node
system과 동일하게 쓰이는 용어
model parallelization
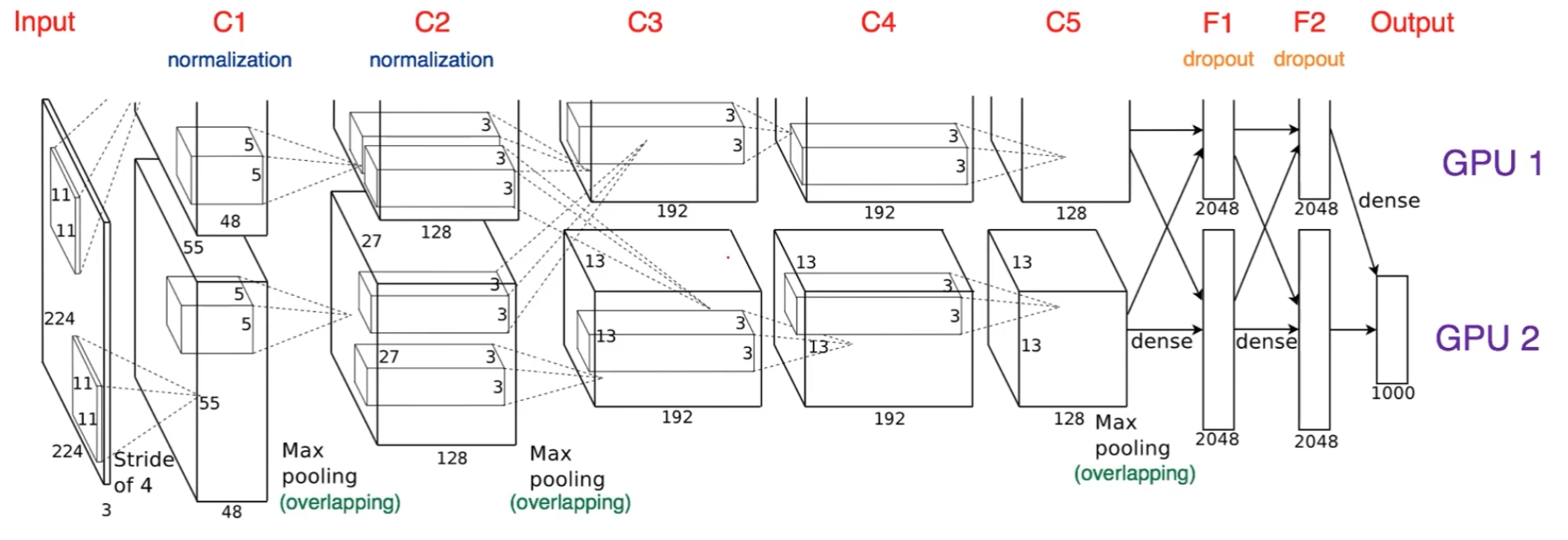
model parallelization은 alex-net에서 이미 쓰였던 적이 있다.
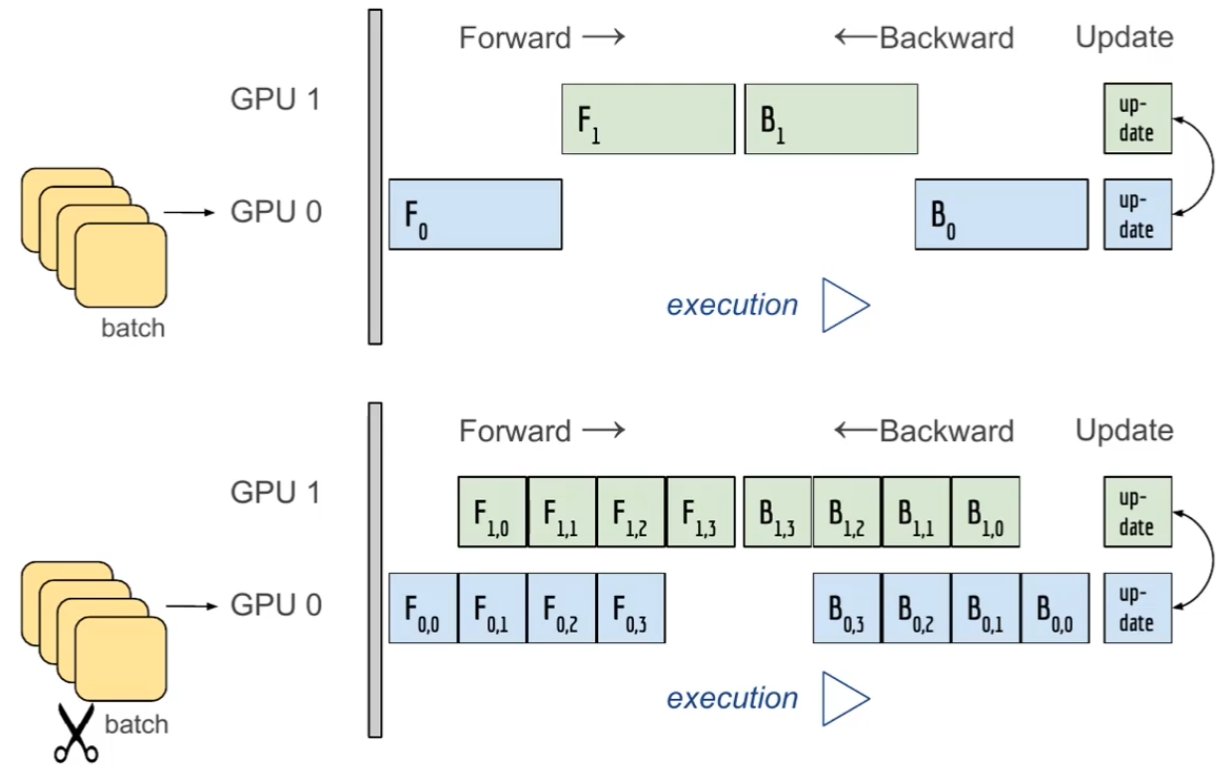
좋은 gpu parallelization은 그림처럼 gpu가 동시에 사용되도록 파이프라인 구조로 코딩해야한다.
data parallelization

- gpu1에서 데이터 취합 후 뿌려주기
- 각자 알아서 forward
- gpu1이 forward 취합
- gpu1이 gradient 정보 뿌려주기
- 각자 알아서 gradient 계산
- graident 취합 후 계산
pytorch의 DataParallel
- 위 방식을 그대로 구현할 수 있다.
- 단순히 데이터를 분배 후, 평균을 취함
- gpu 불균형 사용으로 인해 batch size 감소
pytorch의 DistributedDataParallel
각각의 gpu가 cpu 스레드를 할당받아서 알아서 평균 취한 결과를 구한다.
- sampler: dataloader에서 어떻게 데이터를 sampling 할지 결정해주는 객체. torch에서 제공해준다.
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
train_loader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=shuffle, pin_memory=pin_memory, num_workers=4, sampler=train_sampler)
- num_workers: thread 수. 보통 gpu의 4배로 사용한다고 한다.
- pin_memory: 데이터는 memory에 page되고 pinned되고 gpu에 올라간다고 하는데 바로 pinned되게 해준다고 한다.
def main():
ngpus_per_node = torch.cuda.device_count()
world_size = ngpus_per_node
torch.multiprocessing.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, ))
worker를 만들고 python에서 map 함수를 쓰듯이 spawn에 넣어준다.

https://github.com/naem1023