pytorch
1.pytorch 기본 문법

numpy와 비슷하다.동일한건줄 알았는데 다르다고 한다.https://sanghyu.tistory.com/3view: 원본 데이터와 데이터 공유reshape: 원본 데이터와 데이터 공유될지 보장 못함. 될수도 안될수도 있다.많이 사용했던 함수인데 제대로된 정의
2.pytorch template, tip
지금까지 졸업프로젝트, 회사 인턴이나 알바들을 할 때 tf도 쓰고 pytroch도 썻지만 template이란 것들 정해두고 쓰지 않았다. 중구난방하게 필요에 따라서 디렉터리와 스크립트를 추가하고 분리하고 구현하고... 물론 템플릿이 만능은 아니다. 어느 템플릿이 그렇듯
3.pytorch hook
고등학생 때 DLL injection으로 피카츄 배구 해킹같은걸 했었는데, 그 때 사용했던 기법들이 일종의 hooking이다. 그런 기법들을 공식적으로 pytorch의 nn.Module에서 지원해준다.pytorch의 hook들은 다음과 같은 규칙을 가진다.return이
4.pytorch apply
nn.Module의 모든 하위 모듈들에 일괄적으로 적용하고 싶은 함수를 map과 같이 적용시켜주는 함수다.Postorder traversal 방식으로 module들을 순회한다고 한다. left child 우선으로 탐색.
5.pytorch dataset, dataloader
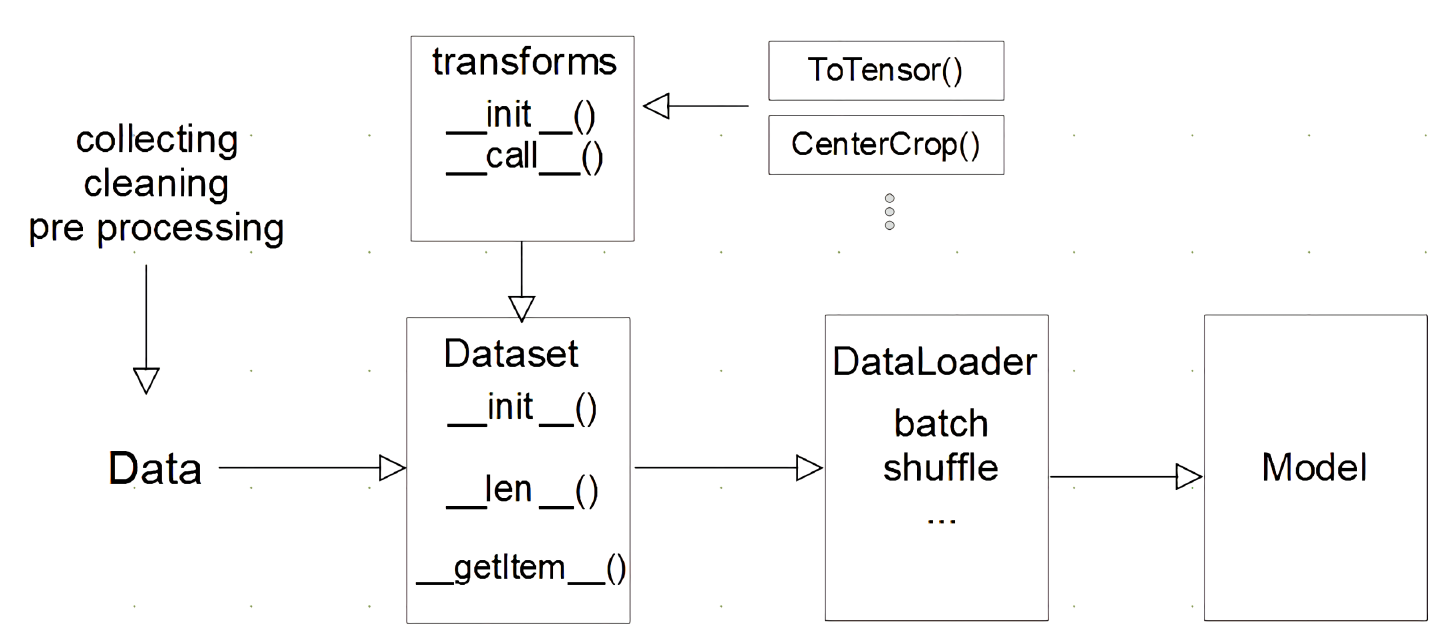
졸업프로젝트 때 직접 dataset, dataloader를 구현했었는데 시간에 쫓겨서 개발한지라 정말 개발새발로 내 기억 속에 남아있다.. 이 참에 헷갈리거나 몰랐던 내용들 위주로 정리해봤다.중요한 것은 데이터를 tensor로 바꿔주는 것 또한 따로 고려를 해야한다는
6.pytorch transfer
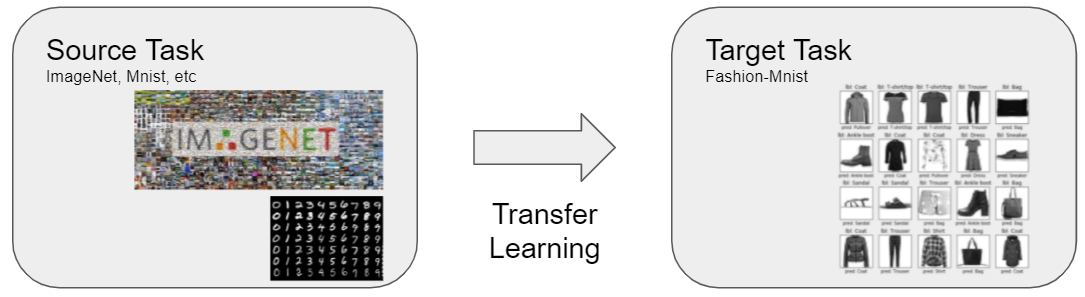
model 자체 코딩보다는 모델을 어떻게 다룰 것인지.다른 데이터셋으로 만든 모델(pre-trained model)을 현재 데이터에 적용텅 빈 모델로부터 개발하지 않아서 효율적대용량 데이터셋으로 만들어진 모델을 사용시, 성능은 더 좋다.가장 일반적인 학습 방법일부분만
7.Multi gpu
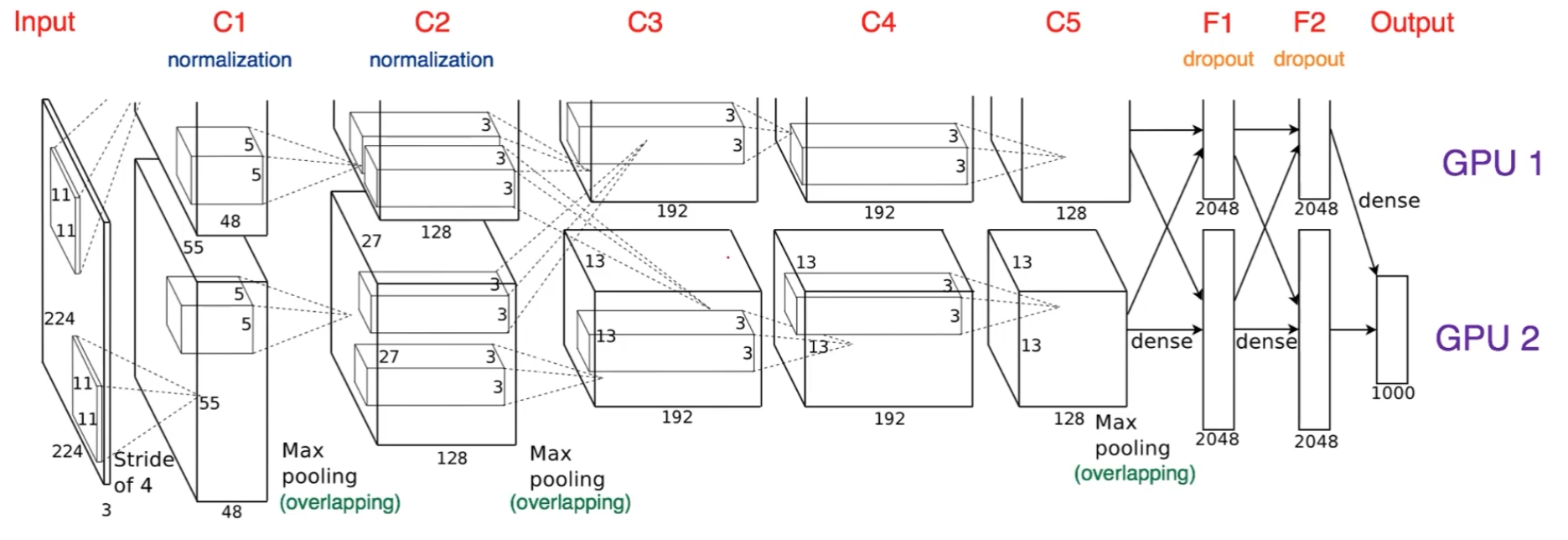
system과 동일하게 쓰이는 용어model parallelization은 alex-net에서 이미 쓰였던 적이 있다.좋은 gpu parallelization은 그림처럼 gpu가 동시에 사용되도록 파이프라인 구조로 코딩해야한다. gpu1에서 데이터 취합 후 뿌려주기각자
8.weight init
init method: https://reniew.github.io/13why?: https://stackoverflow.com/questions/49433936/how-to-initialize-weights-in-pytorch선택과제에서 varian
9.tqdm with epoch statics
tqdm을 쓰면 원래 accuracy나 loss를 따로 찍어줘야한다. tqdm 내에서만 사용되는 변수를 update하는 것으로 이걸 해결해볼 수 있다. https://adamoudad.github.io/posts/progress_bar_with_tqdm/
10.Hyperparameter tuning
개발자가 수동으로 정해야하는 값들learning ratesize of modeloptimizer의 종류epochetc...모델, 데이터, hyper paramter 중에서 hyper parameter의 수치는 중요도가 가장 떨어진다.모델이 가장 중요하지만 보통 좋은 모
11.Trouble shooting
nvidia-smi같은 모듈gpu, mem 통계를 지속적으로 콘솔에 찍어준다.gpu 메모리를 사용하는 tensor 변수들이 있다. (대부분)이런 변수들의 값이 지속적으로 누적되는 loop문이 있다면 gpu의 메모리가 금방 고갈될 것이다.e.g.,