텐서플로로 시작하는 딥러닝
이 책의 목표
- '합성곱 산경망(CNN, Convolution Neural Network)' 구조 이해
- CNN을 이용한 필기 문자(숫자) 분류 처리 원리 파악 및 코드 작성
텐서플로 공식 웹 사이트 튜토리얼 중 'Deep MNIST for Exports' 기반의 내용
Chapter 1. 텐서플로 입문
1장 목표
- 딥러닝과 텐서플로의 개요 소개
- 텐서플로 코드 실행 환경 준비
- 텐서플로의 기본적인 코드 작성법 설명
1.1 딥러닝과 텐서플로
1.1.1 머신러닝의 개념
딥러닝
- 넓은 의미로 머신러닝 중 ‘신경망(neural network)’이라는 모델의 일종
머신러닝
- 데이터 속의 ‘수학적인 구조' 를 컴퓨터로 계산해 발견해 내는 구조
데이터의 모델화
- 주어진 데이터의 수치를 있는 그대로 받아들이는 것이 아니라 그 속의 ‘원리'를 생각하는 것
- 생각해 낸 구조가 데이터의 ‘모델‘
- 일반적으로 식으로 표현 가능
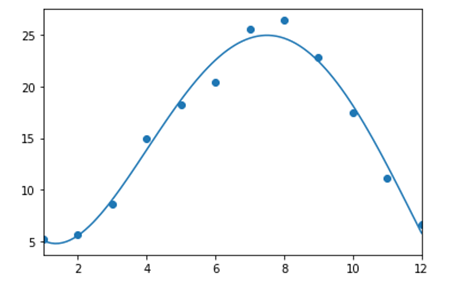
ex) 특정 도시의 올해 1년간 월별 평균 기온으로 내년 월별 평균 기온 예측
- 그림 1-3의 노이즈를 없애 그림 1-4를 만든다.
- 그림 1-4 그래프를 아래와 같은 식으로 표현한다.
- 실제 데이터와 월별 예측 값 사이 오차 함수가 최소화 될 수 있도록 파라미터를 조정
파라미터의 값이 구체적으로 결정되면 얻어진 식으로 내년 이후 평균 기온 예측 가능
미지의 데이터에 대한 예측 정밀도를 향상하기 위해 최적의 모델(예측용 식)을 발견하는 것이 머신러닝을 활용하는 데이터 과학자의 능력 발휘 부분
=========================================
🎈머신 러닝 모델의 3단계🎈
-
주어진 데이터를 기반으로 미지의 데이터를 예측하는 식 생각
-
식에 포함된 파라미터의 좋고 나쁨을 판단하는 오차 함수 준비
-
오차함수를 최소화할 수 있도록 파라미터 값 결정
- 머신러닝에서 컴퓨터의 역할이 이루어지는 부분
- 빅데이터에 대해 오차함수를 최소화하기 위해 정해진 알고리즘을 사용해 자동으로 계산 (이 책에서 설명하는 텐서플로의 주요 업무)
- 머신러닝에서 컴퓨터의 역할이 이루어지는 부분
==========================================
1.1.2 신경망의 필요성
ex) 특정 바이러스에 감염되었는지 판정하기
검사결과는 (, )로 주어짐 -> 두가지 수치를 기반으로 바이러스 감염 확률 를 구해야 함
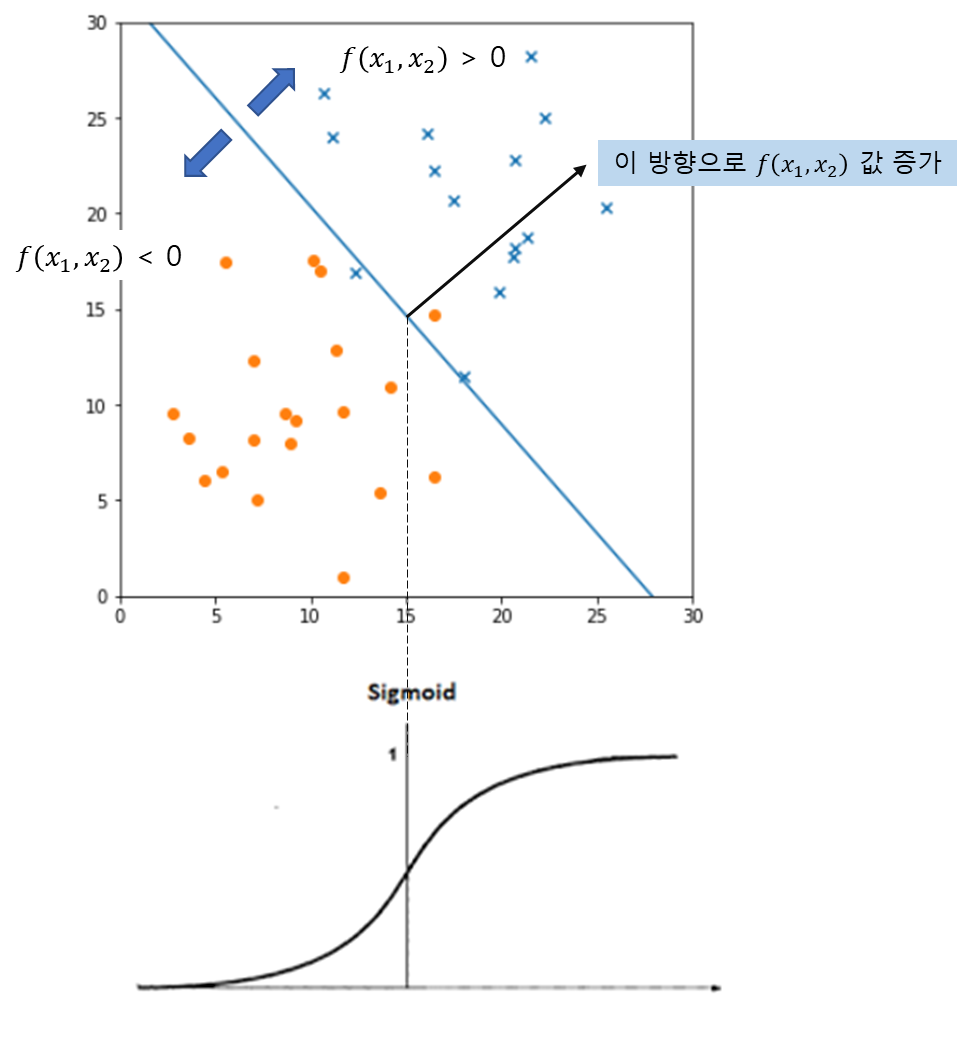
직선을 기준으로 오른쪽 위 영역은 감염되었을 확률이 높다.
직선 -
이 형식의 장점
1. 이 경계가 됨
2. 경계에서 멀어질수록 값이 무한대를 향해 증가, 감소하는 성질을 나타냄
==> 머신러닝 모델의 3단계 중 1단계
여기서 위의 모델은 주어진 데이터를 직선으로 분류했지만 보다 복잡한 데이터 배치는 곡선 또는 더욱 복잡한 수식으로 분류해야 한다.
현재 머신러닝은 데이터의 모델(1단계의 식)은 사람이 생각해 내야하므로 가능한 한 유연성이 높은 수식을 생각해 내려는 노력 중의 하나가 [신경망] 이다.
신경망
- 머신러닝의 모델의 본질은 입력 데이터에 대해 해당 모델의 특징을 나타내는 값을 출력해주는 함수는 준비하는 것이다.
- 하나의 수식이 아닌 복수의 수식을 조합한 함수를 만드는 것이 신경망
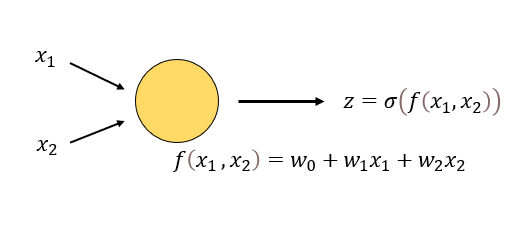
- 가장 간단한 신경망 = 노드(뉴런)
- , 두 값을 입력하면 값 도출, 시그모이드 함수로 0~1사이 값 출력
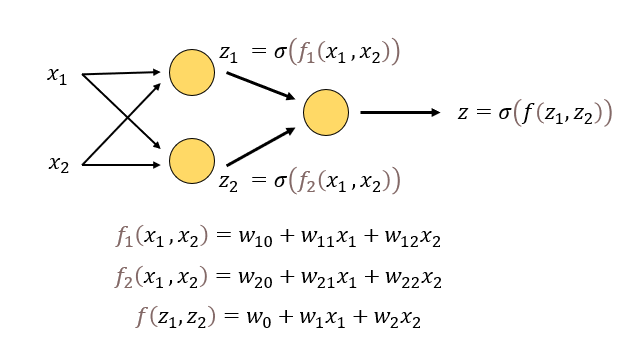
- 2계층 노드로 된 신경망
- 이 신경망에 총 9개의 파라미터가 포함되어 있으며 값을 조정해 단순한 직선이 아닌 복잡한 경계선을 표현할 수 있다.
1.1.3 딥러닝의 특징
딥러닝의 등장 배경
- 노드는 계층의 수를 늘리거나 하나의 계층에 포함된 노드의 수를 늘리 수 있다. 하지만 노드가 늘어날 수록 파라미터의 수가 방대해져 최적화 계산이 어려워진다.
- 눈에 보이지 않는 데이터의 특성을 감으로 찾아낸다는 어려움이 존재해 이를 해결하고자 등장한 것이 '딥러닝'
딥러닝
- 다층 신경망을 이용한 머신러닝
- 단순히 계층을 증가시켜 복잡화하는 것이 아닌 해결해야 하는 문제에 맞게 각각의 노드에 특별한 역할을 부여하거나 노드 간의 연결 방식을 다양하게 연구한 것
딥러닝의 예시
1. 최초의 입력이 이미지 데이터일 경우
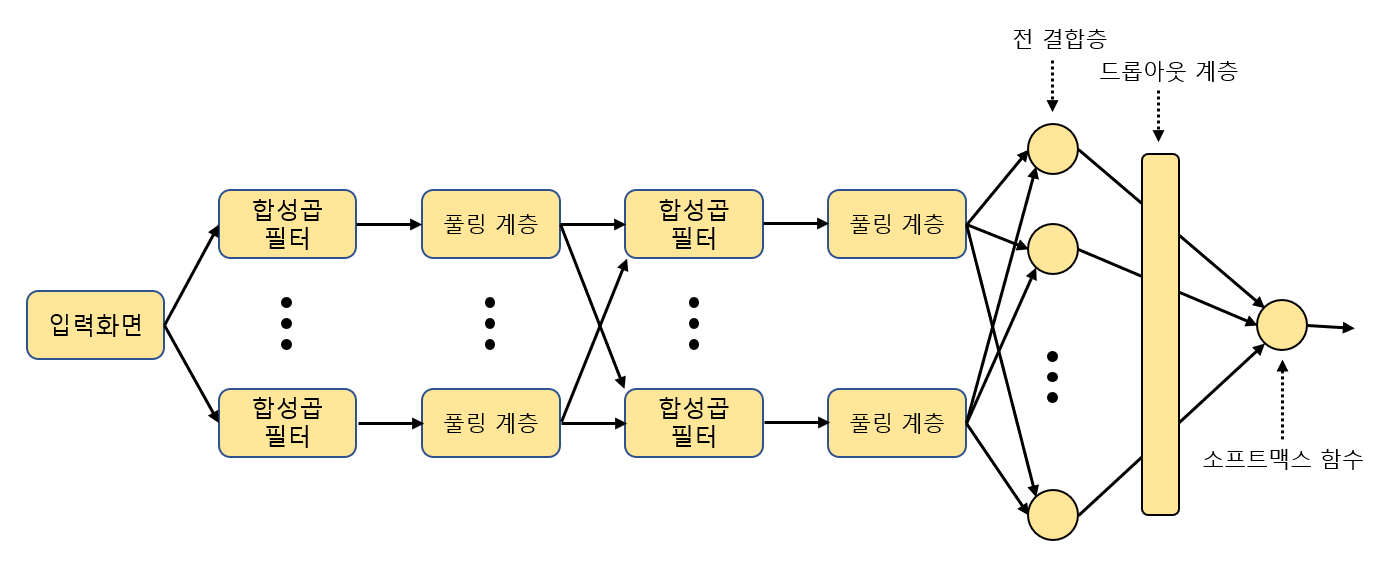
- 첫 번째 계층 노드 - 합성곱 필터
- 사진에서 물체의 윤곽을 추출하는 필터
- 두 번째 계층 노드 - 풀링 계층
- 이미지의 해상도 낮춤
- 순환 신경망 (RNN, Recurrent Neural Network)
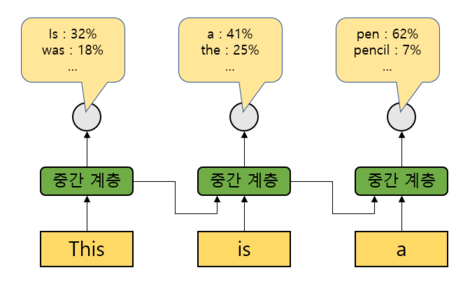
- 이전 중간 계층의 값을 다음 입력에 재이용함
- 'This' 입력 후 'is'를 입력할 때 'This'를 입력할 때의 중간 계층의 출력값이 더해서 입력됨
- 그 다음은 위의 중간 계층 정보와 'a'를 입력해 'This is a'에 이어질 단어를 예측함
딥러닝의 이면에는 최적의 네트위크를 구성해 가는 시행착오가 숨겨져 있다.
아무리 잘 만들어진 모델이라도 실제로 계산할 수 없다면 활용할 수 없기 때문에 각각의 네트워크에 대해 효율적으로 파라미터를 최적화하는 알고리즘 연구가 필요하다.
1.1.4 텐서플로를 이용한 파라미터 최적화
텐서플로는 경사 하강법을 사용해 오차함수의 파라미터 값을 결정한다.
경사 하강법
- 현재 파라미터의 값에 대해 기울기 벡터를 계산하고 그 반대 방향으로 파라미터를 수정하는 알고리즘
- 파라미터를 수정하는 분량을 주의해야 한다.
- 기울기 벡터가 너무 커지면 원점에서 멀어질 수 있기 때문에 단순히 기울기 벡터만큼 이동하는 것이 아니라 이동량을 적당히 줄여 가면서 파라미터가 발산하는 것을 방지해야 함
- 학습률을 조절한다.
- 학습률 : 한번의 갱신으로 파라미터를 얼마나 많이 수정하는지 결정하는 값.
- 에서 이 학습률
- 학습률 : 한번의 갱신으로 파라미터를 얼마나 많이 수정하는지 결정하는 값.
변수의 개수가 늘어나도 같은 방식을 사용하는데 이것이 매우 복잡해지기 때문에 이 부분을 자동화하는 것이 딥러닝에서 텐서플로의 역할이다.
텐서플로의 특징
1. 복잡한 신경망에 대해 편미분을 계산하고 기울기 벡터를 결정하며, 혹은 결정한 기울기 벡터를 이용해 경사 하강법으로 파라미터를 최적화하는 식의 알고리즘이 사전에 마련되어 있다.
2. 합성곱 필터나 풀링 계층에 해당하는 함수가 미리 준비되어 있다.
1.2 환경 준비
1.2.1 CentOS 7에서의 준비 과정(Google Colab)
이 책에서는 CentOS 7을 사용해 주피터를 사용하고 있지만 이 글에서는 Google Colab을 사용한다.
Colab의 장점
1. 머신러닝 과정에서 필요한 메모리와 GPU를 구글에서 제공하는 무료 자원으로 사용 가능하다.
2. 기본적으로 Tensorflow, Pytorch등이 설치되어 있어 환경 세팅의 번거로움이 없다.
하지만 파이썬만 실행 가능하다.
1.2.2 주피터 사용법
- 파일 - 새노트 클릭
- 파일 이름 변경
- 책의 예제 코드가 포함된 노트북 파일 다운로드
!git clone https://github.com/Jpub/TensorflowDeeplearning jupyter_tfbook- 구글 드라이브에 마운트 - 엑세스 허용 - drive폴더 생성됨
from google.colab import drive
drive.mount('/content/drive')- 내 구글드라이브로 파일 옮기기
!mv jupyter_tfbook/ ./drive/MyDrive/1.3 텐서플로 훑어보기
1.3.1 다차원 배열을 이용한 모델 표현
텐서플로에서는 계산에 사용하는 데이터를 모두 다차원 배열로 표현
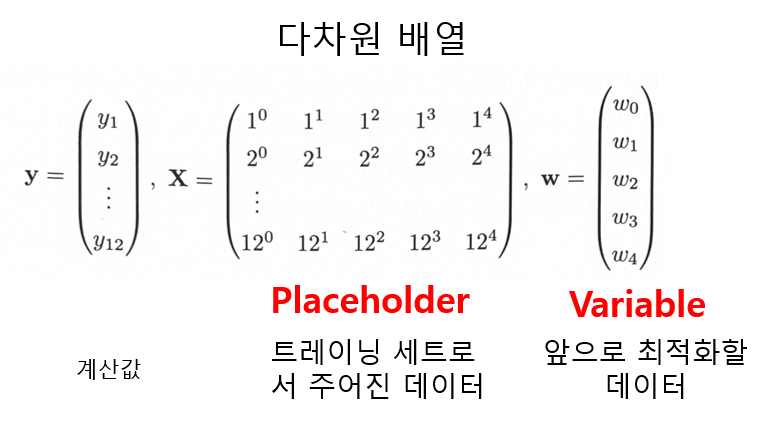
실제 텐서플로 코드로 표현해보자.
위 책의 텐서플로는 버전1이며 현재 코랩에서는 텐서플로 버전2를 사용하기 때문에
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()코드를 추가해야 한다.
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import matplotlib.pyplot as plt
x = tf.placeholder(tf.float32, [None, 5])
w = tf.Variable(tf.zeros([5,1]))
y = tf.matmul(x, w) #matmul은 행렬을 곱하는 함수
t = tf.placeholder(tf.float32, [None, 1]) #실제 관측된 기온
loss = tf.reduce_sum(tf.square(y-t)) #오차 함수
train_step = tf.train.AdamOptimizer().minimize(loss)
#adam optimizer을 사용해 학습률을 자동으로 조절
#.minimize(loss)는 loss를 오차 함수로 해서 이를 최소화하도록 명령
sess = tf.Session()
sess.run(tf.initialize_all_variables()) #텐서플로 v2에선 세션 필요 없음
train_t = np.array([5.2, 5.7, 8.6, 14.9, 18.2, 20.4,
25.5, 26.4, 22.8, 17.5, 11.1, 6.6]) #실제 관측된 데이터
train_t = train_t.reshape([12,1])
train_x = np.zeros([12, 5])
for row, month in enumerate(range(1, 13)):
for col, n in enumerate(range(0, 5)):
train_x[row][col] = month**n
#경사 하강법으로 파라미터 최적화
#앞의 train_step 트레이닝 알고리즘을 통해 Variable에 해당하는 변수보정 10만회 반복
#feed_dict옵션 : Placeholder에 구체적인 값 설정
i = 0
for _ in range(100000):
i += 1
sess.run(train_step, feed_dict={x:train_x, t:train_t})
if i % 10000 == 0:
loss_val = sess.run(loss, feed_dict={x:train_x, t:train_t})
print ('Step: %d, Loss: %f' % (i, loss_val))
#앞에 나온 결과를 이용해 예측 기온을 계산
w_val = sess.run(w)
def predict(x):
result = 0.0
for n in range(0, 5):
result += w_val[n][0] * x**n
return result
#함수를 그래프로 나타냄
fig = plt.figure()
subplot = fig.add_subplot(1,1,1)
subplot.set_xlim(1,12)
subplot.scatter(range(1,13), train_t)
linex = np.linspace(1,12,100)
liney = predict(linex)
subplot.plot(linex, liney)