tf.keras.preprocessing.sequence.pad_sequences(
sequences, maxlen=None, dtype='int32', padding='pre',
truncating='pre', value=0.0
)이 함수는 Sequences로 이루어진 리스트를 넘파이 2d 배열로 바꿔주는 함수이다. 리턴되는 배열의 형태는 (num_samples, num_timesteps)로 출력된다. 각 파라미터들의 역할을 살펴보자.
-
sequences: 바꾸고자 하는 sequences들이 들어있는 리스트를 넣어주면 된다. -
maxlen: sequence를 원하는 길이로 바꿔줄 때 사용하는 파라미터이다. default 값은 리스트 내 요소의 최대길이로 리턴해준다. -
dtype: 원하는 데이터 타입을 넣어주면 된다. -
padding: 길이를 맞춰줄 때 padding 을 넣어주는 방식을 정해주는 파라미터이다. 인자값으로는 pre/post가 있고 default 값은 pre 이다. pre는 전, post는 후에 padding을 넣어준다. -
truncating: 리스트 내 sequence가 maxlen보다 길어서 잘라줄 때 사용하는 파라미터이다. padding과 마찬가지로 인자값으로는 pre/post가 있고 default값은 pre 이다. -
value: padding을 넣어줄 때 값을 지정하는 파라미터이다. default값은 0 이다.
간단한 예제를 통해 결과값을 살펴보자
from tensorflow.keras.preprocessing.sequence import pad_sequences
data = [[1,2,2,3],
[3,7,6,5,3],
[8,1,2,6,8,4,1,6]]
pad_sequences(data, padding="post")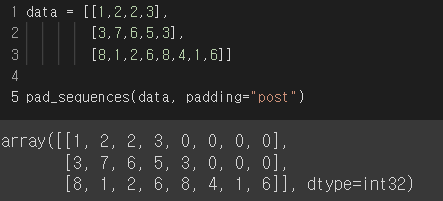
padding 을 "post"로 설정하니 padding값이 sequence의 뒤로 들어간 것을 확인할 수 있다.
이번에는 maxlen을 리스트 내 sequence의 최대길이보다 작은 수를 넣어보자.
data = [[1,2,2,3],
[3,7,6,5,3],
[8,1,2,6,8,4,1,6]]
pad_sequences(data, maxlen = 6,
padding="post", truncating="post")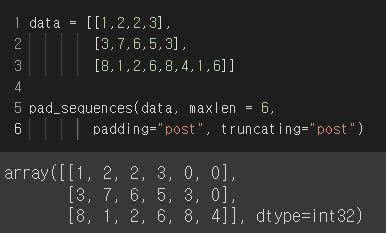
maxlen 을 6으로 설정하고 truncating 을 "post"로 설정하니 길이가 6이 넘을때 뒤에서 잘라주는 것을 확인할 수 있다.
여기까지 sequence를 요소로 갖고 있는 리스트에 padding을 넣어주는 함수 pad_sequences 를 살펴 보았다.
