
지금의 AWS가 된 과정 (가상화)
- AWS는 초기에 책을 팔았다
- 이후 물류사업에서 배송이 오래걸리는 단점을 빅데이터사용해서 선풍적인 인기를 끌었다.
- 이후 가상화를 사용해서 개발자가 단 몇번의 클릭으로 인프라를 구축할수 있게 함
- Paas - 개발자가 몇번의 클릭으로 네트워크,서버,보안,스토리지등 인프라 즉, 플랫폼을 구축할 수 있게 해줌 = 개발자가 바로 투입될 수 있는 플랫폼을 제공한다
- Iaas - 여러 회사가 오픈스택 프로젝트 진행함 - 인프라를 구성할 수 있는 환경을 제공 (여러 회사가 있기때문에 각자 색깔을 입혀야해서 플랫폼은 안된다)
- Saas - 서비스를 인증하면 클라우드가 만들어놓은 서비스제공
📒 Saas- > Paas - > Iaas
가상화의 장점/단점 및 컨테이너 기술
가상화의 장점
- 과거에는 박스환경 즉, 서버에 CPU,OS등을 올려서 사용
- 가상화를 통해 만든 독립적인 하드웨어에 os를 올려서 사용하여 싸고, 자동적인 오토스케일링,재해복구가 가능해졌다.
가상화의 치명적인 단점
- 운영체제가 임포트되는데 느리다 - > 만약 재해복구를 위해 이중화(프라이머리-대기) , 오토스케일링을 할때 임포트가 느려서 공백시간이 있다.
- 가상화는 자동화에 큰 제약이 있다.
컨테이너기술의 등장
- 컨테이너 = 해석환경 + os
- 즉시성을 가지고 있다
- 즉시성 : 가상화 환경에서 오토스케일링 할때 사람이 설정해야함 - 그걸 자동화로 만들어서 스케일 아웃이 필요할때 즉시성으로 자동적으로 확장
📌 가상화는 꼭 필요(os올리고 그 안에서 컨테이너 사용하는경우) but 가상화만 가지고는 효율적이지 않다
📌 온프레미스환경 = 박스환경
devops(쿠버네티스 클러스터 관리자)
devops : build하고 test하고 release하고 나온 이미지를 docker, aws 탑재하는 (CI/CD) 까지 과정(파이프라인)을 automation(자동화) 시키는 것을 함
- 개발자는 오로지 코드개발만하고 devops는 서버에만 집중한다고 보면됨
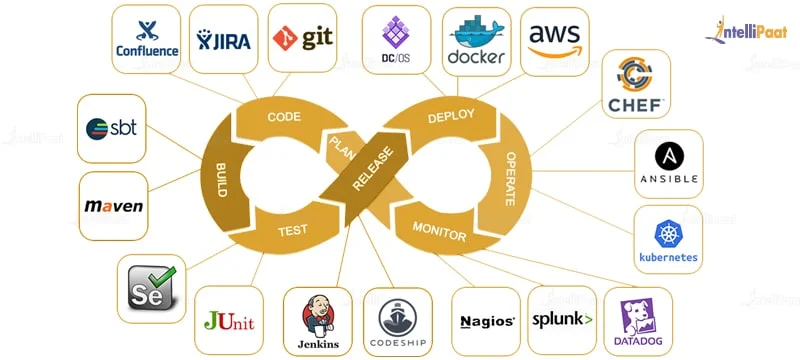
개발자의 영역은 그림에서는 코드쉽까지다.
이번 과정은 배포와 운영에 대한 것은 배운다.
내가 만든것이 잘 운영되는지 보려면 monitor를 해야한다.
AWS 제공 API를 저런 monitor(splunk,datadog등)사용해서 빅데이터로부터 통찰 -> 나중에 프로젝트할때 염두
네트워크
프로토콜 : 컴퓨터 네트워크를 하기 위하여 송수신 장치 간 통일된 통신 규약
📌 해당 프로토콜이 가진 규칙은 RFC문서에 반드시 정의되어있다
OSI 7계층
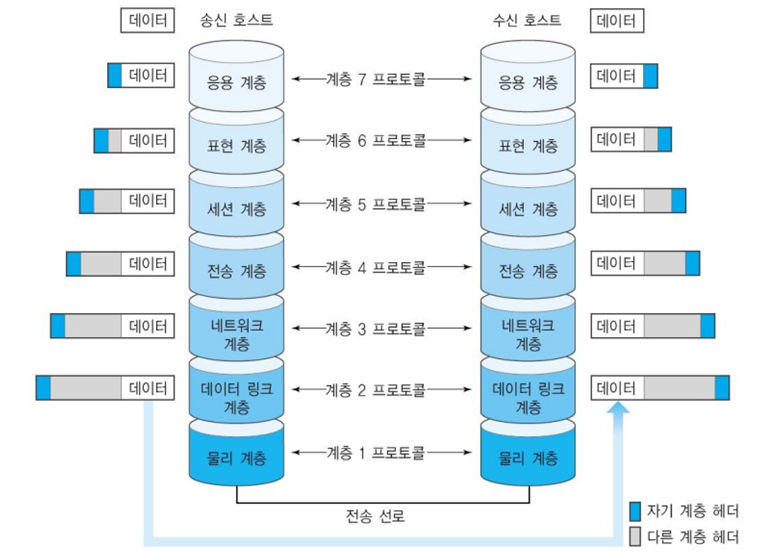
- 계층 별 특징
- 계층 별 PDU
- 게층 별 장비 및 Protocol
📌encapsulation : 위에서 아래로 내려오는 과정
📌decapsulation : 아래에서 위로 올라가는 과정
Application layer(7)
- pdu = data (http://~~~<-이 부분이 data)
Presentation Layer(6)
- pdu = data = 위 data + 압축,인코딩,암호화(SSL/TLS),코덱
Session Layer(5)
- pdu = data
- client들이 sever의 동일한 port를 목적지로해서 보냈을때 client를 session단위로 구분한다.
- 운영체제내에서 사용자를 식별하기 위한 단위, 로그인을했을때 유지되는 이유
if 세션날리면 로그아웃됨
Transport Layer(4)
- pdu = port+pdu = segment
- Transport Layer가 Aplication(aplication+presentation+session)에 연결해준다.
- Port number는 세가지 범위내에서 할당된다.
- System Ports(0~1023) : administrator, root권한으로 프로그램실행(binding)
- User Ports(1024~49151) : user권한으로 프로그램을 실행
- Dynamic and/or Private Ports(49152~65536) : cilent port(결국 source port)로 셋팅되는 포트로 os가 할당해줌
📒 보통 system,user는 서버, dynamic은 클라이언트에 할당된다.
-> C/S구조
📒 만약 system,user두가지만 있다면 system이 우위다. system이 서버가 된다.
- 포트넘버 찾기 : netstat -nato | findstr :445(포트넘버)
- 포트에 연결된 모든 프로세스 찾기 : netstat -nato | more
- port가 없다면 네트워크패킷이 들어올때마다 cpu가 계속 연산을 통해 process(PID)를 식별해야하고 이것은 비효율적이다.
- port는 패킷을 응용프로그램에 연결시켜줌
Network Layer(3)
- pdu = packet
- 장비 : router
- 논리적인 주소(IP)를 사용
- protocol : IP(주소 프로토콜), {ICMP, IGMP, IPSEC}(통신프로토콜)
- ARP를 통해 상대방의 MAC주소를 알 수 있다. 다만 Broadcast를 사용하기 때문에 Bandwidth의 낭비가 있다.
낭비를 해결하기 위해 ARP Cache Table을 사용하여 이미 통신한 MAC주소는 일정 기간동안 기록해둔다. - ARP를 보낼때 Cache table을 확인하고 원하는 MAC주소가 있다면 이미 통신한 것이기에 ARP를 보내지 않는다.
📌 ARP는 IP를 통해 상대방의 MAC주소를 아는 방법
💡 arp -a : arp cache테이블 확인
💡 arp -d : arp cache테이블 삭제
📌 RARP는 나의 MAC에 해당하는 IP를 아는 방법
datalink Layer(2)
- 데이터 전송을 위한 Format결정 , Error Detection제공
- MAC(하드웨어의 고유 주소),LLC정보 사용
- 물리적인 주소(MAC) 사용
- PDU = frame
- 장비 : 스위치 OR 스위칭 허브
- topology = 네트워크 망(ex.star,bus,ring,tree 등)
-> 네트워크의 끝단은 endpoint에 연결된다 - 기업 topology는 한마디로 기업의 네트워크 구성도
💡 현재 사용중인 네트워크망은 star + tree의 topology구조가 많다
💡 MAC의 OUI정보는 앞의 세가지 값으로 만든 회사의 정보를 알 수 있다.
Physical Layer(1)
- 물리적인 연결, 전기신호를 보냄
- PDU = 비트
- 장비 : 허브, repeater(증폭기), 케이블(ex. utp 등), 커넥터
추가 정보
process = 프로그램이 메모리에 올라가면
program = 확장자가 exe
processor = cpu
📒 it기술자가 사용하는 워딩 익숙해지기
📒saas업체는 iaas인증받은 업체에서 서비스를 인증받아서 제공받아야하는데 국내 iaas업체들의 kubernetes기술력이 약하다.
📒 협업도구 - slack, notion, trello, jira, github도 많이 사용해 버릇하자.
📒 만약 A에서 B로 보내는데 라우터를 거쳐서 보낼때 라우터에서는 데이터를 볼 수 없다.
-> 라우터는 3계층이고 데이터는 4계층 패킷에 담기기 때문에 라우터를 거칠때 3계층까지만 올라가므로 패킷을 볼 수 없다.
📒 windows - system32 - etc - services에 가면 내 os에서 규정한 서비스에 대한 프로토콜/포트번호가 정의되어 있다.
마치며
첫주차라 그런지 인트로 느낌의 강의였고 이것저것 많이 알려주신 느낌이다. 이번 주차까지는 네트워크와 전반적인 흐름에 대해서 포스팅 할 예정이다.
