
Background Knowledge
Process
Process
프로세스란 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램이다. 메모리에 올라와 실행되고 있는 독립적인 개체이자 프로그램의 인스턴스라고 생각하면 된다. 운영체제로부터 시스템 자원을 할당받는 작업의 단위이며, 실행된 프로그램이다.
프로세스가 되기 위해 할당받는 시스템의 자원으로는 CPU 시간, 운영되기 위해 필요한 주소 공간, Code, Data, Stack, Heap 구조로 되어 있는 독립된 메모리 영역 등이 있다.
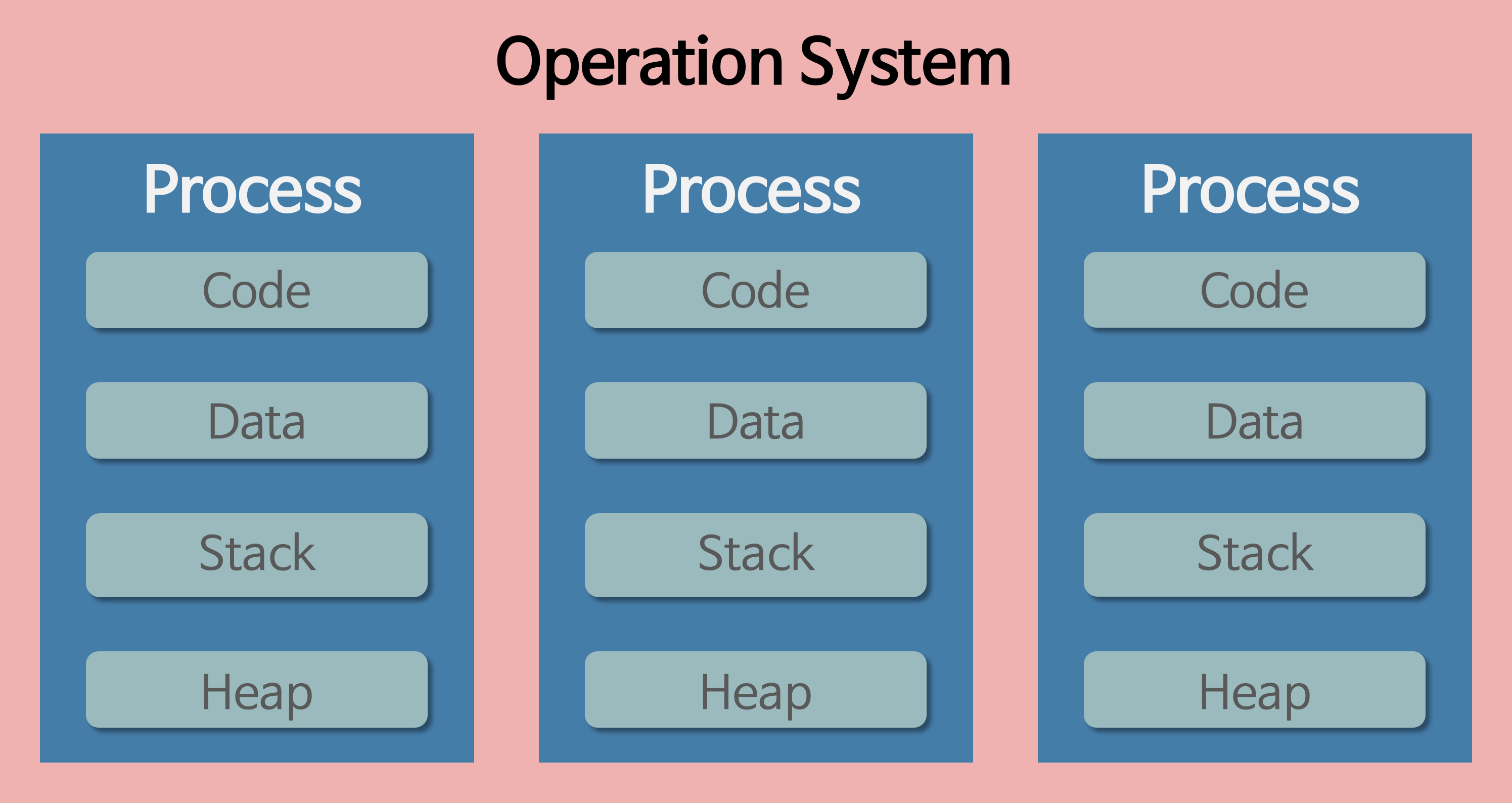
기본적으로 프로세스는 최소 1개의 스레드인 메인 스레드는 필수로 가지고 있다. 각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료 구조에 접근할 수 없다. 한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신인 파이프, 파일, 소켓 등을 이용한 통신을 진행해야 한다.
Hardware Interrupt
운영체제는 동시에 여러 작업을 처리할 수 없다. 그러나 사용자가 한 번에 여러 작업을 수행하는 멀티태스킹을 원할 때, 우선 순위에 따라 해당 작업을 시행하도록 지시하기 위해 인터럽트를 사용한다. 인터럽트란 CPU가 하던 작업을 중단하고, 먼저 처리할 다른 작업을 수행한 뒤 다시 원래의 작업으로 복기하도록 하는 신호이다.
Hardware Interrupt는 외부 장치 또는 하드웨어에서 생성되는 인터럽트다. 프린터, 마우스 클릭, USB 인식 등의 장치로 발생할 수 있다.
System Call
System Call
System Call은 소프트웨어가 운영체제를 호출하는 것이다. OS는 다양한 서비스들을 수행하기 위해 하드웨어를 직접적으로 관리하는 반면, 응용 프로그램들은 OS가 제공한 인터페이스를 통해서만 자원을 사용할 수 있다. 이 인터페이스를 시스템 호출이라고 한다.
-
fork()
유닉스, 리눅스 시스템 콜 중 하나이다. 새로운 프로세스 공간을 별도로 만들고, fork() 시스템 콜을 호출한 부모 프로세스 공간의 데이터을 모두 복사한다. 기존에 실행되고 있었던 부모 프로세스에 있는 모든 내용을 자식 프로세스에 copy한다.
프로세스 안에 있는 fork() 시스템 콜을 실행하면 새로운 프로세스 공간(동일한 코드, 데이터를 가짐)을 만든 다음에 fork() 다음 줄에 Program Counter가 놓여서 동일한 Code를 읽어나가게 된다.
#include <sys/types.h> #include <unistd.h> #include <stdio.h> int main() { pid_t pid; printf("Before fork() call\n"); **pid = fork();** if (pid == 0) printf("This is Child process. PID is %d\n", pid); else if (pid > 0) printf("This is Parent process. PID is %d\n", pid); else printf("fork() is failed\n"); return 0; }자식 프로세스는 pid가 0으로 return 되고부모 프로세스는 pid가 실제 프로세스의 pid으로 return 되어 자식, 부모 프로세스를 pid를 이용해서 구분할 수 있다.
-
exec()
유닉스, 리눅스 시스템 콜 중 하나로 덮어씌운다. exec() 시스템 콜을 호출한 현재 프로세스 공간의 CODE, DATA, BSS 영역을 새로운 프로세스의 이미지로 덮어씌운다. 별도의 프로세스 공간을 만들지 않는다.
프로세스 안에 있는 exec() 시스템 콜 실행을 하면 새로운 프로세스를 만드는 것이 아니라 현재 만들어진 exec 인자에 들어가 있는 프로그램 실행 파일을 읽어서 현재 부모 프로세스 공간의 exec 인자에 있는 실행파일에 대한 CODE, DATA, BSS 영역을 덮어 씌운다. (HEAP, STACK 은 동적 영역이기 때문)
-
bind()
// 함수 원형 int bind(int sockfd, struct sockaddr *addr, socklen_t addrlen); // 실제 사용 if(bind(serv_sock,(struct sockaddr*) &serv_addr,sizeof(serv_addr))==-1){,,,}bind() 함수에 3가지 인자를 전달함으로써 비로소 소켓에 주소를 할당할 수 있다.
즉, 우리가 앞서 socket() 함수로 받아온 디스크립터 sockfd가 존재하는데, 이 디스크립터 파일에 해당하는 소켓에 serv_addr 주소를 할당하겠다는 의미이다.
sockfd: socket() 함수를 통해 배정받은 디스크립터 번호 serv_sockaddr: IP주소와 PORT번호를 지정한 serv_addr 구조체addrlen: 주소정보를 담은 변수의 길이
bind() 함수는 성공시 0, 실패시 -1을 반환한다.
-
listen()
bind를 통해 하나의 소켓에 ip주소와 port번호까지 할당했으니, 이제 클라이언트가 해당 소켓에 연결할 수 있도록 그 요청을 대기하는 상태로 만들어주어야 한다.
이 과정을 담당하는 함수가 listen함수이다.
즉, listen함수가 호출된 후 부터 클라이언트에서 connect(연결을 요청하는 함수)를 호출할 수 있게된다.
// 함수 원형 int listen(int sock, int backlog); // 실제 사용 if(listen(serv_sock,5)==-1){,,,}-
sock: 소켓 디스크립터 번호 -
backlog: 연결요청을 대기하는 큐의 크기즉, 지정한 디스크립터의 소켓이 리스닝소켓이 되며, backlog 만큼의 큐 공간을 갖는다.
위의 예시에서는 큐의 크기를 5로 설정했으며, 이는 5개까지의 클라이언트 연결 요청을 대기시킬 수 있음을 의미한다.연결 요청을 대기하는 큐(Queue)
우선 '연결요청을 대기'한다는 것은 클라이언트가 연결을 요청했을 때, 그 요청을 대기시킬 수 있음을 의미한다. 그리고 큐는 쉽게 말해 대기실이라고 이해할 수 있는데, 시스템에서 순서대로(tcp인경우) 클라이언트를 연결시킬 수 있도록 큐에 모아 놓은 것이다. -
-
accept()
이제 마지막으로, 대기중인 클라이언트의 요청을 차례로 수락함으로써 데이터를 주고받을 수 있게 된다.
accpet 함수가 바로 연결 요청을 수락하는 함수이다.
// 함수 원형 int accept(int sock, struct sockaddr*addr, socklen_t *addrlen); // 실제 사용 clnt_addr_size=sizeof(clnt_addr); clnt_sock=accept(serv_sock,(struct sockaddr*)&clnt_addr,&clnt_addr_size);여기서 주의해야 할 점은, accept의 반환값은 성공/실패에 대한 정수값이 아닌, 새로운 디스크립터 번호라는 점이다.
즉, 우리가 앞서 이용하던 서버 소켓(리스닝 소켓)은 연결 요청을 대기시키는 과정까지를 담당하며, accept() 함수를 통해 새로 할당받은 소켓을 이용해 데이터 송수신을 할 수 있는 것이다.
sock: 서버 소켓(리스닝 소켓)의 디스크립터 번호addr: 대기 큐를 참조해 얻은 클라이언트의 주소 정보addrlen: addr 변수의 크기
TCP / IP
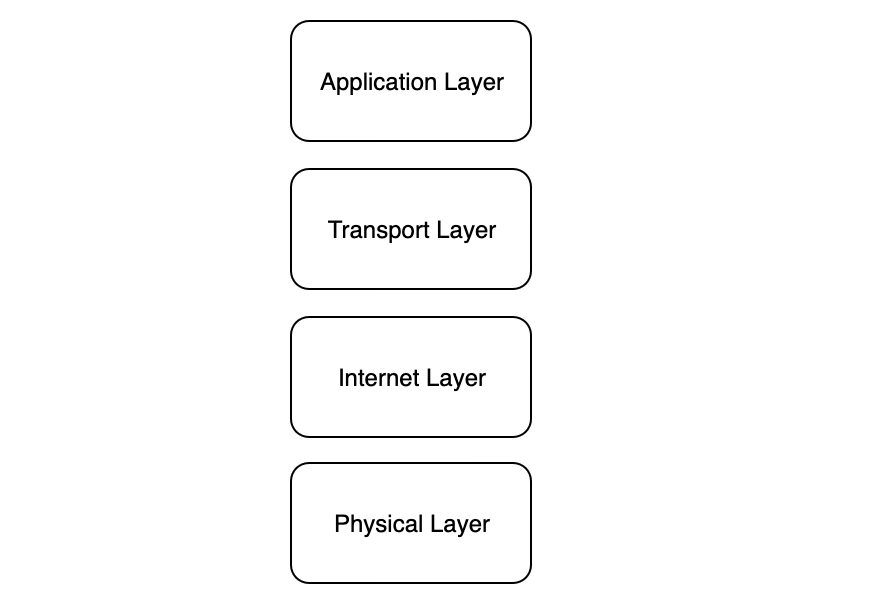
Application Layer
- 응용 계층 (Application Layer) 프로토콜은 TCP/IP 프로토콜 (TCP IP protocol)의 범위에 포함되어있다.
- 이러한 프로토콜은 앱에 구축되기 때문에 사용자가 상호작용하기 가장 쉬운 계층이다.
- 응용 계층은 사용자 (사람 또는 소프트웨어)가 네트워크에 접근할 수 있도록 한다. 게다가, 사용자 인터페이스를 제공할 뿐만 아니라 이메일, 원격 파일 접근 및 전송, 공유 데이터베이스 관리 등의 서비스를 제공한다.
- 메일 프로그램에서는 인터넷에서 전자우편을 보낼 때 이용하게 되는 표준 통신 규약인 SMPT (Simple Mail Transfer Protocol)를 이용한다.
- 인터넷 브라우저는 웹 서버와 사용자의 인터넷 브라우저 사이에 문서를 전송하기 위해 사용되는 통신 규약인 HTTP (Hypertext Transfer Protocol) 등을 이용한다.
Transport Layer
- 전송 계층은 전송을 담당하는 계층이다.
- 전송 계층에는 TCP뿐만 아니라 사용자 데이터그램 통신 규약(User Datagram Protocol: UDP)도 있다.
- UDP는 TCP보다 단순하며 다른 데이터에 비해 안전하게 보호되어야 할 필요가 없는 실시간 응용 프로그램에서 흔히 이용된다.
- UDP는 TCP보다 신뢰도가 낮고 오류 검출, 흐름 제어 등의 기능을 제공하지 않아 패킷을 빠르게 전송하는 응용 계층에서 이용되고있다.
- TCP는 두 네트워크 사이에 연결을 형성하고 효율적인 작업을 위해 데이터를 작은 패킷으로 나눠서 데이터를 전송한다. TCP는 연결형 서비스이지만, UDP는 비연결형 서비스이다.
- TCP는 신뢰도가 높지만 속도가 느리고, 이에 비해서 UDP는 신뢰도가 낮지만 속도가 빠르다. TCP의 패킷 교환 방식은 가상 회선 방식인 반면, 반면에 UDP는 데이터그램 방식을 따르고 있다. TCP에서는 전송 순서를 보장하지만 UDP의 경우 전송 순서가 바뀔 수 있다.
Internet Layer
- 인터넷 계층 (Internet Layer) 프로토콜에는 IP뿐만 아니라 주소 변환 규약(Address Resolution Protocol: ARP), 인터넷 그룹 관리 프로토콜(Internet Group Management Protocol: IGMP), 인터넷 제어 메시지 프로토콜 (Internet Control Message Protocol: ICMP)도 있다.
- 인터넷 계층은 네트워크 간 데이터 패킷의 전송을 관리한다.
- 여기서 ARP는 네트워크 계층 주소와 링크 계층 주소 사이의 변환을 담당하는 프로토콜이며, IGMP는 그룹 멤버십을 구성하거나, 그룹 관리를 위한 프로토콜이며, ICMP는 인터넷 통신 서비스 환경에서 오류에 대한 알림과 관련된 메시지를 전달하는 목적의 프로토콜이다.
Datalink Layer
- 데이터 링크 계층 (Datalink Layer)은 데이터 전송의 최하위 계층으로, 네트워크 인터페이스 계층(Network Interface Layer)이라고도 부른다.
- 이 계층에서 하는 일은 데이터가 원하는 IP 주소 (즉, 공유기)에 도달할 뿐만 아니라 해당 네트워크 내의 연결된 기기에 연결되어 있는지 확인하는 역할이다.
- 데이터 링크 계층은 원하는 기기의 MAC 주소를 확인하고 이더넷 케이블 및 와이파이를 통한 데이터 전송을 관리하는 등의 작업을 담당한다.
Socket
Socket
TCP/ IP 모델에서 어플리케이션 계층의 어플리케이션들 (웹 서버, 웹 어플리케이션 서버)이 네트워크 스택이 처리한 데이터를 받아서 처리하기 위한 인터페이스이다. 어플리케이션이 바로 네트워크 스택의 정보를 직접 접근하면 위험하기에 무조건 운영체제를 거치게 하기 위해 사용한다. 소켓은 네트워크 상에서 돌아가는 두 개의 프로그램 간 양방향 통신의 하나의 엔드 포인트이다. 소켓은 포트 번호에 바인딩되어 TCP 레이어에서 데이터가 전달되야하는 애플리케이션을 식별할 수 있게 합니다.
End Point
아이피 주소와 포트 번호의 조합을 의미한다. 모든 TCP 연결은 2개의 엔드 포인트로 유일하게 식별되어질 수 있다. 따라서 클라이언트와 서버 간 여러 개의 연결이 맺어질 수 있다.
PORT
네트워크 상에서의 특정 호스트(IP 주소를 가진 컴퓨터)에서 프로세스를 구분하기 위한 번호이다. 하나의 운영체제는 프로세스를 PID로 구분한다. 근데 그렇다고 다른 컴퓨터에 있는 프로세스도 PID를 이용해서 구분하는 것은 매우 좋지 않다. 내 컴퓨터에도 2345번 프로세스가 있고 다른 컴퓨터에도 2345번 프로세스가 있으면 구분이 어려워진다. 그래서 포트를 쓴다.
서버는 포트 번호가 바인딩된 소켓이 서버 컴퓨터 위에서 돌아가는 프로세스를 가진다. 해당 서버는 클라이언트의 연결 요청을 소켓을 통해 리스닝하면서 기다리게 된다.
클라이언트는 서버의 호스트 네임과 서버가 리스닝 중인 포트 번호를 알아야지만 연결을 시도할 수 있다. 또한 클라이언트는 서버에게 자신이 누구인지 말해 주기 위해 로컬 포트에 바인딩되는데, 이 과정은 보통 시스템에 의해 이루어진다.

서버와 클라이언트의 연결이 무사히 실행된다면, 서버는 클라이언트의 로컬 포트에 바인딩된 새로운 포트를 얻게 되며, 이는 클라이언트의 주소와 포트로 세팅된 리모트 엔드 포인트이다. 서버가 새로운 소켓이 필요한 이유는 연결을 처리하면서도 기존에 가지고 있던 소켓으로 리스닝 작업을 처리해야 하기 때문이다.

클라이언트 입장에서는 만약에 연결이 수락되면 소켓은 성공적으로 생성되며 클라이언트는 서버와 통신하기 위해서 소켓을 사용할 수 있게 된다.
File Descriptor
File Descriptor
유닉스/ 리눅스에서는 모든 것을 다 파일로 취급한다. 그래서 소켓도 파일이다. 이 때 각각 파일을 식별하는 번호가 디스크립터라고 생각하면 된다. 이걸 언제 쓰냐면 read() 함수로 파일에 있는 정보를 가져올때 파라미터로 이 파일 디스크립터를 주면 알아서 잘 읽어온다.
Data Communications
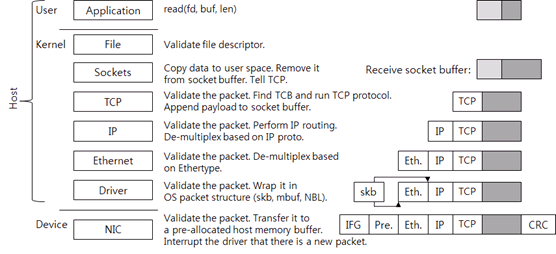
NIC
이 랜 카드가 OSI 7계층에서의 물리 계층의 일을 해 준다고 보면 된다. NIC는 하드웨어 적으로(논리 회로의 그 xor, and 등 게이트) CRC(오류 검사 과정) 등 과정을 거쳐 문제가 없다는 것이 확인되면 저 위 그림의 드라이버라는 곳에다가 데이터를 넣고 운영체제에게 하드웨어 인터럽트를 걸어서 CPU한테 그 데이터를 네트워크 스택에 보내라고 한다.
네트워크 스택은 소프트웨어라고 하며 서로 계층간에 데이터를 주고받을 때 시스템 콜을 통해 데이터를 주고 받는다.
네트워크 계층은 이더넷 계층, IP 계층, TCP 계층을 대표로 다룬다. UDP와 같이 다른 친구들도 있다.
Network - Ethernet
OSI 7계층에서의 데이터링크 계층의 일을 한다고 생각하면 된다. 데이터가 올바른지 확인 하고 상위 프로토콜이 무엇인지 확인해 그 프로토콜을 처리하는 네트워크 스택 중 하나에게 데이터를 전송한다.
Network - IP
송신을 할 때는 여기서 라우팅을 하지만 수신을 할 때는 그냥 똑같이 확인하고 다음 계층이 무엇인지 찾아내서 보내 준다.
Network - TCP
네트워크 스택의 마지막 부분으로 가장 많은 일을 하고 이후 소켓에게 데이터를 보내 준다.
TCP 계층 역시 check sum 값을 체크해 보고 헤더를 확인한다.
TCP는 연결지향 프로토콜이라 3-way handshake로 서로 논리적인 연결이 완성된 경우에만 데이터를 송수신 한다. 따라서 새로운 데이터가 올 경우 receive socket buffer(TCP 의 윈도우)에 넣어두고 3-way handshake가 완성되면 제거 후 데이터를 송수신을 한다. 여기서는 수신이니 데이터를 소켓에 보낸다.
아무 소켓한테나 데이터를 주는 게 아니고 소켓에 바인딩 된 아이피 주소, 프로토콜, 포트번호가 올바른 소켓에게 데이터를 준다.
Sockets
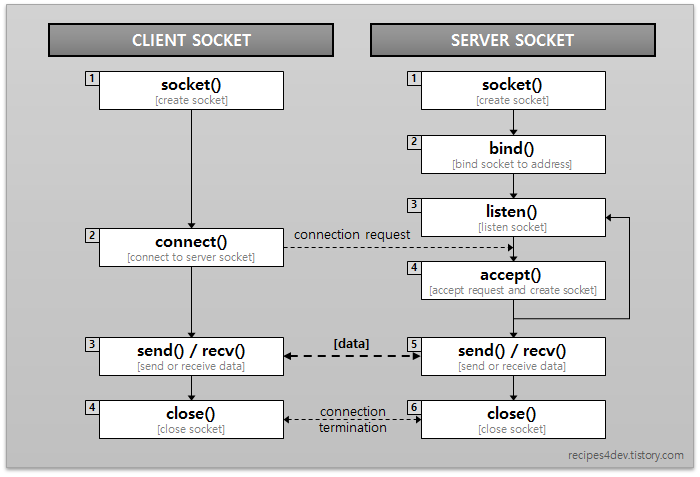
위의 소켓 통신은 TCP 기반이다. UDP는 다르다.
-
socket()
socket() 시스템 콜을 해서 사용할 소켓을 생성한다. 생성시 소켓도 파일이고 운영체제에서 소켓을 사용할 프로세스에게 소켓의 파일 디스크립터를 return 해 준다.
-
bind()
socket을 만들었지만 아직 소켓을 사용할 수는 없다. 네트워크 스택에서 이 소켓을 식별할 수 없기 때문이다. 따라서 소켓에는 여러가지 값을 바인드 해 줘야 하며 IP 버전, 포트, 소켓 타입(TCP - 스트림, UDP - 데이터그램)을 바인드 한다. 이렇게 바인드를 하면 소켓 식별이 가능해진다.
이 시스템 콜은 서버에만 존재하고 클라이언트에는 존재하지 않는다. 바인드가 없으면 운영 체제가 아무 포트 번호에 박아 버린다. 서버는 포트 번호가 일정해야 하기 때문에 바인드가 필요하다. 바인드느 포트 번호 외에도 ip 버전 등을 받지만 실제 ip 주소가 할당되는 것은
accept()이다. -
listen() (only for stream socket)
이름만 보면 마치 소켓이 데이터를 받도록 대기하라고 하는 함수 같지만 이 함수는 소켓이 최대로 받을 연결 갯수를 지정하는 함수라고 생각하면 된다. 5로 지정하면 5개 연결까지만 받아준다.
-
accept() (only for stream socket)
listen 상태인 소켓 중 만약 소켓이 stream, 즉 tcp를 활용할 경우 바로 데이터를 송수신 하지 않는다. tcp기반 통신은 통신을 하는 객체와 주체간의 논리적인 연결을 만들어야 한다. 이러한 논리적인 연결을 최종적으로 수립하는 시스템 콜이다.
여기서 헷갈리면 안 되는 부분은 accept를 통해 TCP 3-way handshake를 하지 않는다는 것이다.
3-way handshake는 위에서 TCP 네트워크 스택에서 말했듯 네트워크 스택이 처리하고 이후 최종 세션 수립은
accept()를 통해서 진행한다. -
recv() or recvform() (only for datagram socket)
recv()는 tcp,recvform()은 udp에서 사용한다.왜 위에 구분선을 만들었냐면, tcp의 경우는 accept를 통해 세션이 수립 된 이후
fork()를 호출해 실제 수신, 응답에 필요한 나머지 처리를 자식 프로세스에서 진행한다. **자식 프로세스는
recv()를 사용하고 wait 상태에 들어가 네트워크 스택이 데이터를 소켓에 보내주기를 기다린다. 이후read()시스템 콜을 통해 소켓 파일에 있는 데이터를 읽는다.반면 udp는 비연결 지향이기에 tcp처럼 listen(), accept()를 거치지 않고 bind()가 되자마자 **
fork()를 통해 자식 프로세스를 만들고 곧바로 recvform() 시스템 콜을 통해 데이터를 기다린다. 이후read()로 udp 소켓에서 필요한 데이터를 읽어들여 어플리케이션에서 사용하는 것은 동일하다. -
close()
사용한 소켓 파일을 삭제한다.
클라이언트랑 서버가 연결된 이후로 응용프로그램이 혼자 모든 일을 다 하고 답을 줄까?
아니다. 연결이 왔으면 연결을 받아 주기만 하고 일을 하는 애를 fork로 따로 만들어서 실행한다. 나는 연결만 만들게 자식 프로세스인 너는 응답을 만들렴 방식으로 진행한다.
