두 문장 관계 분류 task
주어진 2개의 문장에 대해, 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 task.
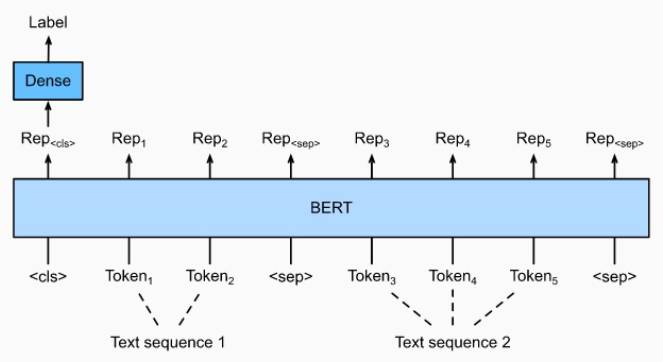
문장 분류와 유사하게 CLS token에 대한 classifier로 분류를 한다. 다른 점은 두 문장이 SEP token을 통해 함께 모델에 입력된다는 점이다.
NLI
Natural language inference.
- Language model이 자연어의 맥락을 이해하는지 검증하는 task
- Premise(전제)와 Hypothesis(가설)을 다으모가 같이 분류한다.
- Entailment(함의): hypothesis가 true
- Contradiction(모순): hypothesis가 false
- Neutral(중립): hypothesis가 true인 것으로 추정되거나, 명백하게 판단하기 어려운 경우
Semantic text pair
두 문장의 의미가 서로 같은 문장인지 검증하는 task
IRAQ
Information Retrieval Question and Answering.
질문에 대해, 사전에 정의한 QA set에서 가장 적절한 답을 찾아내는 task.
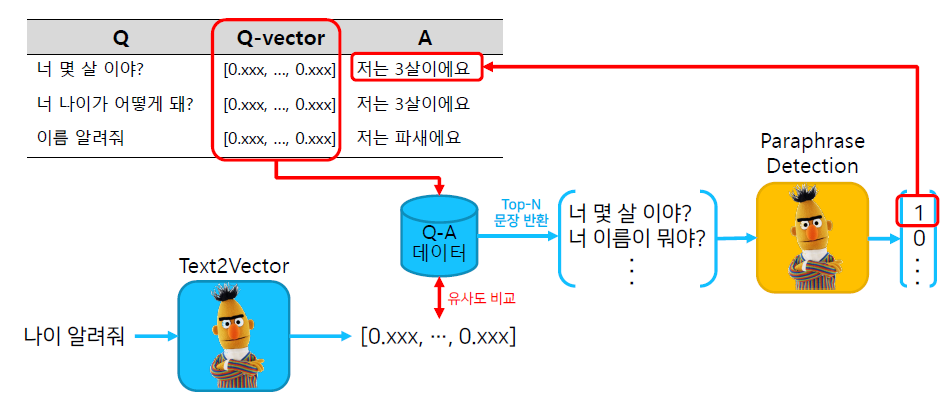
기본적인 구조는 일반적인 챗봇과 같다. 사용자의 Query와 사전에 정의한 Query의 유사도를 비교해서 유사도가 높은 Query에 대한 답변을 반환한다.
다른점은 모델의 마지막에 Paraphrase Detection이 붙는 점이다. 앞선 task를 통해 유사도가 높은 상위 n개의 답변이 준비될텐데, 여기서 가장 적절한 답을 찾는 모델이다. 의미론적으로 유사한지 추론하는 모델이 된다.

https://github.com/naem1023