니다.
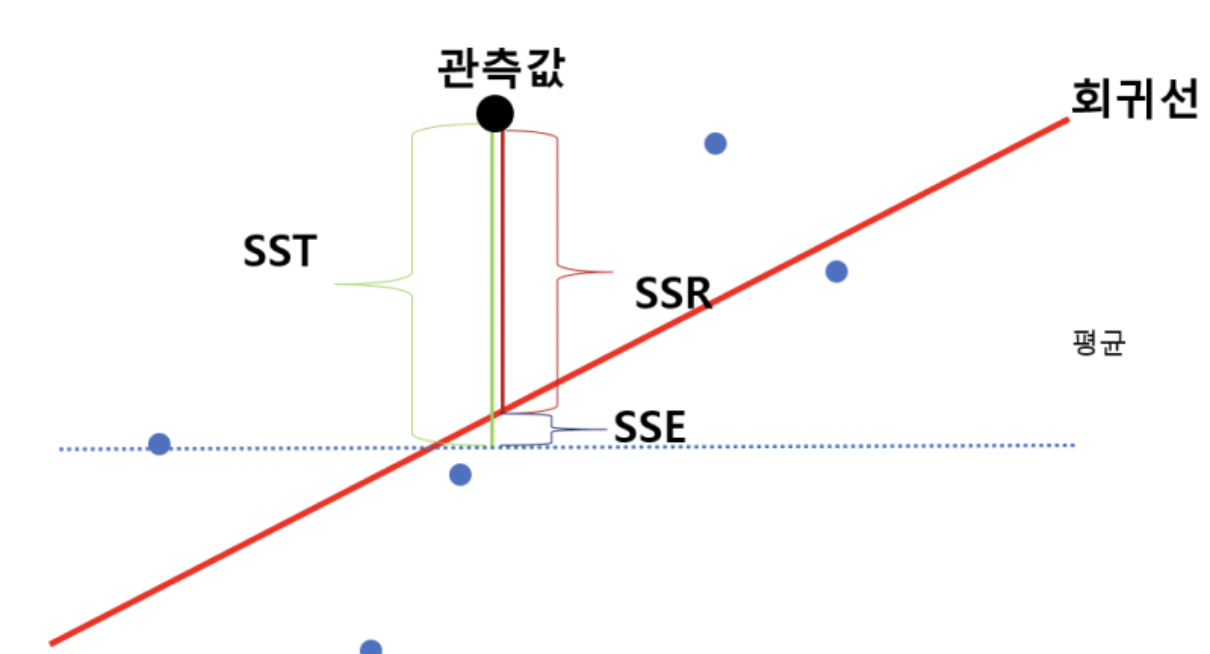
위 그림에서 1 - SSE/SST가 R2 스코어를 계산하는 계산식이 되고 전체 오차를 관측값과 평균 간의 차이라고 할 때 그 중에서 모델이 해결해 낸 오차의 비율을 R2스코어라고 보시면 될 것 같습니다.
분류 모델 성능 평가 지표
분류 모델은 회귀 모델과 달리 0과 1 같은 값들 중에서 하나를 맞추는 것이기 때문에 오차를 줄이는 것이 아닌 정확도를 높이는 것을 목표로 하게 됩니다. 즉 같게 예측한 비율이 얼마나 되는지를 활용하는 지표들이 많습니다.
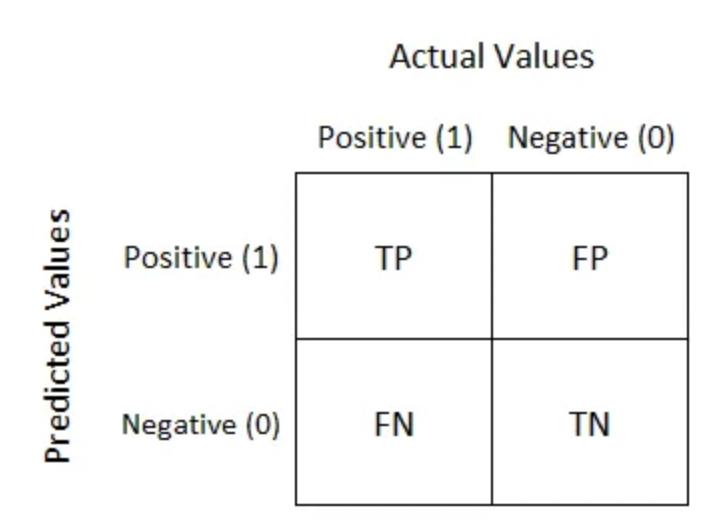
그리고 분류 모델에서의 평가 지표를 이해하기 위해서는 confusion matrix라고 불리는 위의 표를 머릿속에 넣어두고 생각하는 것이 좋습니다. 앞의 글자인 T나 F는 예측이 맞았는지의 여부를 나타내고 뒤의 글자 P나 N은 예측한 값이 positive인지 negative인지를 나타낸다고 보시면 될 것 같습니다. 즉 TP는 positive로 예측을 했고 실제값도 positive여서 옳게 예측된 값이라고 생각하시면 됩니다.
Accuracy
Accuracy는 (TN + TP) / (TN + FP + FN + TP)로 나타나며 즉 전체 중에서 바르게 예측된 비율을 나타내는 지표입니다. 가장 직관적으로 모델의 성능을 확인할 수 있다는 장점이 있습니다.
Precision
정밀도라고 불리며 TP / (FP + TP)로 positive라고 예측한 것 중에서 맞은 비율을 나타냅니다. 잘못 예측 했을 때의 비용이 클 경우 많이 사용되는 지표라고 볼 수 있습니다.
Recall
재현율이라고 불리며 수식으로는 TP / (FN + TP)가 됩니다. 실제 positive인 값들 중에서 예측이 성공한 positive값의 비율을 나타내며 암 발병과 같이 예측을 예측하지 못한 경우의 비용이 클 경우 많이 사용되는 지표입니다.
F1 - score
정밀도와 재현율의 조화 평균으로 정밀도와 재현율이 적절하게 요구될 때 사용됩니다. (2 precision recall) / (precision + recall)의 식으로 계산할 수 있습니다.
이렇게 다양한 평가지표들에 대해서 알아봤고, 이제는 케글 등의 대회에서도 왜 해당 지표가 중요하다고 선정되어 사용되는지 그리고 프로젝트를 진행할 때에도 어떤 지표가 중요한지 판단하고 진행하는데에 위의 내용들을 다시 한 번 확인하며 진행해 볼 수 있을 것 같습니다.
