(시리즈2) 쿠버네티스 클러스터에서 작업 유형 기반 오토스케일링 기준 선택과 성능 분석 (2) - 어플리케이션 구성, 컨테이너 이미지 생성
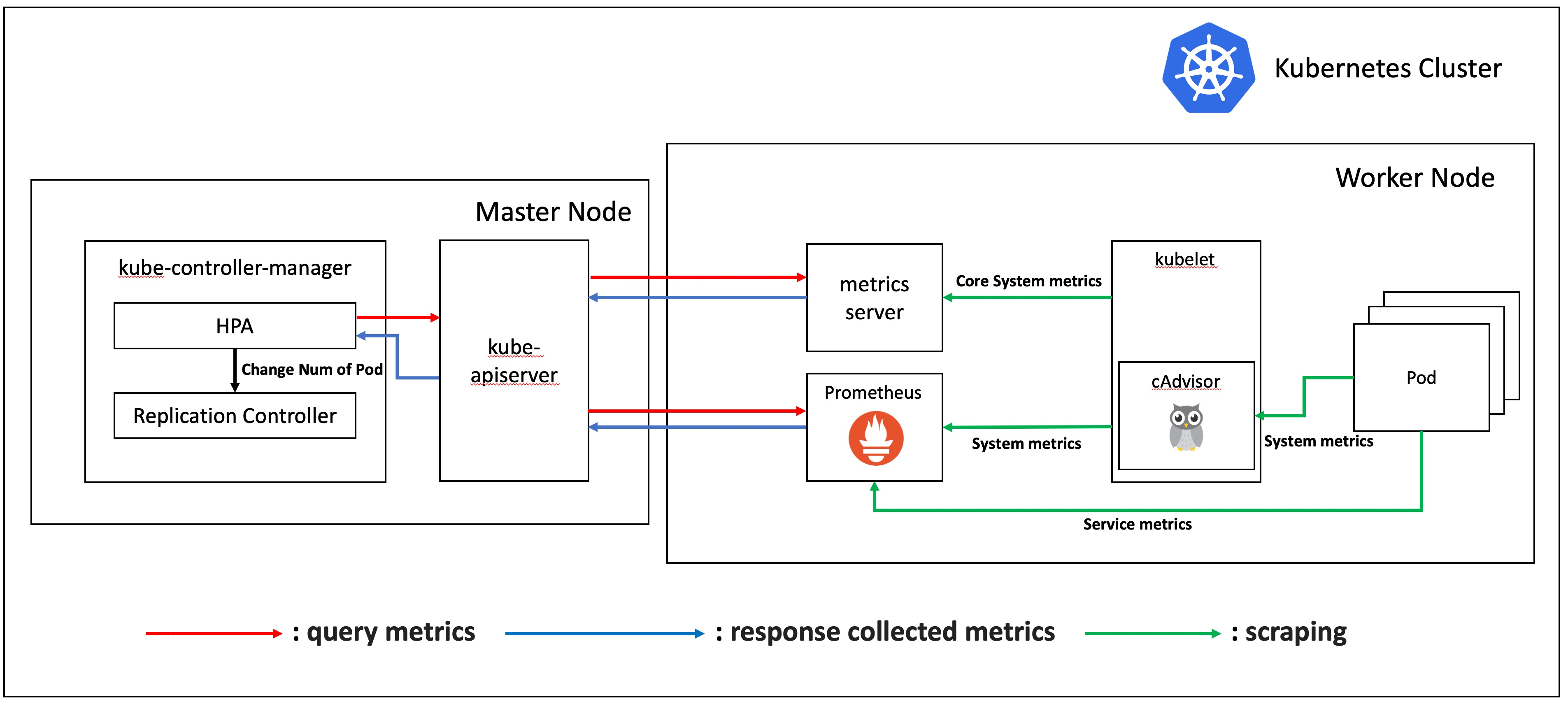
지난 글에서 이론에 해당하는 오토스케일링에 대해 알아보고, 쿠버네티스에서의 오토스케일링 종류와 오토스케일링 기준이 되는 메트릭 및 관련 컴포넌트, 마지막으로 프로메테우스까지 알아보았습니다. 이제부터는 실제로 실험을 진행하기 위한 환경을 구축하고, 실험을 진행할 것입니다.
실험에 필요한 준비물들
우선 실제 환경 구축에 앞서 필요한 준비물들을 정리해 보았습니다.
쿠버네티스 클러스터- 실험할 어플리케이션과 도커 이미지
- 실험 시나리오에 따라 요청을 보낼 웹 서버 요청 툴
- 쿠버네티스 클러스터를 모니터링하기 위한 Prometheus + Grafana 환경
- HPA가 오토스케일링 메트릭을 받아오기 위한 metrics-server와 Prometheus adapter
쿠버네티스 클러스터는 저번 글에서 KVM 가상 머신 환경을 이용해 구축했고, 이번 글에서는 오토스케일링할 어플리케이션을 구성하고 dockerfile로 이미지화 및 docker hub에 배포한 후, 저번에 구축해둔 쿠버네티스 클러스터에 배포해 보겠습니다.

어플리케이션 구성
node.js, express 를 이용한 REST API 코드
본 실험에서는 쿠버네티스 클러스터 상에서 CPU, IO 집약적인 두 개의 node.js REST API로 들어오는 요청 수가 변화하는 상황에서 실험을 진행할 것입니다. 위 환경에서 오토스케일링 기준 메트릭을 각각 파드들의 평균 CPU 사용량과 컨테이너들의 평균 write byte 수로 놓고, 어플리케이션 작업 유형별로 오토스케일링 기준을 바꿨을 때 그 성능을 비교할 예정입니다. 따라서 CPU 집약적 연산을 하는 API와 IO 집약적 연산을 하는 API를 각각 준비했습니다.
어플리케이션은 연구실 선배가 사용하던 node.js express 를 fork 해온 후 몇몇 부분을 수정하였습니다. 본 실험에서 사용할 핵심 코드는 다음과 같습니다.
// CPU Intensive
app.get("/api/cpu/:id", (req, res) => {
let startTime = new Date().getTime();
let result = 0;
for (let i=0; i<parseInt(req.params.id); i++) {
result = ((result + Math.random()*10000)*Math.sqrt(Math.random()*10000))%123456789;
}
let endTime = new Date().getTime();
res.send([endTime-startTime]);
});
// IO Intensive
app.get("/api/copyfile/:filename", (req, res) => {
let startTime = new Date().getTime();
let filename = req.params.filename;
fs.copyFileSync(filename, 'copied' + filename);
let endTime = new Date().getTime();
res.send([endTime-startTime]);
});CPU Intensive한 API 는 for문을 돌면서 반복적으로 임의의 숫자의 곱 및 나머지 연산을 수행해주는 함수입니다. 실험에서는 요청 당 100,000 번 반복문을 돌도록 했습니다.
IO Intensive한 API 는 파일을 읽은 다음 복사해서 저장하는 함수입니다. 실험에서는 요청 당 50MB 크기의 파일을 복사하도록 했습니다.
전체 코드는 다음 주소에서 확인하실 수 있습니다.
docker Image 생성, 배포
쿠버네티스는 도커 이미지를 이용해 컨테이너를 생성하므로, 위 어플리케이션을 도커 이미지로 만들어야 합니다. 그 절차는 다음과 같습니다.
Dockerfile 생성
Dockerfile 은 컨테이너에 필요한 패키지, 소스코드, 명령어, 환경변수 등을 기록한 하나의 파일입니다. 이 파일에 쓰인 대로 빌드를 실행하면 도커 이미지를 생성할 수 있습니다[1].
FROM node:8
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
CMD ["node", "server.js", "3000"]- FROM : 생성할 이미지의
베이스가 될 이미지를 뜻합니다. 반드시 한번 이상 입력해야 합니다. - WORKDIR : 명령어를 실행할 디렉토리. 배시 셸에서의
cd 명령어와 동일한 기능을 합니다. - COPY : COPY는 파일을 이미지에 추가합니다.
COPY <복사할 파일 경로> <이미지에서 파일이 위치할 경로>형식입니다. - RUN : 이미지를 만들기 위해 컨테이너
내부에서 명령어를 실행합니다. - CMD :
컨테이너가 시작될 때마다 실행할 명령어. Dockerfile에서 한번만 사용할 수 있습니다.
Docker build & push
Dockerfile을 작성하였으면 이미지를 생성하고, 허브에 올립니다. 그 전에, docker hub 에 가입되어 있어야 하며, 터미널에 로그인 되어 있어야 합니다.
sudo docker build --tag [dockerhub id]/[프로젝트명]:[버전] .
sudo docker push [dockerhub id]/[프로젝트명]:[버전]
쿠버네티스 클러스터에서 어플리케이션 실행
마지막 단계로, 만들어서 올린 우리의 app image 를 쿠버네티스 클러스터에서 구동시켜 보겠습니다.
Deployment, 서비스의 정의
deployment 란 실행시켜야 할 파드 개수를 유지하고, 앱을 배포할 때 롤링 업데이트하거나 롤백 등의 기능을 지원하는 쿠버네티스에서 상태가 없는 앱을 배포할 때 사용하는 가장 기본적인 컨트롤러입니다.
서비스란 쿠버네티스 클러스터 안의 파드에 접근하는 방법입니다. 파드는 컨트롤러가 관리하므로 한군데에 고정해서 실행되지 않고, 클러스터 안을 옮겨 다닙니다. 이렇게 동적으로 변하는 파드들에 고정적으로 접근할 때 사용하는 방법이 쿠버네티스 서비스입니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8shpatest-for-default
namespace: k8shpatest
spec:
replicas: 1
selector:
matchLabels:
app: k8shpatest-for-default
template:
metadata:
labels:
app: k8shpatest-for-default
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: k8shpatest-for-default
image: zesow/k8shpatest:v8.1
resources:
limits:
cpu: 300m
requests:
cpu: 300m
---
apiVersion: v1
kind: Service
metadata:
name: k8shpatest-for-default
namespace: k8shpatest
spec:
type: NodePort
selector:
app: k8shpatest-for-default
ports:
- port: 3000
targetPort: 3000
nodePort: 30001—- 를 구분자로 Deployment와 Service가 각각 선언되어 있는데, 쿠버네티스는 이런 식으로 한 파일에서 연관된 여러 선언문을 관리할 수 있습니다. 간단히 중요 파라미터를 알아보겠습니다.
- Deployment
spec.template.spec.containers[].image: 위에서 올린 docker image 파일입니다.spec.template.spec.containers[].resources.limits/requests: 각각 자원을 최대로 얼마까지 사용할 수 있는지, 최소 자원 요구량을 명시할 수 있습니다.
- Service
spec.type: 서비스 타입을 나타냅니다. nodePort는 서비스 하나에 노드의 지정된 포트를 할당하는 타입으로서 클러스터 외부에서도 접근할 수 있습니다. 특이한 점은 파드가 node1에만 실행되어 있고, node2에는 실행되지 않았더라도 node2:8080으로 접근했을 때 node1에 실행된 파드로 연결합니다.spec.ports[].port: targetPort 는 팟 내부 포트로서 3000을 나타내고, nodePort는 외부에 노출할 포트로서 30001번입니다.
마지막으로, 쿠버네티스 커맨드라인 인터페이스인 kubectl 의 apply 기능을 이용해 위 파일을 클러스터에 적용시켜 줍니다.
kubectl apply -f k8shpatest-for-default.yaml다음 글에서는 실험 시나리오를 설계하고 실제 실험을 진행하도록 하겠습니다.
잘못된 부분이 있는 경우 댓글로 남겨주시면 적극 반영하겠습니다! 감사합니다.

참고문헌
[1][https://velog.io/@ckstn0777/도커파일Dockerfile](https://velog.io/@ckstn0777/%EB%8F%84%EC%BB%A4%ED%8C%8C%EC%9D%BCDockerfile)
