
📌 2장. 통계분석
1. 통계의 이해
1) 통계 개요
- 통계와 표본조사
- 통계의 이해
- 통계: 분석하고자 하는 집단에 대해서 조사하거나 실험을 통해서 얻는 자료 또는 이의 요약된 형태를 말한다.
- 통계분석: 특정집단을 대상으로 자료를 수집하여 대상집단에 대한 정보를 구하고, 적절한 통계분석 방법을 이용하여 의사결정(통계적 추론)을 하는 과정을 말한다.
- 표본조사
- 특정 모집단에 대해서 전수조사가 거의 불가능하므로 모집단을 대표하는 표본집단을 선별하여 조사를 실시하는 방법이다.
- 표본의 대표성: 선별한 표본집단이 모집단을 대표할 수 있는가를 의미한다.
- 통계의 이해
- 표본추출 방법
- 단순 랜덤 추출법
- N개의 모집단에서 n개의 데이터를 무작위로 추출하는 방법이다.
- 계통 추출법
- 모집단의 원소에 차례대로 번호를 부여한 뒤 일정한 간격을 두고 데이터를 추출하는 방법이다.
- 집락 추출법
- 군집 추출법(Cluster Sampling)이라고도 한다.
- 데이터를 여러 집락으로 구분한 뒤, 단순 랜덤 추출법에 의하여 선택된 집락의 데이터를 표본으로 사용하는 방법이다.
- 각 집락은 서로 동질적이며, 집락 내 데이터는 서로 이질적이다.
- 층화 추출법
- 데이터를 여러 집락으로 구분하지만 각 집락은 서로 이질적이며, 군집 내 데이터들은 서로 동질적이다.
- 단순 랜덤 추출법
- 측정과 척도
- 측정과 척도의 개념
- 측정: 표본조사를 실시하는 경우 추출된 원소들이나 실험 단위로부터 주어진 목적에 적합하게 관측해 자료를 얻는 것
- 척도: 관측 대상의 속성을 측정하여 그 값이 숫자로 나타나도록 일정한 규칙을 정하여 바꾸는 도구
- 척도의 종류
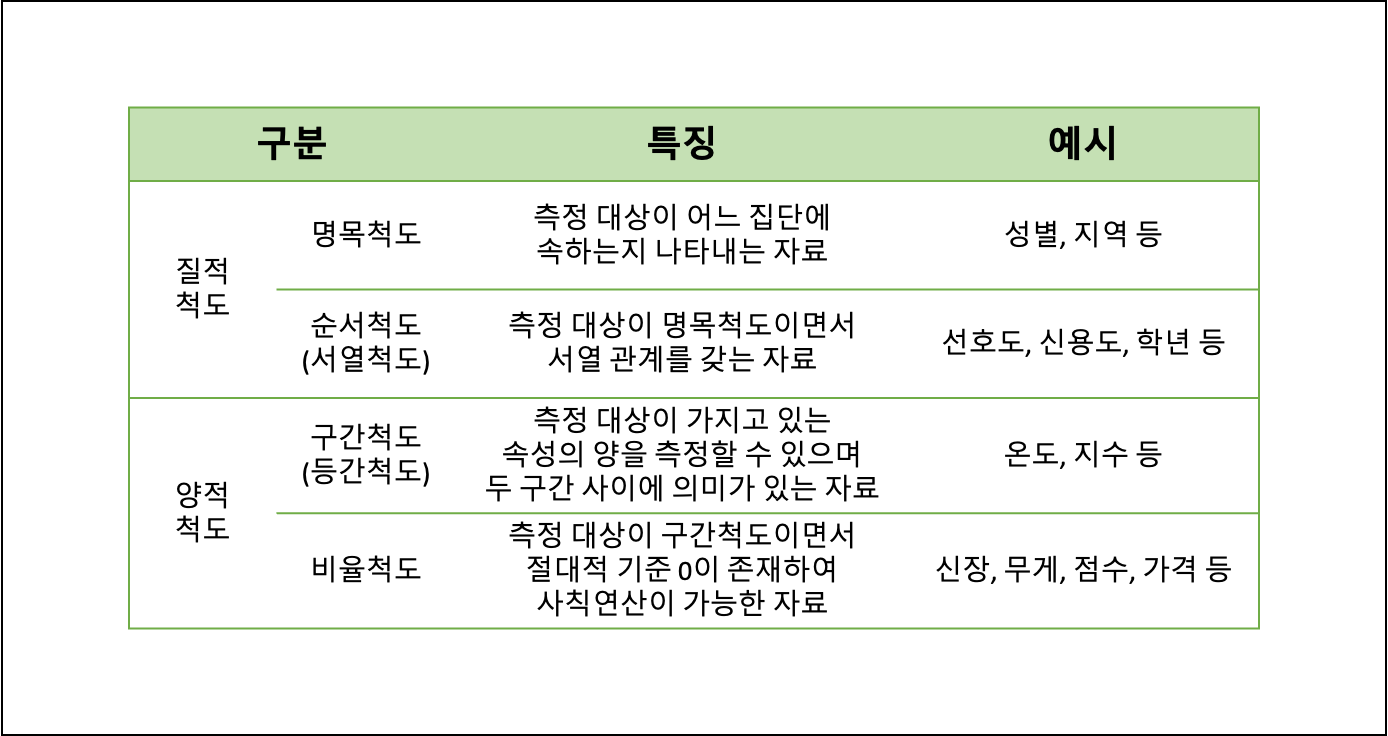
- 측정과 척도의 개념
- 기술통계와 추리통계
- 기술통계
- 표본 자체의 속성이나 특징을 파악하는데 중점을 두는 데이터 분석 통계이다.
- 자료를 요약하고 조직화, 단순화하는데 그 목적이 있다.
- 기술통계량: 데이터의 최소값, 최대값, 중위수 등의 통계량
- 추론통계(추리통계)
- 수집한 데이터를 바탕으로 '추론 및 예측'하는 통계 기법을 의미한다.
- 표본에서 얻은 통계치를 바탕으로 오차를 고려하면서 모수를 확률적으로 추정하는 통계기법이다.
- 기술통계
2) 확률과 확률분포
-
확률
- 발생가능한 모든 사건들의 집합 표본공간에서 표본공간의 부분집한인 특정 사건 A가 발생할 수 있는 비율을 나타내는 값
- 0 ~ 1 사이의 값
- 가능한 모든 사건의 확률의 합은 항상 1이다.
- 발생가능한 모든 사건들의 집합 표본공간에서 표본공간의 부분집한인 특정 사건 A가 발생할 수 있는 비율을 나타내는 값
-
조건부 확률
- 특정 사건 A가 발생했다는 것이 사실이라는 전제하에 또 다른 사건 B가 발생할 확률을 나타낸 값
-
독립사건과 배반사건
- 독립사건: 서로에게 영향을 주지 않는 두 개의 사건을 의미한다.

- 배반사건: 두 사건 A와 B에 대하여 교집합, 즉 공통된 부분이 없는 경우를 의미한다.
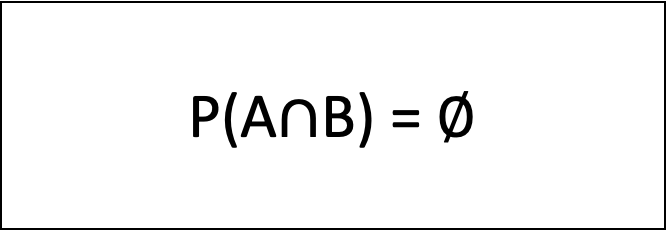
- 독립사건: 서로에게 영향을 주지 않는 두 개의 사건을 의미한다.
-
확률변수와 확률분포 그리고 확률변수
- 확률변수
- 무작위 실험을 했을때 특정 확률로 발생하는 각각의 결과를 수치적 값으로 표현하는 변수를 의미한다.
- 확률분포
- 확률변수의 모든 값과 그에 대응하는 확률이 어떻게 분포하고 있는지를 의미한다.
- 이산확률분포의 확률함수는 '확률질량함수', 연속확률분포의 확률함수는 '확률밀도함수'
- 확률변수
-
이산확률분포
- 베르누이 분포
- 확률변수 X가 취할 수 있는 값이 두 개인 경우로 일반적으로 한 번의 시행을 할때 성공과 실패로 나눌 수 있는 성공할 확률이 p인 분포를 의미한다.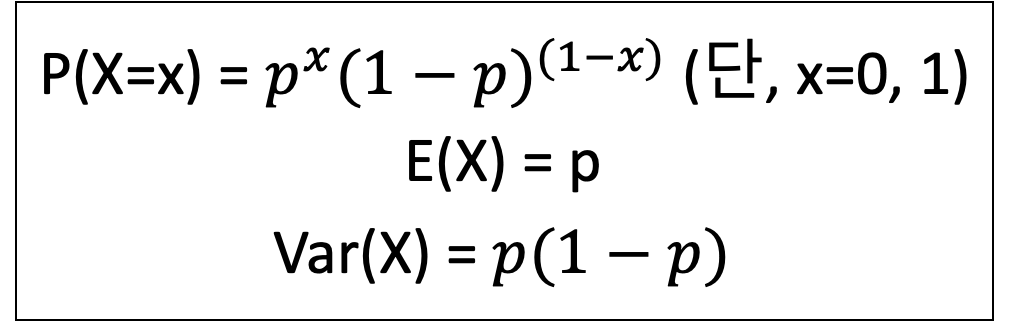
- 이항 분포
- n번의 베르누이 시행에서 k번 성공할 확률의 분포를 의미한다.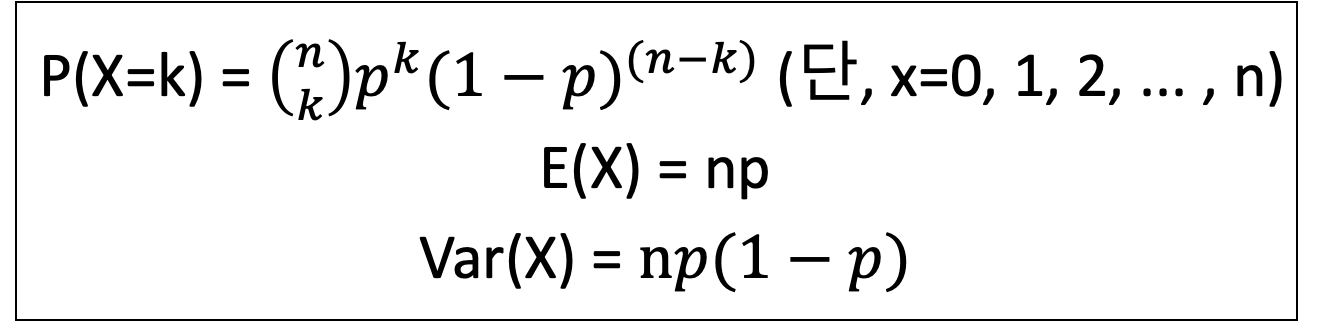
- 기하 분포
- 성공 확률이 p인 베르누이 시행에서 처음으로 성공이 나올 때까지 k번 실패할 확률의 분포를 의미한다.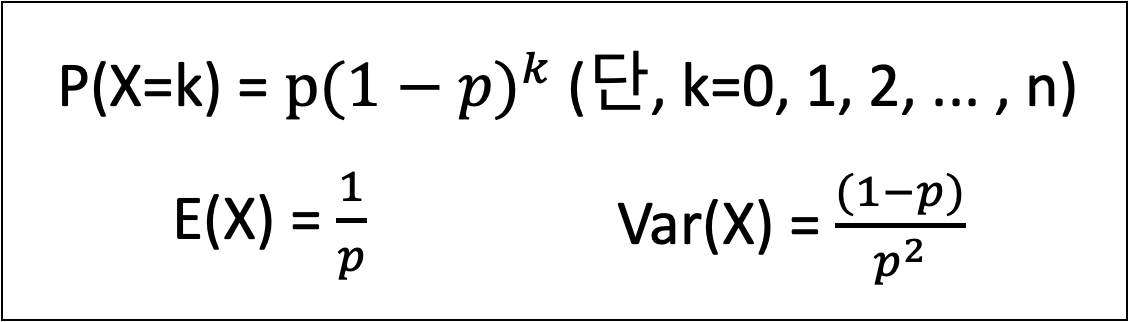
- 다항 분포
- 이항 분포를 확장한 개념으로, n번의 시행에서 각 시행이 3개 이상의 결과를 가질 수 있는 확률의 분포를 의미한다.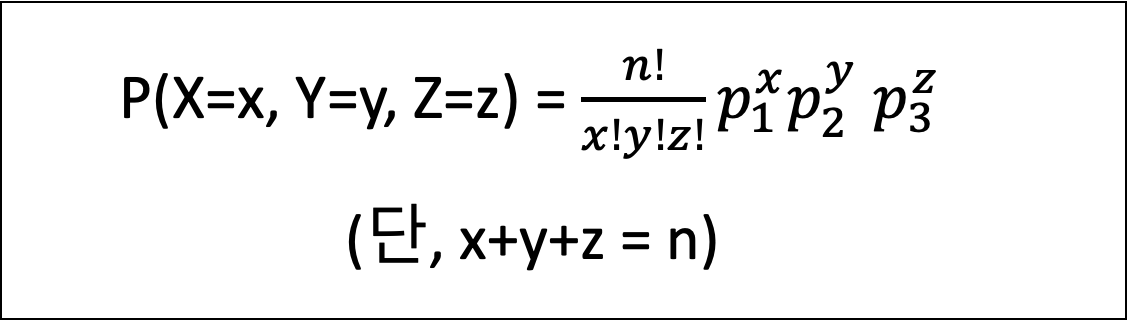
- 포아송 분포
- 단위 시간 또는 단위 공간 내에서 발생할 수 있는 사건의 발생 횟수에 대한 확률분포를 의미한다.
- 이산확률변수
- 확률변수가 취할 수 있는 실수 값의 수를 셀 수 있는 변수를 의미한다.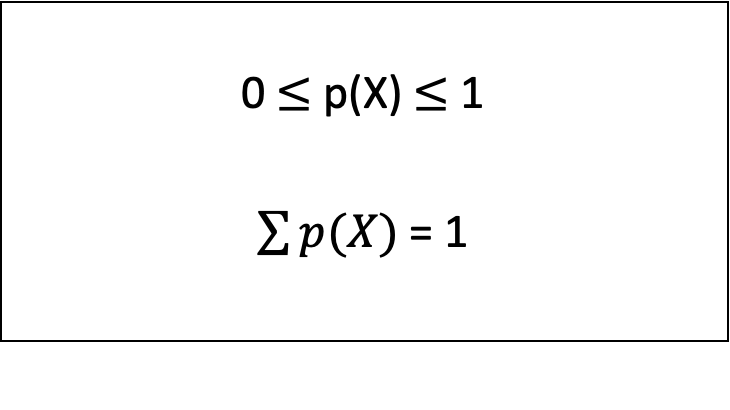
- 베르누이 분포
-
연속확률분포
- 균일 분포
- 연속형 확률변수인 X가 취할 수 있는 모든 값에 대하여 같은 확률을 갖고 있는 분포를 의미한다.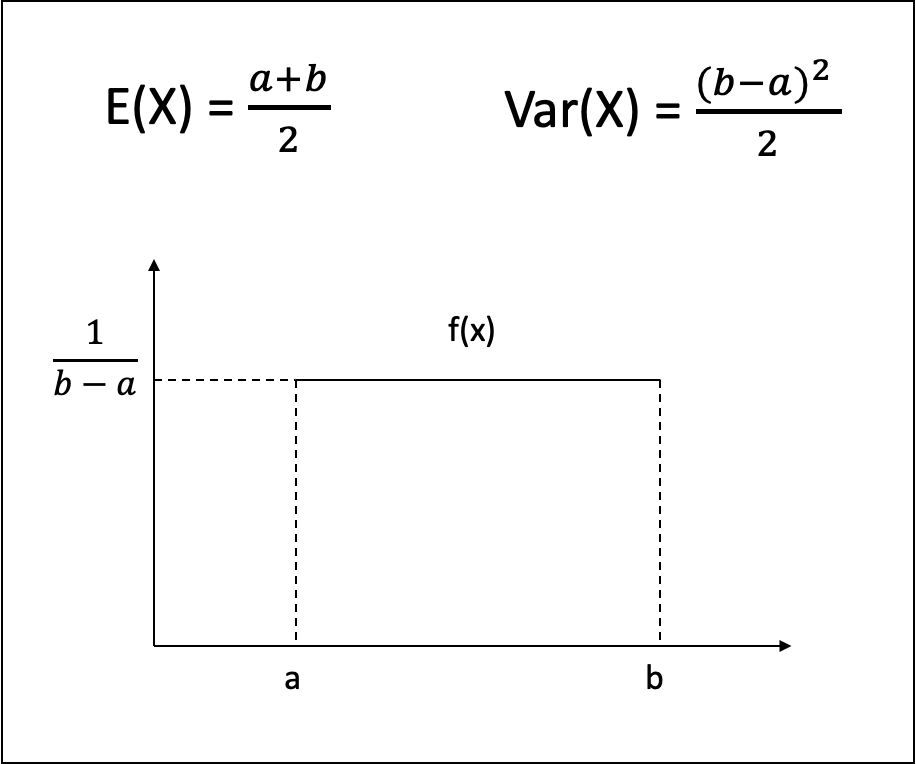
- 정규 분포
- 가장 대표적인 연속형 확률분포 중 하나로 평균이 𝜇이고, 표준편차가 𝜎인 분포를 의미한다.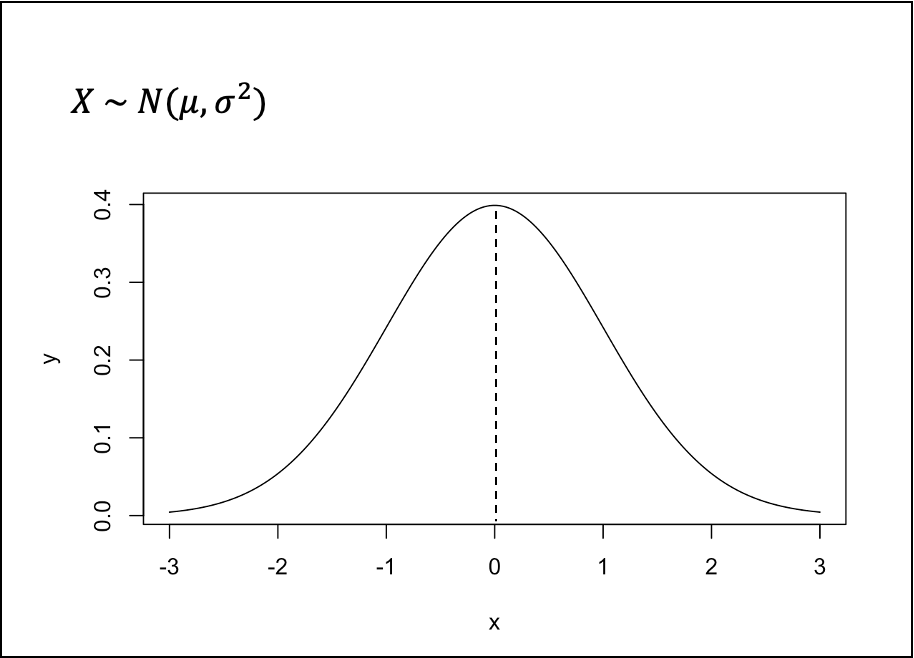
- t-분포
- 자유도가 n인 t 분포는 표준정규분포와 마찬가지로 평균이 0이고 좌우가 대칭인 종 모양의 그래프지만 정규분포보다 두꺼운 꼬리를 갖는다.
- 자유가 커질수록 t 분포는 표준정규분포에 가까워진다.
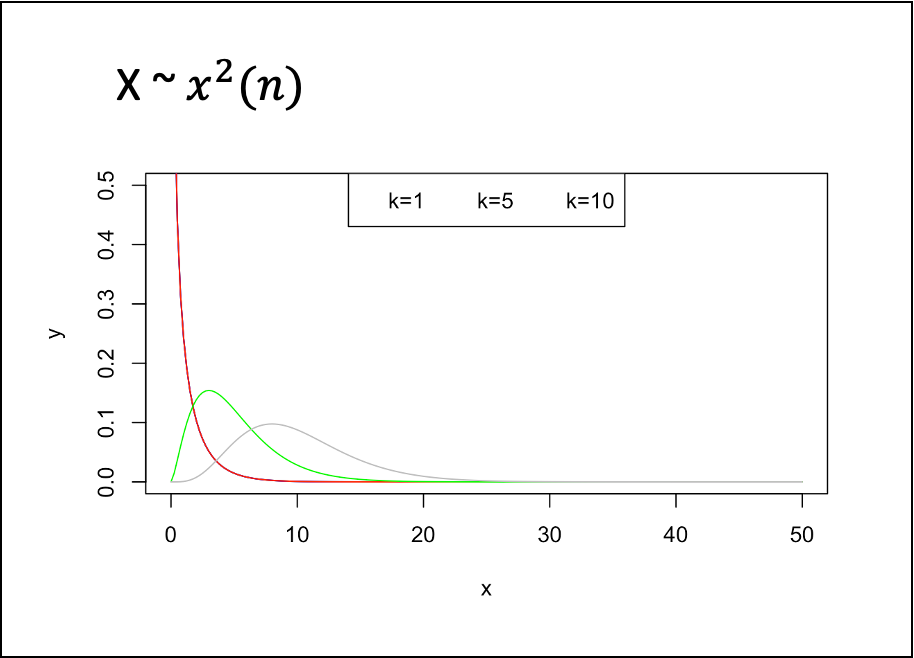
- 카이제곱 분포
- 표준정규분포를 따르는 확률변수 Z1, Z2, ..., Zn의 제곱의 합 X는 자유도가 n인 카이제곱 분포를 따른다.
- 모평균과 모분산을 모르는 두 개 이상의 집단 간 동질성 검정 또는 모분산 검정을 위해 활용된다.
- F 분포
- 서로 독립인 두 카이제곱 분포를 따르는 확률변수 V1, V2를 각각의 자유도로 나누었을 때 서로의 비율 X는 자유가 k1, k2인 F분포를 따른다.
- 등분산 검정 및 분산분석을 위해 활용된다.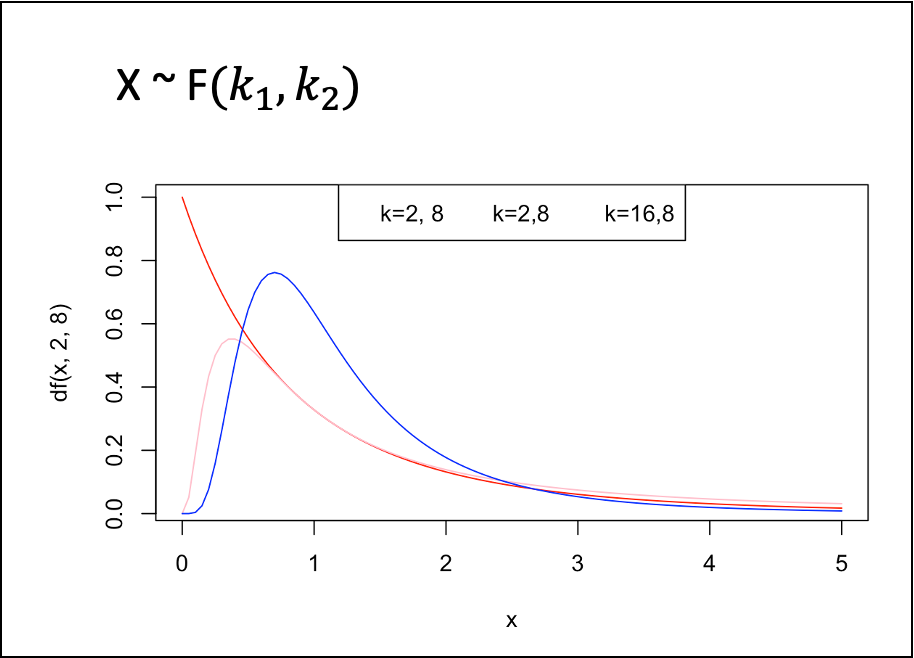
- 연속확률변수
- 확률변수가 취할 수 있는 실수 값이 어떤 특정구간 전체에 해당하여 그 수를 셀 수 없는 변수를 연속확률변수라 한다.
- 확률밀도함수의 아래 면적이 확률을 의미한다.
- 균일 분포
-
기댓값, 분산, 표준편차
-
기댓값
- 특정 사건이 시행되었을때 확률변수 X가 취할 수 있는 값의 평균 값을 의미한다.
-
분산
- 데이터들이 중심에서 얼마나 떨어져 있는지를 알아보기 위한 측도이다.
- 확률변수의 분산: 확률변수가 취할 수 있는 값들이 그 중심(모평균)에서 얼마나 떨어져 있는지를 측정하는 측도이다.
-
표준편차
- 자료의 산포도를 나타내는 수치
- 분산의 양의 제곱근으로 정의된다.
-
첨도(kurtosis)
- 확률분포의 뾰족한 정도를 나타내는 측도이다.
- 값이 3에 가까울수록 정규분포 모양을 갖는다.
-
왜도(Skewness)
- 확률분포의 비대칭 정도를 나타내는 측도이다.
- 왜도값이 0인 경우에는 정규분포와 유사한 모습으로 평균, 중앙값, 최빈값이 모두 같다.
-
공분산(Covarience)
- 두 확률변수 X, Y의 상관 정도를 나타내는 값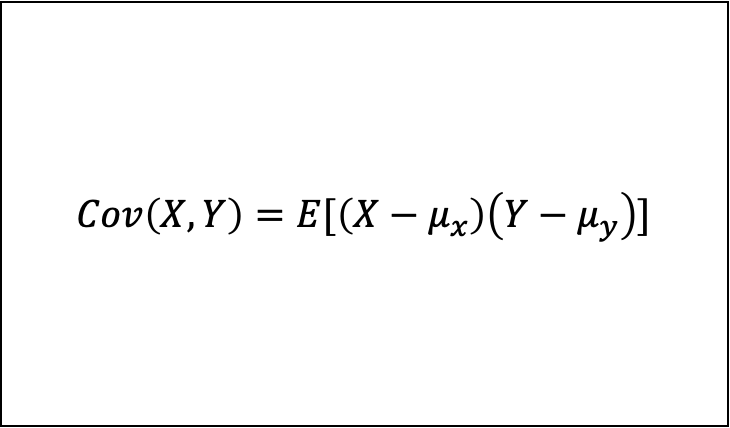
-
상관계수(Correlation)
- -1과 1 사이의 값을 가지며 공분산을 X의 표준편차와 Y의 표준편차 모두로 나눈 값이다.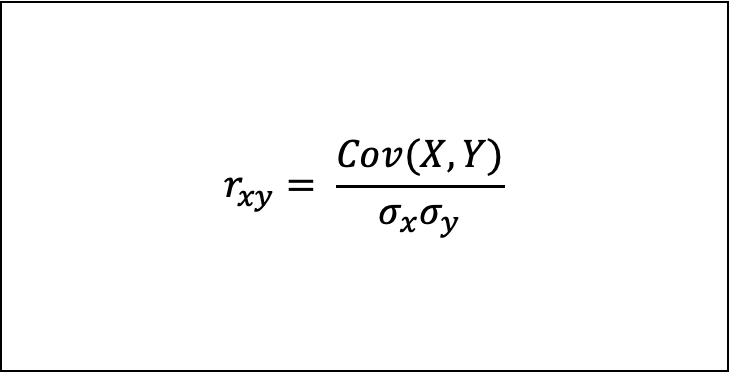
3) 추정과 가설검정
- 추정
- 모수의 추정
- 모집단의 확률분포 및 특성을 알려주는 모평균과 모분산과 같은 값들인 모수라고 한다.
- 점추정
- 모평균을 추정할때 모평균을 하나의 특정한 값이라고 예측하는 것이다.
- 불편추정량: 모수를 추정할때 추정하는 값과 실제 모수 값의 차이의 기댓값이 0으로 어느 한쪽으로 편향되지 않아 모수를 추정하기에 이상적인 값을 의미한다.
- 구간추정
- 모수가 특정한 구간 안에 존재할 것이라 예상하는 것이다.
- 신뢰도(신뢰수준)는 95%와 99%를 가장 많이 사용한다.
- 모수의 추정
- 가설검정
- 가설검정의 개념
- 모집단의 특성에 대한 주장 또는 가설을 세우고 표본에서 얻은 정보를 이용해 가설이 옳은지를 판정하는 과정이다.
- 통계적 가설은 귀무가설과 대립가설로 구분할 수 있다.
- 귀무가설(Null Hypothesis)
- 모집단이 어떠한 특징을 지닐 것으로 여겨지는 가설 또는 실험, 연규를 통해 기각하고자 하는 어떤 가설을 의미한다.
- 일반적으로 '차이가 없다.', '같다(=)'를 사용하여 나타낼 수 있는 가설로 흔히 H0로 나타낸다.
- 대립가설(Alternative Hypothesis)
- 귀무가설에 반대되는 가설로, 귀무가설이 틀렸다고 판단될 경우 채택되는 가설 또는 실험, 연구를 통해 증명하고자 하는 새로운 아이디어 혹은 가설에 해당하며 H1으로 나타낸다.
- 제 1종 오류와 제 2종 오류
- 제 1종 오류: 귀무가설(H0)이 사실인데 귀무가설(H0)이 틀렸다고 결정하는 오류
- 제 2종 오류: 귀무가설(H0)이 사실이 아님에도 불구하고 귀무가설(H0)이 옳다고 결정하는 오류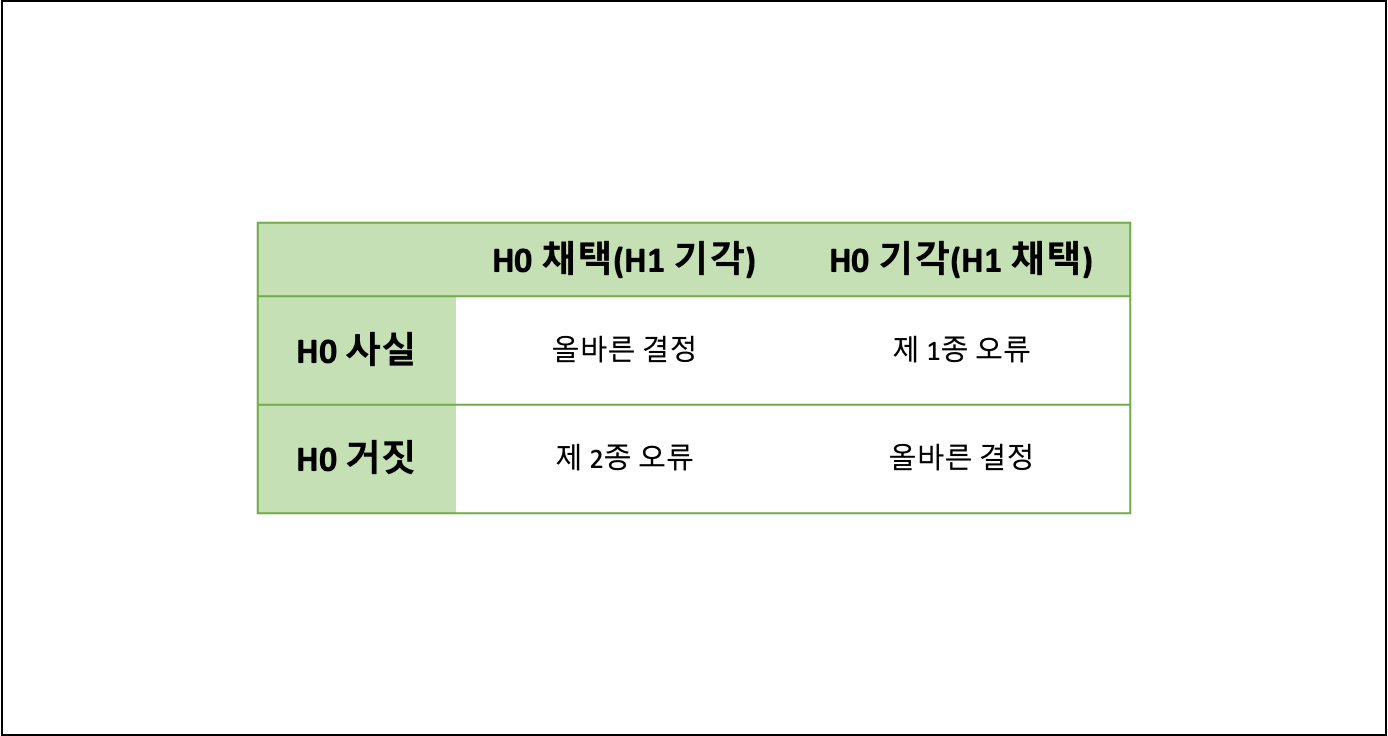
- 검정통계량(Test Statistic)
- 귀무가설의 채택 여부를 판단하기 위하여 표본조사를 실시하였을 때 특정 수식에 의하여 표본들로부터 얻을 수 있는 값이다.
- 귀무가설의 옳고 그름을 판단할 수 있는 값
- 기각역
- 귀무가설을 기각하게 될 검정통계량의 영역이다.
- 검정통계량이 기각역 내에 있으면 귀무가설을 기각한다.
- 기각역의 경계값을 임계값(critical value)이라고 한다.
- 유의수준(Significance Level, α)
- 귀무가설이 참인데도 이를 잘못 기각하는 오류를 범할 확률의 최대 허용한계를 의미한다.
- 1%(0.01), 5%(0.05)를 주로 사용한다.
- 유의확률(Significance Probability)
- p-value라고도 하며, 귀무가설을 지지하는 정도를 나타낸 확률이다.
- 유의수준 α보다 작은 경우에는 귀무가설이 참임을 가정했을 때 이러한 결과가 나올 확률이 매우 적다고 해석할 수 있다.
- 가설검정의 개념
- 모수검정 vs 비모수검정
- 모수검정(Parametric Test)
- 표본이 정규성을 갖는다는 모수적 특성을 이용하는 통계방법이다.
- 따라서 표본의 정규성이 반드시 확보되어야 한다.
- 비모수검정(Nonparametric Test)
- 정규성 검정에서 정규분포를 따르지 않는다고 증명되거나 표본 군집당 10명 미만의 소규모 실험에서와 같이 정규분포임을 가정할 수 없는 경우에 사용한다.
- 모수검정과 비모수검정의 차이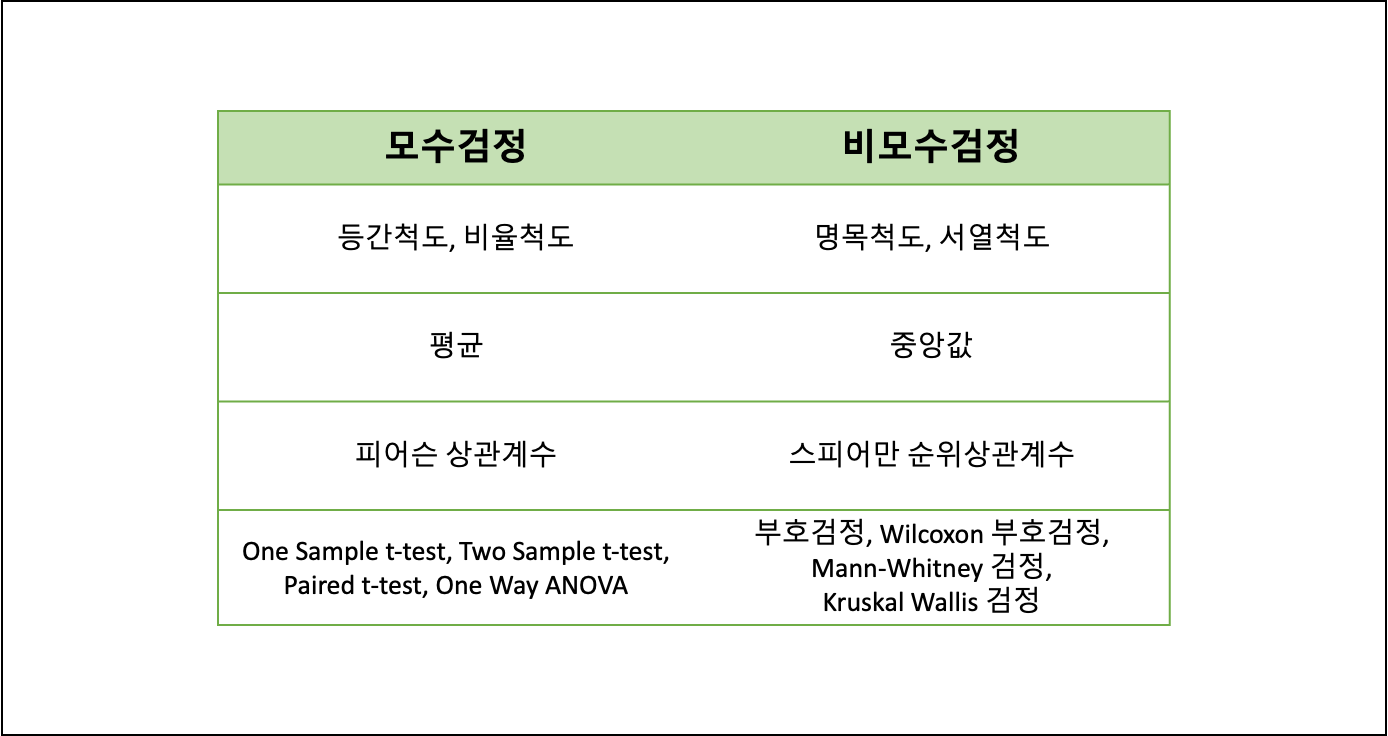
- 모수검정(Parametric Test)
2. 기초통계
1) t-검정
-
단일 표본 t-검정(One Sample t-test)
- 단측 t-검정 개념
- 모수에 대한 검정을 할때 모수값이 한쪽으로의 방향성을 갖는 경우 수행되는 검정방법이다.
- 단측 검정

- 양측 t-검정 개념
- 모수값이 방향성이 없는 경우 수행되는 검정 방법이다.
- 양측 검정

- 단측 t-검정 개념
-
이(독립) 표본 t-검정(Independent Sample t-test)
- 개념
- 서로 독립적인 두 개의 집단에 대하여 모수(모평균)의 값이 같은 값을 갖는지 통계적으로 검정하는 방법이다.
- 독립이란 두 모집단에서 각각 추출된 두 표본이 서로 관계가 없다는 것을 의미한다
- 두 모집단의 분산이 같음을 의미하는 등분산성을 만족해야 한다.
- 이 표본 단측 검정

- 이 표본 양측 검정

- 개념
-
대응 표본 t-검정(Paired t-test)
- 개념
- 동일한 대상에 대한 두 가지 관측치가 있는 경우 이를 비교하여 차이가 있는지 검정할 때 사용한다.
- 주로 시험 전후의 효과를 비교하기 위해 사용한다.
- 검정

- 개념
2) 분산분석(ANOVA)
-
분산분석 개요
- 세 개 이상의 모집단이 있을 경우에 여러 집단 사이의 평균을 비교하는 검정 방법이다.
- 귀무가설은 항상 'H0: 모든 집단 간 평균은 같다."이다.
- 분산분석의 3가지 사항
- 정규성: 각 집단의 표본들은 정규분포를 따라야한다.
- 등분산성: 각 집단은 동일한 분산을 가져야 한다.
- 독립성: 각 집단은 서로에게 영향을 주지 않는다.
- 독립변수는 범주형 데이터여야 하고, 종속변수는 연속형이어야 한다.
- "(집단 간 분산) / (집단 내 분산)"으로 계산되는 F-value가 사용된다.
- 집단 간 평균의 분산니 클수록 각 집단의 평균은 서로 멀리 떨어져 있기 때문에 집단 간 차이를 비교하기 쉬워진다.
-
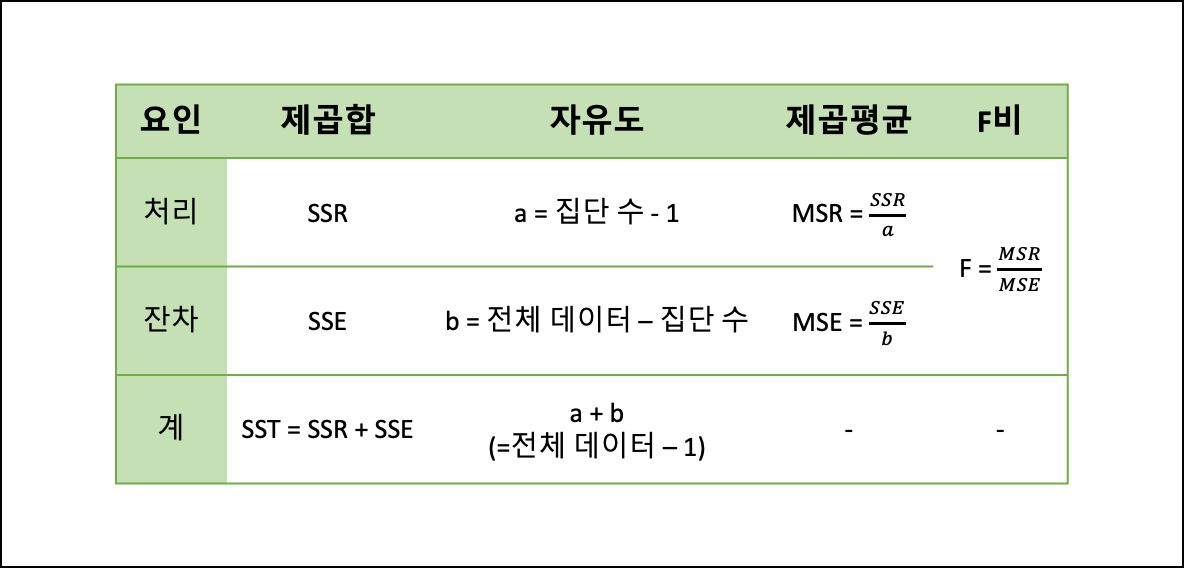
분산분석표
- SSE: 잔차들이 자신의 표본평균으로부터 벗어난 편차의 제곱
- SSR: 표본평균과 종속변수값 중 독립변수에 의해 설명된 부분과의 차이를 제곱하여 합한 값
- SST: 종속변수의 관측값과 표본의 평균의 차이(편차)를 제곱하여 합한 값
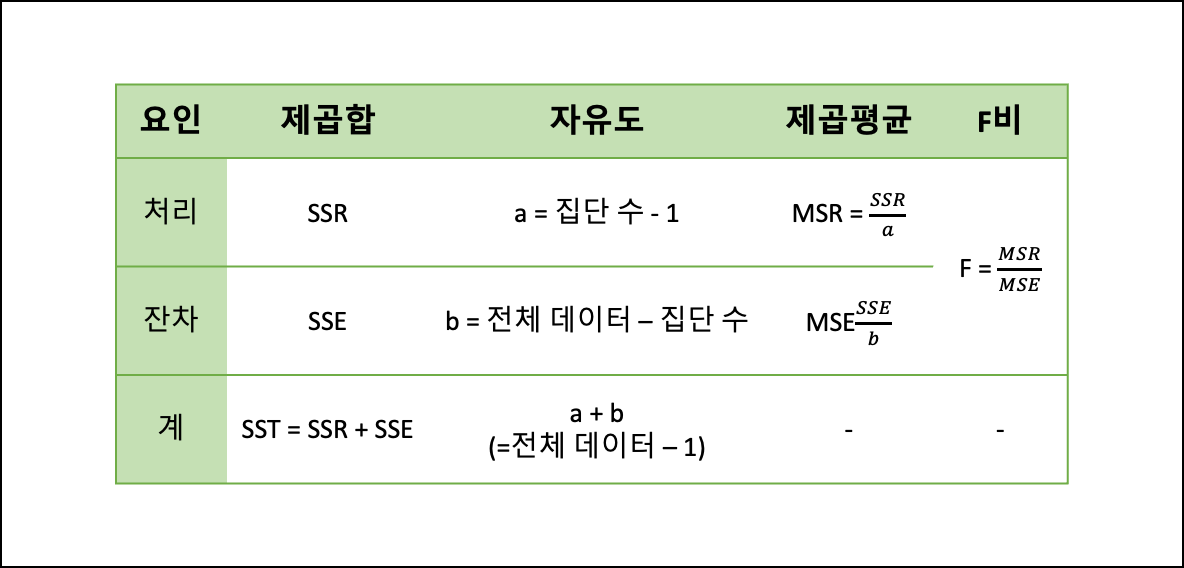
-
일원분산분석(One-Way ANOVA)
- 개념
- 셋 이상의 집단 간 평균을 비교하는 상황에서 하나의 집단에 속하는 독립변수와 종속변수 모두 한 개 일때 사용한다.
- 분산분석 수행
- 개념
-
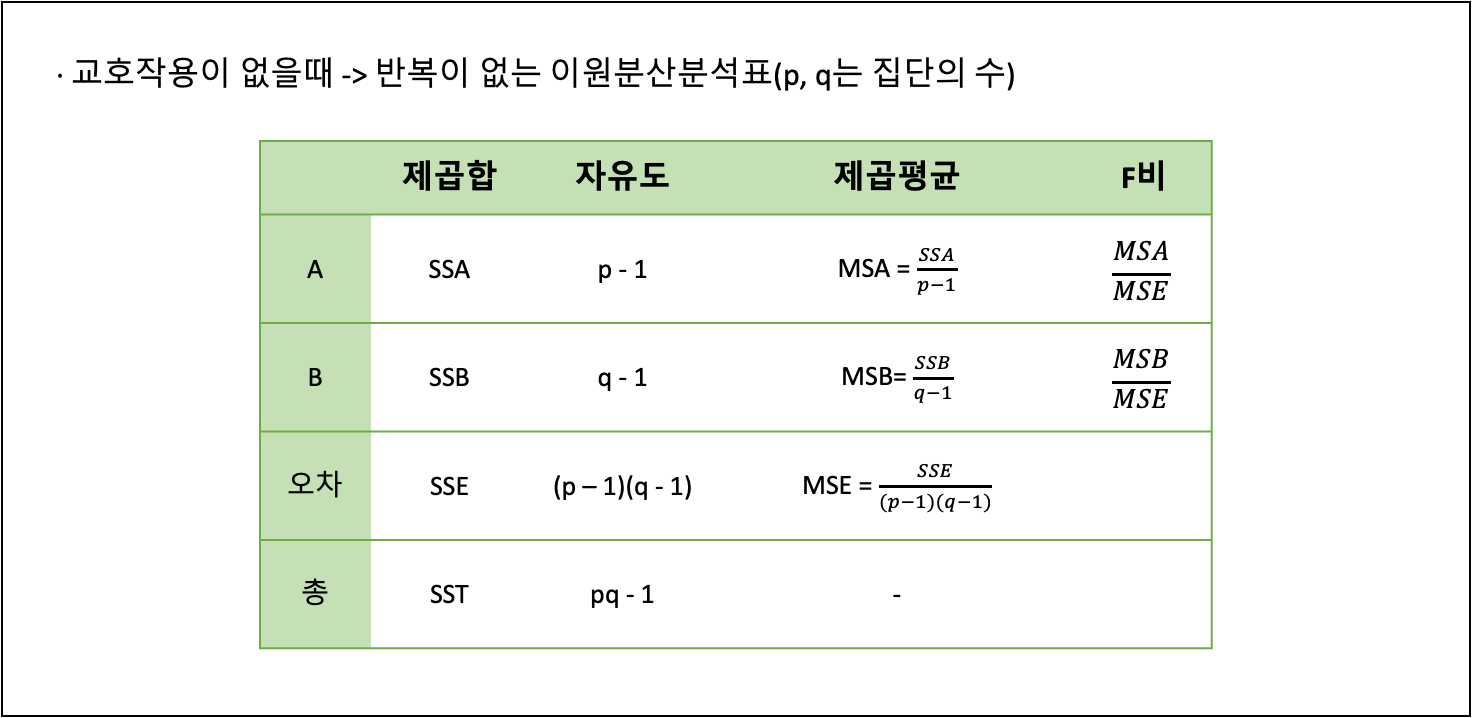
이원분산분석(Two-Way ANOVA)
- 개념
- 독립변수의 수가 두 개 이상일때 사용한다.
- 독립변수 간 교호작용이 있다고 판단될 때는 '반복이 있는 실험'을 하고, 교호작용이 없다고 판단될때는 두 독립변수가 독립인 경우에는 '반복이 없는 실험'을 한다.
- 집단 간의 평균 차이를 검증할때 종속변수가 2개 이상이라면 '다변량분산분석'을 수행하고, '다원분산분석'이라고도 한다.
- 분산분석표

- 개념
3) 교차분석
-
교차분석
- 개념
- 범주형 자료(명목,서열)간의 관계를 알아보고자 할때 사용되는 분석방법이다.
- 카이제곱(𝜒2) 검정통계량을 이용한다.
- 적합도 검정, 독립성 검정, 동질성 검정에 사용된다.
- 교차분석표
- 두 범주형 변수를 교차하여 데이터의 빈도를 표 형태로 나타낸 것이다.
- 개념
-
적합도 검정
- 개념
- 실험결과 얻어진 관측값이 예상값과 일치하는지 여부를 검정하는 방법이다.
- 실험 데이터를 '관측도수', 예측값을 '기대도수'라고 부른다.
- 실험결과 관측도수가 기대도수와 일치하면 실제 분포와 예측 분포 간에는 차이가 없다고 볼 수 있다.
- 개념
-
독립성 검정
- 개념
- 모집단이 두 개의 변수에 의해 범주화됐을 때 그 두 변수들 사이의 관계가 독립적인지 아닌지 검정하는 것을 의미한다.
- 변수들 사이의 관계가 독립적이라면 변수들 사이에 유의한 관계가 없다고 판단하며, 만약 독립적이지 않다면 유의한 관계가 있다고 판단한다.
- 개념
-
동질성 검정
- 개념
- 관측값들이 정해진 범주 내에서 서로 비슷하게 나타나고 있는지를 검정하는 것이다.
- 두 집단의 분포가 동일한 모집단에 추출된 것인지를 검정한다. 즉, 부모집단별로 요인에 대한 차이가 있는지 검정하는 것이 동질성 검정이다.
- 개념
4) 상관분석
- 상관분석
- 개념
- 두 변수 간의 선형적 관계가 존재하는지 알아보는 분석 방법으로, 상관계수를 활용한다.
- 상관계수는 -1과 +1 사이의 값을 갖는데, +1에 가까우면 강한 양의 상관관계가, -1에 가까우면 강한 음의 상관관계가 있다고 본다.
- 상관분석 귀무가설
- 상관분석의 귀무가설은 "H0: 𝛾𝑥𝑦 = 0(두 변수는 아무 상관관계가 없다.)"이다.
- 개념
- 상관 분석의 종류
- 피어슨 상관분석(선형적 상관관계)
- 두 변수가 모두 정규분포를 따른다는 가정이 필요하다.
- 스피어만 상관분석(비선형적 상관관계)
- 측정된 두 변수들이 서열척도일 때 사용하며, 관측값의 순위에 대하여 상관계수를 계산하는 방법이다.
- 피어슨 상관분석(선형적 상관관계)
3. 회귀분석
1) 회귀분석 개요
-
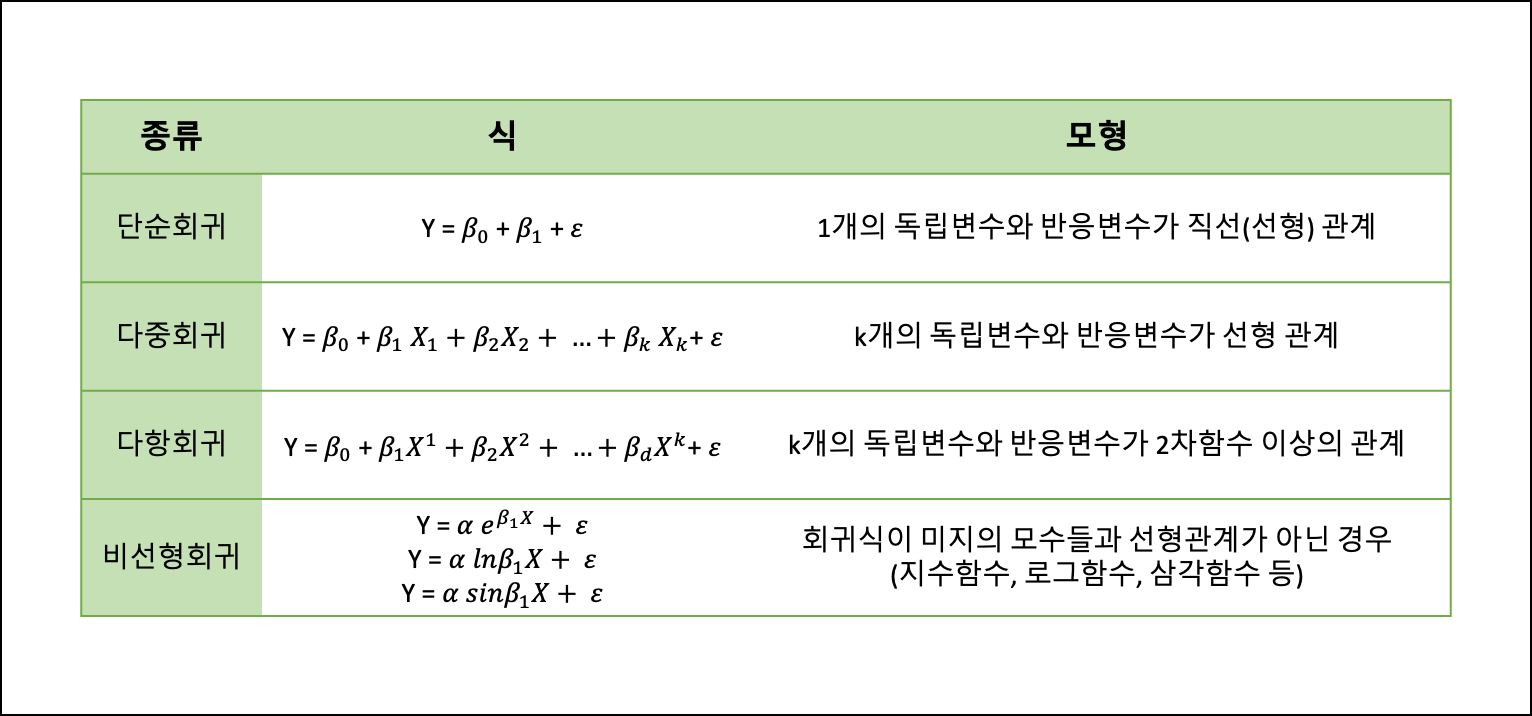
회귀분석 개념
- 회귀분석
- 하나 이상의 독립변수들(x1,x2, ... , xn)이 종속변수(y)에 얼마나 영향을 미치는지 추정하는 통계기법이다.
- 독립변수를 원인변수(또는 설명변수), 종속변수를 결과변수(또는 반응변수)
- 독립변수가 하나이면 단순선형회귀분석, 2개 이상이면 다중선형회귀분석으로 분석할 수 있다.
- 회귀분석의 종류
- 회귀분석
-
회귀분석의 가정
- 선형성
- 독립변수와 종속변수가 선형적이어야 한다.
- 예외로 2차함수 회귀선을 갖는 다항회귀분석의 경우에는 선형성을 갖지 않아도 된다.
- 독립성
- 잔차와 독립변수의 값이 서로 독립이어야 한다.
- 독립변수가 여러 개인 다중회귀분석의 경우에는 독립변수들 간에 상관성이 없이 독립이어야 한다.
- 다중공선성: 독립변수들 간에 상관선이 존재하는 경우(이를 제거하고 회귀분석을 수행해야한다.)
- 등분산성
- 분산이 같다는 의미로 잔차들이 고르게 분포하고 있다는 의미이다.
- 정규성
- 잔차항이 정규분포 형태를 띠는 것을 정규성을 만족한다고 한다.
- 선형성
-
오차와 잔차
- 오차: 모집단의 데이터를 활용하여 회귀식을 구한 경우 예측값과 실제값의 차이
- 잔차: 표본집단에 의해 추정된 회귀식의 예측값과 실제값의 차이
2) 단순회귀분석
- 단순선형회귀분석
- 개념
- 독립변수와 종속변수가 1개씩일 때 둘 사이의 인과관계를 분석하는 것
- 최소제곱법으로 회귀계수 추정
- 실제 관측치와 추세선에 의해 예측된 점 사이의 거리, 즉 오차를 제곱해 더한 값을 최소화하는 것이다.
- 개념
- 회귀분석모형의 적합성
- 회귀분석의 분산분석표
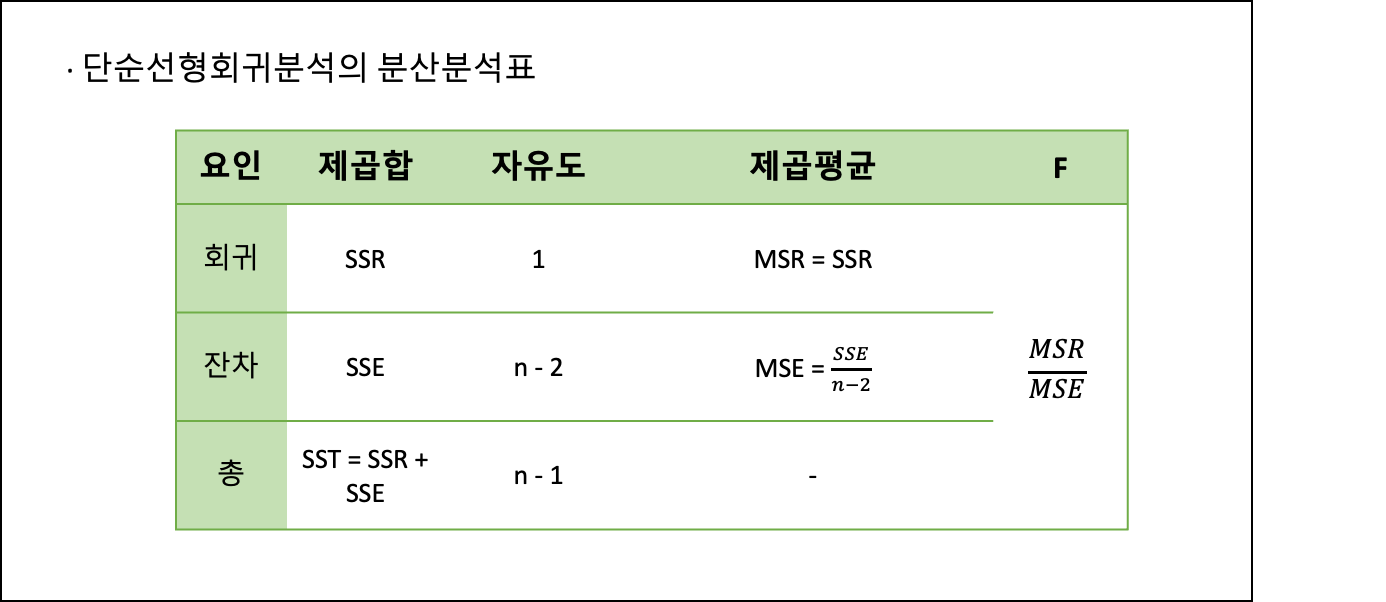
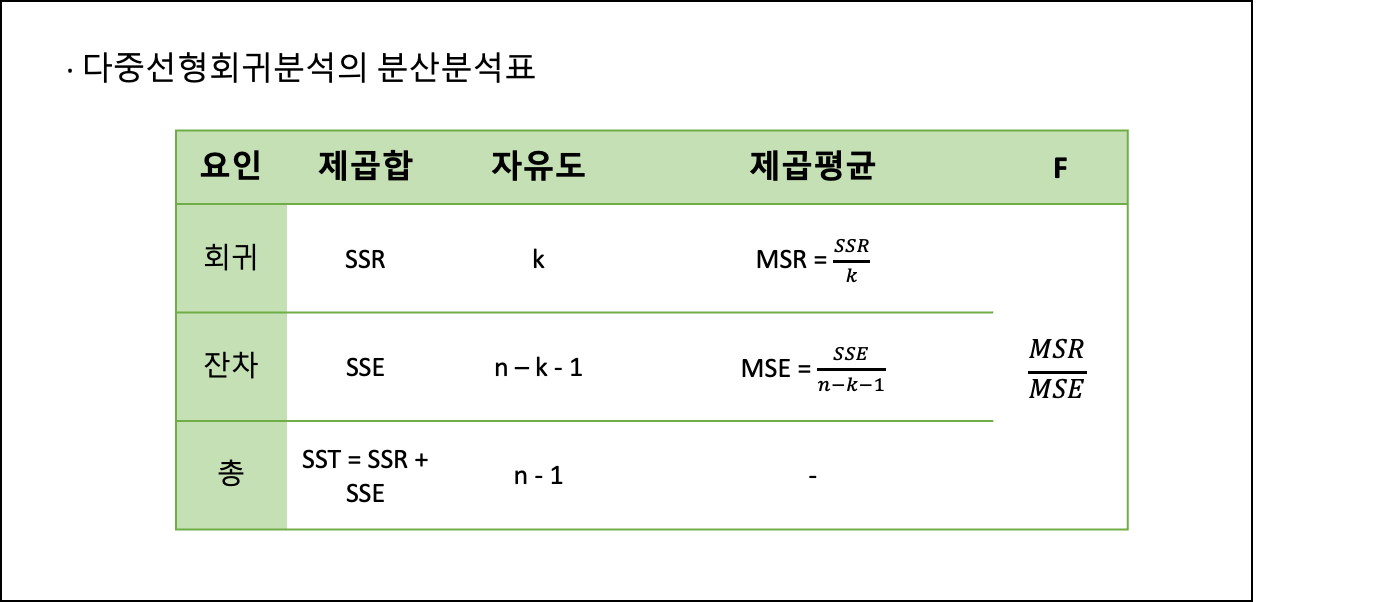
- 회귀모형의 통계적 유의성 검증
- 회귀모형의 통계적 유의성은 F-검정을 통해 확인한다.
- F-검정은 분산의 차이를 확인할때 사용되는데, 이 분산의 차이가 크다는 것은 회귀모형에서 회귀계수가 크다는 의미를 갖는다.
- F값이 크다는 말은 회귀계수가 크고 가파르다는 말과 같으니 변수 간에 유의미한 인과관계가 존재한다고 볼 수 있는다는 것이다.
- 회귀계수의 유의성 검증
- 회귀계수의 유의성은 t-검정을 통해 확인할 수 있다.
- t-통계량이 크면 회귀계수도 커지고, 회귀계수가 크므로 유의미한 인과관계가 검증이 되는 것이다.
- 모형의 설명력
- 회귀모형의 설명력이 좋다는 의미는 데이터들의 분포가 회귀선에 밀접하게 분포하고 있다는 의미이다.
- 결정계수(𝑅^2)가 1에 가깝다면 데이터들이 회귀선에 매우 밀접하게 분포한다는 것이며, 회귀모형에 예측력이 높다는 말과 같다.
- 회귀분석의 분산분석표
3) 다중선형회귀분석
- 다중선형회귀분석
- 개념
- 독립변수가 2개 이상이고 종속변수가 하나일때 사용 가능한 회귀분석으로 독립변수와 종속변수의 관계가 선형으로 표현된다.
- 개념
- 다중공선성
- 개념
- 회귀분석에서 독립변수 간에 강한 상관관계가 나타나는 문제이다.
- 다중공선성이 존재하면 회귀분석의 기본 가정인 독립성에 위배된다.
- 진단방법
- 결정계수(R^2)값이 커서 회귀식의 설명력은 높지만 각 독립변수의 P-value값이 커서 개별 인자가 유의하지 않은 경우 다중공선성을 의심할 수 있다.
- 독립변수 간의 상관계수를 구한다.
- 다양한 다중공선성 문제 해결법
- 문제를 발생하는 변수를 제거한다.
- 주성분분석(PCA)을 통해 변수의 차원을 축소한다.
- '스크린 산점도(Scree plot)'를 사용해 주성분 개수를 선택한다.
- 선형판별분석(LDA)으로 차원을 축소한다.
- t-분포 확률적 임베딩(t-SNE)으로 차원ㅇ르 축소한다.
- 특이값 분해(SVD)로 차원을 축소한다.
- 개념
4) 최적 회귀방정식
- 최적 회귀방적식
- 개념
- 1개의 반응변수 y를 설명하기 위한 k개의 독립변수 후보들이 있을때 반응변수 y를 가장 잘 설명할 수 있는 회귀식을 찾는 것이 최적 회귀방정식의 목표이다.
- 변수선택법(최적의 회귀방정식 도출방법)
- 부분집합법(임베디드 기법): 모든 가능한 모델을 고려하여 가장 좋은 모델을 선정하는 방법이다.(라쏘, 릿지, 엘라스틱넷 등)
- 단계적 변수선택법: 일정한 단계를 거치면서 변수를 추가하거나 혹은 제거하는 방식으로 최적의 회귀방정식을 도출하는 방식이다.(전진선택법, 후진제거법, 단계선택법 등)
- 개념
- 변수 선택에 사용되는 성능지표
- 벌점화(페널티)방식의 AIC와 BIC
- 회귀모형은 변수의 수가 증가할수록 편향(bias)은 작아지고 분산(variance)은 커지려는 경향이 있다.
- 페널티가 적은 회귀모형이 좋은 회귀모형(설명력이 높은)이라고 할 수 있다.
- AIC(아키이케 정보 기준)
- 모델의 성능지표로서 MSE에 변수 수만큼 페널티를 주는 지표이다.
- BIC(베이즈 정보 기준)
- AIC의 단점인 표본이 커질 때 부정확한 점을 보완하여 표본이 커질수록 정확한 결과가 나타난다.
- 멜로우 Cp
- Cp값은 최소제곱법으로 사용하여 추정된 회귀모형의 적합성을 평가하는데 사용된다.
- 벌점화(페널티)방식의 AIC와 BIC
- 단계적 변수 선택법
- 전진선택법(Forward Selection)
- 설명력이 가장 높은 설명변수부터 시작해 하나씩 모형에 추가한다.
- 변수의 개수가 많을때 사용할 수 있지만 변수값이 조금만 변해도 결과에 큰 영향을 미치기 때문에 안정성이 부족한 방법이다.
- 후진제거법(Backward Elimination)
- 독립변수를 모두 포함하여 가장 적은 영향을 주는 변수부터 하나씩 제거하는 방법이다.
- 단계별 방법(Stepwise Method)
- 전진선택법과 후진제거법을 보완한 방법이다.
- 전진선택법(Forward Selection)
5) 고급 회귀분석
- 정규화 선형회귀
- 과적합과 과소적합
- 과적합(Overfitting): 과대적합이라고 하며, 모델이 학습데이터를 과하게 학습하는 것을 의미한다.(이미 학습한 데이터에 대한 성능은 높게 나오지만, 아직 학습하지 않은 테스트 데이터에 대한 성능은 낮게 나온다.)
- 과소적합(Underfitting): 모델이 너무 단순해서 학습데이터조차 제대로 예측하지 못하는 경우를 의미한다.
- 정규화 선형회귀
- 계수의 크기를 제한하는 방법이다.
- 라쏘(Lasso Regression): L1 규제라고도 하며, 가중치들의 절대값의 합을 최소화하는 것을 제약조건을 추가하는 방법이다.(일부 불필요한 가중치 파라미터를 0으로 만들어 분석에서 아예 제외시킨다.)
- 릿지(Ridge Regression): L2 규제라고도 하며, 가중치들의 제곱합을 최소화하는 것을 제약조건으로 추가하는 방법이다.(일부 가중치 파라미터를 제한하지만, 완전히 0으로 만들지는 않고 0에 가깝게 만든다.)
- 엘라스틱넷(Elastic Net): 라쏘와 릿지를 결합한 모델로 가중치의 절대값의 합과 제곱합을 동시에 제약조건으로 가지는 모형이다.
- 과적합과 과소적합
- 일반화 선형회귀(GML: Generalized Linear Regression)
- 개념
- 종속변수가 범주형 자료이거나 정규성을 만족하지 못하는 경우 종속변수를 적절하게 정의한 함수 f(x)와 독립변수를 선형 결합하여 회귀분석을 수행할 수 있도록 하는 것을 의미한다.
- 구성요소
- 확률 요소: 종속변수의 확률분포를 규정한은 성분
- 선형 예측자(체계적 성분): 종속변수의 기대값을 정의하는 독립변수들 간의 선형 결합
- 연결 함수: 확률 요소와 선형예측자를 연결하는 함수
- 종류
- 로지스틱 회귀(Logistic Regression): 종속변수가 범주형 변수인 경우로 의학연구에 많이 사용 된다.
- 포아송 회귀(Poisson Regression): 종속변수가 특정시간 동안 발생한 사건의 건수에 대한 도수 자료인 경우이면서, 종속변수가 정규분포를 따르지 않거나 등분산성을 만족하지 못하는 경우에 사용된다.
- 개념
- 더빈 왓슨(Durbin-Waston) 검정
- 오차항의 상관계
- 오차항이 상관관계를 갖는 경우는 대부분 시계열 데이터의 경우이다.
- 하나의 잔차항의 크기가 이웃하는 다른 잔차항의 크기와 서로 일정한 관련이 있다.(= 자기상관성)
- 더번 왓슨 검정
- 회귀분석에 있어서는 오차항이 서로 연관성이 없어야 한다.(오차항의 공분산은 '0')
- 회귀분석에 있어 이러한 자기상관성이 존재하는지 검정하는 방법이다.
- 오차항의 상관계
4. 다변량 분석
1) 다차원 척도법
-
다차원 척도법의 개요
- 개념
- MDS(Multidimensional Scaling)
- 객체 간의 근접성을 시각화하는 통계기법
- 데이터를 축소하는 목적으로 사용된다.
- 데이터들의 유사성 혹은 비유사성과 같은 데이터들의 정보 속성을 파악하기 위한 수단으로도 활용된다.
- 측도
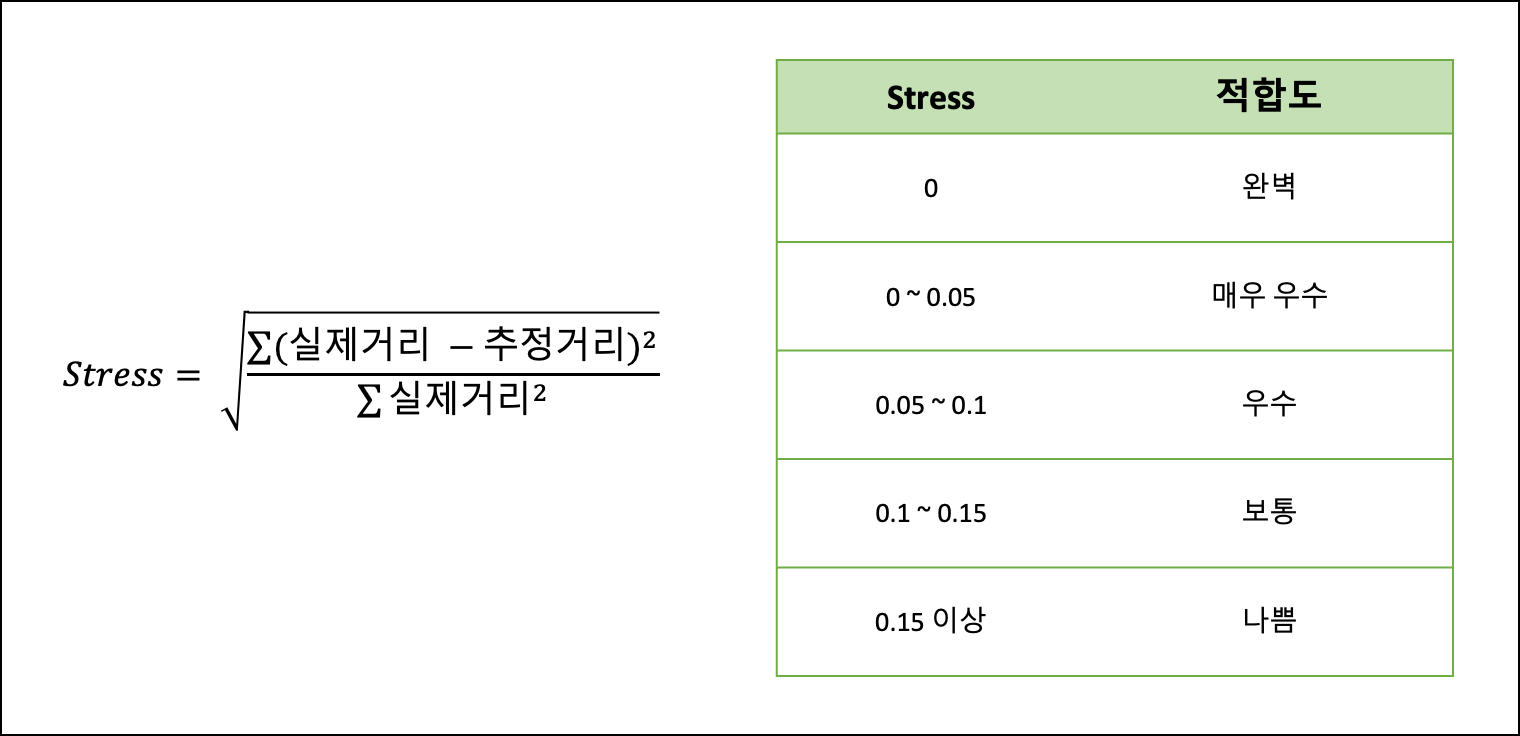
- 개념
-
다차원 척도법의 종류
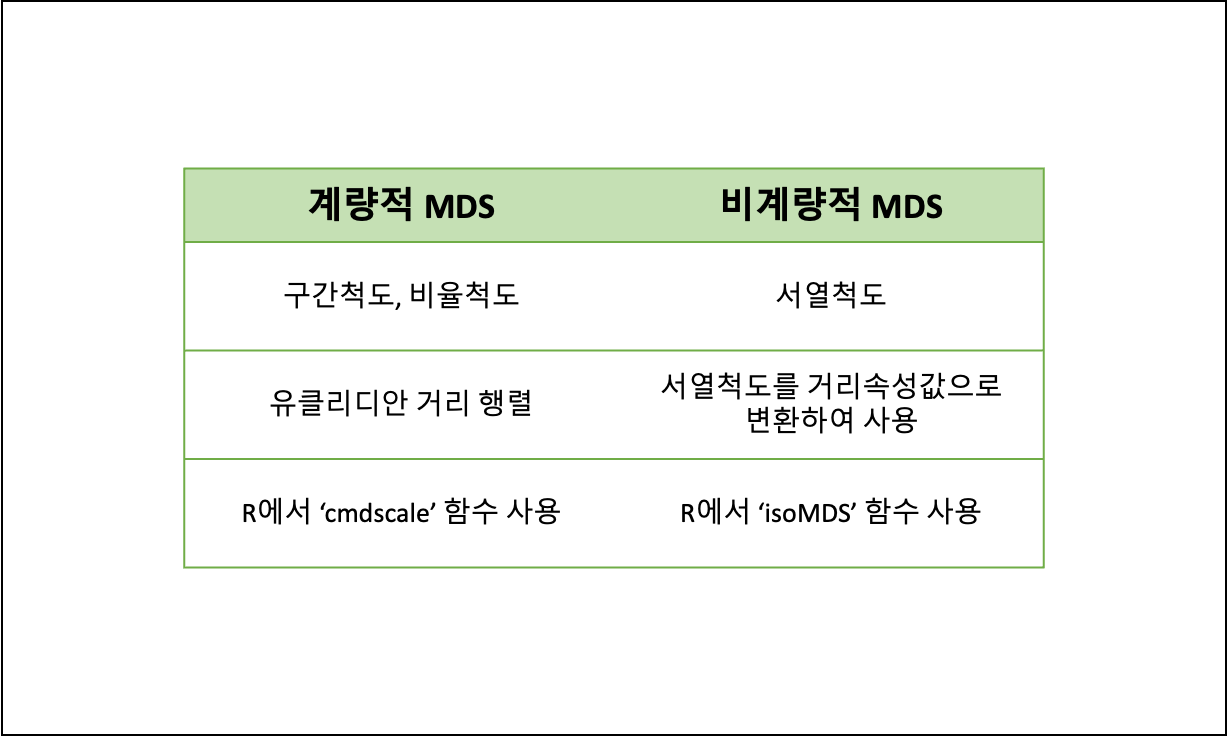
2) 주성분분석(PCA)
- 주성분분석 개요
- 개념
- PCA(Principal Componens Analysis)
- 여러 개의 변수 중 서로 상관성이 높은 변수들의 선형결합으로 새로운 변수(주성분)를 만들어 기존 변수를 요약 및 축소하는 분석 방법이다.
- 목적
- 변수를 축소하여 모형의 설명력을 높임
- 다중공선성 문제를 해결
- 군집분석 시 모형의 성능을 높일 수 있음
- 주성분분석 시 선형변환이 필요함
- 개념
5. 시계열 분석
1) 시계열 분석 개요
-
시계열 분석의 개념
- 일정시간 간격으로 기록된 자료들에 대하여 특성을 파악하고 미래를 예측하는 분석 방법이다.
- 주가, 환율, 월별 재고량, 일일 확진자 수 등이 시계열 자료에 해당한다.
-
시계열 자료의 자기상관성
- 시계열 자료는 인접한 자료들과 상호연관성을 가진다. (하나의 잔차항의 크기가 이웃하는 다른 잔차항의 크기와 서로 일정한 관련이 있다.)
- 대부분의 시계열 자료들은 자기상관성을 가지기 때문에 공분산은 '0'이 아니다.
-
시계열 자료의 정상성 조건
- 일정한 평균
- 모든 시점에 대하여 평균이 일정해야한다.
- 일정한 분산
- 모든 시점에 대하여 분산이 일정해야한다.
- 시차에만 의존하는 공분산
- 공분산은 단지 시차에만 의존하고 특정 시점에 의존하지 않는다.
- 일정한 평균
-
자기상관계수
- 자기상관계수(ACF: Autocorrelation Function)
- 시간의 흐름에 따른 자기상관관계를 나타낸다.
- 부분자기상관계수(PACF: Partial Autocorrelation Function)
- 두 시계열 확률변수 간에 다른 시점의 확률변수 영향력은 통제하고 상관관계만 보여준다.
- 자기상관계수(ACF: Autocorrelation Function)
-
시계열 분석 기법
- 이동평균법
- 일정기간별로 자료를 묶어 평균을 구하는 방법
- 지수평활법
- 최근 자료가 과거 자료보다 예측에 효과적이라는 가정하에 최근 데이터일수록 큰 가중치를 부여하고, 오래된 데이터일수록 작은 비중을 부여하는 방식을 사용해 평균을 계산한다.
- 이동평균법
2) 시계열 모형
- 자기회귀모형(AR: Autoregression)
- 이동평균모형(MA: Moving Average)
- 자기회귀누적이동평균모형(ARIMA: Autoregressive Integrated Moving Average)
- 분해시계열
- 분석 목적에 따라 특정 요인만 분리해 분석하거나 제거하는 시계열 모형이다.
- 시계열의 구성요소
- 추세요인: 장기간 일정한 방향으로 상승 또는 하락하는 경향을 보이는 요인(인구의 증가, 기술의 변화 등)
- 순환요인: 알려진 이유가 없고 주기가 일정하지 않은 변동
- 계절요인: 일정한 주기를 가지는 상하 반복의 규칙적인 변동
- 불규칙요인: 다른 요인으로 설명하지 못하는 오차에 해당하는 요인
