(시리즈2) 쿠버네티스 클러스터에서 작업 유형 기반 오토스케일링 기준 선택과 성능 분석 (3) - Prometheus, Grafana, Metric-Server 를 이용해 모니터링 및 매트릭 수집 환경 구축
지난 글에서 실제 어플리케이션을 만들고, 어플리케이션을 도커 이미지로 만들고, 마지막으로 쿠버네티스 Deployment로 해당 어플리케이션을 배포해 보았습니다. 남은 준비물을 살펴보겠습니다.
실험에 필요한 준비물들
-
쿠버네티스 클러스터 -
실험할 어플리케이션과 도커 이미지 -
쿠버네티스 클러스터를 모니터링하기 위한 Prometheus + Grafana 환경
-
HPA가 오토스케일링 메트릭을 받아오기 위한 metrics-server와 Prometheus adapter
-
실험 시나리오에 따라 요청을 보낼 웹 서버 요청 툴
쿠버네티스 클러스터와 어플리케이션, 이미지를 구성 완료한 상황입니다. 이번 시간에는 쿠버네티스 클러스터에 prometheus + grafana 로 모니터링 환경을 구축하고, HPA를 이용하기 위해 관련 메트릭을 가져올 metric-server, prometheus adapter를 설치하겠습니다.
이번 글의 프로메테우스 구축 개념은 stefanprodan 의 prometheus 구축 설명 글을 통해 잡았으며, 그림과 글의 일부는 위 글을 번역/인용했습니다. 실제로 본 글과 같은 시스템을 구축하시려는 분은 밑의 yaml 코드를 하나하나 적용할 필요 없이, 위 글에서 정리해놓은 폴더별로
kubectl apply를 하시는 걸 권장드립니다.

시스템 구조 - recap
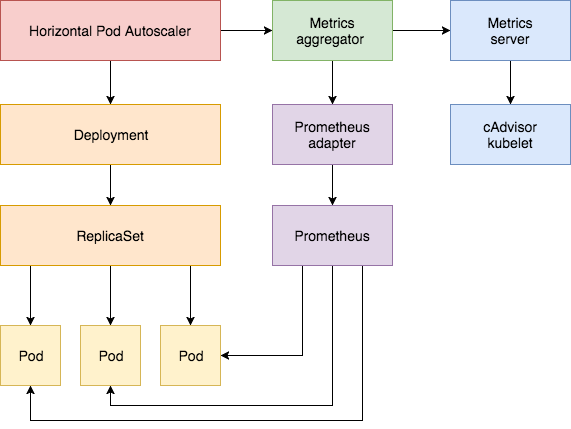
쿠버네티스에서 HPA 기능은 처음에 1.1버전에 소개되었습니다. 처음에는 CPU만 오토스케일링 기준으로 삼았으나, 후에는 메모리 사용량 또한 오토스케일링 기준으로 설정이 가능하게 되었습니다. 1.7버전부터는 'metrics aggregator'라는 모듈이 등장했는데, 이 모듈을 통해 써드파티 어플리케이션들이 그들의 API를 등록함으로서 쿠버네티스의 API를 확장하는 것이 가능하도록 되었습니다. 이것을 'Custom Metrics API' 라고 부르며, 이것을 통해서 프로메테우스 같은 모니터링 시스템이 자신의 메트릭들을 HPA 컨트롤러에게 노출시킬 수 있습니다.
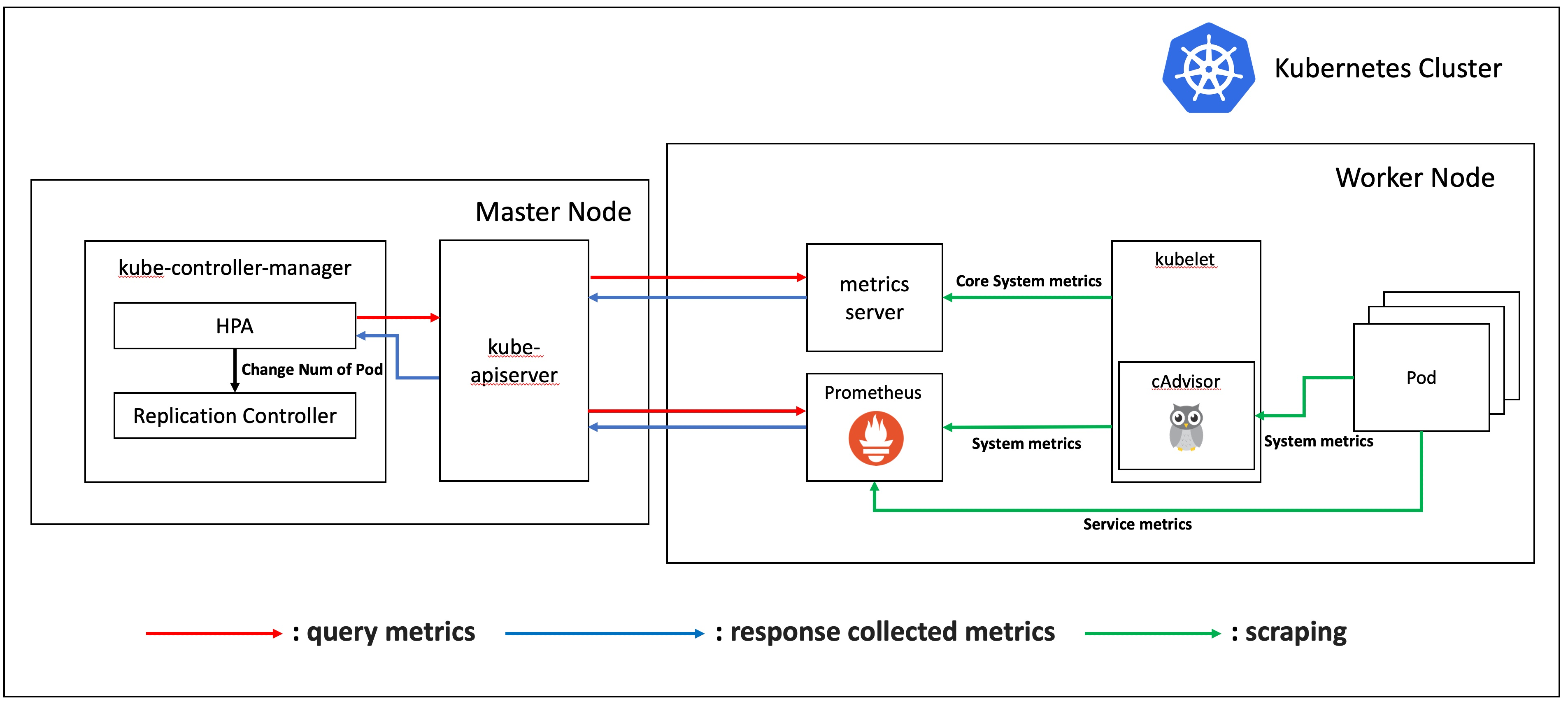
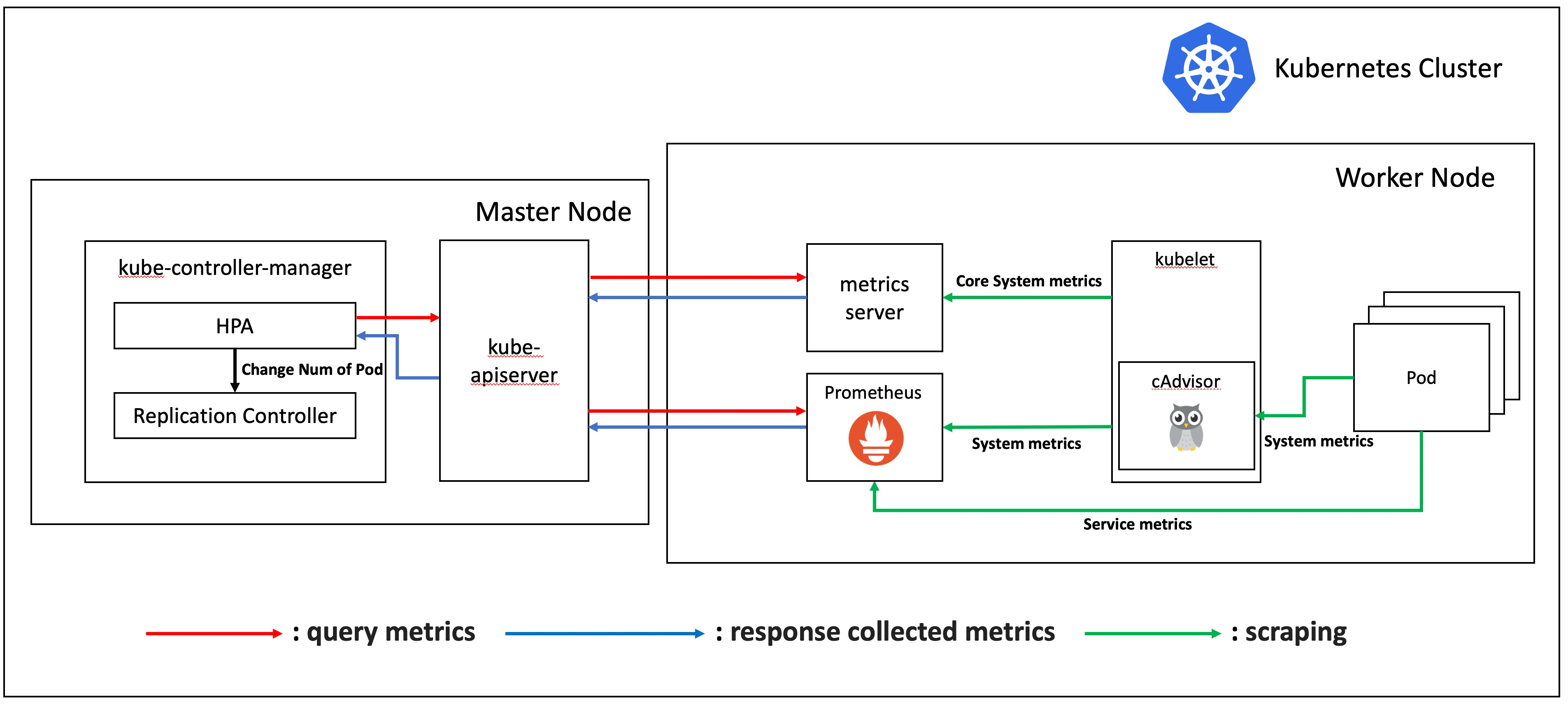
HPA는 주기적으로 컨트롤 루프를 돌며 코어 메트릭과 커스텀 메트릭을 질의합니다.
core metric 수집을 위한 metrics-server 설치
개념
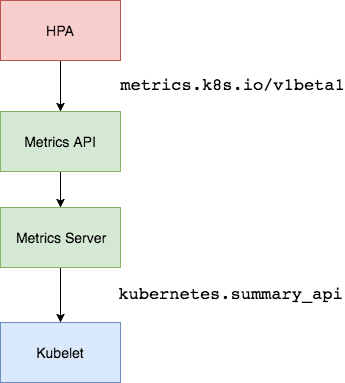
쿠버네티스의 metrics-server는 클러스터 전체 노드, 팟들의 CPU, memory 사용량를 수집합니다. 위 정보들은 kubernetes.summary_api 를 통해 kubelet 안의 cAdvisor 에서 metrics-server 로 수집됩니다. 그 후 metrics.k8s.io/v1beta1 를 통해 HPA 까지 전달됩니다.
설치
Namespace 생성
kubectl create ns monitoringClusterRole
ClusterRole 은 kube-state-metrics 가 api-server 에 접속할 수 있는 권한을 부여합니다.
# kube-state-cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources: ["configmaps", "secrets", "nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list","watch"]
- apiGroups:
- extensions
resources: ["daemonsets", "deployments", "replicasets", "ingresses"]
verbs: ["list", "watch"]
- apiGroups:
- apps
resources: ["statefulsets", "daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups:
- batch
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups:
- autoscaling
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
- apiGroups:
- authentication.k8s.io
resources: ["tokenreviews"]
verbs: ["create"]
- apiGroups:
- authorization.k8s.io
resources: ["subjectaccessreviews"]
verbs: ["create"]
- apiGroups:
- policy
resources: ["poddisruptionbudgets"]
verbs: ["list", "watch"]
- apiGroups:
- certificates.k8s.io
resources: ["certificatesigningrequests"]
verbs: ["list", "watch"]
- apiGroups:
- storage.k8s.io
resources: ["storageclasses", "volumeattachments"]
verbs: ["list", "watch"]
- apiGroups:
- admissionregistration.k8s.io
resources: ["mutatingwebhookconfigurations", "validatingwebhookconfigurations"]
verbs: ["list", "watch"]
- apiGroups:
- networking.k8s.io
resources: ["networkpolicies"]
verbs: ["list", "watch"]ServiceAccount
ServiceAccount 는 api-server가 특정 name을 가진 컴포넌트에게 특정 namespace 권한을 주는 것이다.
# kube-state-svcaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-systemDeployment
# kube-state-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: kube-state-metrics
name: kube-state-metrics
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
containers:
- image: quay.io/coreos/kube-state-metrics:v1.8.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metricsService
# kube-state-svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: kube-state-metrics
name: kube-state-metrics
namespace: kube-system
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app: kube-state-metrics배포
kubectl apply -f kube-state-cluster-role.yaml
kubectl apply -f kube-state-deployment.yaml
kubectl apply -f kube-state-svcaccount.yaml
kubectl apply -f kube-state-svc.yaml설치결과
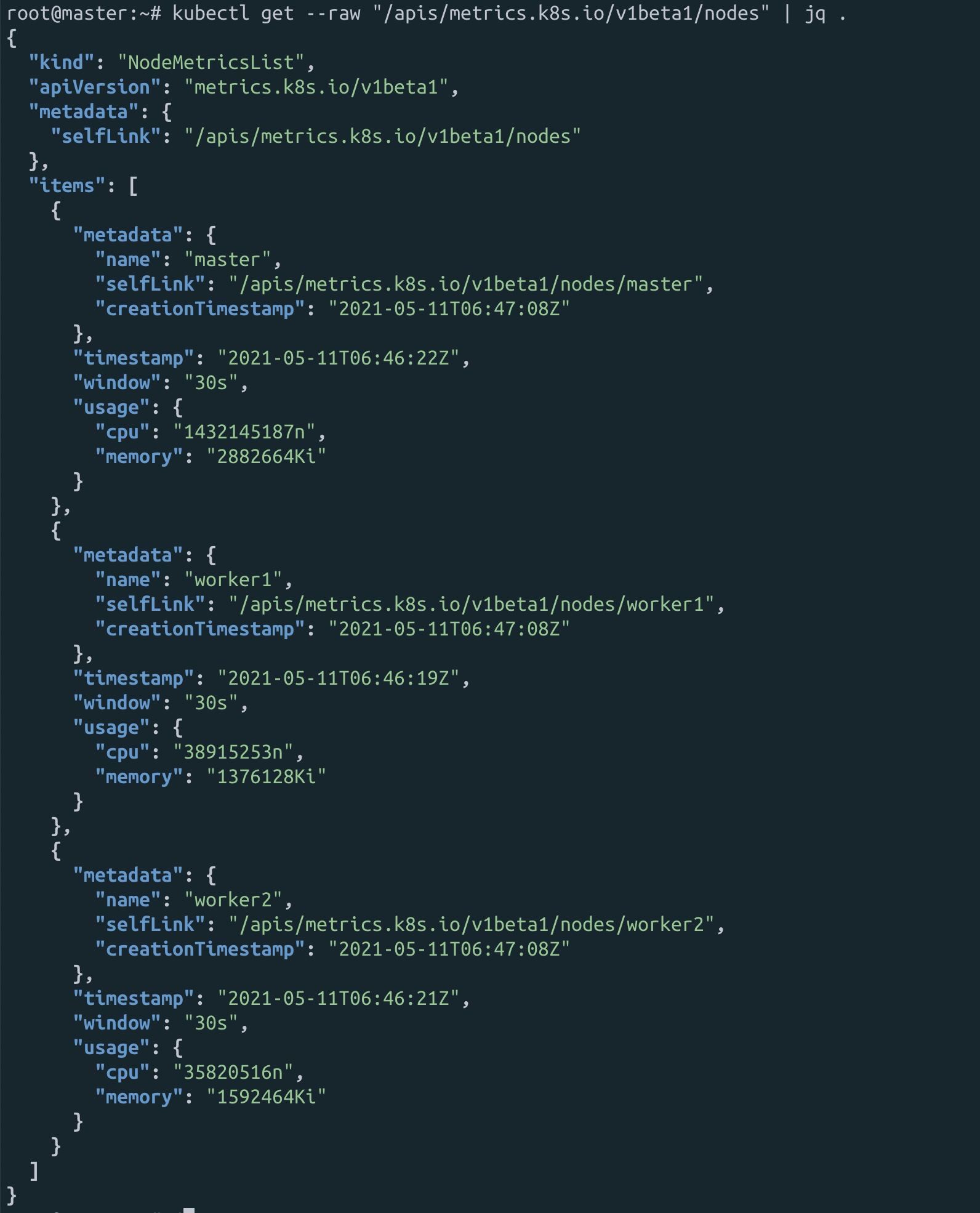
[그림] kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq . 로 수집되는 코어 매트릭
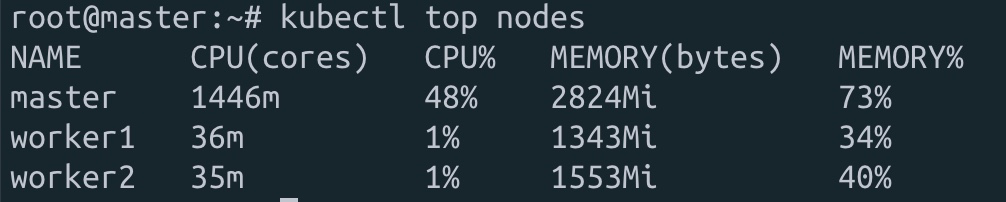
[그림] kubectl top nodes
custom metric 수집을 위한 prometheus, prometheus adapter 설치
개념
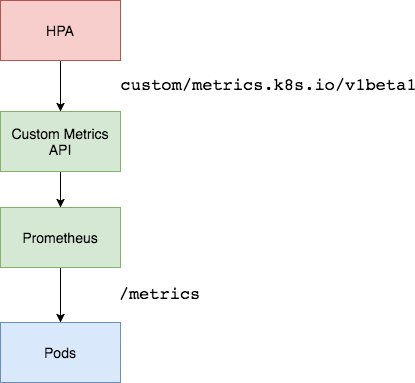
custom metric을 사용하기 위해서 우리는 두 개의 컴포넌트가 필요합니다. 하나의 컴포넌트는 어플리케이션으로부터 metric 을 수집하고 그 정보를 prometheus의 time series database에 저장하는 컴포넌트입니다. 다른 하나는 쿠버네티스의 custom metric API와 연결하는 Prometheus Adapter 입니다.
설치
ClusterRole
프로메테우스 컨테이너가 쿠버네티스 api에 접근할 수 있는 권한을 부여합니다.
프로메테우스가 클러스터의 모든 것을 볼 수 있습니다.
# prometheus-cluster-role.yaml
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
namespace: monitoring
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: monitoringConfigmap
각종 스크래핑 규칙 혹은 스크래핑 할 컴포넌트를 정의합니다.
밑 설정파일에서 scraping하는 컴포넌트는 다음과 같습니다.
- kubernetes-apiservers : api-server 정보
- kubernetes-nodes : kubelet 정보
- kubernetes-pods : pod 정보
- kube-state-metrics : 노드 자체에 대한정보(cpu, memory ...)
- kubernetes-cadvisor : 컨테이너에 관한 정보를 획득
- kubernetes-service-endpoints : Service 정보
를 5초 간격으로 scraping 합니다.
# prometheus-config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-server-conf
labels:
name: prometheus-server-conf
namespace: monitoring
data:
prometheus.rules: |-
groups:
- name: container memory alert
rules:
- alert: container memory usage rate is very high( > 55%)
expr: sum(container_memory_working_set_bytes{pod!="", name=""})/ sum (kube_node_status_allocatable_memory_bytes) * 100 > 55
for: 1m
labels:
severity: fatal
annotations:
summary: High Memory Usage on
identifier: ""
description: " Memory Usage: "
- name: container CPU alert
rules:
- alert: container CPU usage rate is very high( > 10%)
expr: sum (rate (container_cpu_usage_seconds_total{pod!=""}[1m])) / sum (machine_cpu_cores) * 100 > 10
for: 1m
labels:
severity: fatal
annotations:
summary: High Cpu Usage
prometheus.yml: |-
global:
scrape_interval: 5s
evaluation_interval: 5s
rule_files:
- /etc/prometheus/prometheus.rules
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- "alertmanager.monitoring.svc:9093"
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kube-state-metrics'
static_configs:
- targets: ['kube-state-metrics.kube-system.svc.cluster.local:8080']
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_nameDeployment
# prometheus-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: prometheus-server
template:
metadata:
labels:
app: prometheus-server
spec:
containers:
- name: prometheus
image: prom/prometheus:latest
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus/"
ports:
- containerPort: 9090
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus/
- name: prometheus-storage-volume
mountPath: /prometheus/
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420
name: prometheus-server-conf
- name: prometheus-storage-volume
emptyDir: {}Service
# prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9090'
spec:
selector:
app: prometheus-server
type: NodePort
ports:
- port: 8080
targetPort: 9090
nodePort: 30003배포
kubectl apply -f prometheus-cluster-role.yaml
kubectl apply -f prometheus-config-map.yaml
kubectl apply -f prometheus-deployment.yaml
kubectl apply -f prometheus-svc.yaml
#kubectl apply -f prometheus-node-exporter.yaml배포 후 ip:30003 로 접속해서 확인
Node-Exporter 설치
Pod로 적용한 Node Exporter는 k8s의 pod으로 생성되었기 때문에 cluster의 정보를 가져올뿐, 노드 자체의 정보를 가져오진 못 했습니다.
따라서 노드 자체에 service로 node exporter를 띄워줘야 했습니다.
코드 다운
wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0-rc.1/node_exporter-0.16.0-rc.1.linux-amd64.tar.gz # 코드 다운
tar -xzvf node_exporter-0.16.0-rc.1.linux-amd64.tar.gz # 압축 해제
mv node_exporter-0.16.0-rc.1.linux-amd64 node_exporter # 이름 변경service 생성 & 실행
cd /etc/systemd/system/
sudo vim node_exporter.service# node_exporter.service
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/home/dnclab/node_exporter/node_exporter # 위에서 다운받은 경로 적어주셔야 합니다. 마지막에 바이너리파일까지 적어주셔야 합니다.
[Install]
WantedBy=default.target# daemon 실행
systemctl daemon-reload
systemctl start node_exporter
systemctl enable node_exporter
# 실행 확인
systemctl status node_exporter
netstat -tnlp | grep 9100 # 9100 포트 잘 열려 있는지?프로메테우스 설정 변경
위에 우리가 만들었던 prometheus-config-map.yaml 파일의 scrape_configs 태그 맨 밑에 다음 설정을 추가합니다.
...
- job_name: 'node-info'
static_configs:
- targets: ['192.168:0.2:9100', '192.168:0.4:9100', '192.168:0.5:9100', '192.168:0.6:9100']이 때, target에는 node exporter 배포한 서버 ip와 포트를 적어줍니다.
마지막으로 반영을 위해 프로메테우스 deployment를 재시작 해줍니다.
kubectl rollout restart deployment prometheus-deployment -n monitoring설치결과
[그림] kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq . 로 수집되는 커스텀 메트릭 + 코어 메트릭 일부
[그림] promQL 대시보드
prometheus + grafana 설치
위 글에서 데이터를 모아주는 Prometheus를 설치 완료 했으니, 이제 마지막으로 시각화를 위한 툴 Grafana를 이용해 Prometheus가 모은 metric들을 모니터링 할 수 있습니다.
Grafana란, 시계열 매트릭 데이터를 시각화 하는데 가장 최적화된 대시보드를 제공해주는 오픈소스 툴킷입니다. Prometheus 자체도 간단한 그래프를 지원하기는 하지만, 좀 더 다양한 설정을 위해서 grafana와 함께 쓰는 것이 일반적입니다.
grafana pod, service 생성
# grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
name: grafana
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:latest
ports:
- name: grafana
containerPort: 3000
env:
- name: GF_SERVER_HTTP_PORT
value: "3000"
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
value: /
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '3000'
spec:
selector:
app: grafana
type: NodePort
ports:
- port: 3000
targetPort: 3000
nodePort: 30004배포 후 ip:30004 로 접속해서 확인
grafana - prometheus 연결
Add data source → Prometheus → URL에 prometheus nodeport 내부 ip:포트 입력해주기
kubectl get svc -n monitoringgrafana 홈페이지에서 원하는 dashboard선택하기
여기서 선택 가능합니다.
Grafana Dashboards - discover and share dashboards for Grafana.
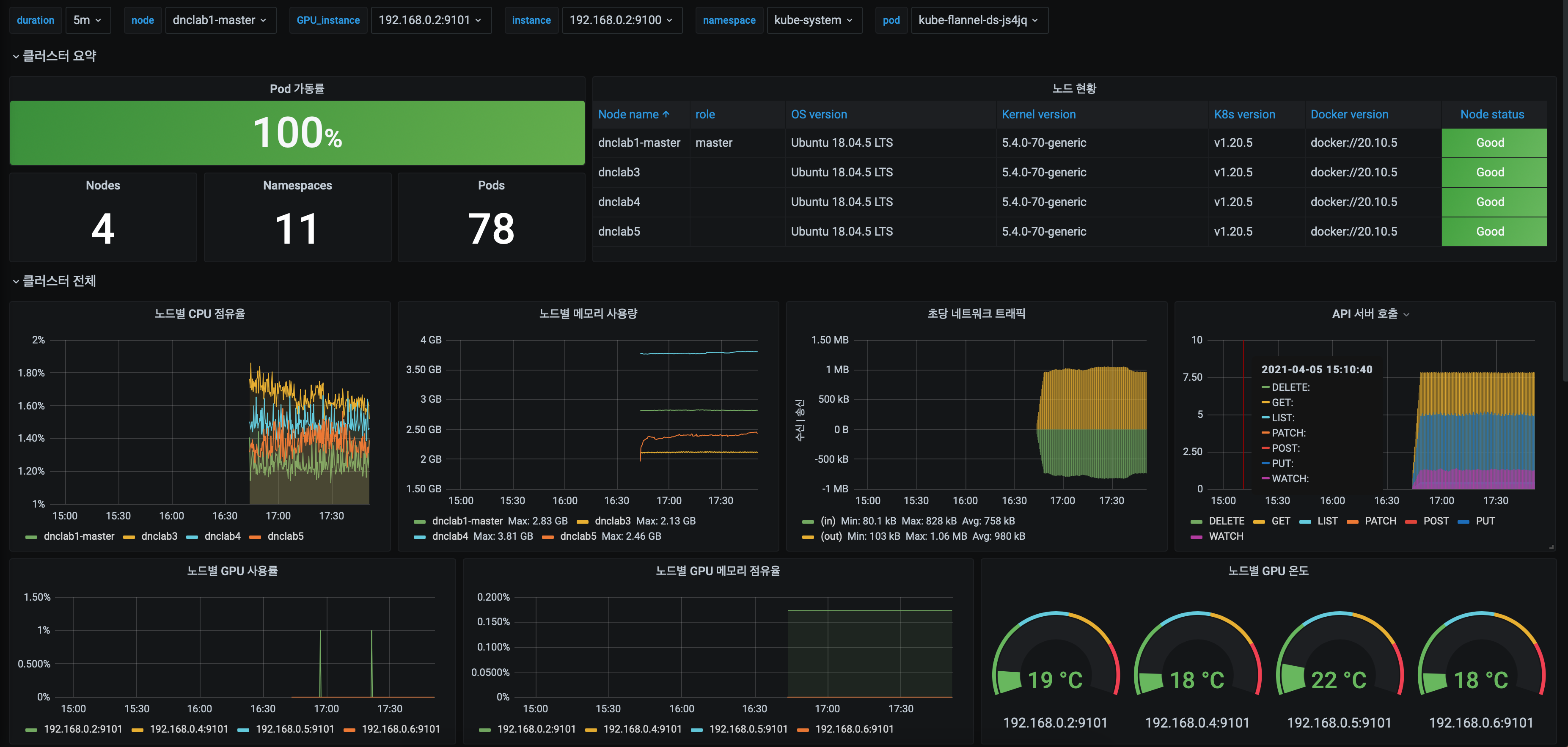
저는 다음과 같이 GPU 관련 정보까지 모니터링이 가능하도록 커스텀된(커스텀해주고 방법을 알려준 연구실 동기에게 감사...) 모니터링 시스템을 이용합니다. 원하는 메트릭을 추가하기 위해서는 약간의 PromQL 지식이 필요한데, 그리 어렵지는 않으니 검색해서 마음대로 바꿔보시기 바랍니다.
잘못된 부분이나 의견이 있으신 경우 댓글로 남겨주시면 적극 반영하겠습니다! 감사합니다.

