"The text below is a very recent leaked document"
Google의 유출된 AI 전략입니다.
발췌 : semianalysis
We have no Moat, And Neither does OpenAI
우리는 Moat이 없습니다. 그리고 이는 OpenAI도 마찬가지입니다.
여기서 Moat이란 경제적 해자(Economic Moat)에 많이 사용되는 표현입니다.
이는 "회사를 경쟁자들로부터 보호하는 독점적인 경쟁력"이라는 의미를 가지고 있습니다.
해당 표현에서 "Google과 OpenAI는 이와 같은 독점적인 경쟁력이 없다"라고 표현합니다.
Google과 OpenAI의 경쟁에서 진정한 승자는 제 3의 그룹이며 그 이유는 open source 때문이라고 합니다.
심지어 그들은 구글에서 고려한 "major open problems"또한 이들은 간단하게 풀어버립니다.
이에 대한 몇가지 예시는 다음과 같습니다.
- LLMs on a Phone: People are running foundation models on a Pixel 6 at 5 tokens / sec.
- Scalable Personal AI: You can finetune a personalized AI on your laptop in an evening.
- Responsible Release: This one isn’t “solved” so much as “obviated”. There are entire websites full of art models with no restrictions whatsoever, and text is not far behind.
- Multimodality: The current multimodal ScienceQA SOTA was trained in an hour.
이에 품질 측면에서는 아직 우리의 모델이 더 좋지만 이또한 빠르게 좁혀지고 있다고 말합니다.
OpenAI와 Google에서 비싼 가격($10M)과 오랜 시간(540B)을 투자해서 만든 모델을 제 삼의 조직들이 싼 가격($100)과 적은 파라미터(13B)로 활용하며 한달도 아닌 주 단위로 발전하는 제 3의 그룹을 보며 구글은 다음과 같은 시사점을 얻었다고 합니다.
- We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google. We should prioritize enabling 3P integrations.
- People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality. We should consider where our value add really is.
- Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
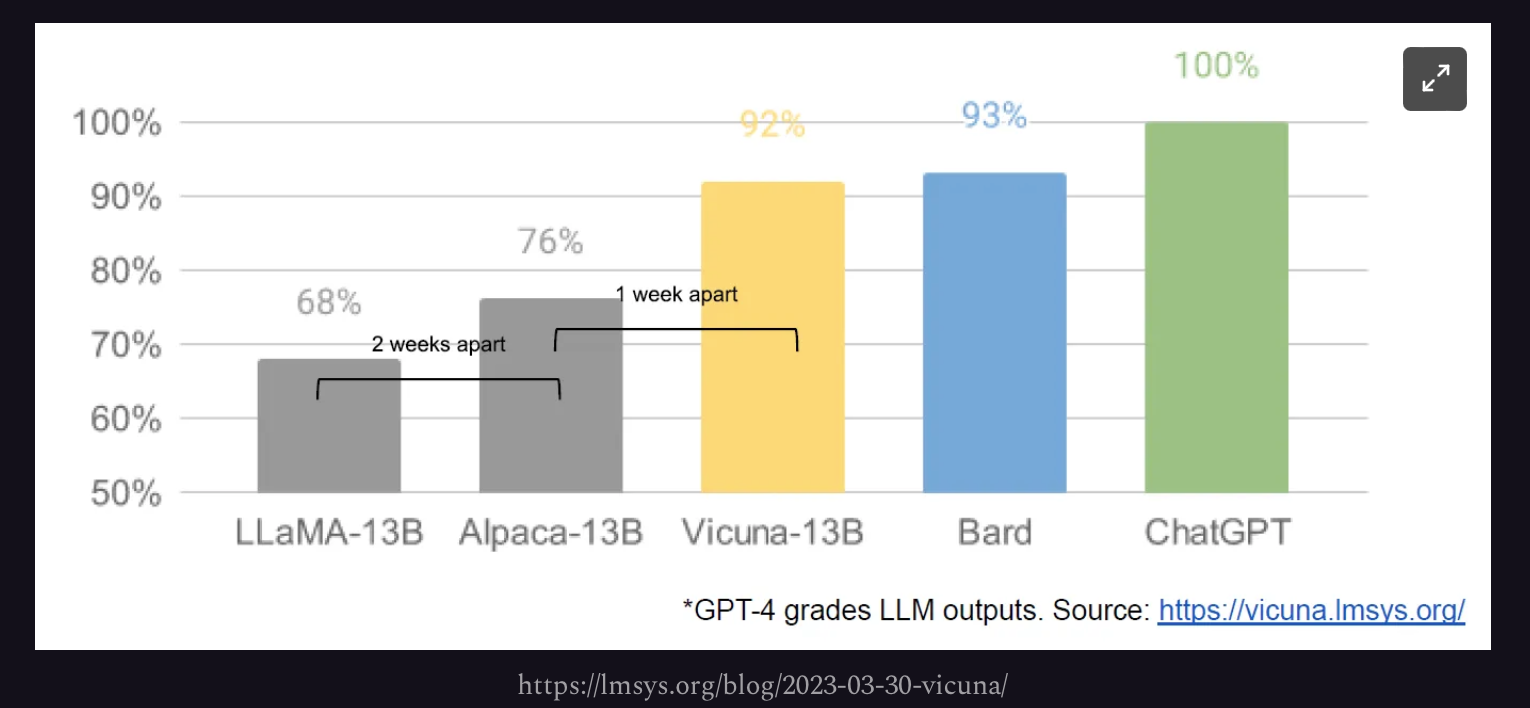
정리하자면 LoRA 논문 이후 LLM에 fine-tuning은 적은 시간 및 용량 대비 높은 성능을 보여주고 있습니다. 그렇기에 기반이 되는 backbone 모델이 존재하면 다양한 task 혹은 목적에 맞게 개인 혹은 그룹이 fine-tuning을 할 수 있습니다.
하지만 문제점은 기반이 되는 backbone 모델 학습에는 많은 리소스와 시간 그리고 돈이 필요합니다.
이를 지불한 뒤 모델을 공개하면 새로운 그룹들은 빠르고 저렴하게 모델을 개량합니다.
그렇기에 자신들의 파이가 줄어들며 앞서 언급한 시사점인 "People will not pay for a restricted model"와 같이 새로운 모델을 학습하는 의미가 사라질 수도 있다는 점을 말하는 것 같습니다.
이러한 기조로 인해 OpenAI에서 ChatGPT와 같은 자사 product의 코드를 공개하지 않는 것 같습니다.
What Happend
3월 초, 메타의 LLaMA가 대중에게 유출되면서 오픈 소스 커뮤니티는 처음으로 제대로 된 기능을 갖춘 파운데이션 모델을 손에 넣었습니다. 이 모델에는 instruction이나 conversation tuning이 없었고 RLHF도 없었습니다.
그 후 엄청난 혁신이 쏟아져 나왔고, 주요 개발이 단 며칠 사이에 이루어졌습니다. 한 달이 지난 지금, Instruction tuning, quantization, uality improvements, human evals, multimodality, RLHF 등 다양한 변형이 등장했으며, 이 중 상당수는 서로를 기반으로 발전했습니다.
가장 중요한 것은 누구나 손댈 수 있을 정도로 스케일링 문제를 해결했다는 점입니다. 새로운 아이디어의 대부분은 커뮤니티에서 나온 아이디어입니다. 이를 통해 진입 장벽이 대형 연구 기관의 결과물에서 한 사람, 짧은 시간, 구식 노트북으로 낮아졌습니다.
LLaMa가 유출된뒤 Alpaca, Vicuna 등 LLaMa를 fine-tuning한 모델들이 등장했으며 이에 LoRA를 붙여 개인이 fine-tuning할 수 있는 Scalable Personal AI까지 등장한 사건을 말하는 것 같습니다.
Why We Could Have Seen It Coming
여러 면에서 이것은 놀라운 일이 아닙니다. 현재 오픈 소스 LLM의 르네상스는 이미지 생성의 르네상스를 이어가고 있습니다. 커뮤니티에서도 비슷한 점을 발견할 수 있으며, 많은 사람들이 이 시기를 LLM의 'Stable Diffusion Moment'이라고 부릅니다.
두 경우 모두 저비용 대중의 참여는 LoRA라는 훨씬 저렴한 fine-tuning 메커니즘과 규모 면에서 획기적인 발전 (이미지 합성의 경우 latent diffusion, LLM의 경우 Chinchilla)이 결합되어 가능했습니다. 두 경우 모두, 충분히 높은 품질의 모델에 대한 액세스는 전 세계의 개인과 기관으로부터 수많은 아이디어와 반복을 촉발시켰습니다. 두 경우 모두 대형 업체를 빠르게 앞질렀습니다.
이러한 기여는 이미지 생성 space에서 중추적인 역할을 했으며, Stable Diffusion은 Dall-E와는 다른 길을 걷게 되었습니다. 개방형 모델을 채택함으로써 제품 통합, 마켓플레이스, 사용자 인터페이스, 그리고 Dall-E에는 없던 혁신이 이루어졌습니다.
그 결과 문화적 영향력 측면에서 빠르게 우위를 점한 OpenAI 솔루션은 점점 더 무의미해졌습니다. LLM에서도 같은 일이 일어날지는 아직 미지수이지만, 큰 구조적 요소는 동일합니다.
OpenAI에서 처음 Dall-E와 Dall-E 2를 공개했을 때만 해도 이미지 생성이 대중적으로 사용할 수 있는 기능은 아니였습니다. 하지만 Stable Diffusion 모델 공개 후 이미지 생성을 다양한 application을 통해 사용할 수 있었고 이를 통해 이미지 생성 시장을 stable diffusion 모델일 잡았다는 이야기인 것 같습니다. 여기서 Dall-E와 Stable Diffusion 모델의 가장 큰 차이점은 Open source라는 점이며 이는 LLaMA와 ChatGPT의 차이와 같습니다.
그렇기에 LLM에서도 다음과 같은 변화가 일어날 수 있는 큰 구조적 요소는 동일하다고 언급한 것 같습니다.
What We Missed
오픈소스의 최근 성공을 이끈 혁신은 우리가 여전히 고민하고 있는 문제를 직접적으로 해결해 줍니다. 이들의 작업에 더 많은 관심을 기울이면 같은 일을 반복하지 않을 수 있습니다.
LoRA는 우리가 더 주목해야 할 놀랍도록 강력한 기술입니다.
LoRA는 모델 업데이트를 low-rank factorizations로 표현하여 update matrices의 크기를 최대 수천 배까지 줄이는 방식으로 작동합니다. 이를 통해 적은 비용과 시간으로 모델을 fine-tuning 할 수 있습니다. 소비자 하드웨어에서 몇 시간 만에 언어 모델을 개인화할 수 있다는 것은 특히 새롭고 다양한 지식을 거의 실시간으로 통합해야 하는 경우 큰 의미가 있습니다.
이 기술이 Google의 가장 야심찬 프로젝트에 직접적인 영향을 미치고 있음에도 불구하고 이 기술이 존재한다는 사실은 Google 내부에서 제대로 활용되지 않고 있습니다.
Retraining models from scratch is the hard path
LoRA가 효과적인 이유 중 하나는 다른 형태의 fine-tuning과 마찬가지로 누적 학습이 가능하다는 점입니다.
instruction tuning과 같은 개선 사항을 적용한 다음 다른 기여자가 대화, 추론 또는 도구 사용을 추가할 때 이를 활용할 수 있습니다.
개별적인 fine-tuning은 low rank이지만, 그 총합은 시간이 지남에 따라 모델에 대한 full-rank 업데이트가 누적될 수 있습니다.
즉, 새롭고 더 나은 데이터 세트와 작업을 사용할 수 있게 되면 전체 실행 비용을 지불하지 않고도 모델을 저렴하게 최신 상태로 유지할 수 있습니다.
반면, 거대한 모델을 처음부터 학습시키면 사전 학습뿐만 아니라 그 위에 이루어진 반복적인 개선 사항도 모두 버려지게 됩니다.
오픈 소스 세계에서는 이러한 개선 사항이 지배적이기까지 오래 걸리지 않으므로 전체 재학습에 엄청난 비용이 소요됩니다.
각각의 새로운 애플리케이션이나 아이디어에 정말 완전히 새로운 모델이 필요한지 신중하게 생각해야 합니다. 모델 가중치를 직접 재사용할 수 없을 정도로 아키텍처가 크게 개선되었다면 이전 세대의 기능을 최대한 유지할 수 있는 보다 공격적인 형태의 증류에 투자해야 합니다.
정리하자면 LoRA를 통해 fine-tuning하는 오픈소스 커뮤니티의 경우 학습된 adapter에 fine-tuning을 하고 또 새로운 기법이 나오면 해당 adapter에 fine-tuning을 하며 누적 학습이 가능합니다.
하지만 scratch부터 모델을 만들어야 하는 입장에서는 이처럼 누적학습이 되지 않기에 새로운 기법에 대해 보수적으로 접근할 수 밖에 없다고 얘기합니다.
Large models aren’t more capable in the long run if we can iterate faster on small models
LoRA update는 가장 인기 있는 모델 사이즈의 경우 비용이 매우 저렴합니다(~$100).
즉, 아이디어만 있으면 거의 모든 사람이 업데이트를 제작하여 배포할 수 있습니다.
training 시간은 하루가 채 걸리지 않는 것이 일반적입니다.
이 정도 속도라면 이러한 모든 fine-tuning의 누적 효과가 model size로 인한 단점을 극복하는 데 그리 오랜 시간이 걸리지 않습니다.
실제로 엔지니어 시간 측면에서 볼 때, 이러한 모델의 개선 속도는 가장 큰 모델로 할 수 있는 것보다 훨씬 빠르며, 최고의 모델은 이미 ChatGPT와 거의 구별할 수 없을 정도입니다.
지구상에서 가장 큰 모델을 유지 관리하는 데 집중하면 오히려 불리한 상황에 처하게 됩니다.
Data quality scales better than data size
이러한 프로젝트 중 상당수는 고도로 선별된 소규모 데이터 세트를 학습하여 시간을 절약하고 있습니다.
이는 데이터 확장 법칙에 어느 정도 유연성이 있음을 시사합니다.
이러한 데이터 세트의 존재는 '데이터는 생각대로 작동하지 않는다'의 사고 방식에서 비롯된 것으로, Google 외부에서 학습을 수행하는 표준 방식으로 빠르게 자리 잡고 있습니다.
이러한 데이터 세트는 합성 방법(예: 기존 모델에서 최상의 응답을 필터링)과 다른 프로젝트에서 스크래빙을 통해 구축되며, 이 두 가지 방법 중 어느 것도 Google에서 널리 사용되는 방법은 아닙니다.
다행히도 이러한 고품질 데이터 세트는 오픈 소스이므로 무료로 사용할 수 있습니다.
Directly Competing With Open Source Is a Losing Proposition
이러한 최근 진전은 Google의 비즈니스 전략에 직접적이고 즉각적인 영향을 미칩니다. 사용 제한이 없는 고품질의 무료 대안이 있는데 누가 사용 제한이 있는 Google 제품에 비용을 지불할까요?
그리고 우리가 따라잡을 수 있을 거라고 기대해서는 안 됩니다. 현대 인터넷이 오픈소스로 운영되는 데에는 이유가 있습니다. 오픈소스에는 우리가 복제할 수 없는 몇 가지 중요한 이점이 있습니다.
We need them more than they need us
기술을 비밀로 유지하는 것은 항상 어려운 일이었습니다. Google 연구원들은 정기적으로 다른 회사로 이직하기 때문에 우리가 알고 있는 모든 것을 알고 있다고 가정할 수 있으며, 파이프라인이 열려 있는 한 계속 그럴 것입니다.
하지만 LLM의 최첨단 연구 비용이 저렴해지면서 기술 경쟁 우위를 유지하는 것은 더욱 어려워졌습니다.
전 세계의 연구 기관들이 서로의 연구를 기반으로 솔루션 분야를 폭넓게 탐색하고 있으며, 이는 우리의 역량을 훨씬 뛰어넘는 수준입니다.
우리는 외부의 혁신이 그 가치를 희석시키는 동안 우리의 비밀을 굳건히 지키려고 노력할 수도 있고, 서로에게서 배우려고 노력할 수도 있습니다.
Individuals are not constrained by licenses to the same degree as corporations
이러한 혁신의 대부분은 메타에서 유출된 모델 가중치를 기반으로 이루어지고 있습니다.
진정한 개방형 모델이 개선됨에 따라 이러한 상황은 필연적으로 변화하겠지만, 중요한 점은 기다릴 필요가 없다는 것입니다.
'개인적 사용'이 제공하는 법적 보호와 개인 기소의 비현실성은 개인이 이러한 기술이 hot할 때 접근하고 있다는 것을 의미합니다.
Being your own customer means you understand the use case
이미지 생성 공간에서 사람들이 만드는 모델을 살펴보면 애니메이션 제너레이터부터 HDR 랜드스케이프에 이르기까지 방대한 창의성이 쏟아져 나오고 있습니다.
이러한 모델은 특정 하위 장르에 깊이 몰입한 사람들이 사용하고 만들었기 때문에 우리가 따라올 수 없는 깊이 있는 지식과 공감을 제공합니다.
Owning the Ecosystem: Letting Open Source Work for Us
역설적이게도 이 모든 것의 확실한 승자는 바로 메타입니다.
유출된 모델이 자신들의 것이었기 때문에, 그들은 사실상 지구 전체에 해당하는 무료 노동력을 확보한 셈입니다.
대부분의 오픈소스 혁신이 메타의 아키텍처를 기반으로 이루어지고 있기 때문에, 메타가 이를 자사 제품에 직접 통합하는 것을 막을 수 있는 방법은 없습니다.
생태계를 소유하는 것의 가치는 아무리 강조해도 지나치지 않습니다.
Google은 Chrome 및 Android와 같은 오픈 소스 제품에서 이 패러다임을 성공적으로 활용하고 있습니다. 혁신이 일어나는 플랫폼을 소유함으로써 Google은 사고의 리더이자 방향 설정자로서의 입지를 굳히고, 자신보다 더 큰 아이디어에 대한 내러티브를 형성할 수 있는 능력을 얻게 됩니다.
모델을 더 엄격하게 통제할수록 개방형 대안을 더 매력적으로 만들 수 있습니다.
Google과 OpenAI는 모두 모델 사용 방식을 엄격하게 통제할 수 있는 릴리스 패턴에 방어적으로 끌려왔습니다.
하지만 이러한 통제는 허구입니다.
승인되지 않은 목적으로 LLM을 사용하고자 하는 사람은 누구나 자유롭게 사용할 수 있는 모델 중 원하는 것을 선택하면 됩니다.
구글은 오픈소스 커뮤니티의 리더로서 폭넓은 대화를 무시하지 않고 협력하여 주도권을 잡아야 합니다.
이는 아마도 작은 ULM 변형에 대한 모델 가중치를 게시하는 것과 같은 불편한 조치를 취하는 것을 의미할 것입니다.
이는 모델에 대한 일부 통제권을 포기하는 것을 의미합니다.
하지만 이러한 타협은 불가피합니다.
혁신을 주도하면서 동시에 혁신을 통제할 수는 없기 때문입니다.
Epilogue: What about OpenAI?
오픈소스에 대한 이 모든 이야기는 OpenAI의 현재 폐쇄적인 정책을 고려할 때 불공평하게 느껴질 수 있습니다. 저들은 공유하지 않을 텐데 우리는 왜 공유해야 하나요? 하지만 사실 우리는 이미 고급 연구원이 꾸준히 유출되는 형태로 모든 것을 그들과 공유하고 있습니다. 이러한 흐름을 막기 전까지는 비밀 유지에 대한 논의는 무의미합니다.
결국 OpenAI는 중요하지 않습니다. 오픈소스와 관련하여 그들도 우리와 같은 실수를 저지르고 있으며, 우위를 유지할 수 있는 능력에 의문이 제기될 수밖에 없습니다. 오픈소스 대안이 그들의 입장을 바꾸지 않는 한 결국에는 오픈소스가 그들을 잠식할 수 있고 잠식할 것입니다. 이 점에서 적어도 우리가 먼저 움직일 수 있습니다.
정리
원본 포스트에는 Eplilogue 뒤에 Timeline이 있습니다.
해당 Timeline을 통해 LLaMA 유출 이 후 어떠한 변화와 혁신들이 이루어졌는지 알 수 있습니다.
폐쇄적인 OpenAI의 Dall-E는 Stable Diffusion이라는 open source로 인해 시장의 파이를 뺏겼습니다.
ChatGPT 또한 같은 구조의 상황을 맞이하게 되었습니다.
이를 보며 Google은 결국 오픈 소스와의 타협을 통해 혁신을 주도하고자 하는 것 같습니다.
DeepL을 통해 번역했으며 일부 어색한 문장들을 수정하였습니다.
