해싱 (Hashing) 이란
원본 데이터의 값을 적절하게 매핑하는 과정을 해싱이라고 한다.
해싱이라는 단어가 자주 나오는 해시테이블에 대해서 언급을 해보자면
해시테이블은 검색하고자하는 key값을 입력받아서 해시함수를 돌려서 반환받은 해시코드를 배열의 인덱스로 환산해서 데이터에 접근하는 방식이다.
해시 테이블의 가장 큰 장점은 검색 속도가 매우 빠르다는 점.
(배열 공간을 고정된 크기로 미리 생성 후 인덱스로 접근하는 것이기 때문)
해시 함수의 제일 좋은 알고리즘은 어떻게 해야 값을 골고루 분포하게 하느냐. 이다. (충돌이 없게끔 한다.)
해시코드를 가지고 배열 인덱스로 환산하는 방법은 해시 테이블의 크기만큼
나눴을 때의 나머지로 하는 방법이 있다.
충돌이 생기는 경우를 대비하여 바로 해시 테이블에 값을 저장하는 것이 아니라 해시테이블 안에 Linked List를 선언하여 그곳에 할당해준다.
(출처 : https://www.youtube.com/watch?v=Vi0hauJemxA)
문제

어떻게 해야할까
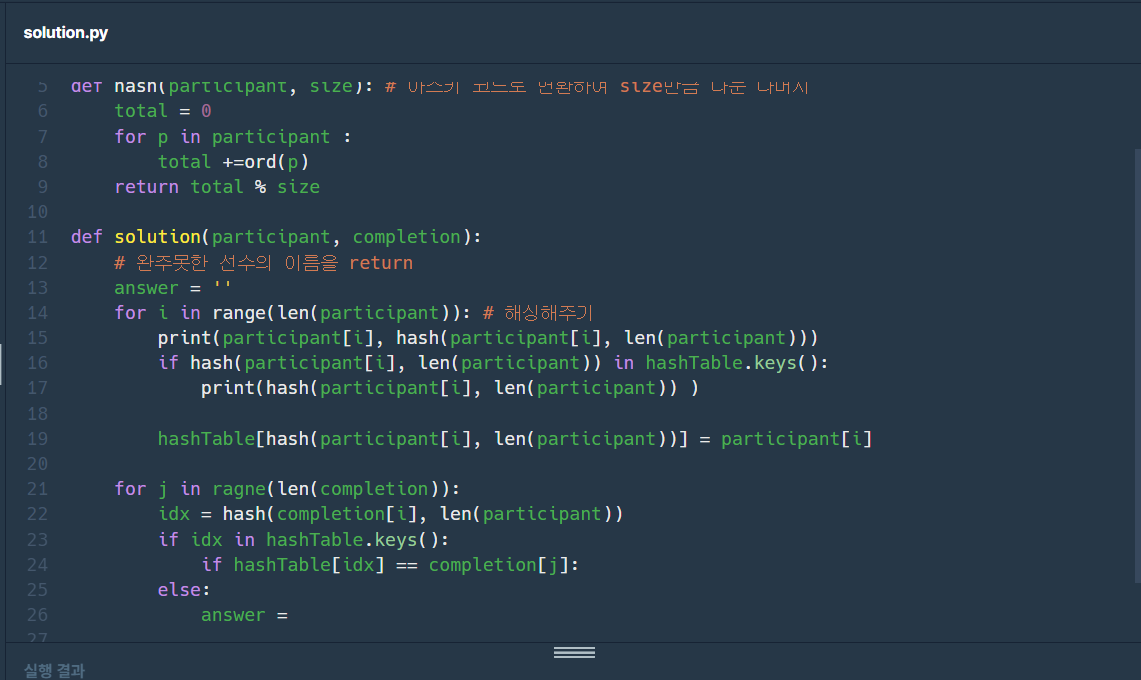
동명이인이 있을 수 있으니 충돌의 가능성이 높다. 그러면 Linked list를 선언해주어야되려나?
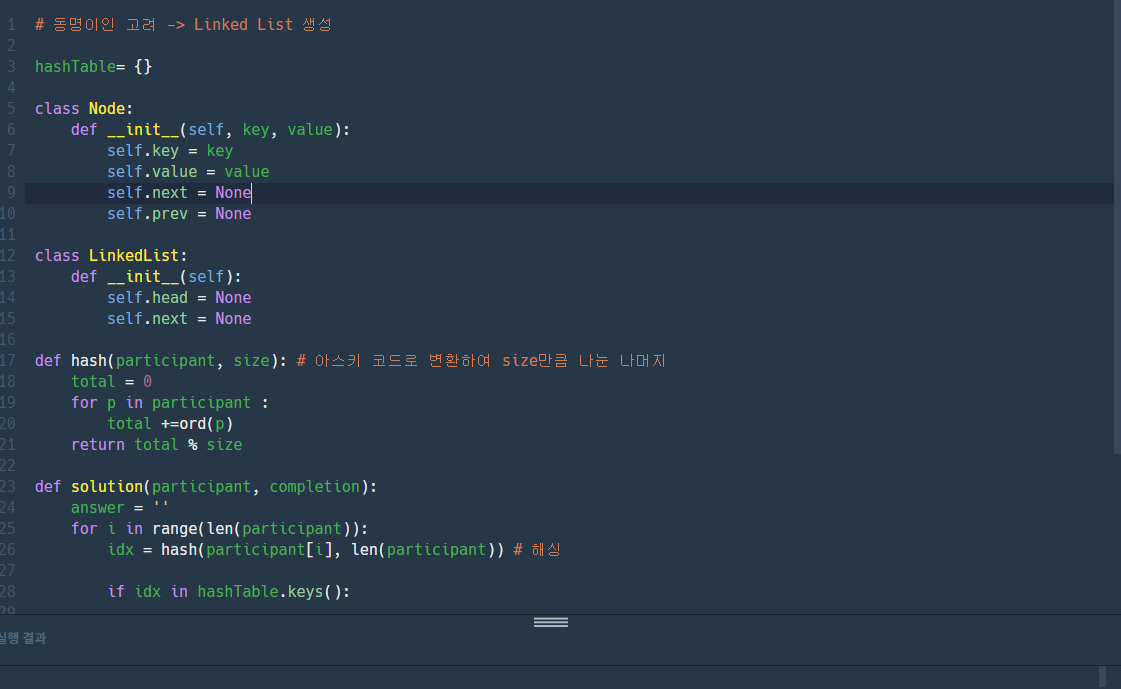
근데 Lv.1 치고 코드가 너무 길어진다. 이게 맞나 싶음. 좀더 간략화해서 해볼까..
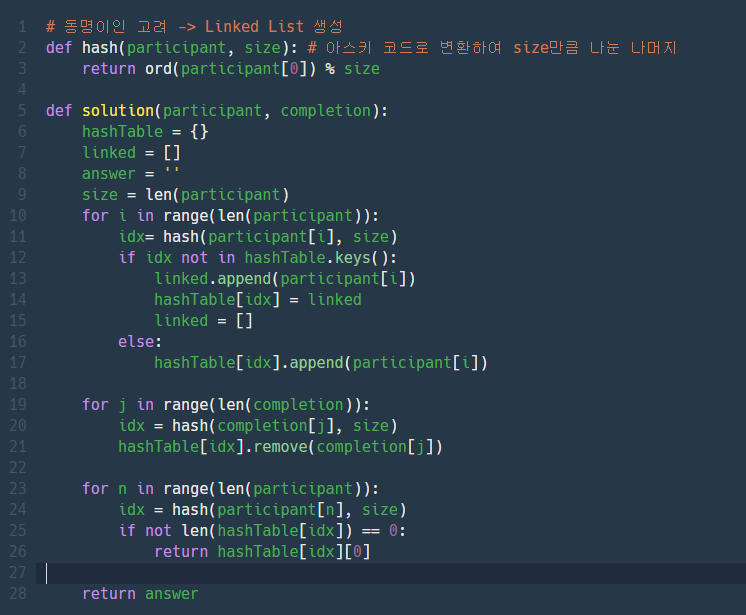 이렇게 하면 테스트케이스는 통과하는데 수행시간이 맞을지 모르겠다.
이렇게 하면 테스트케이스는 통과하는데 수행시간이 맞을지 모르겠다.
 이럴줄 알았다 ㅠ
이럴줄 알았다 ㅠ
최종 코드
그냥 진짜 간단하게 모든 참가자의 이름을 key값으로 하는 딕셔너리를 만들어서 중복이름을 count해주면 제일 간단했다.
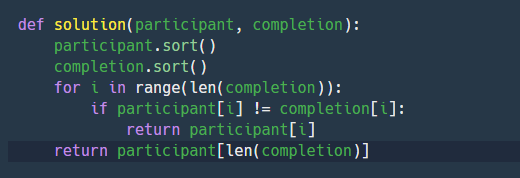
sort하는 방법도 있었지만 일단 내가 실제 테스트 볼 때 제일 쉽게 접근해서 사용할수 있는 코드 같아서 최종코드를 다음과 같이 제출했다.
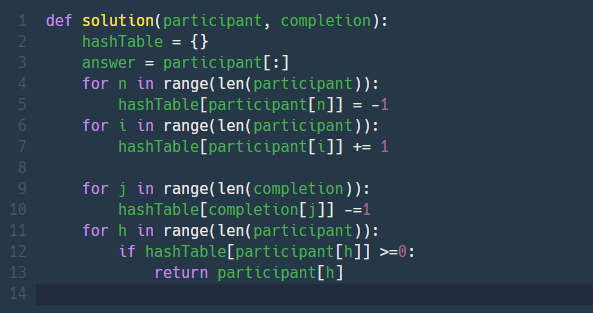
(+) sort로 푸는 방법
.gif)