Product Serving
CLOUD
Cloud 서비스를 사용하는 이유
- 자신의 컴퓨터로 만들 경우 해당 컴퓨터가 항상 켜져있어야 한다.
- IDC(Internet Data Center)의 확장성이 좋다
- 다양한 작업들을 쉽게 사용할 수 있도록 지원해줌
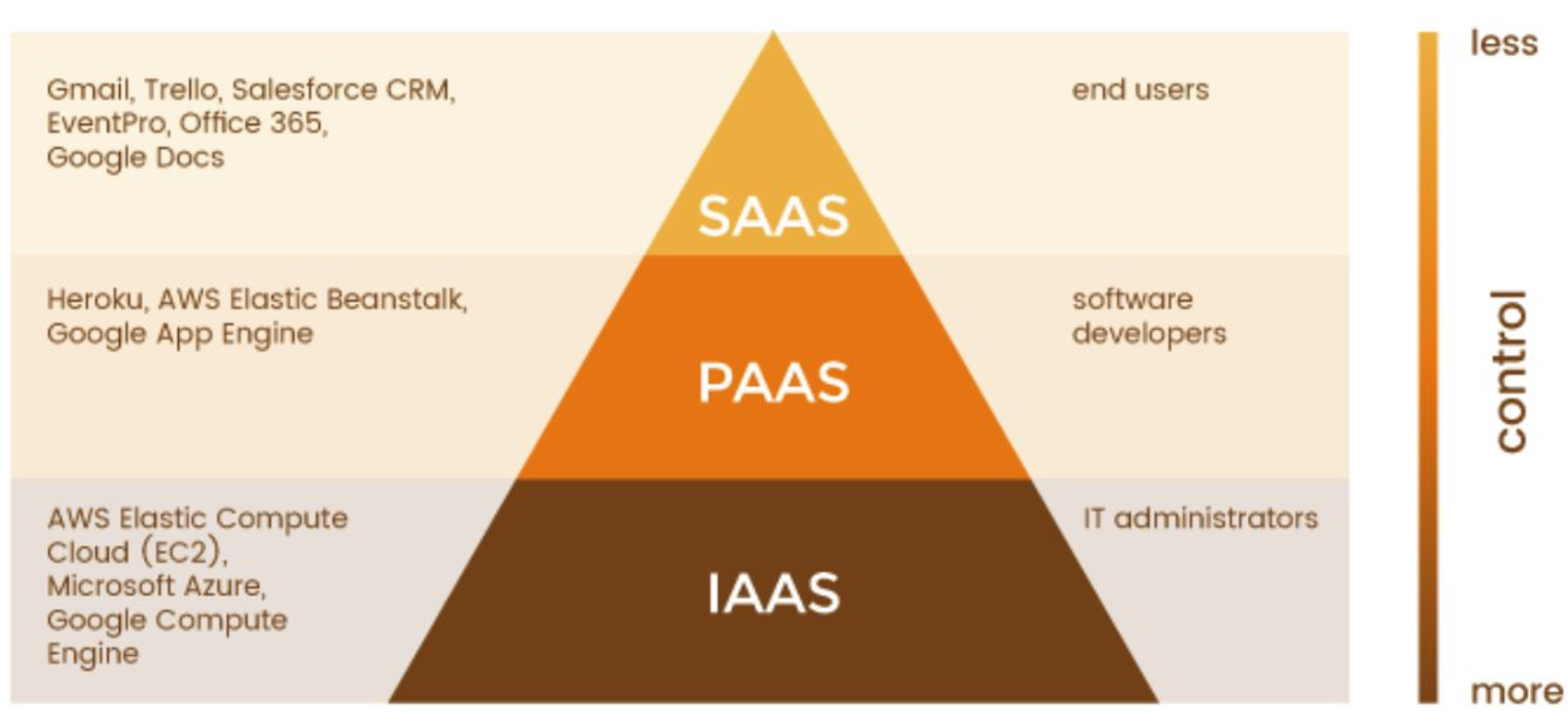
프로토타입부터 점진적으로 개선하기
CI/CD
Local : 각자의 컴퓨터에서 개발, 각자의 환경을 통일시키기 위해 Docker 등을 사용
Dev : Local에서 개발한 기능을 테스트 할 수 있는 환경, Test 서버
Staging : Production 환경에 배포하기 전에 운영하거나 보안, 성능을 측정하는 환경, Staging 서버
Production : 실제 서비스를 운영하는 환경, 운영 서버
개발 환경을 나누는 이유
실제 운영중인 서비에 장애가 발생하면 안되기에
Dev = Staging = Production인 경우
소스 코드를 저장하면 바로 반영, 오타 혹은 오류가 발생할 경우 장애 발생
Git Flow 방식
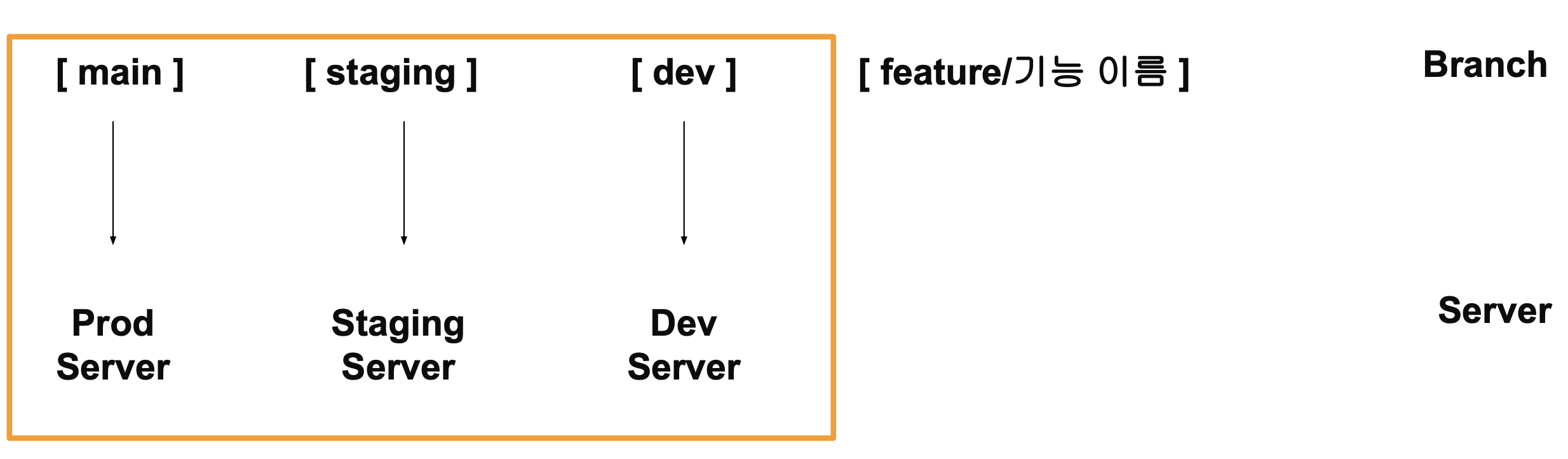
다음과 같이 feature -> dev -> staging -> main에 P&R을 통해 업데이트 할 때 서버에 코드를 보내는 것과 반복적으로 진행할 Test를 실행하는 방법은?
CI
CI : Continuous Integration, 지속적 통합
- 새롭게 작성한 코드 변경 사항이 Build, Test 진행한 후 Test Case에 통과했는지 확인
- 지속적으로 코드 품질 관리
CD
CD : Continuous Deploy/Delivery, 지속적 배포
- 작성한 코드가 항상 신뢰 가능한 상태가 되면 자동으로 배포될 수 있도록 하는 과정
- CI 이후 CD를 진행
- dev / staging / main 브랜치에 Merge가 될 경우 코드가 자동으로 서버에 배포
즉,
- CI : 빌드, 테스트 자동화
- CD : 배포 자동화
Github Action
Github에서 출시한 기능으로, 소프트웨어 Workflow 자동화를 도와주는 도구
WorkFlow 예시
1) Test Code : 특정 타입의 return 값이 어떻게 나오는지 확인하는 test code
2) 배포 : Prod, Staging, Dev 서버로 코드 배포, FTP로 파일을 전송할 수 있으며 Docker Image 푸쉬 등
3) 파이썬, 쉘 스크립트 실행 : Github Repo에 저장된 스크립트를 일정 주기를 가지고 실행, crontab의 대용, 데이터 수집을 주기적으로 해야할 때 사용 가능
4) Github Tag, Release 자동으로 설정 : Main 브랜치에서 Merge될 경우 특정 작업 실행, 기존 버전에서 버전 UP, 새로운 브랜치 생성시 특정 작업 수행 가능
Github Action 사용하는 방식
1) 코드 작업
2) 코드 작업 후, Github Action으로 무엇을 할 것인지 생각
3) 사용할 WorkFlow 정의
4) workflow 정의 후 정상 작동하는지 확인
머신러닝 디자인 패턴
디자인 패턴
- 문제를 해결하는 방법을 패턴화하여 표현
- 반복적으로 발생하는 문제들을 어떻게 해결하는지에 대한 솔루션
- 추상화된 패턴
- 안티 패턴 : 좋지 않은 패턴
머신러닝 디자인 패턴
- 일반적인 개발 디자인 패턴과 다르게 머신러닝의 특수성으로 인해 별도의 디자인 패턴이 생김
- 머신러닝 개발의 특수성 : Data, Model, Code
- 소프트웨어 개발 : Code
크게 4가지 패턴으로 나뉘어진다.
- Serving 패턴 : 모델을 Production 환경에서 서빙하는 패턴
- Training 패턴 : 모델을 학습하는 패턴
- QA 패턴 : 모델의 성능을 Production 환경에서 평가하기 위한 패턴
- Operation 패턴 : 모델을 운영하기 위한 패턴
Serving 패턴
머신러닝 모델을 Production 환경에서 어떻게 사용할 것인가?
- Web Single 패턴
- UseCase
- 가장 간단한 아키텍처
- 예측 서버를 빠르게 출시하고 싶은 경우
- Architecture
- FastAPI, Flask 등으로 단일 REST 인터페이스 생성
- 요청시 전처리도 같이 포함
- 간단하게 생성할 수 있는 구조
- 장점
- 하나의 프로그램 언어, 단순함
- 단점
- 구성 요소 하나가 변경되면 전체 업데이트를 해야함
- UseCase
- Synchronous 패턴
- UseCase
- 예측의 결과에 따라 로직이 달라지는 경우
- Architecture
- 예측이 끝날 때까지 프로세스를 block
- REST API는 대부분 Synchronous 패턴
- 장점
- 아키텍처의 단순함, 예측이 완료될 때까지 프로세스가 다른 작업을 할 필요가 없어 WorkFlow가 단순해짐
- 단점
- 예측 속도가 병목이 됨
- 예측 지연으로 사용자 경험이 악화될 수 있음
- UseCase
- Asynchronous 패턴
- UseCase
- 예측과 진행 프로세스의 의존성이 없는 경우
- 비동기로 실행됨, 예측 요청을 하고 응답을 바로 받을 필요가 없는 경우
- 예측을 요청하는 클라이언트와 응답을 반환하는 목적지가 분리된 경우
- Architecture
- 클라이언트와 예측 서버 사이에 메세지 시스템(Queue)을 추가
- 특정 메세지는 Request 데이터를 메세지 Queue에 저장(Push)
- 특정 서버는 메세지 Queue의 데이터를 가져와서 예측(Pull)
- 장점
- 클라이언트와 예측을 분리
- 클라이언가 예측을 기다릴 필요가 없음
- 단점
- 메세지 Queue 시스템을 만들어야 함
- 실시간 시스템에 적합하지 않음
- UseCase
- Batch 패턴
- UseCase
- 예측 결과를 실시간으로 얻을 필요가 없는 경우
- 대량의 데이터에 대한 예측을 하는 경우
- 예측 실행이 시간대별, 월별, 일별로 스케쥴링 해도 괜찮은 경우
- Architecture
- 실시간으로 진행할 필요가 없는 경우 사용
- Airflow 등으로 Batch 작업을 스케쥴링에 맞게 트리거링
- Input, Output 데이터는 데이터 웨어하우스 등에 저장
- 장점
- API 서버 등을 개발하지 않아도 되는 단순함
- 서버 리소스를 유연하게 관리할 수 있음
- 단점
- 스케줄링을 위한 서버 필요
- UseCase
- Prediction 패턴
- UseCase
- 전처리와 예측을 분리하고 싶은 경우
- 전처리와 예측에서 사용하는 언어가 다른 경우
- 리소스를 분리하여 효율성을 향하고 싶은 경우
- Architecture
- 전처리와 예측 서버를 분리
- Request를 할 경우 맨 처음엔 전처리 서버로 가서 전처리하고, 그 데이터를 예측 서버로 Request
- 장점
- 전처리 서버와 예측 서버를 분리하여 효율적으로 리소스를 사용할 수 있다.
- Fault Isolation : 장애를 격리할 수 있다.
- 딥러닝에서는 전처리가 많이 필요해서 이렇게 활용하는 경우도 존재
- 단점
- 서버 2개를 운영해야 해서 운영 비용이 증가
- 전처리 서버와 예측 서버 네트워크 연결이 병목현상이 될 수 있다.
- UseCase
- Microservice Vertical 패턴
- Usecase
- 여러 모델이 순차적으로 연결되는 경우
- A모델의 결과를 B서버의 Input으로 사용하는 경우
- 예측끼리 의존 관계가 있는 경우
- Architecture
- 각각의 모델을 별도의 서버로 배포
- 동기적으로 순서대로 예측하고, 예측 결과를 다른 모델에 또 Request
- 장점
- 여러 예측을 순서대로 실행할 수 있음
- 이전 예측 결과에 따라 다음 예측 모델을 여러개로 분기할 수 있다.
- 단점
- 동기식으로 진행되기에 대기 시간이 더 필요함
- 하나의 포인트에서 병목현상이 생길 수 있음
- 복잡한 시스템 구조
- Usecase
- Microservice Horizontal 패턴
- Usecase
- 하나의 Request에 여러 모델을 병렬로 실행하고 싶은 경우
- 보통 이런 경우 마지막에 예측 겨로가를 통합함
- Architecture
- Microservice Vertical 패턴과 유사하게 모델을 각각의 서버로 배포
- Request가 올 경우 여러 모델 서버로 예측
- 장점
- 리소스 사용량을 독립적으로 사용할 수 있으며, 장애를 격리 할 수 있다.
- 다른 모델에 의존성 없이 개발할 수 있다.
- 단점
- 시스템이 복잡해질 수 있다.
- Usecase
- Prediction Cache 패턴
- UseCase
- Request할 때 데이터를 저장하고, 예측 결과도 별도로 저장해야 하는 경우
- 예측 결과가 자주 변경되지 않는 경우
- 입력 데이터를 캐시로 활용할 수 있는 경우
- 입력 데이터를 캐시로 활용할 수 있는 경우
- Architecture
- Request가 올 경우 해당 데이터로 예측한 결과가 있는지 캐시에서 검색함
- 만약 예측 결과가 있다면 해당 데이터를 바로 Return, 예측 결과가 없다면 모델에 예측
- 오래된 예측이 있다면 주기적으로 삭제하는 로직이 필요함
- 장점
- 반복되는 요청이 있을 경우 성능을 개선할 수 있음
- 단점
- 캐시 서버를 운영해야함
- UseCase
Serving Anti 패턴
- Online Bigsize 패턴
- 실시간 대응이 필요한 온라인 서비스에 예측에 오래 걸리는 모델을 사용한 경우
- 속도와 비용 Tradeoff를 조절하여 모델 경량화하는 작업이 필요
- 실시간이 아닌 배치로 변경하는 것도 가능한지 검토
- 중간에 캐시 서버를 추가하고, 전처리를 분리하는 것도 Bigsize를 탈피하는 방법
- 하나의 서버에 여러 예측 모델을 띄운 경우
- predict1, predict2, predict3으로 나눠서 하나의 서버에서 모두 실행하는 경우
- 라이브러리 선택 제한이 존재함
- 장애가 발생할 경우(서버가 갑자기 다운) 로그를 확인하기 어려움
Training 패턴
학습 파이프라인을 구성하기 위한 패턴
자주 학습하는가?, 학습의 Component 다양한 단계를 재사용하는가?
- Batch Training 패턴
- Usecase
- 주기적으로 학습해야하는 경우
- Architecture
- Batch Serving 패턴처럼 스케줄링 서버가 필요
- 학습 과정에서 데이터 전처리, 평가 과정 모두 필요
- 저장한 모델 파일을 사용할 수 있도록 저장하는 작업 필요
- 장점
- 정기적인 재학습과 모델 업데이트
- 단점
- 데이터 수집, 전처리, 학습, 평가 과정에서 오류가 발생할 상황을 고려해야 함
- Usecase
- Pipeline Training 패턴
- Usecase
- 학습 파이프라인 단계를 분리해 각각을 선택하고 재사용할 수 있도록 만드는 경우
- 각 작업을 별도로 컨트롤하고 싶은 경우
- Architecture
- Batch Training 패턴의 응용 패턴
- 각 작업을 개별 리소스로 분할(서버, 컨테이너 등) => 전처리 서버는 메모리가 크게, 서빙 서버는 GPU 등
- 이전 작업의 실행 결과가 후속 작업의 Input
- 장점
- 작업 리소스, 라이브러리를 유연하게 선택할 수 있음
- 장애 분리
- Workflow 기반 작업
- 컨테이너를 재사용할 수 있음
- Usecase
Training Anti 패턴
-
Training code in Serving 패턴
- 학습, 실험, 평가에 사용해야 하는 코드가 서빙 코드에 들어간 경우
- 학습, 실험, 평가를 위한 환경과 서빙을 같이 처리하는 경우
- Research 단계와 Production 단계에서 필요한 코드와 로직은 다름 => 리소스도 마찬가지로 분리
-
Too many pipes 패턴
- 학습 파이프라인이 너무 다양하고 복잡한 경우
- 데이터 소스가 너무 많아서 각각 가져오는 방법이 다양하고, 추상화되어 있지 않은 경우
QA 패턴
예측 서버와 모델의 성능평가를 위한 패턴
- 모델이 처음 배포된다면 배포 끝!이지만 기존 모델이 있고 신규 모델이 있다면 모델을 비교해야 함
- Production 환경에 영향이 없도록 Test하는 패턴, 바로 영향이 가는 패턴 등이 존재
- 추천 시스템에서 자주 사용하며, AB Test - MAB 등의 키워드도 존재
-
Shadow AB Test 패턴
- Usecase
- 새로운 예측 모델이 Production 환경에서 잘 동작하는지 확인하고 싶은 경우
- 새로운 예측 서버가 Production 환경의 부하를 견디는지 확인하고 싶은 경우
- Architecture
- 예측 모델, 서버를 Production 환경에 배포하기 전에 사용
- Request가 들어온 경우 기존 모델과 새로운 모델에게 모두 전달되고, Response는 기존 모델 서버에만 전달됨(새로운 모델의 결과는 별도로 저장만)
- 모델이 잘 예측하는지 동시에 2개의 모델을 실행해서 파악할 수 있음
- 새로운 모델이 문제가 생기면 AB Test에서 제거하고 다시 개선
- Shadow AB Test 패턴은 Risk가 적음(현재 모델은 그대로 운영)
- 예측 모델, 서버를 Production 환경에 배포하기 전에 사용
- 장점
- Production 환경에 영향을 주지 않고 새로운 모델 성능을 확인할 수 있음
- 여러 모델의 예측 결과를 수집해 분석할 수 있음
- 단점
- 새로운 예측 서버에 대한 비용이 발생
- Usecase
-
Online AB Test 패턴
- Usecase
- 새로운 모델이 Production 환경에서 잘 동작하는지 확인하고 싶은 경우
- 새로운 서버가 Production 환경의 부하를 견딜 수 있는지 확인하고 싶은 경우
- 온라인으로 여러 예측 모델을 측정하고 싶은 경우
- Architecture
- Shadow AB Test 패턴과 큰 방식은 동일
- Request가 들어오면 지정된 비율(예-1:1)로 트래픽을 나눠서 절반은 기존 모델, 절반은 신규 모델에 예측
- 처음부터 1:1로 하진 않고, 새로운 모델을 10% 정도로 조절하곤 함
- 장점
- Production 환경에서 새로운 모델의 예측 결과, 속도를 확인할 수 있음
- 여러 모델의 예측 결과를 수집해 분석할 수 있음
- 단점
- 새로운 모델이 바로 비즈니스에 노출되므로 부정적인 비즈니스 영향이 발생할 수 있음
- 새로운 예측 서버에 대한 비용이 발생
- Usecase
QA Anti 패턴
- Offline Only 패턴
- 머신러닝 모델이 Online Test를 하지 않고, Offline Test Data로만 진행되는 경우
- 머신러닝 모델의 비즈니스 가치를 입증하기 어려움
- Production 환경에도 꼭 사용하는 시기가 필요함
Operation 패턴
머신러닝 시스템의 설정, 로깅, 모니터링 등 운영을 위한 패턴
- Model in Image 패턴
- Usecase
- 서비스 환경과 모델을 통합해서 관리하고 싶은 경우
- Docker Image 안에 모델이 저장되어 있는 경우
- Architecture
- Docker Image로 모델 코드와 모델 파일(pkl 등)을 저장해서 사용
- Production 환경에선 이 이미지를 Pull해서 사용
- 장점
- Production 환경과 Dev 환경을 동일하게 운영할 수 있음
- 단점
- 모델을 수정하는 일이 빈번할 경우, Docker Image Build를 계속 수행해야 함
- Usecase
- Model Load 패턴
- Usecase
- Docker 이미지와 모델 파일을 분리하고 싶은 경우
- 모델 업데이트가 빈번한 경우
- 서버 이미지는 공통으로 사용하되, 모델은 여러개를 사용하는 경우
- Architecture
- 개발 코드는 Docker Image로 Build
- 모델 파일은 Object Storage 등에 업로드하고 프로세스 시작할 때 모델 파일을 다운(프리트레인 모델처럼)
- 분리를 통해 서버 이미지를 경량화할 수 있는 패턴
- 장점
- 모델과 서버 이미지를 구분
- 서버 이미지를 재사용할 수 있으며, 서버 이미지가 경량화됨
- 단점
- 모델 파일을 가지고 와야하기 때문에 서비스 시작하는데 더 오래 걸릴 수 있음
- 서버 이미지, 모델 관리를 해야 함
- Usecase
- Prediction Log 패턴
- Usecase
- 서비스 개선을 위해 예측, 지연 시간(latency) 로그를 사용하려고 할 경우
- Data Validation, 예측 결과 등을 확인하고 싶은 경우
- Architecture
- 프로세스에서 로그를 저장하지 않고, 메세지 시스템으로 넘겨서 프로세스가 저장에 신경쓰는 시간을 줄임
- 장애 등을 파악할 수 있도록 로그도 기록하고 모니터링도 할 수 있도록 대비해야 함
- 장점
- 예측 결과, 모델의 Latency 등을 분석할 수 있음
- 단점
- 로그가 많아지면 저장 비용이 발생함
- Usecase
- Condition Based Serving 패턴
- Usecase
- 상황에 따라(특정 조건) 예측해야 하는 대상이 다양한 경우
- 룰 베이스 방식으로 상황에 따라 모델을 선택하는 경우
- Architecture
- 사용자의 상태, 시간, 장소에 따라 예측 대상이 바뀔 수 있음
- 장점
- 상황에 따라 알맞은 모델 제공
- 단점
- 모델 수에 따라 운영 비용 증가
- Usecase
Operation Anti 패턴
- No Logging 패턴
