
📌 1장. R 기초와 데이터 마트
1. R 기초
1) R 기본 사용법
-
RStudio를 활용한 R 기본 사용법
- RStudio 기본 구성
- R 스크립트 창: 명령문을 작성하여 원하는 라인, 원하는 블록 단위로 문장을 실행할 수 있다.
- 콘솔 창: R 스크립트 창과 같이 명령문을 작성하고 실행할 수 있으며, 명령문에 의해 발생한 오류, 결과 등을 확인할 수 있다.
- 환경(Environment)과 히스토리(History): 명령문을 통해 생성된 변수, 불러온 데이터, 생성된 함수 등의 개요를 볼 수 있으며, 히스토리 창에서는 그동안 실행된 과거 명령문을 볼 수 있다.
- 기타: 현재 작업 디렉터리에 존재하는 파일, 현재 호출되어 있는 패키지, 산점도 같은 시각화 데이터, 도움말 등르 볼 수 있다.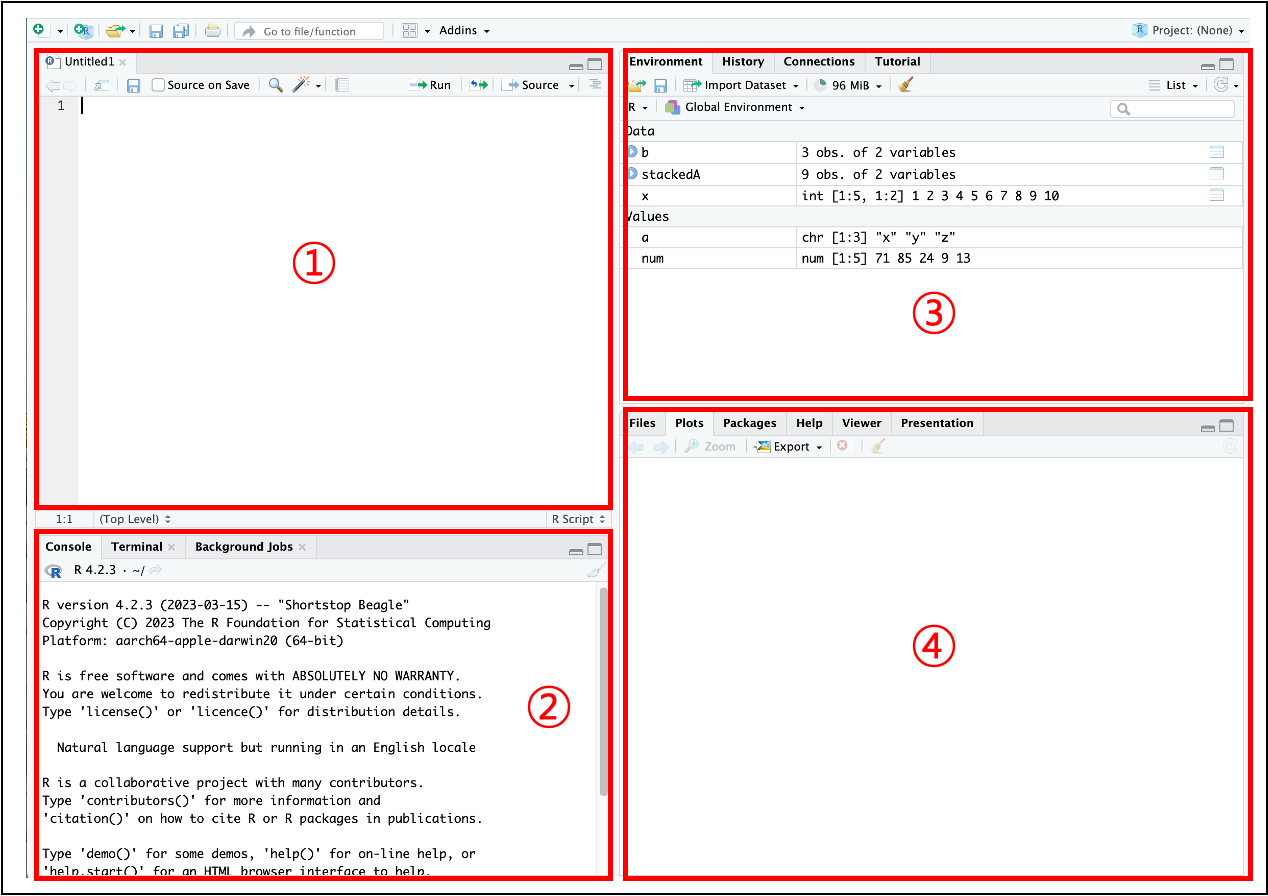
- RStudio 기본 구성
-
R의 데이터 타입
- 문자형 타입
- 문자형 타입을 character이라고 한다.
- 따옴표 혹은 쌍따옴표로 표시할 수 있다.
- 숫자형 타입
- 계산이 가능한 데이터를 숫자형 타입이라고 한다.
- numeric(숫자형), double(실수), integer(정수), complex(복소수) 등이 있다.
- Inf는 Infinite의 약자로, 무한대를 의미하며, -Inf는 음의 무한대를 의미한다.
- 논리형 타입
- logical은 논리형 타입으로 참 혹은 거짓을 의미한다.
- NaN, NA, NULL
- NaN은 'Not a Number'의 약자로 숫자가 아님에 대한 오류를 반환한다.
- NA는 공간을 차지하는 결측값을 의미한다.
- NULL은 공간을 차지하지 않는 존재하지 않는 값을 의미한다.
- 문자형 타입
2) R 기본 문법
-
연산자
- 대입 연산자

- 비교 연산자
- 할당된 값과 변수를 비교하거나 임의의 숫자, 문자 혹은 논리값을 비교할 수 있다.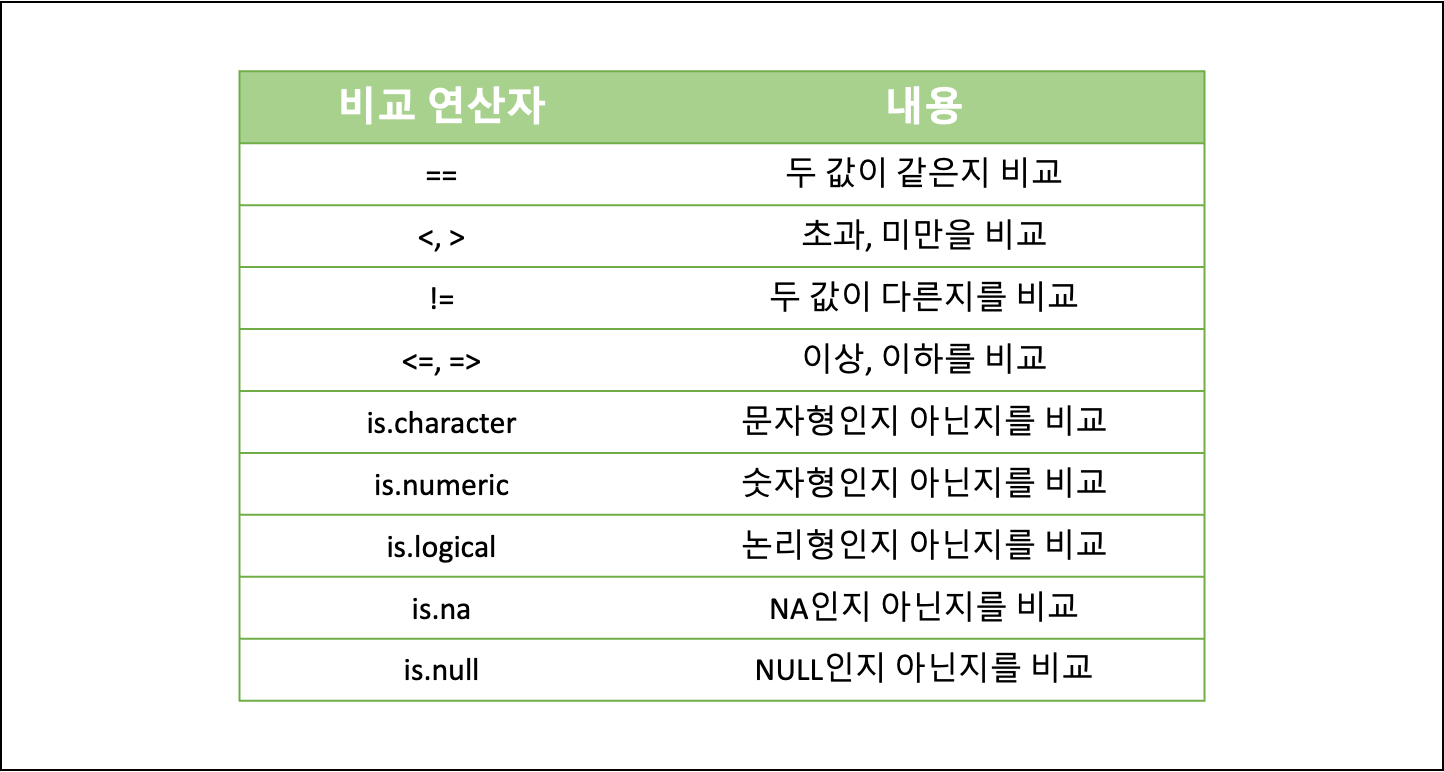
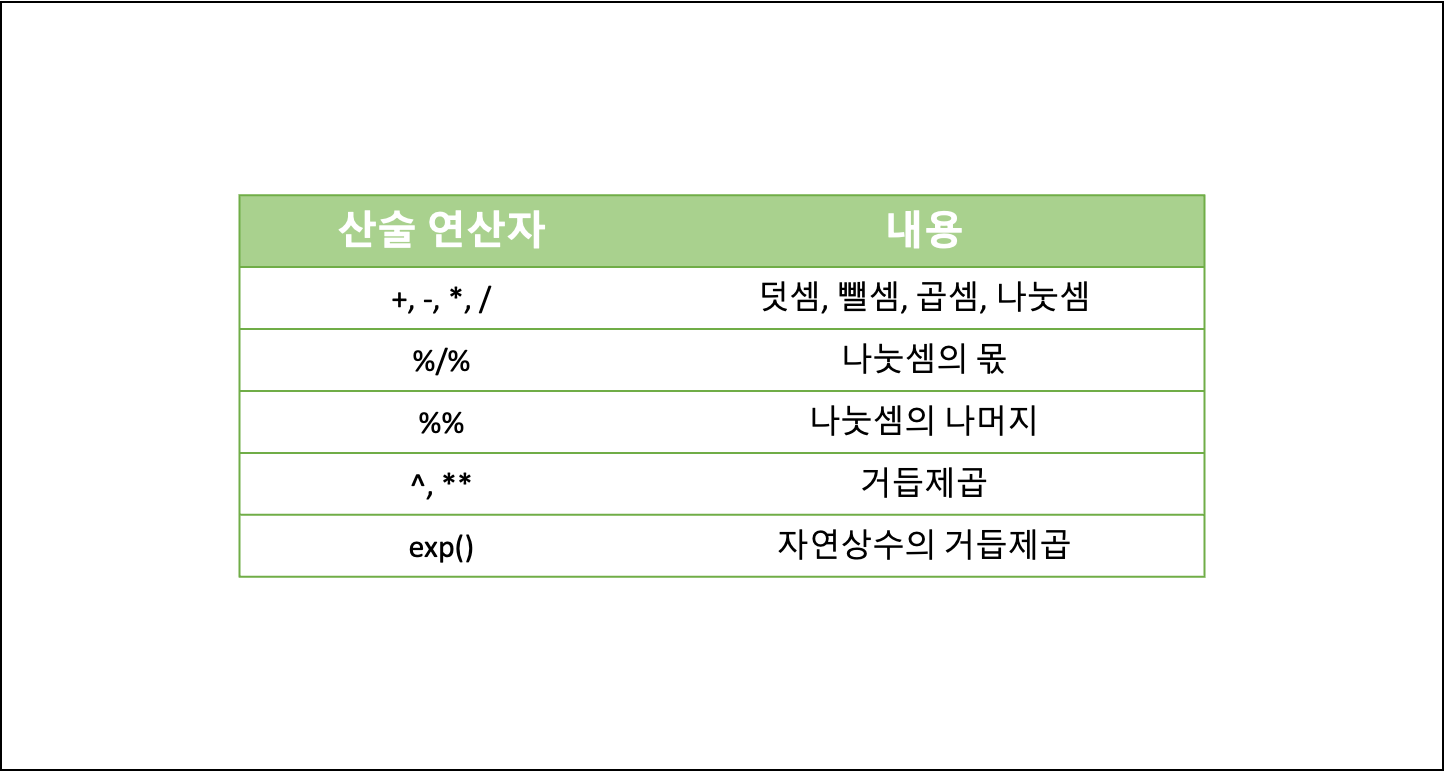
- 산술 연산자
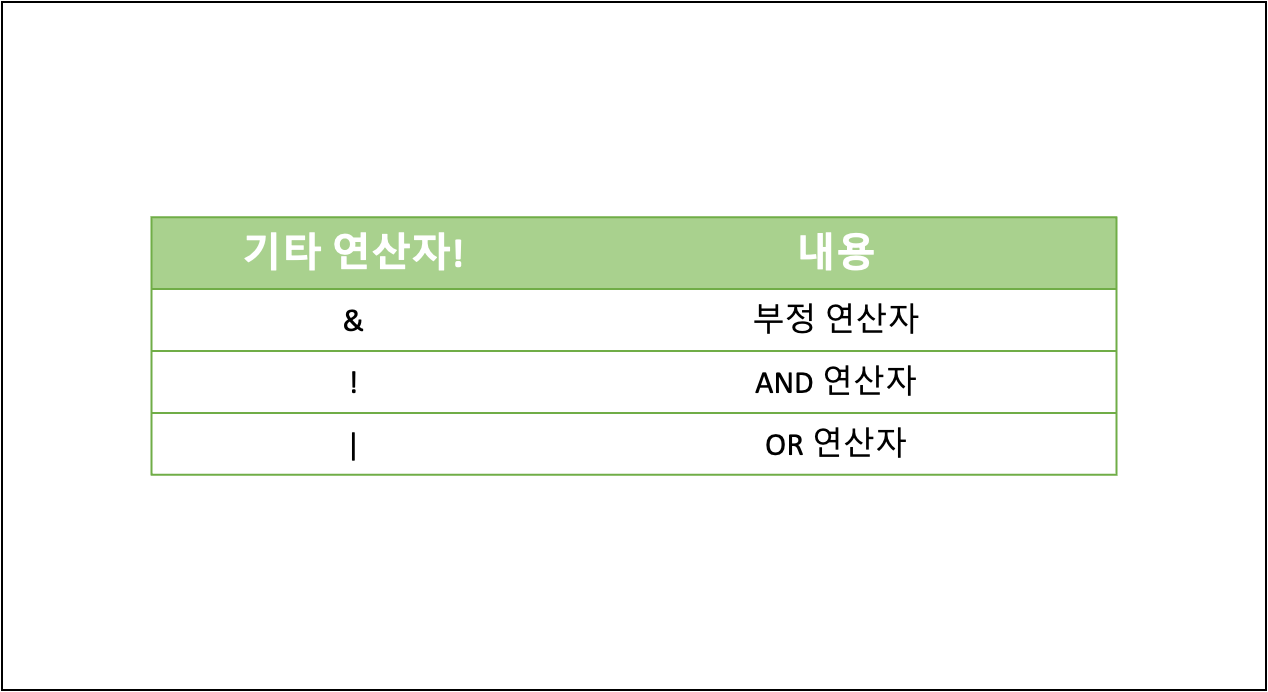
- 기타 연산자
- 대입 연산자
-
데이터 구조
- 벡터: 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조이다.

- 행렬: 2차원 구조를 가진 벡터이며, 행렬에 저장된 모든 데이터는 같은 타입이어야 한다.

- 배열: 3차원 이상의 구조를 갖는 벡터를 배열이라고 한다.

- 리스트: 데이터 타입, 데이터 구조에 상관없이 사용자가 원하는 모든 것을 저장할 수 있는 자료구조다.

- 데이터프레임: 데이터 분석을 위한 2차원 구조를 갖는 관계형 데이터 구조이다.

- 벡터: 타입이 같은 여러 데이터를 하나의 행으로 저장하는 1차원 데이터 구조이다.
-
R 내장함수
- 기본 함수
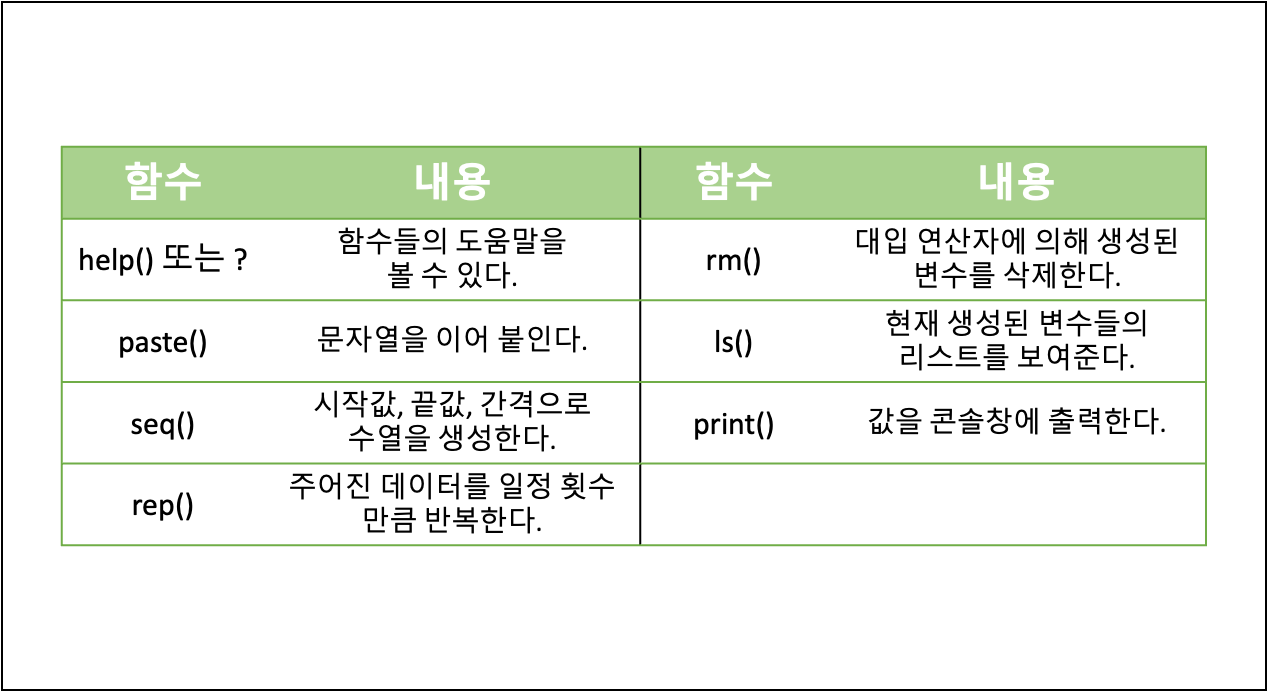
- 통계 함수
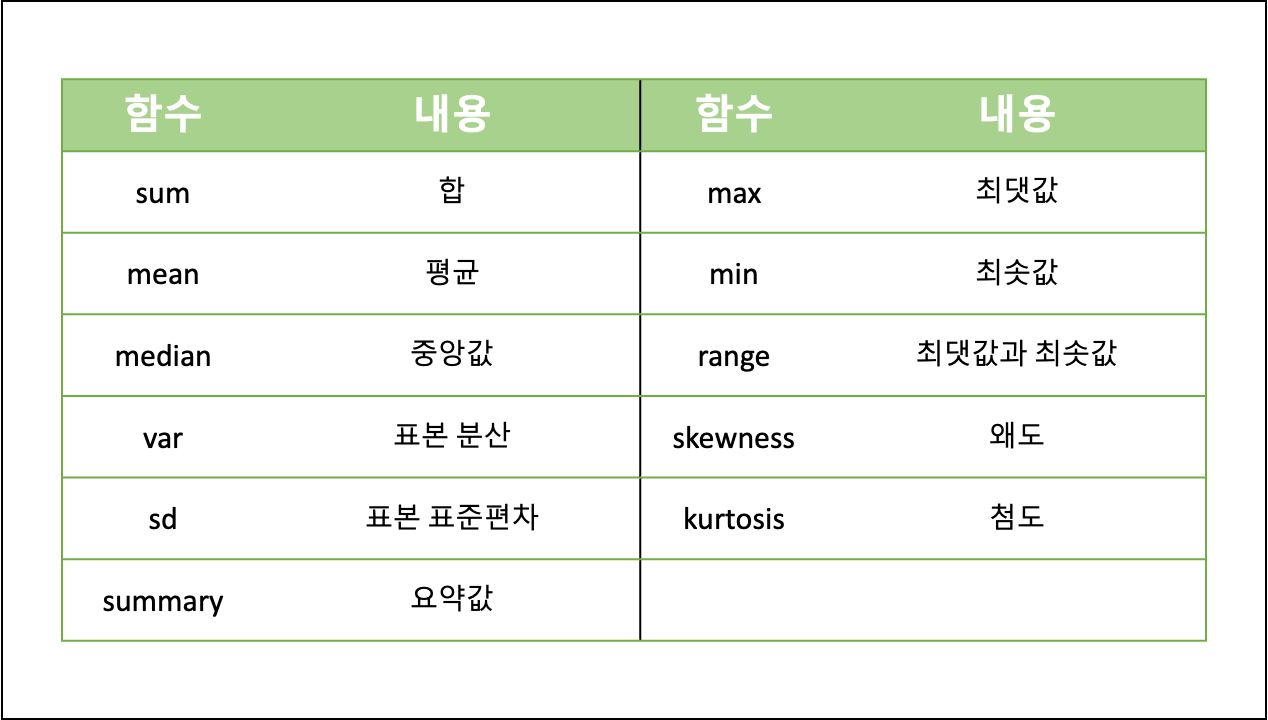
- 기본 함수
-
R 데이터 핸들링
- 데이터 이름 변경: 2차원 이상의 데이터 구조(행렬, 배열, 데이터프레임)는 행과 열의 이름을 알 수 있으며, 이름을 지정할 수 있다.
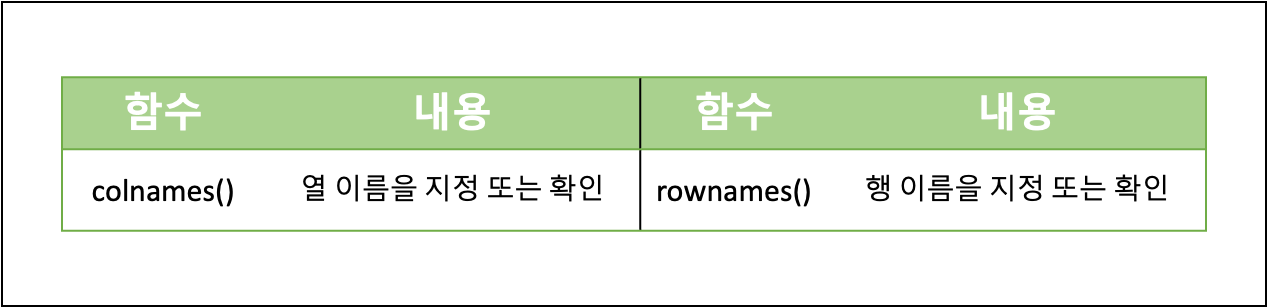
- 데이터 추출: 벡터, 행렬, 배열, 리스트, 데이터프레임 모두 인덱싱을 지원한다.

- 데이터 결합
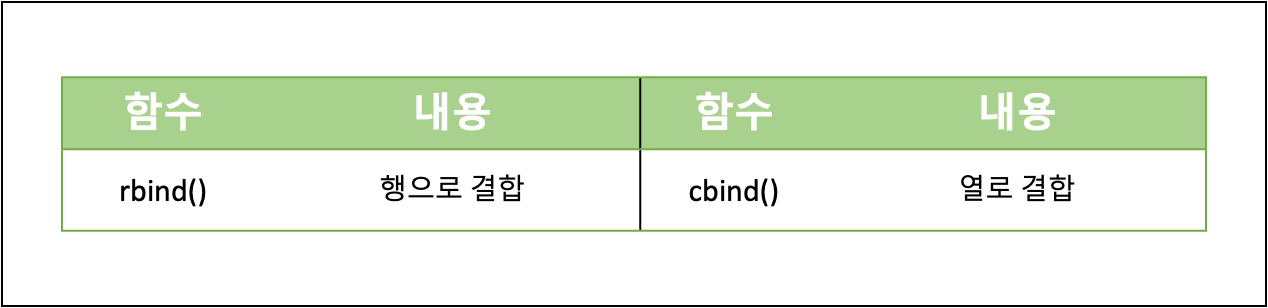
- 데이터 이름 변경: 2차원 이상의 데이터 구조(행렬, 배열, 데이터프레임)는 행과 열의 이름을 알 수 있으며, 이름을 지정할 수 있다.
-
제어문
-
반복문

-
조건문

-
사용자 정의 함수

-
-
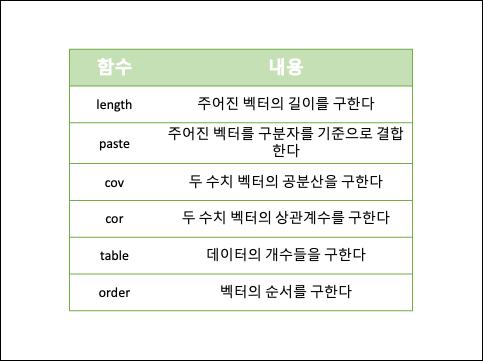
통계분석에 자주 사용되는 R함수
- 숫자 연산

- 문자 연산
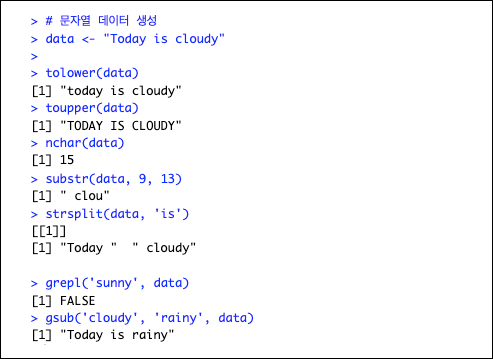
- 벡터 연산
- 행렬 연산

- 데이터 탐색

- 데이터 전처리

- 정규분포
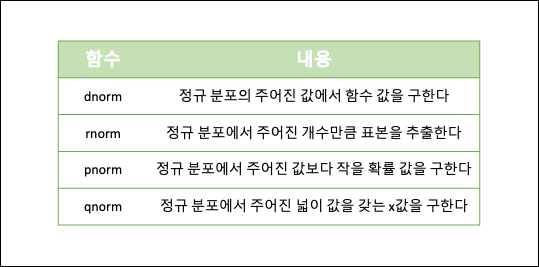
- 표본추출

- 날짜
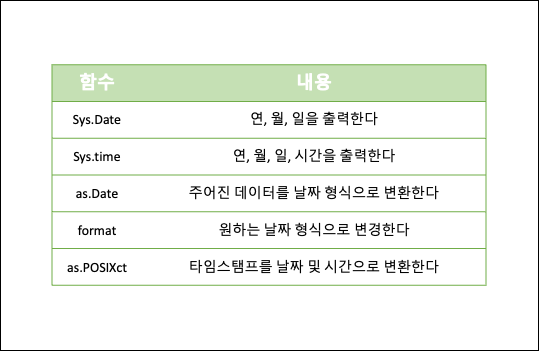
- 산점도

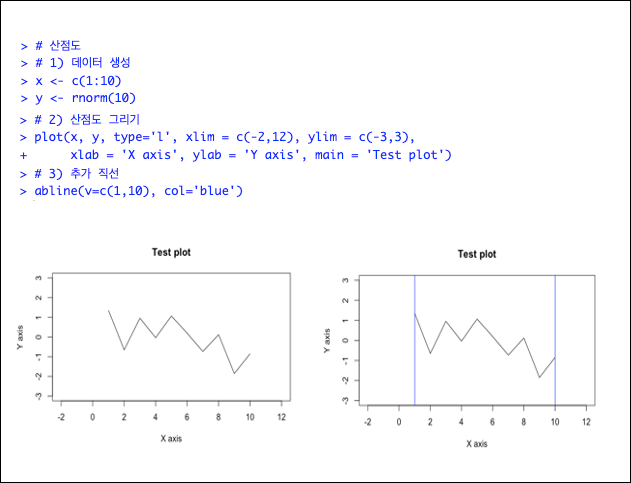
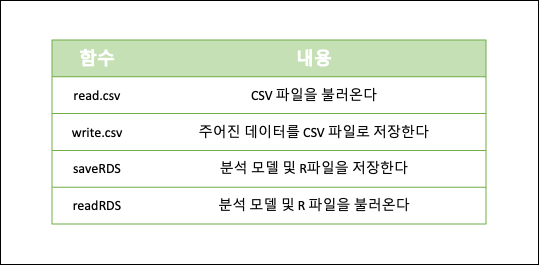
- 파일 읽기 쓰기
- 기타
- 숫자 연산
2. 데이터 마트
1) 데이터 마트의 이해
- 데이터 마트
- 데이터 웨어하우스로부터 특정 사용자가 관심을 갖는 데이터들을 주제별, 부서별로 추출하여 모은 비교적 작은 규모의 데이터 웨어하우스다.
- 데이터 전처리
- 데이터 마트에 사용자가 원하는 데이터를 수집하고 변형하여 적재했다면, 전처리 단계를 거쳐야 한다
- 빅데이터 분석 단계에 들어가기 전, 데이터 전처리(processing)에는 데이터 정제하는 과정과 분석 변수를 처리하는 과정이 포함된다.
- 데이터 정제 과정(processing): 결측값과 이상값을 처리하는 내용
- 분석 변수 처리 과정: 변수 선택, 차원 축소, 파생변수 생성, 클래스 불균형(불균형 데이터 처리) 등
2) 데이터 마트 개발을 위한 R 패키지 활용
- reshape 패키지
- melt 함수: 데이터를 특정 변수를 기준으로 녹여서 나머지 변수에 대한 세분화된 데이터를 만들 수 있다.
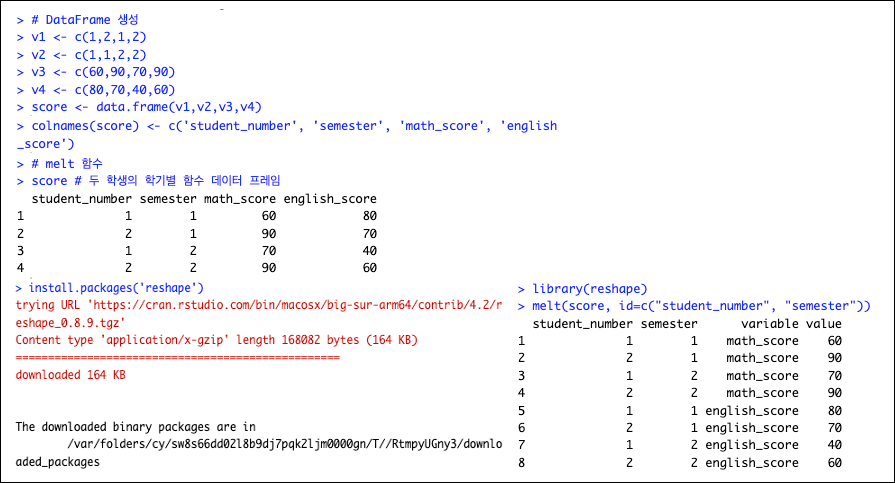
- cast 함수: melt에 의해 녹은 데이터를 요약을 위해 새롭게 가공할 수 있게 도와준다.
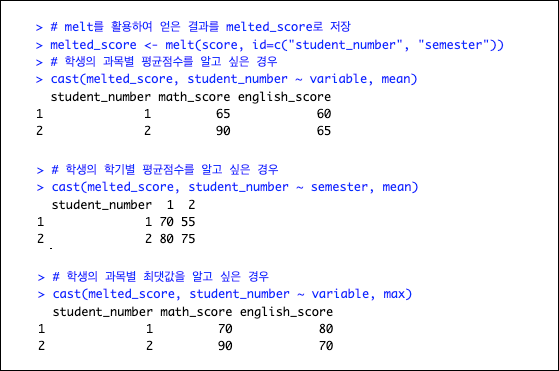
- melt 함수: 데이터를 특정 변수를 기준으로 녹여서 나머지 변수에 대한 세분화된 데이터를 만들 수 있다.
- sqldf 패키지
- 표준 SQL 문장을 활용하여 R에서 데이터프레임을 다루는 것을 가능하게 해주는 패키지로서 SAS에서 PROC SQL과 같은 역할을 한다.
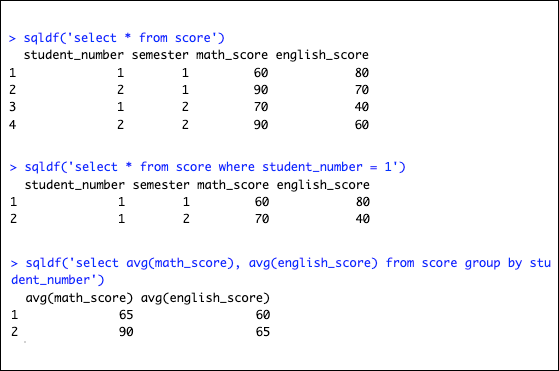
- 표준 SQL 문장을 활용하여 R에서 데이터프레임을 다루는 것을 가능하게 해주는 패키지로서 SAS에서 PROC SQL과 같은 역할을 한다.
- plyr 패키지
- apply 함수를 기반으로 데이터를 분리하고 다시 결합하는 가장 필수적인 데이터 처리 기능을 제공한다. plyr은 입력되는 데이터 구조와 출력되는 데이터 구조에 따라 여러가지 함수를 지원한다.
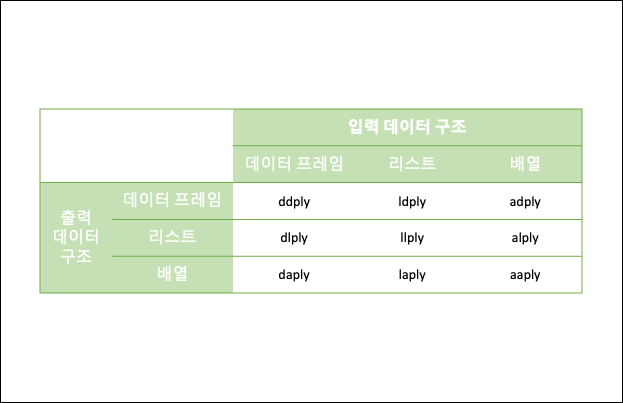
- apply 함수를 기반으로 데이터를 분리하고 다시 결합하는 가장 필수적인 데이터 처리 기능을 제공한다. plyr은 입력되는 데이터 구조와 출력되는 데이터 구조에 따라 여러가지 함수를 지원한다.
- data.table 패키지
- 데이터 테이블은 데이터프레임과 유사하지만 특정 컬럼별로 주소값을 갖는 인덱스를 생성하여 연산 및 검색을 빠르게 수행할 수 있는 데이터 구조다.
3. 데이터 탐색
1) 탐색적 데이터 분석(EDA)
- 탐색적 데이터 분석(EDA: Exploratory Data Analysis)
- 데이터를 이해하고 의미있는 관계를 찾아내기 위해 데이터의 통계값과 분포 등을 시각화하고 분석하는 것을 말한다.
2) 결측값
- 결측값
- 존재하지 않는 데이터를 의미한다.
- NA(Not Available)로 표현하지만 데이터를 수집하는 환경에 따라 null, 공백, -1 등 다양하게 표현될 수 있다.
- 결측값 처리를 위한 대표적인 패키지로 Amelia와 DMwR2 패키지가 있다.
- 결측값 대치 방법
- 단순대치법
- 결측값이 존재하는 데이터를 삭제하는 방법이다.
- 가장 쉬운 결측값 처리 방법이지만 결측값이 많은 경우 대량의 데이터 손실이 발생할 수 있다.
- 단순 대치법을 위한 함수로 complete.cases 함수가 있다.
- complete.cases는 하나의 열에 결측값이 존재하면 FALSE, 존재하지 않으면 TRUE를 반환다.
- 평균 대치법
- 관측 또는 실험으로 얻은 데이터를 대표할 수 있는 평균 혹은 중앙값으로 결측값을 대치하여 불완전한 자료를 완전한 자료로 만드는 방법이다.
- 비조건부 평균 대치법은 데이터의 평균값으로 결측값을 대치하고, 평균 대치법은 실제 값들을 분석하여 회귀분석을 활용하는 대치 방법이다.
- 단순 확률 대치법
- 평균 대치법에서 추정량 표준 오차의 과소 추정 문제를 보완하고자 고안된 방법이다.
- 대표적인 방법으로 K-Nearest Neighbor 방법이 있다.
- 다중 대치법
- 여러 번의 대치를 통해 n개의 임의 완전자료를 만드는 방법으로, 결측값 대치, 분석, 결합의 세 단계로 구성되어 있다.
- 단순대치법
3) 이상값
- 이상값
- 값이 존재하지 않는 결측값과 달리 다른 데이터와 비교하였을 때 극단적으로 크거나 극단적으로 작은 값을 의미한다.
- 데이터를 입력하는 과정에서 입력자의 실수로 입력되거나 설문응답자의 악의적인 의도에 의해 입력될 수 있다.
- 이상값 판단
- ESD(Extreme Studentized Deviation)
- 평균으로부터 '표준편자 3'만큼 떨어진 값들을 이상값으로 인식하는 방법이다.
- 정규분포에서 99.7%의 자료들을 '표준편차 3'안에 위치하므로 전체 데이터의 약 0.3퍼센트를 이상값으로 구분한다.
- 사분위수
- 사분위수를 이용하여 25%에 해당하는 값(Q1)과 75%에 해당하는 값(Q3)을 활용하여 이상치를 판단하여 방법이다.
- IQR(사분범위: Interquartile Range)이란 사분위의 정상 범위인 Q1과 Q3 사이를 의미한다.
- 일반적으로 사분범위에서 1.5분위수를 벗어나는 경우 이상치로 판단한다.
- ESD(Extreme Studentized Deviation)
