Introduction
이미지는 다른 감각들을 끌어들이는 힘이 있다. 예를 들어 바다 사진을 보게 되면 우리는 파도의 소리도 느낄 수 있고, 바람의 촉감도 느끼게 될 수 있는 것처럼 말이다. 이런 아이디어 기반해서 meta AI의 연구진들은 이미지의 representation을 기반으로 다른 모달들을 정렬하고자 하는 시도를 했다. 이전에도 특정 모달리티 셋을 기반으로 embedding space를 만들고자 하는 시도들은 있었지만 이 모델들은 해당 조합의 모달리티 데이터에서만 작동이 가능하다는 문제가 있다.
ImageBind
이에 해당 연구진들은 이미지의 끌어당기는 힘 즉 binding property를 강화하고자 했다. 그들은 다른 모달리티들을 이미지를 기준으로 정렬함으로써 학습되지 않은 조합의 데이터들에 대해서도 task가 가능한 emergent zero shot alignment가 가능해졌다고 한다. 이를 통해 해당 연구에서는 모든 모달리티를 포함하는 하나의 임베딩 공간을 구성할 수 있게 된다.
Related Work
관련 연구로 해당 논문에서는 이전의 Language Image Training에 대해서 설명한다. 이전에도 다른 모달리티 간의 관계성을 통해 하나의 embedding space를 만들고자 하는 시도는 있었고 대표적으로는 CLIP이 있다. CLIP에서는 언어 즉 단어나 문장을 supervision으로 사용하여 다양한 zero-shot task에서 좋은 성능을 보였다.
또한 이러한 CLIP을 기반으로 다른 모달리티 또한 추가하고자 하는 연구들도 존재했지만 그 연구들 또한 해당하는 모달리티가 모두 포함되어 있는 데이터가 필요하다는 점에서 어려움이 있다.
Method

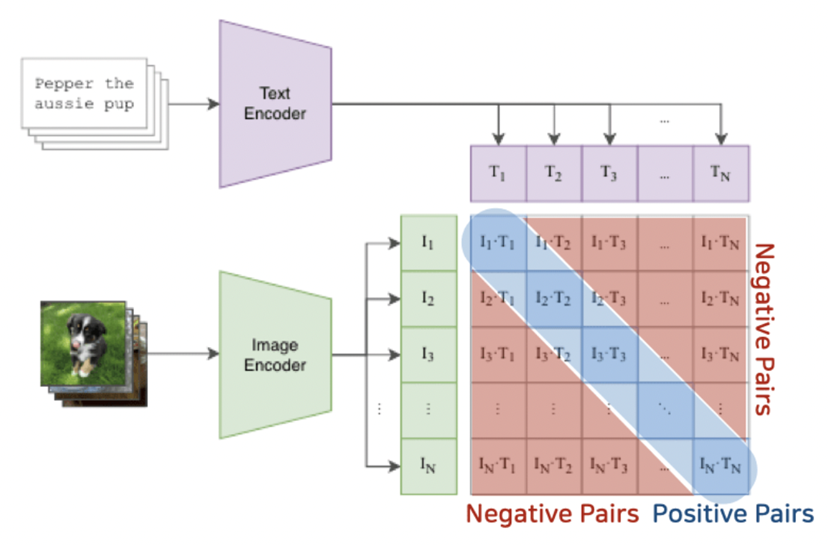
이러한 문제들을 해결하기 위해 해당 논문에서는 ImageBind라는 방법론을 제시한다. 이름에서도 알 수 있듯 해당 방법론은 image를 anchor로 하여 서로 다른 모달리티를 하나의 embedding space에 구성하게 된다. 앞에서 언급했던 emergen zeor-shot alignment에 좋은 성능을 보이는데 예를 들자면 해당 모델은 이미지를 베이스로 하기 때문에 (이미지, 텍스트) 쌍과 (이미지, 오디오) 쌍으로는 학습이 되었지만 (텍스트, 오디오)로는 학습되지 않았음에도 (텍스트, 오디오)를 기반으로 하는 task들에서도 좋은 성능을 보인다.
Binding modalities with image
다른 많은 모델이 그러하듯 imagebind에서도 contrastive learning을 기반으로 학습하게 된다. 관련 oberservation은 positive이고 관련이 없는 observation은 negative로 취급한다. 각각의 모달리티에 대해 Image와 쌍을 이루는 데이터를 활용해 학습하게 된다. (Image, modal1), (Image, modal2)와 같은 형식으로 학습 데이터가 이루어졌다고 볼 수 있다.
Implementation Detail
각각의 모달리티를 인코딩하기 위해 독립적인 인코더들을 활용한다. 텍스트를 제외한 나머지 모달리티에는 ViT를 베이스로 하고 있는 인코더를 사용한다. 그리고 dimension을 맞춰주기 위해 각각에 대해 linear projection head를 두고 있고 이러한 방법을 통해 OpenCLIP와 같은 pretrined model 또한 쉽게 적용할 수 있다.
Experiments
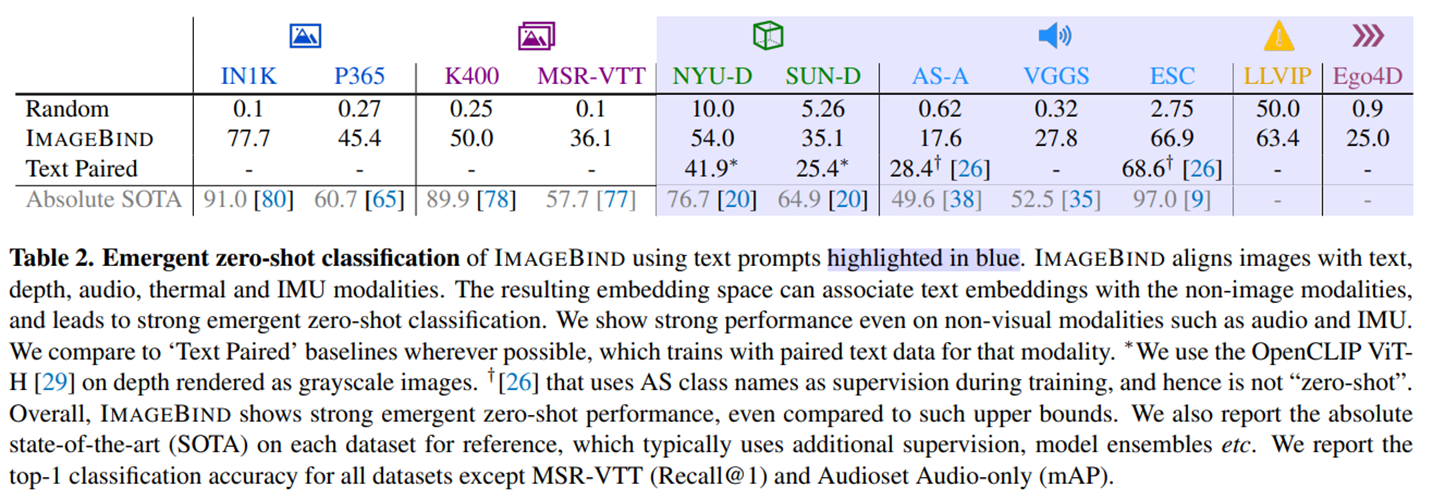
앞에서도 언급했듯 해당 논문에서는 emergent zero-shot이라는 새로운 방식의 성능 지표를 제안한다. 그렇기에 합리적으로 비교할 대상은 존재하지 않지만 supervised로 학습된 모델들과 비교함으로써 어느정도 좋은 성능을 보이고 있다는 것을 특히 학습되지 않은 모달리티 조합에 대해서도 좋은 성능을 보인다는 것을 주장하고 있다.
Multimodal embedding space arithmetic
또한 ImageBind에서는 임베딩 간의 연산이 가능하다.

위 예시처럼 다른 모달의 임베딩을 연산을 통해 새로운 결과물을 만들어내는 것또한 가능해진다.
Upgrading text-based to audio based

또한 텍스트 프롬프트를 필요로 하는 감지 모델이나 생성 모델에서도 해당 임베딩을 다른 모달의 임베딩으로 교체하는 것 만으로 다른 모달을 베이스로 하는 감지 모델 또는 생성 모델로의 사용이 가능해진다.
