How to NLP
1.Language model Benchmark 간단 정리
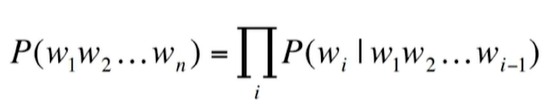
주재걸 교수님 강의에서 배웠던 내용들을 간략하게 정리할 겸, 특강 내용과 더불어 language model 정리를 한다.Seq2Seq task다. 주어진 문맥을 활용해 다음 단어를 예측하는 task.특정 시점의 문장에 대한 다음 단어가 나타날 확률을 예측하는 task로
2.BERT 응용
주재걸 교수님 강의에서 길게 풀어썻던 내용들이다. 짧게 BERT 모델을 다시 요약해보자. Introduction Language model은 위와 같은 순서로 발전했다. 초기에는 Encoder와 Decoder를 분리해 각각 RNN으로 개발했다. Seq2Seq에 At
3.Training BERT
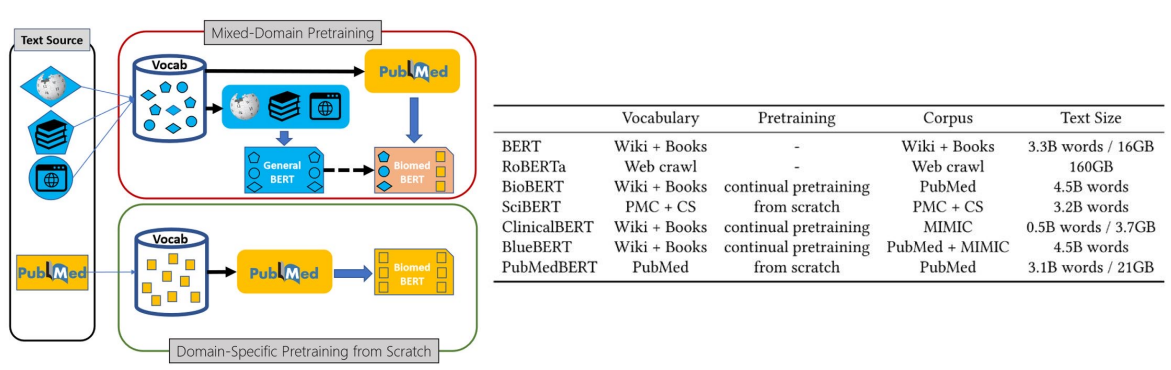
Create Tokenizer Make DatasetNSP(Next Sentence Prediction)Masking앞서 배웠던 내용이랑 조금 상반되는 내용이라 일단 적어본다.도메인 특화 task에서는 Pretrained model을 fine-tuning하는 것보다,
4.BERT 두 문장 관계 분류 task
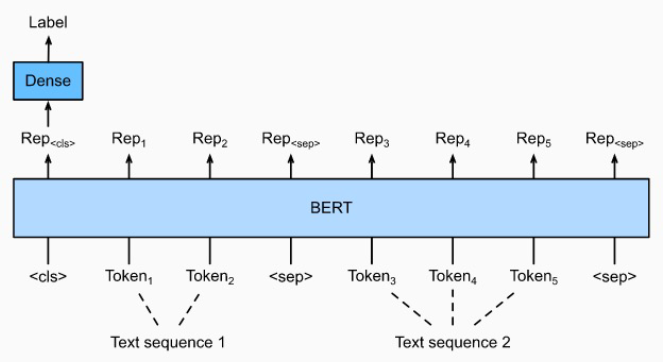
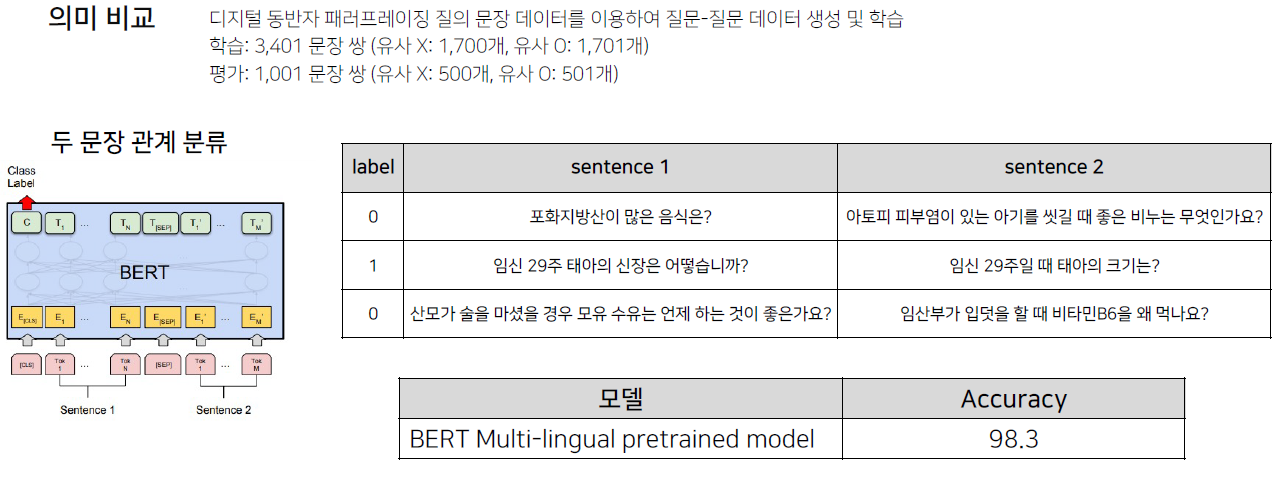
주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task. 문장 분류와 유사하게 CLS token에 대한 classifier로 분류를 한다. 다른 점은 두 문장이 SEP token을 통해 함께 모델에 입력된다는 점이다.Natural l
5.KLUE 의존 구문 분석, 단일문장 분류
지배소: 의미의 중심의존소: 지배소가 갖는 의미를 보완(수식)어순과 생략이 자유로운 한국어같은 언어에서 주로 연구지배소는 후위언어지배소는 항상 의존소보다 뒤에 위치각 의존소와 지배소는 한 개씩 존재한다.교차 의존 구조는 없다.중첩은 된다. 즉, A가 누군가의 지배소라면
6.문장 토큰 분류
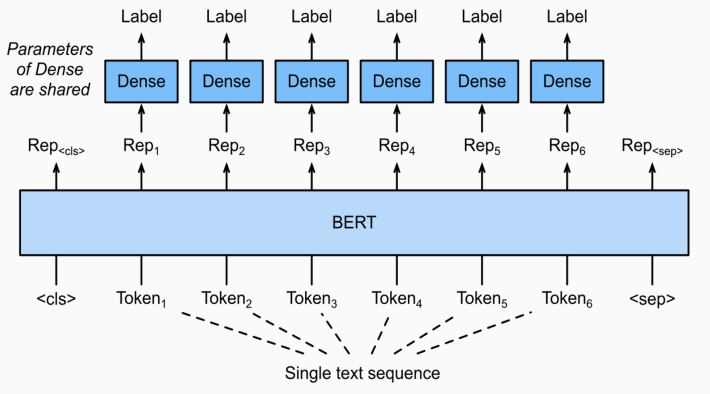
주어진 문장의 각 token들이 어떤 범주에 속하는 분류하는 task. classifier가 token마다 붙게된다.Named Entity Recognition.문맥을 통해 문서에서 인명, 기관명 같은 특정 의미를 가진 단어 / 어구 / 개체를 인식하는 과정.같은 단어
7.NLP trends

ROGUE score를 올리는 행위를 reward로 설정해서 RL을 수행하는 NLP.mixed objective and deep residual coattention for question answering.기존의 QA model이 Answer를 잘못 추출하는 경우가