
5. 회원 관리 예제 - 웹 MVC 개발
ⓐ 회원 웹 기능 - 홈 화면 추가
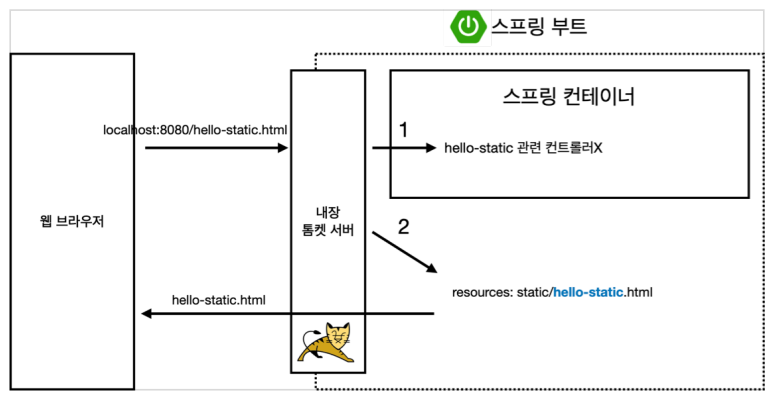
'우선순위' 有
요청이 오면 ① 스프링 컨네이너 안에 관련 컨트롤러가 있나 먼저 찾고, ② 없으면 그때 static 파일 찾도록 되어있음
controller로 지금 home page가 home.html이 지정이 되어있기 때문에 static의 index.html은 무시가 되고 home.html이 보여짐
ⓑ 회원 웹 기능 - 등록
<input type="text" id="name" name="name" placeholder="이름을 입력하세요">에서
name="" => 서버로 넘어올 때의 '키'
Mapping의 url은 동일하지만, get이냐, post냐에 따라서 다르게 mapping할 수 있음
- post : 데이터를 폼 같은 것에 넣어서 등록할 때 주로 사용
- get : url에 직접 쳐서 조회할 때 주로 사용
cf) 스스로 더 알아보면 좋은 사항
- http의 post & get 메서드
- <form> 태그
ⓒ 회원 웹 기능 - 조회
members 리스트 자체를 model에다 다 담아서 view template에 넘김
<tr th:each="member : ${members}">
<td th:text="${member.id}"></td>
<td th:text="${member.name}"></td>
</tr>에서
th:each="" => <thymeleaf 문법> loop 돌기 (JAVA의 for each 문법과 유사)
↓ thymeleaf를 통해 변환된 html ↓
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Member List</title>
</head>
<body>
<div class="container">
<table>
<thead>
<tr>
<th>#</th>
<th>이름</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>spring1</td>
</tr>
<tr>
<td>2</td>
<td>spring2</td>
</tr>
<tr>
<td>3</td>
<td>네네치킨</td>
</tr>
</tbody>
</table>
</div> <!-- /container-->
</body>
</html>getter, setter 접근 방식 => "property 방식의 접근"
memory에 있기 때문에 서버를 내렸다가 다시 올리면 데이터가 다 지워짐.
그래서 이 데이터들을 파일이나 DB에다 저장을 해둬야 함
6. 스프링 DB 접근 기술
memory => 휘발성
따라서 memory가 아닌 "DB"에 데이터를 저장/관리해볼 예정.
H2 데이터베이스 : 아주 가볍고 심플한 DB
DB 설치 후에는 SQL을 가지고 애플리케이션 서버와 DB를 연결해볼 것.
이때 필요한 기술이 'JDBC'.
일단은 20년에 사용했던 '순수 JDBC'를 경험해볼 것임.
아무래도 개발이 힘듦
→ 스프링이 제공하는 JdbcTemplate 기술 => 애플리케이션에서 DB로 SQL을 편리하게 날릴 수 있음
→ (더 혁신적인 방법) JPA => SQL조차도 개발자들이 직접 짜지 않고 JPA를 통해 DB에 SQL 쿼리를 날릴 수 있도록 함 (책 추천 : 'JPA 프로그래밍'). JPA를 쓰면 객체를 바로 DB에 쿼리 없이 저장/관리 가능
→ 스프링 데이터 JPA : JPA를 편리하게 쓸 수 있도록 한 번 감싼 기술
회원 객체에 이 기술들을 다 적용해보면서 한 단계씩 바꿔볼 예정.
memoryRepository → jdbcRepository → jpaRepository
ⓐ H2 데이터베이스 설치
mySQL 계열의 DB를 많이 쓰게 될 것
H2 DB : 교육용으로 좋음 / 가볍고 용량 작음 / 웹의 화면도 제공해줌
H2 Console에서 '연결'하면 test.mv.db 파일이 사용자 홈에 만들어질 것.
http:// localhost :8082/login.jsp?jsessionid=...
이후부터는 파일로 접근하지 말고 (애플리케이션이랑 웹 콘솔이랑 동시 접근이 안 되고 오류가 날 수 있기 때문) 아래와 같이 '소켓'을 통해 접근할 것. 그래서 여러 곳에서 동시에 접근할 수 있도록 함.
jdbc:h2:tcp://localhost/~/test
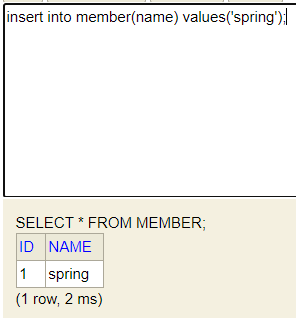
drop table if exists member CASCADE;
create table member
(
id bigint generated by default as identity,
name varchar(255),
primary key (id)
);generated by default as identity => 값 세팅하지 않고 넣어주면 DB가 알아서 값을 채워줌
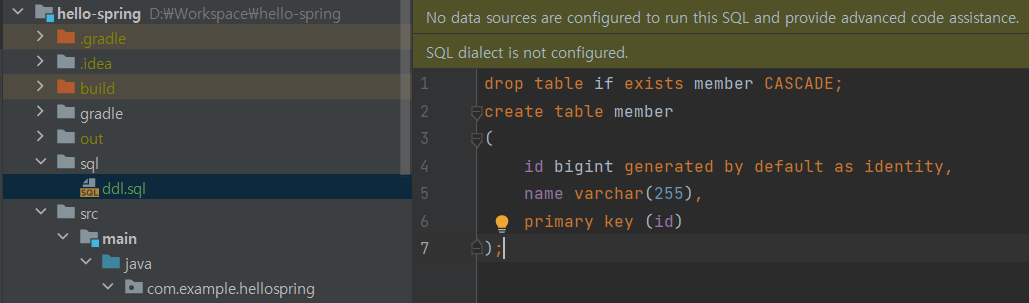 sql 디렉토리와 그 안에 ddl.sql이라는 파일을 파서 sql의 ddl을 관리하는 걸 권장.
sql 디렉토리와 그 안에 ddl.sql이라는 파일을 파서 sql의 ddl을 관리하는 걸 권장.
지금은 '웹 콘솔'로 들어갔는데, 다음부터는 우리가 만든 애플리케이션에서 이 DB에 접근해서 데이터를 넣고 빼고 해볼 예정.
ⓑ 순수 JDBC
애플리케이션에다 DB에 연동해서 DB에 쿼리를 날려 데이터를 넣고 빼볼 것임.
굉장히 오래된 방법... 그냥 참고로만 알아둘 것. 데이터 저장 기술의 역사 정도 알아보려고 하는 활동.
① build.gradle 파일에 jdbc, h2 데이터베이스 관련 라이브러리 추가
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'com.h2database:h2'두 개의 라이브러리
- jdbc => JAVA는 기본적으로 DB랑 붙으려면 JDBC 드라이버가 꼭 있어야 함
- h2database:h2 => DB가 제공하는 클라이언트
아래 버튼 눌러서 gradle sync
② 스프링 부트 데이터베이스 연결 설정 추가
resources/application.properties 파일에 아래 코드 작성
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa※ 공백은 모두 제거할 것
이렇게 DB에 접근하기 위한 준비 완료.
③ Jdbc 리포지토리 구현
repository/JdbcMemberRepository 생성
DB에 붙으려면 DataSource라는 것이 필요함 (import javax.sql.DataSource;)
스프링한테서 dataSource를 주입 받아야 함
dataSource.getConnection() => DB connection을 얻음. 여기에다 sql문 날려서 DB에 전달하면 되는 것.
원리는 간단하지만... 코딩이 엄청남
코드 => 강의자료 참고 -- 앞으로 이렇게 쓸 일도 없고 매우 복잡해서 그냥 아 이렇게 복잡했었구나 정도로 알아두고 일단은 넘어가기
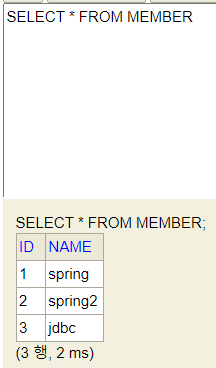
④ 스프링 설정 (SpringConfig) 변경
MemoryMemberRepository() → JdbcMemberRepository() 로 변경
DataSource
=> DataSource : 데이터베이스 커넥션을 획득할 때 사용하는 객체
=> 스프링 부트는 데이터베이스 커넥션 정보를 바탕으로 DataSource를 생성하고 스프링 빈으로 만들어둔다. 그래서 DI를 받을 수 있다.
=> @Autowired 해놓으면 스프링이 자동으로 주입해줌

# 정리
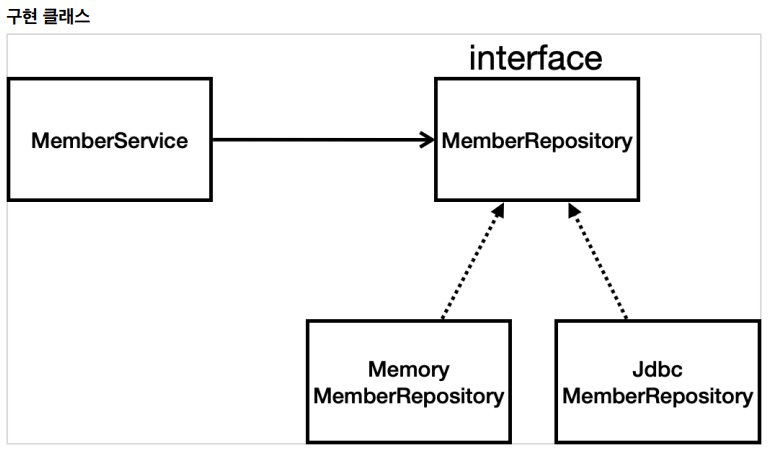
객체지향적 설계가 왜 좋은가?
=> 다형성 ; 인터페이스를 두고 구현체를 바꿔 끼워넣을 수 있음
=> 스프링 : 다형성을 편리하게 적용할 수 있도록 '스프링 컨테이너'가 이를 지원해줌 & 'DI(dependency injection)' 덕분에 굉장히 편리하게 가능
'객체 지향 설계 (SOLID)' 中,
'개방-폐쇄 원칙(OCP, Open-Closed Principle)'
=> 확장에는 열려있고, 수정, 변경에는 닫혀있다.
스프링의 DI (Dependencies Injection)을 사용하면 기존 코드를 전혀 손대지 않고, 설정만으로 구현 클래스를 변경할 수 있다
SpringConfig 파일의 코드만 딱 손대면 다른 코드들은 손댈 필요 없게 됨
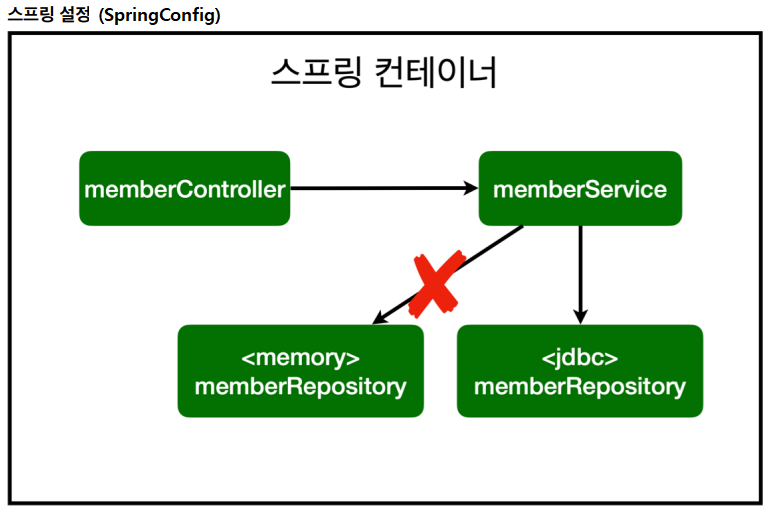
데이터를 DB에 저장하므로 스프링 서버를 다시 실행해도 데이터가 안전하게 저장된다.
ⓒ 스프링 통합 테스트
test도 Spring부터 DB까지 실제 다 연결시켜 통합적으로 테스트를 해보자!
이전에 한 테스트들은 spring과 관련없이 순수 자바 코드만을 가지고 테스트 해본 것임
근데 이제는 순수 자바 코드만으로 테스트 할 수 없는 상황임. 왜냐하면 DB connection 정보도 스프링 부트가 들고 있기 때문.
그래서 이제는 테스트를 스프링과 엮어서 해볼 예정.
@SpringBootTest
@Transactional
=> '스프링이' 테스트 할 때 2가지 꼭 적기
@SpringBootTest => 스프링 컨테이너와 테스트를 함께 실행한다. 진짜 스프링을 띄워서 테스트를 하는 것 ; 스프링 '통합' 테스트
beforeEach() 코드 삭제
beforeEach()에서는 직접 객체 생성해서 넣었는데
이제는 그게 아니라 스프링 컨테이너한테 MemberService, MemberRepository 내놓으라고 해야 함
그런데 기존 코드들은 '생성자 injection'이 좋은데, 테스트는 제일 끝단에서 테스트만 하고 끝낼 거기 때문에 제일 편한 방법 쓰면 됨
따라서 그냥 @Autowired만 앞에 붙여주는 '필드 injection'으로 처리.
@Autowired MemberService memberService;
@Autowired MemoryMemberRepository memberRepository;afterEach() 코드도 삭제
@Transactional 때문에 afterEach() 필요 없게 됐기 때문.
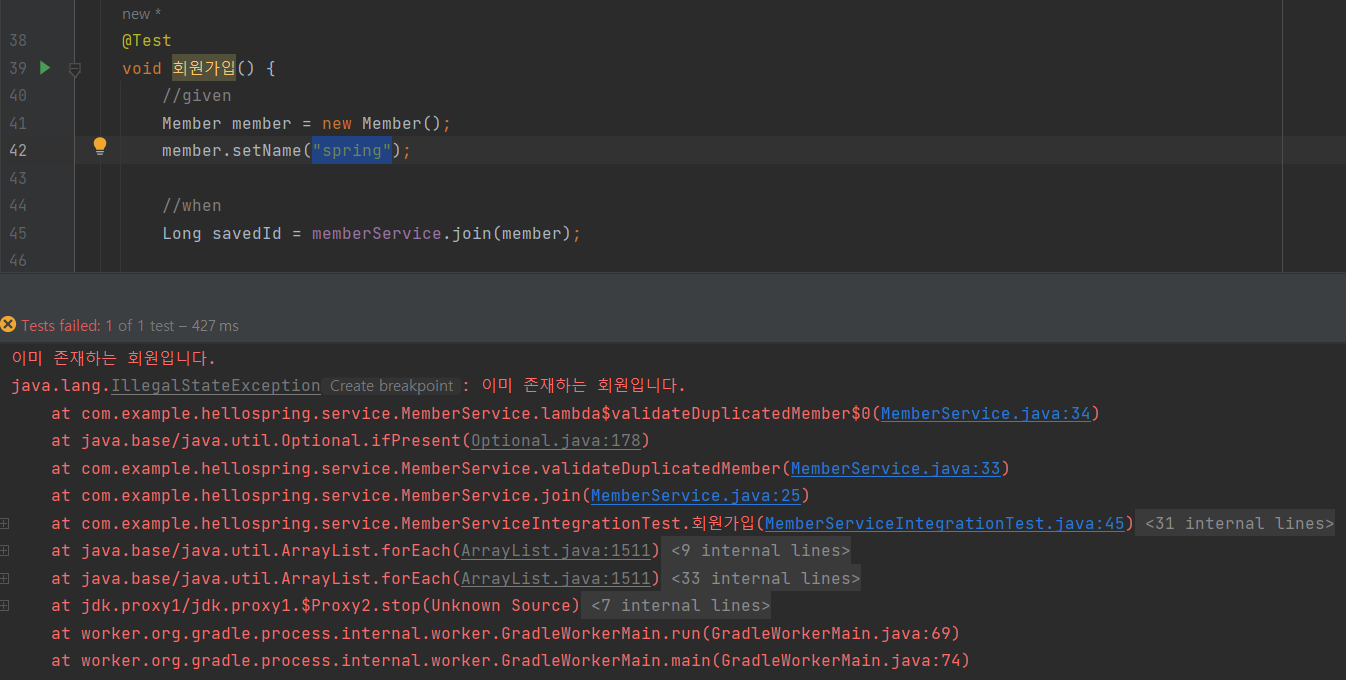
에러 발생 이유 : DB에 데이터가 남아있었기 때문.
따라서 DB의 데이터들을 완전히 지워주고 test를 실행해야 함
실무에서는 test 전용 DB를 따로 구축함
찐 DB 아님.
delete from member테스트는 '반복 가능'해야 함
테스트할 때마다 DB 데이터 지워주지 않으면 동일 test지만 두 번째부터는 DB의 데이터가 반영돼 또 에러 발생하게 됨.
DB는 기본적으로 '트랜잭션'이라는 개념 有
그래서 DB의 데이터를 insert query한 다음에 'commit'이라는 걸 해줘야 DB에 진짜 반영이 됨
그게 아니면 'auto commit' 모드인 거임
무조건 commit 과정은 필요함
DB에 insert query 다 날리고 rollback 해버리면 DB에서 그 데이터들이 반영이 안 되어버림
=> @Transactional
@Transactional을 테스트 케이스에다 달면 test를 실행할 때 transaction을 먼저 실행하고 DB에 insert query 다 날리고 테스트 끝나면 항상 rollback을 해줌. 그래서 DB에 넣었던 데이터들이 반영 안 되고 깔끔하게 지워지도록 함
(테스트 케이스에다 달면 rollback 하는 거고, service 같은 곳에 달면 rollback 하지 않고 정상적으로 돎)
@Transactional 안 붙여줬을 때는 test 끝나고 DB 조회해보면 넣어줬던 member 데이터가 남아서 보여졌는데,
@Transactional 붙여줬을 때는 항상 DB가 깔끔하게 rollback 되어있는 상태로 보여짐
즉, 다음 테스트를 또 반복해서 실행할 수 있다는 거고,
이전처럼 afterEach() 코드로 매번 지우지 않아도 된다는 것임
@Commit 애노테이션을 굳이 붙이면
테스트 끝나고 commit을 해버림
근데 그럼 스프링 없이 순수한 자바 코드로 하는 테스트는 필요 없지 않나?
=> Nope.
순수한 자바 코드로 하는 테스트 => '단위 테스트'
스프링 컨테이너와 DB까지 연동해서 하는 테스트 => '통합 테스트'
단위 테스트가 테스트 속도 훨씬 빠름. (스프링을 띄울 필요가 없으니까)
단위 테스트가 훨씬 좋은 테스트일 확률이 높음.
단위단위별로 쪼개서 테스트를 잘 할 수 있도록 하고, 스프링 컨테이너 없이도 테스트 할 수 있도록 훈련하는 게 좋음.
컨테이너까지 어쩔 수 없이 올려야 테스트가 가능한 상황은 높은 확률로 테스트 설계가 잘못됐을 거임.
따라서 단위 테스트를 잘 만드는 게 훨씬 더 좋은 테스트임.
ⓓ 스프링 JdbcTemplate
스프링 JdbcTemplate 설정 :
implementation 'org.springframework.boot:spring-boot-starter-jdbc'스프링 JdbcTemplate & MyBatis 같은 라이브러리 :
'반복' 코드를 '제거'해줌
BUT sql은 직접 작성 必
스프링 JdbcTemplate => 실무에서도 多 사용
JdbcTemplate이라는 게 有
JdbcTemplate은 injection을 받을 수 있는 건 아님
그래서 DataSource를 injection 받고, JdbcTemplate에다 dataSource를 넣어주는 방식으로 쓰면 됨
생성자가 딱 1개이고 스프링 빈에 등록이 되어있다면
@Autowired를 생략 가능
생성자가 2개 이상이라면 생략 불가
java 8의 lambda 스타일로 변환 가능
'그냥' jdbc랑 비교해보면, findById() 메소드만 해도 코드 길이가 엄청나게 차이가 남
SimpleJdbcInsert => 쿼리 짤 필요가 없음 (document 참고하면 친절하게 잘 나와있음)
test 잘 작성하는 게 정말 중요. production이 커지면 커질수록 더 중요.
다음 시간에는 이 쿼리까지 다 없애버릴 수 있는 'JPA'에 대해 학습할 예정.
ⓔ JPA
JDBC -> JDBC Template으로 변경하니까 개발해야 하는 코드가 확 줄었음
하지만 아직도 해결 안 된 부분 : sql은 개발자가 아직도 직접 작성해야 한다는 점
BUT 이제 JPA를 사용하면 sql 쿼리도 JPA가 자동으로 처리해줌
=> 개발 생산성 ↑
마치 MemoryMemberRepository에서 객체를 메모리에 넣듯이, JPA를 넣으면 JPA가 중간에서 DB에 SQL 날리고 DB를 통해 데이터를 가져오는 거를 다 JPA가 처리해줌
패러다임의 전환 : SQL & 데이터 중심의 설계 -> 객체 중심의 설계
김영한의 'JPA 프로그래밍' 추천
기술적인 깊이&너비 엄청남
스프링에서 JPA 관련 지원도 엄청 함
build.gradle에서 이제
jdbc 라이브러리는 없애고
data-jpa를 추가해 넣으면 됨
jpa랑 jdbc 등 다 포함함
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
application.properties에도 jpa 관련 설정 추가해줄 것
spring.jpa.show-sql=true
=> JPA가 날리는 SQL 볼 수 있음
spring.jpa.hibernate.ddl-auto=none
=> JPA 사용하면 객체를 보고 지가 테이블도 다 만들어버림. 근데 우리는 이미 테이블 만들었고 그 테이블을 쓸 거기 때문에 none으로 설정해둠
create로 두면 테이블 만들어줌
JPA를 쓰기 위해서는 entity를 매핑해야 함
JPA는 '표준 인터페이스'임
그 구현 기술들로 hibernate, eclipse 등등이 있는 것임
그 중 웬만하면 jpa 인터페이스의 hibernate만 쓴다고 보면 됨
JPA : 객체 + ORM
ORM : Object와 Relational database의 테이블을 Mapping한다
mapping을 어떻게 하냐? => 어노테이션으로.
@Entity
=> jpa가 관리하는 entity
@Id => pk 매핑
@GeneratedValue(strategy = GenerationType.IDENTITY)
=> db가 id를 자동 생성해줌
이렇게 어노테이션들을 가지고 DB와 매핑시키는 거임
그렇게 해놓으면 매핑시킨 정보들을 가지고 JPA가 insert문, delete문 등등을 만들어내는 것
Repository 만들기!
EntityManager
=> JPA는 entity manager로 모든 게 동작함
아까 라이브러리로 data-jpa를 받아놨으면 스프링 부트가 자동으로 EntityManager를 생성해줌 현재 db와 연결까지 다 해줘서.
그래서 우리는 이 만들어진 걸 injection 받으면 됨
EntityManager는 dataSource도 다 들고 있어서 db 통신도 내부에서 처리해줌
결론 : JPA 쓰려면 EntityManager를 주입 받아야 한다
persist => 영속하다, 영구 저장하다
JPQL : 보통 '테이블'을 대상으로 쿼리를 날리는데, 그게 아니라 "entity"를 대상으로 쿼리를 날리면 sql로 번역되는 쿼리 언어
"select m from Member m"
select의 대상이 m이라는 member entity 자체임
저장, 조회, 업데이트, 삭제에 대한 sql을 짤 필요 없었음
다 자동으로 만들어짐
단, findByName(), findAll() 같이, pk 기반이 아니고 하나의 건이 아닌 여러의 건을 다루는 경우는 JPQL이라는 것을 작성해줘야 함
이 다음 시간에는 이 JPA 기술을 스프링에 감싸서 제공하는 기술인 '스프링 데이터 JPA'를 배우게 될 텐데,
그걸 사용하면 findByName(), findAll()마저도 JPQL 안 짜도 되게 됨
JPA를 쓰려면 주의해야 할 게,
항상 @Transactional 있어야 함
데이터를 저장/변경하려면 꼭 있어야 함
MemberService에다.
이제 돌려보기 위해서
SpringConfig에서 EntityManager를 injection 받아서 JpaMemberRepository에 넣어주기
통합 테스트 돌려보기
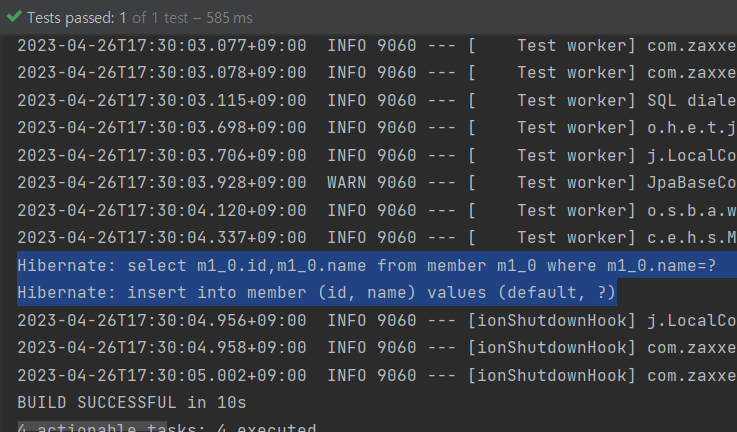
의심된다면 @Commit까지 붙여서 db에 반영된 결과 확인해 볼 것

jpa 현직에서 정말 많이 사용함
실무에서 jpa를 쓰려면 정말 깊게 공부해봐야 함
추천 강의 : '자바 ORM 표준 JPA 프로그래밍 - 기본편'
다음 시간에는 이 JPA에 스프링까지 가세해서 더 엄청나게 할 수 있는 '스프링 데이터 JPA'에 대해 배워볼 예정임
ⓕ 스프링 데이터 JPA
'스프링 데이터 JPA 회원 리포지토리'를 만들어보겠음
이때 java class가 아니라 interface를 만들 것임
우선 jpa는 JpaRepository 인터페이스를 받아야 함
첫 번째 T는 Member, 두 번째 id는 entity에서 식별자 pk를 말하기 때문에 Long으로 둚
인터페이스는 '다중 상속'이 가능하기 때문에 여기다 MemberRepository도 받음
그리고 안에 Optional findByName(String name);만 적어주면.... 끝임!!!!!!
인터페이스 안에 구현체도 없고, 다른 메서드도 다 어디 간 것이냐??? -- 이따 설명 예정..
JpaRepository를 받고 있으면 스프링 데이터 JPA가 인터페이스를 가지고 구현체를 자동으로 만들어서 스프링 빈에도 자동으로 등록해줌. 우리는 그걸 그냥 가져다 쓰기만 하면 됨
SpringConfig 수정
@Autowired (생성자 하나라 생략 가능)
MemberRepository를 injection 받으면 됨. 그러면 스프링 데이터 JPA가 만들어놓은 구현체가 등록이 됨
그리고 memberService에다 의존관계 세팅해주기
스프링 컨테이너에서 멤버 레포지토리를 찾는다
-> 근데 등록해둔 게 없음
-> 근데 SpringDataJpaMemberRepository 인터페이스 & 거기에 extends로 JpaRepository(스프링 데이터 JPA가 제공하는 것), MemberRepository가 받아져있으면 스프링 데이터 JPA가 인터페이스에 대한 구현체를 지가 알아서 만들어내고 스프링 빈에다 등록도 해둠.
-> 그러면 우리는 그걸 injection으로 받아서 memberService에다 등록해주면 됨
테스트 해보면.... 성공!!
스프링 데이터 jpa가 jpa 기술 가져다 쓰는 거라 로그 똑같이 나옴
이제 아까 질문(인터페이스 안에 구현체도 없고, 다른 메서드도 다 어디 간 것이냐???)에 대한 답
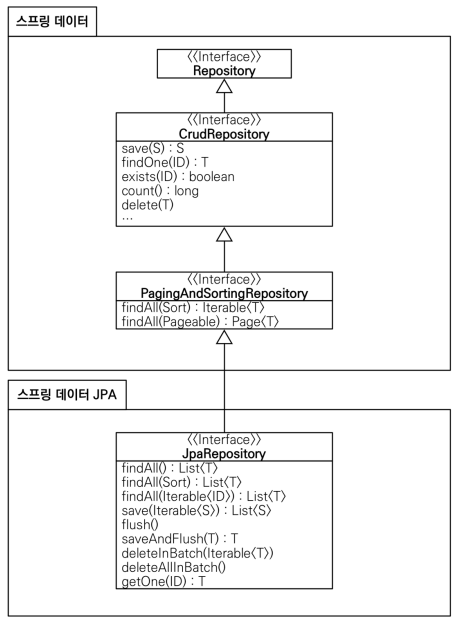
아까 extends로 받은 org.springframework.data.jpa의 JpaRepository를 자세히 들여다보면, 기본 메서드들이 제공되는 걸 확인해볼 수 있음
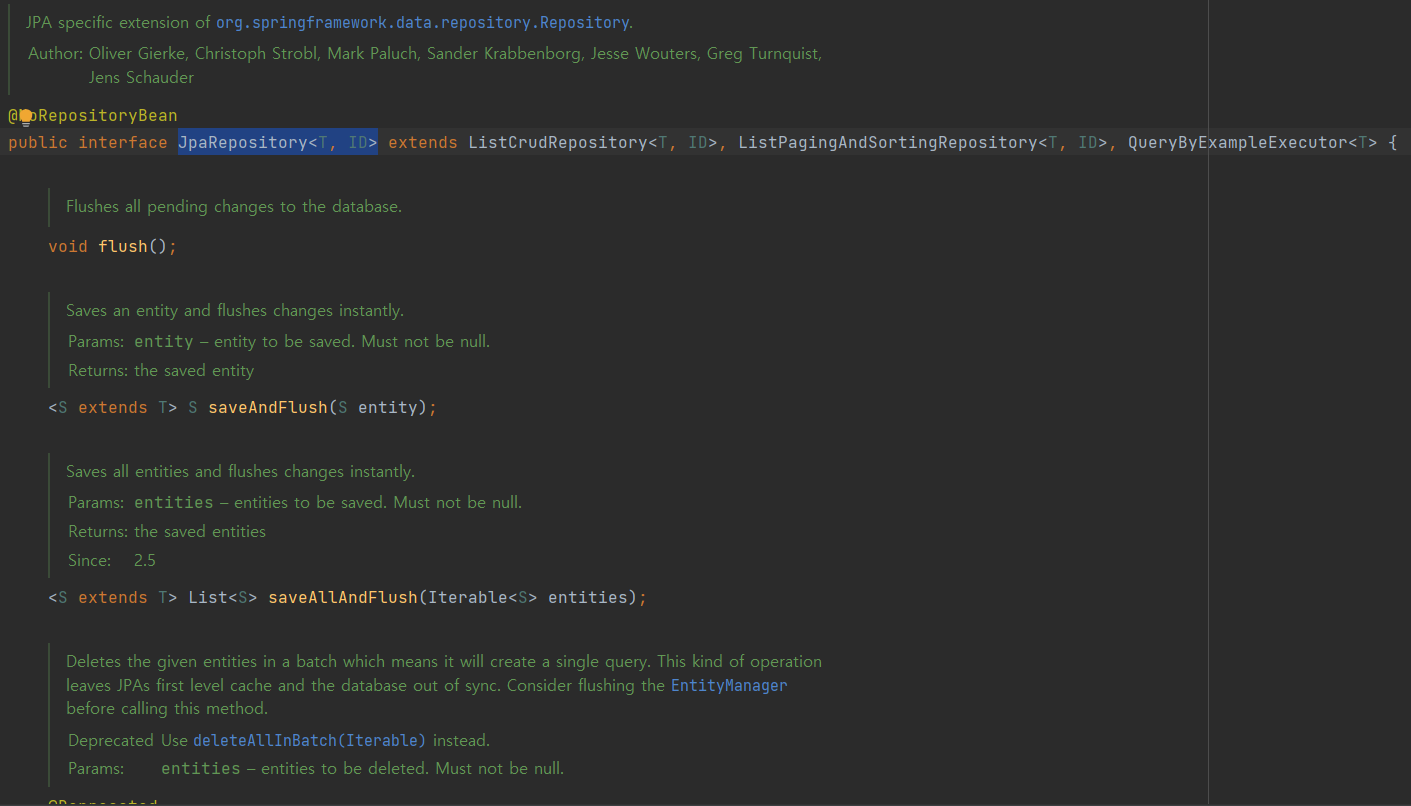
PagingAndSortingRepository도 extends 받고 있어서 페이징 처리 및 조회도 해줌
CrudRepository도 extends로 받고 있어서 이곳에 내가 만들었던 save(), findById() 등등이 이미 작성되어있음
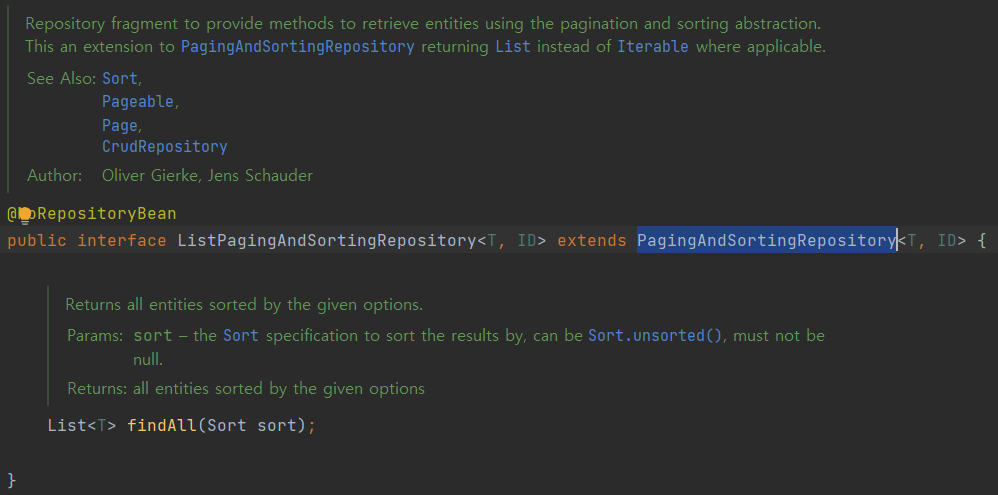
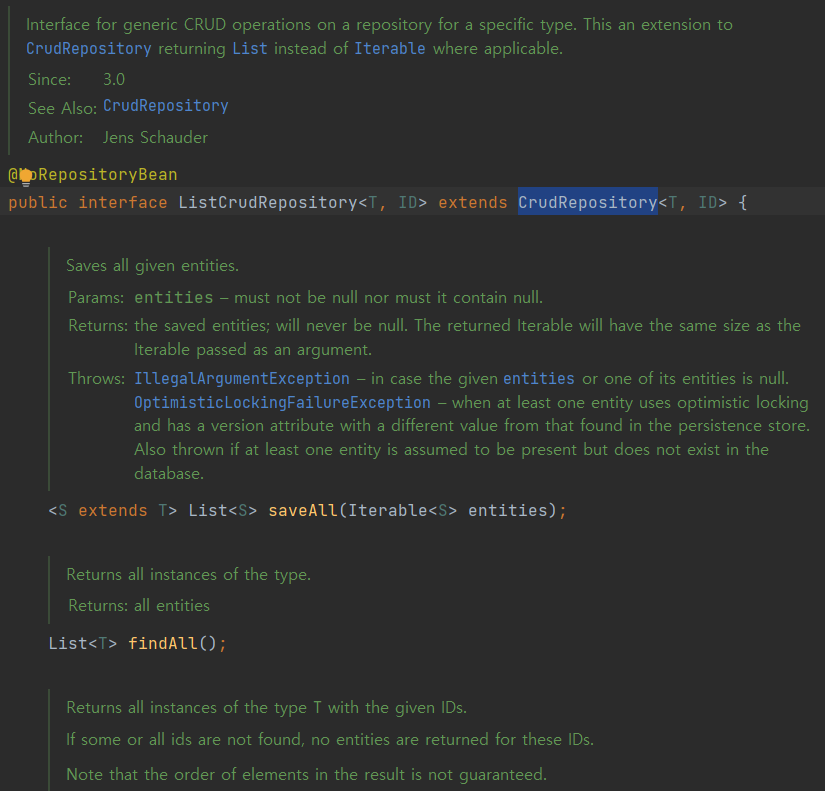
즉, 기본적인 CRUD와 단순 조회들이 다 제공이 됨
그런데 이런 '공통' 인터페이스에서 못 만드는 게 findByName()이라 그것만 아까 SpringDataJpaMemberRepository에서 작성해줬던 거임
이름(findByName()), 이메일 등등으로 찾는 건 비즈니스마다 다르기 때문에 '공통' 클래스로 제공할 수가 없음
그래서 findByName()을 써줘야 함
이때 '규칙'이 있음
findByㅇㅇㅇ()이면 알아서 JPQL 쿼리를 select m from Member m where m.ㅇㅇㅇ = ? 로 짜줌. 그러면 이제 sql로 번역이 돼서 실행이 되는 것
이런 식으로 findByNameAndId(String name, Long id)으로 작성도 가능
규칙엔 여러 가지 있으니까 찾아보면 될 것
이렇게 '인터페이스의 이름'만으로도 개발이 끝나게 되는 것!!!
쿼리의 약 80%를 차지하는 '단순한' 쿼리는 인터페이스만으로 끝이 나는 것임
이게 스프링 데이터 JPA가 부리는 마법..
쿼리의 약 20%를 차지하는 '복잡한' 쿼리(ex. 동적 쿼리)는 Querydsl이라는 라이브러리를 사용하면 됨
JPA를 실무에서 딥하게 하는 사람들은 JPA, 스프링 데이터 JPA, Querydsl 기술을 다 조합해서 씀
그래도 해결하기 어려운 쿼리는 JPA가 제공하는 네이티브 쿼리를
사용하거나, 앞서 학습한 스프링 JdbcTemplate를 사용
jpa랑 MyBatis를 섞어쓰는 것도 가능
자세한 건 '인프런 - 실전! 스프링 데이터 JPA' 강의 참고
# 정리 - '스프링 DB 접근 기술'
- H2 데이터베이스 설치
- 순수 Jdbc
=> 쿼리 하나하나가 어마어마했음 - 스프링 통합 테스트
- 스프링 JdbcTemplate
=> 반복되는 코드 굉장히 줄어들지만, sql을 내가 직접 작성했어야 했음
JPA => 기본적인 CRUD & 기본적인 쿼리 제공함. 단, select할 때는 JPQL을 직접 짜야 함 - 스프링 데이터 JPA
=> 구현 클래스를 아예 작성할 필요 없이 인터페이스만으로 개발이 끝남 + findByㅇㅇㅇ()도 제공해줌
실무에서는 서버 관련 모든 걸 두루두루 잘 알고 있어야 함
그래서 서버 개발자들 대우가 좋은 편... ㅎ
관련해서 더 깊은 내용은 '[중급~활용] 김영한의 스프링 부트와 JPA 실무 완전 정복 로드맵'을 참고해보면 좋을 것
7. AOP
AOP를 이론적으로 공부하면 뭐 이상한 용어들 막 나오고 해서 공부하다 포기하는 사람들 많은 파트임 (like C언어의 포인터 파트.. ㅋㅋ)
근데 AOP를 언제, 왜 쓰는지를 알면 전혀 어렵지 않음
디테일한 이론이나 용어는 나중에 차차 더 알아가면 됨
ⓐ AOP가 필요한 상황
1000개 이상의 모든 메소드의 호출 시간을 호출해야 하는 상황을 떠올려보자
진짜 직관적으로 호출 시간 잰다면
public Long join(Member member) {
long start = System.currentTimeMillis();
try {
validateDuplicateMember(member); //중복 회원 검증
memberRepository.save(member);
return member.getId();
} finally {
long finish = System.currentTimeMillis();
long timeMs = finish - start;
System.out.println("join = " + timeMs + "ms");
}
}try finally 문으로, 에러가 발생해도 무조건 호출시간은 로그에 찍도록.
그러고 test 코드 돌려보면 로그 찍힐 것.
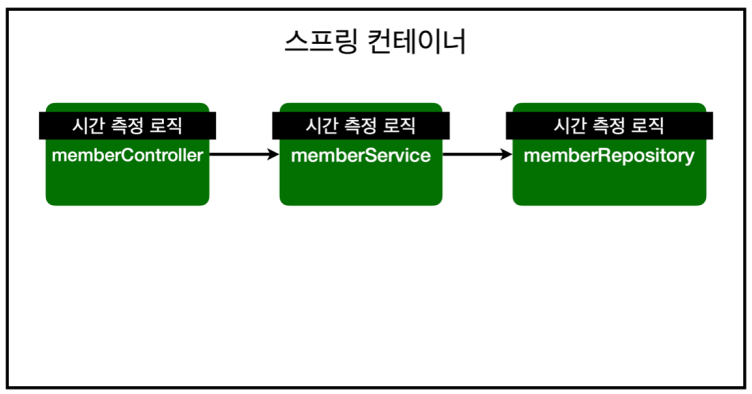
이걸 join() 메소드뿐만 아니라 다른 메소드에도 다~~ 이런 식으로 로직 만들어줘야 함..
공통 메소드로 만들 수 있는 것도 아니라.. 물론 템플릿 메소드 패턴을 쓰거나 하는 식으로 공통 메소드로 만들 수 있기는 함. 또 그것도 복잡함..
이러다 뭐 코드 노가다하는 걸로 야근하고~...
메소드를 '처음' 호출할 때는 이것저것 초기 세팅 하느라 시간 더 걸림. 그래서 실제 운영에서는 처음에 서버 올리고 성능을 위해 이것저것 미리 호출해보는 'warm-up' 작업을 해둠
이렇게 직관적으로 메소드 하나하나의 호출 시간을 쟀을 때의 문제점
- 회원가입, 회원 조회에 시간을 측정하는 기능은 '핵심 관심 사항'이 아니다.
- 시간을 측정하는 로직은 '공통 관심 사항'이다.
- 시간을 측정하는 로직과 핵심 비즈니스의 로직이 섞여서 유지보수가 어렵다.
- 시간을 측정하는 로직을 별도의 공통 로직으로 만들기 매우 어렵다.
- 시간을 측정하는 로직을 변경할 때 모든 로직을 찾아가면서 변경해야 한다.
공통 관심 사항(cross-cutting concern) vs 핵심 관심 사항(core concern)
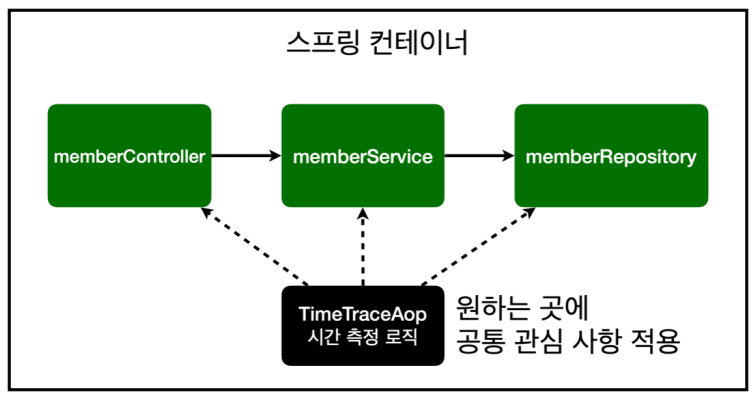
이렇게 한땀한땀 고치고 있는데...... 스프링 고수가 나타나서 그거 AOP로 짠 처리해버리면 된다!!고 알려준 상황 ↓↓↓
ⓑ AOP 적용
AOP: Aspect Oriented Programming (관점 지향 프로그래밍)
=> 공통 관심 사항(cross-cutting concern) vs 핵심 관심 사항(core concern) 분리
AOP 패키지 만들기
그 아래에 TimeTraceAop라는 클래스 만들기
AOP는 @Aspect 애노테이션을 꼭 달아줘야 함
TimeTraceAop을 스프링 빈으로 등록도 해줘야 함 => @Component 또는 스프링 빈 파일(SpringConfig)에 직접 등록해주기
후자가 더 선호됨. 왜냐하면 service, repository는 정형화된 것인 반면, AOP는 정형화되지 않은 특별한 거고 aop가 있구나 명확하게 인지할 수 있도록 하는 게 좋기 때문.
여기서는 그냥 @Component(컴포넌트 스캔) 쓰겠음
@Around() => 공통 관심 사항을 '어디에' 적용할 것인지 '타겟팅' 해줄 수 있음
문법이 있는데, 매뉴얼 보고 하면 어렵지 않고, 웬만하면 쓰던 거 계속 써서 실무에서 쓰는 건 5%도 안 됨
@Around("execution( com.example.hellospring..(..))")
=> com.example.hellospring 패키지 하위에 다 적용해라
이외에도 세부조건 적용해서 Around()를 작성할 수 있음
시간 측정 AOP 등록
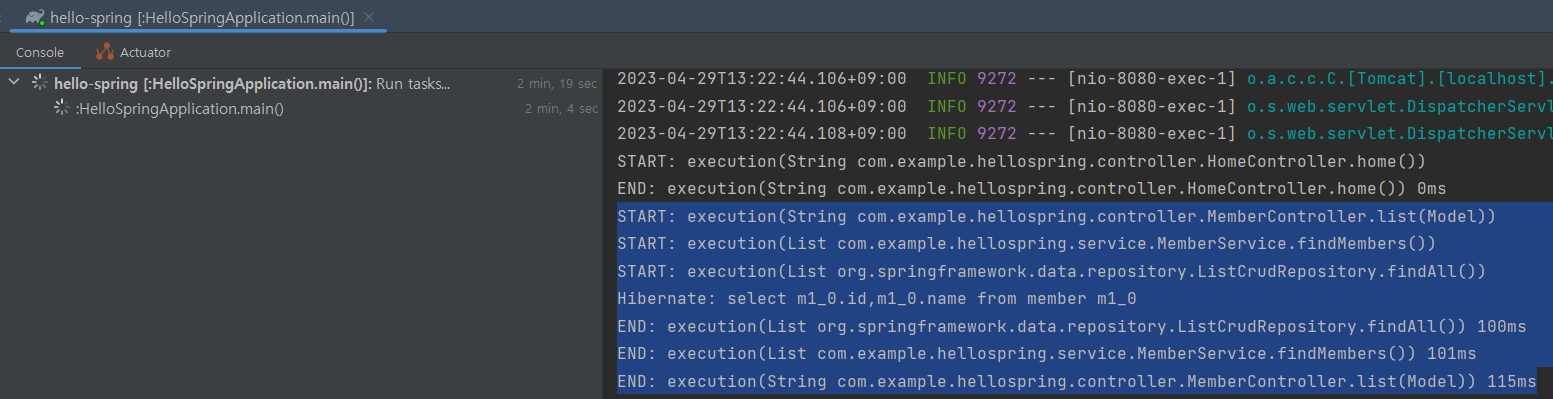
어디서 병목이 생기는지 확인 가능
쉽게 말해서, AOP => 메소드 호출이 될 때마다 인터셉트가 탁탁 걸리도록 하는 것임
<결론>
- 회원가입, 회원 조회 등 '핵심 관심사항'과 시간을 측정하는 '공통 관심사항'을 분리한다
- 시간을 측정하는 로직을 별도의 공통 로직으로 만들었다
- 핵심 관심 사항을 깔끔하게 유지할 수 있다
- 변경이 필요하면 이 로직만 변경하면 된다
- 원하는 적용 대상을 선택할 수 있다 (Around() -- 그때그때 검색해서 적용 가능 ; 보통 패키지 레벨로 많이 함)
패키지 하위 모두 말고 service 하위에만 적용하고 싶다면
@Around("execution(* com.example.hellospring.service..*(..))")<스프링의 AOP 동작 방식 설명>
AOP의 동작 방식은 여러 가지가 있는데, 그 중에서도 '스프링'은 어떻게 동작하는지 알아보자
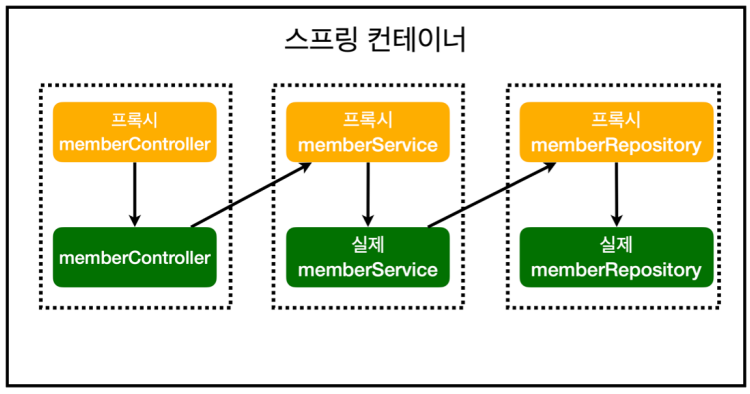
AOP 적용 '전' 의존관계
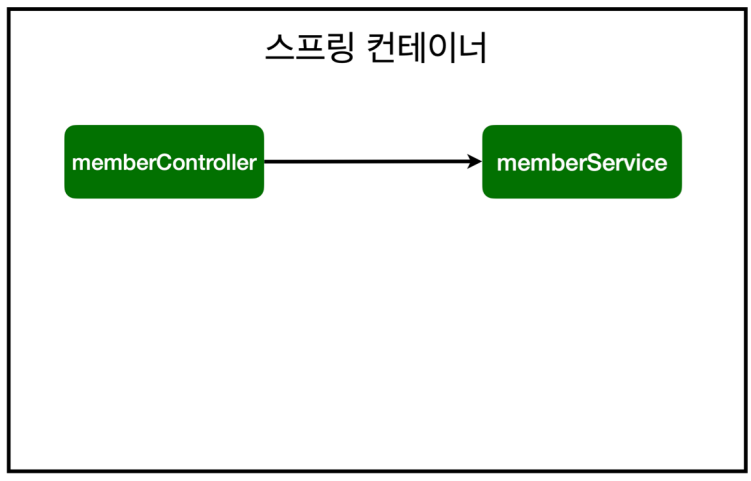
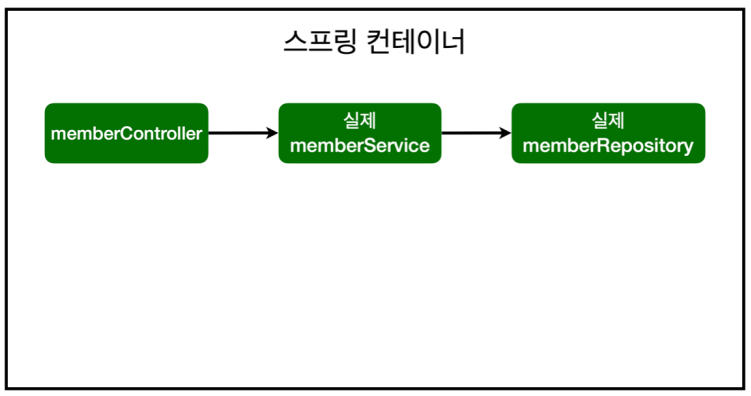
helloController가 자기가 의존하고 있는 실제 memberService를 바로 호출함
AOP 적용 '후' 의존관계 + @Around("execution()")으로 어디에 적용할 건지까지 지정해줄 경우
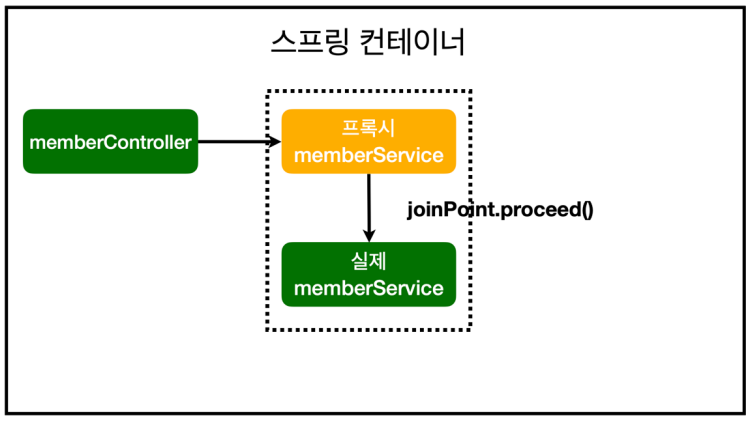
스프링 : AOP가 memberService 적용되어야 한다는 걸 알게 되면 가짜 memberService, 즉 '프록시 memberService'를 만들어냄 -> helloController가 호출하는 건 실제 memberService가 아닌 프록시(가짜) memberService이다 -> 실제 memberService가 호출되는 시점은, 프록시 memberService에서 joinPoint.proceed()가 호출되었을 때.
AOP & 프록시에 대해서는 '핵심편'에서 더 자세히 다룰 예정
실제 Proxy가 주입되는지 콘솔에 출력해서 확인해보고 싶다면
MemberController에서
System.out.println("memberService = " + memberService.getClass());
SpringCGLIB => MemberService를 가지고 복제를 해서 코드를 조작하는 기술
AOP가 가능할 수 있었던 기반 기술
=> 스프링 컨테이너와 같은 컨테이너에서 스프링 빈을 관리 & 'DI'(Dependency Injection)
특히 DI가 없었더라면, 내가 직접 new로 helloController에서 memberService 등을 만들어줘야 하고, 이런 식으로는 AOP 불가능.
DI를 해주니까, HelloController 입장에서는 뭔지 모르겠지만 받아서 쓰고, 거기에 실제 대신 프록시를 집어넣는 AOP가 가능하게 된 것.
스프링은 이를 '프록시 방식의 AOP'라고 하고,
이 방식의 AOP 말고도
JAVA에서 컴파일 타임에 generate한 코드를 아예 정말 위 아래에다 박아 넣어주는 방식의 AOP도 있음
8. 다음으로
'이걸 왜 쓸까, 왜 쓰게 된 걸까, 왜 써야할까'를 이해하는 게 가장 중요
'스프링 완전 정복 시리즈' 로드맵 & '스프링 부트와 JPA 실무 완전 정복' 로드맵의 커리큘럼 참고
