GPT-2 문장 생성 시, 왜 중복이 발생할까
NLP 논문 리뷰 - The Curious case of Neural Text Degeneration을 정리하며 작성.
koGPT-2로 학습 시킨 후 문장을 생성할 때, gready search를 통해서 문장을 생성했는데, 문장 생성이 조금 지나면 중복된 문장이 생성이 되었다. 문장 생성 방법에는 gready search, beam search, random sampling 방법이 있는데, GPT-2에서 빔 탐색을 이용할 경우 이후에 문장 중복이 나온다고 한다.
NLP에서 좋은 결과가 나오는 대부분의 언어모델(language model)의 경우 디코딩 부분에서 빔 탐색과 그리디 탐색을 사용하며 log likelihood와 argmax등을 이용해서 탐색을 한다.
GPT-2의 Beam search
아래 그림을 보면 중복된 내용을 확인할 수 있다. 나의 경우도 GPT-2로 문장 생성시 중복된 내용이 계속 반복 되었다.

GPT-2의 Sampling
k=40일 때의 Top K 샘플링 결과이다.

높은 확률을 탐색하는 빔 탐색은 왜 중복이 더 많은가?
아래 그림을 보면 사람이 생성한 텍스트의 확률 값은 편차가 큰 반면, 빔 탐색으로 생성한 경우 높은 확률 수치를 유지하고 있다. 따라서 아래 그림만 보았을 때도 랜덤 탐색의 경우가 좀더 효율적으로 보인다.
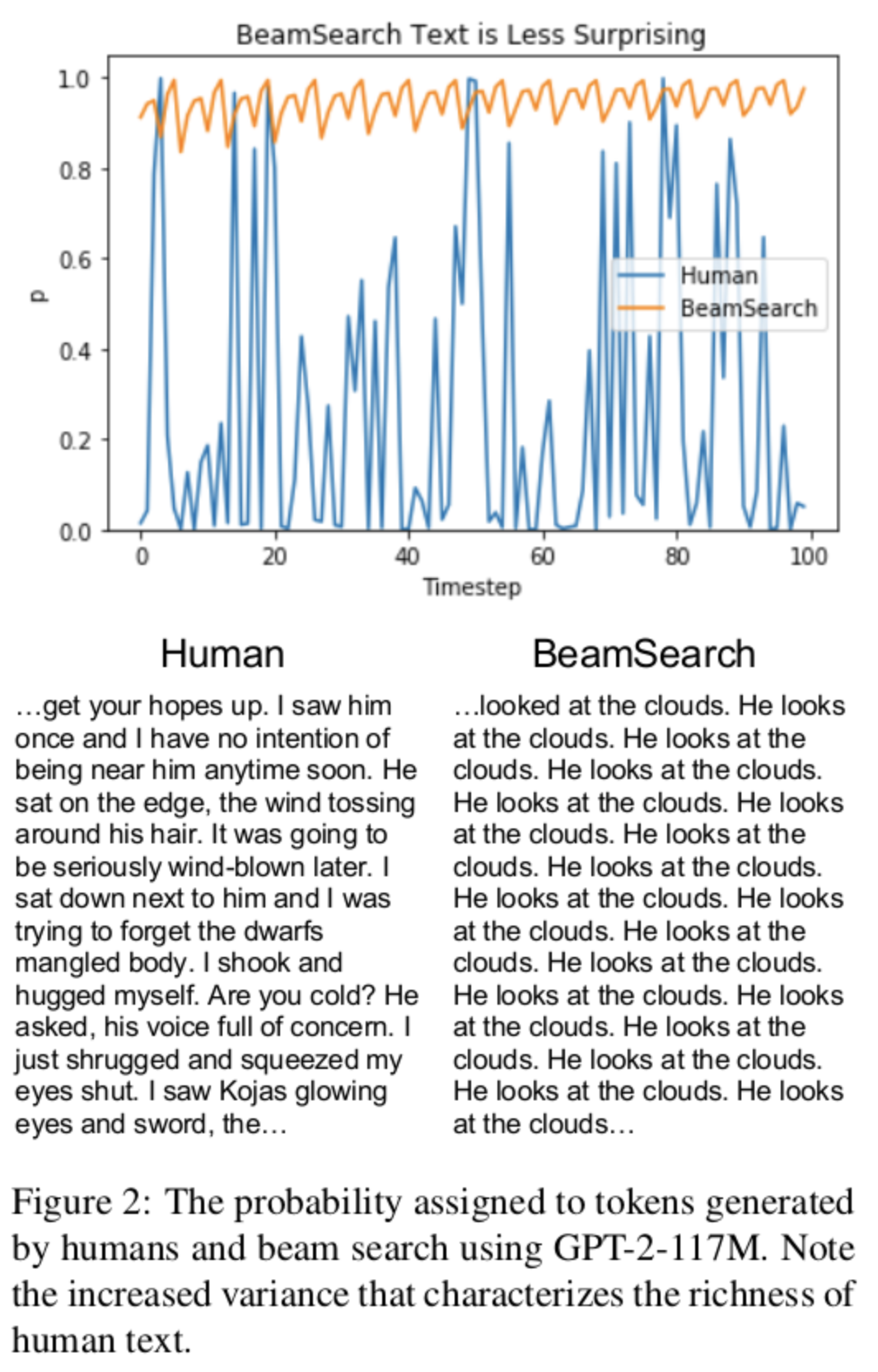
랜덤 탐색에 대한 문제
- 일관성 없는 텍스트
- 일관성 없는 문장이 생성될 경우 다음 예측에도 영향을 미치기 때문에 다음 예측에 안좋을 수 있다.
더 나은 탐색 방법에 대해서
샘플링 방법 중 더 나은 탐색 방법들
1. Nucleus Sampling
2. Top-P Sampling
탐색 결과

