
2023년 3월 6일부터 @cloudnet study를 시작 하였다.
[24단계 실습으로 정복하는 쿠버네티스][이정훈 지음]의 책을 기본으로 학습을 한다.
운영을 하면서도 부족한 부분을 배울 수 있을 것이란 기대감과 함께 시작한 수업이나 숙제를 하지 못해서 발생하는 불상사를 경험하지 않고 5주간의 스터디를 잘 마무리 했으면 좋겠다.
4주차 스터디 내용을 정리해 본다.
4주차에는 쿠버네티스 모니터링 시스템에 대해서 스터디 및 실습을 진행하였다.
내가 속해 있는 회사에서도 쿠버네티스 클러스터를 운영 중이고 클러스터 모니터링을 프로메테우스&그라파나로 진행하고 있어서 그 구축 과정속에서 정리 헀던 내용을 남겨보고자 한다.
1. 모니터링 시스템
모니터링이란
모니터링이란 시스템 상의 상태 변화를 지속적으로 감시하는 과정이라고 정의할 수 있다.
그래서 모니터링 과정 중에 생산된 데이터를 수집·저장한 뒤 관리자의 의사결정에 큰 도움을 주기 위해서는 단편적인 데이터 제공만으로는 부족하다.
지속적인 감시 과정 속에 생성된 데이터를 관리자가 효과적으로 분석할 수 있도록 실직적인 도움을 주어야 한다.
결론적으로 모니터링 시스템이란 이런 데이터의 수집, 처리, 분석, 표현 등을 구현하는 소프트웨어의 집합이라고 정의할 수 있다.
쿠버네티스 모니터링 시스템
쿠버네티스를 운영하면서 필요한 여러 시스템 중에서 클러스터의 상태값을 주기적으로 확인하고 관찰하기 위한 모니터링 시스템은 필수적이라고 할 수 있다.
이미 인프라 운영의 표준처럼 자리 잡은 쿠버네티스 플랫폼이지만 공식적으로 제공해주는 모니터링 시스템은 없는 상황이다
그로 인해서 다양한 진영에서 쿠버네티스와 인프라 환경을 모니터링 하기 위한 제품과 서비스가 생산 되게 되었고 각각의 서비스들을 필요에 따라서 사용하는 것이 기본적인 모니터링 시스템 구축의 트렌드라고 볼 수 있다
유료 모니터링 서비스론 대표적인 datadog, 뉴렐릭, 와탭등이 있다.
무료 모니터링 서비스론 프로메테우스&그라파나, ELK 등이 대표적이라고 할 수 있다.
내가 속해 있는 회사에서도 뉴렐릭을 활용해서 서비스 인프라를 모니터링 하고 있고 훌륭한 모니터링 환경을 제공해 주고 있다
다만 사용하는 만큼의 부가되는 비용과 시스템은 계속 늘어가게 될 것이고 그로 인해서 발생하는 비용에 대한 부분을 조금이나마 줄이기 위해서 내가 운영하고 있는 K8S 클러스터는 무료인 프로메테우스&그라파나 조합으로 구축해서 운영하고 있다
(물론 더 다양한 이유로 인해서 프로메테우스&그라파나를 선택한 것이지 꼭 비용적인 것만은 아니다)
2. 프로메테우스
프로메테우스란
프로메테우스는 메트릭 수집, 시각화, 알림, 서비스 디스커버리 기능을 모두 제공하는 오픈 소스 모니터링 시스템이다.
처음에는 SoundCloud 만들어졌으나 2016년에 쿠버네티스에 이어 두번째로. CNCF산하 프로젝트 멤버로 들어가게 되었다. 시계열 데이터를 수집하고 저장하는데 사용된다. 이 값은 레이블이라는 key-value 쌍으로 타임스탬프와 함께 저장되어 시계열 데이터가 형상화 된다
프로메테우스 아키텍처
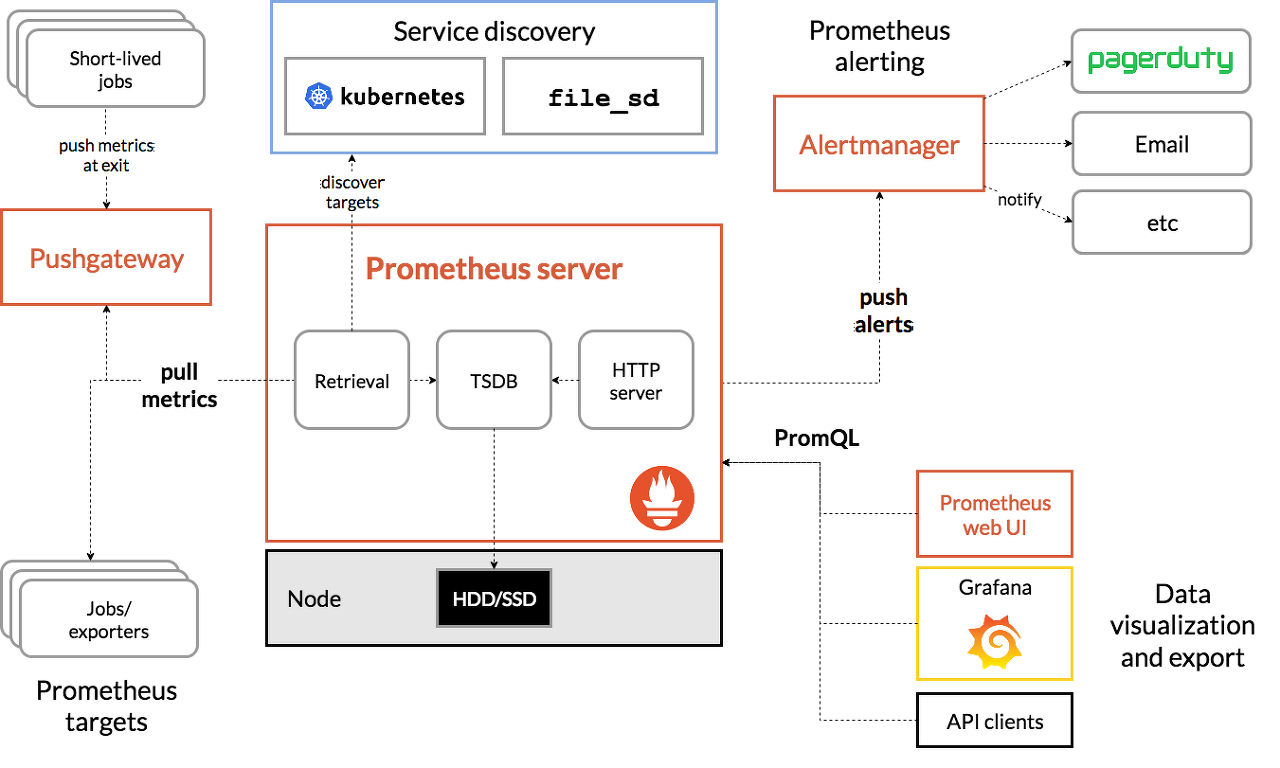
- Service Discovery
DNS나 Hashicorp사의 Consul 또는 쿠버네티스를 통해서, 모니터링해야 할 타겟 서비스 목록을 가지고 있다
- Pushgateway
Proxy Forwarding을 해서 접근 할 수 없는 곳에 데이터가 존재하는 경우에 사용 할 수 있는 대안이다
애플리테이션이 Pushgateway에 메트릭을 push 한 후, Prometheus server가 Pushgateway에 접근하여 메트릭을 pulling 한다
- Exporter
모니터링 에이전트로 타겟 시스템에서 메트릭을 읽어서, 프로메테우스가 pulling 을 할 수 있도록 한다
또한 단순한 http get 으로 메트릭을 텍스트 형태로 프로메테우스가 리턴한다. 요청 당시 데이터를 리턴하는 것 뿐, 저장하지는 않는다.
- Prometheus server
프로메테우스의 메인 서버로 메트릭 데이터를 수집하고 저장한다. 프로메테우스 서버 내부에는. Retrieval, TSDB, HTTP server 모듈이 있다.
- Retrieval
Service Discovery로 부터 모니터링 대상 목록을 받아오고, Exporter로부터 주기적으로 메트릭을 수집하는 모듈이다.
- TSDB(Time-series Database
수집된 메트릭은 Prometheus Server 내의 메모리와 로컬 디스크에 저장된다.
데이터베이스에 별도로 저장하지 않기 때문에 대상 시스템이 늘어날 수 록 디스크를 늘려야 한다.
- HTTP Server
프로메테우스에 저장된 데이터를 조회하기 위해서 필요한 서버이다. 프로메테우스는 데이터를 가져오기 위한 프로토콜로 HTTP REST API를 제공하고 직접 API를 통해 데이터를 가져가던지, Web UI 대시보드에서 데이터를 조회하던지 해서 그라파나를 통해 데이터를 시각화 할 수 있다.
- Alertmanager
프로메테우스에서 문제가 발생했다고 생각되는 시점에 slack, mail, hipchat등을 통해 알람을 보내준다
알람을 거는 기준은 Rule을 작성해서 load시키는 방식으로 정할 수 있다.
프로메테우스 특징
- 메트릭 이름과 Key-Value 쌍으로 식별되는 시계열 데이터가 있는 다차원 데이터 모델
- PromQL, 이차 원성을 활용하는 유연한 쿼리 언어
- 기본적으로 Pull 방식으로 다른 곳의 시계열 데이터를 가지고 온다,
- Push 방식의 데이터도 가져올 수 있도록 하는 Push gateway가 존재하여 두 방식 모두 지원한다.
- PromQL을 활용하여 저장된 시계열을 쿼리 및 집계
- 서비스 디스커버리
- 데이터 시각화
프로메테우스 설치
- 프로메테우스를 설치하는 방법은 다양하게 있다. 회사의 환경을 구성 할땐 쿠버네티스 클러스터에 Helm Chart를 활용해서 설치를 진행 하였다.
Helm chart를 활용해서 구축할때도 아는 한도내에 2가지 정도가 있다. cli를 통해서 설치를 하는 방법이 있고 argoCD를 활용해서 배포하는 방법이 있다. 회사에선 2가지 다 활용해서 배포를 진행하였었고 최종적으론 ArgoCD를 통해서 배포되게 하엿고 values.yaml를 통해서 변경 사항등을 반영해서 운영하고 있다. 이글에선 2가지 방법을 간략하게 설명하도록 하겠다.
Helm chart + CLI
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo updatehelm pull을 통해서 패키지를 다운 받을 수 있고 chart내에 values.yaml 수정을 통해서 서비스 및 구성에 대한 변경을 진행 할 수 있다.
기본적인 프로메테우스 차트를 다운 받으면 관련된 차트들이 많이 있는걸 확인 할수 있다.
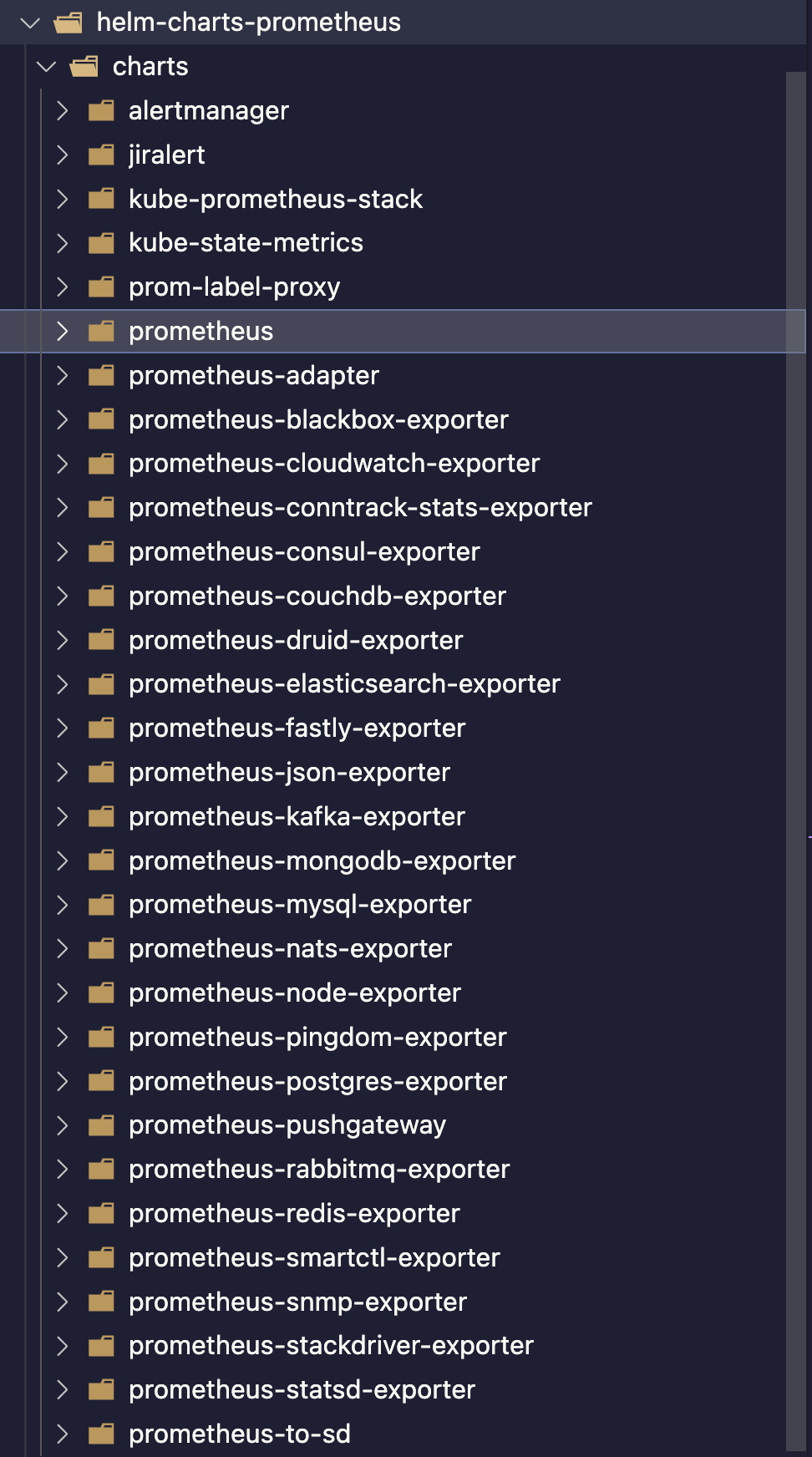
프로메테우스 repo에서 관리하는 차트들이며 필요에 따라서 선택해서 배포 사용가능 하며 사용하는 서비스에 따라서 exporter들을 배포하여서 프로메테우스 서버를 통해서 데이터들을 수집 할 수도 있다.
이번엔 간단하게 service만 nodeport로 변경해서 배포해 보도록 하겠다.
$ helm upgrade --install prometheus prometheus-community/prometheus -f values.yaml --namespace monitoring
Release "prometheus" does not exist. Installing it now.
NAME: prometheus
LAST DEPLOYED: Thu Sep 1 16:40:04 2022
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=prometheus"
Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
$ k get all
NAME READY STATUS RESTARTS AGE
pod/prometheus-alertmanager-5f5d5f956-9zwn7 2/2 Running 2 126d
pod/prometheus-kube-state-metrics-77ddf69b4-2srfh 1/1 Running 1 126d
pod/prometheus-node-exporter-grbm2 1/1 Running 0 125d
pod/prometheus-node-exporter-klfzk 1/1 Running 2 (68d ago) 126d
pod/prometheus-node-exporter-vm6wd 1/1 Running 4 126d
pod/prometheus-pushgateway-969d94d55-tm9f2 1/1 Running 1 126d
pod/prometheus-server-5b87dc7765-gmskr 2/2 Running 3 126d
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus-alertmanager NodePort 10.102.238.47 <none> 80:30000/TCP 126d
service/prometheus-kube-state-metrics ClusterIP 10.110.90.234 <none> 8080/TCP 126d
service/prometheus-node-exporter ClusterIP 10.101.239.48 <none> 9100/TCP 126d
service/prometheus-pushgateway ClusterIP 10.98.80.163 <none> 9091/TCP 126d
service/prometheus-server NodePort 10.96.192.234 <none> 80:30002/TCP 126d- 배포된 리소를 조회를 통해서 외부에서 접근 가능한 서비스 포트를 확인하고 브라우저에서 접근하도록 하겠다.
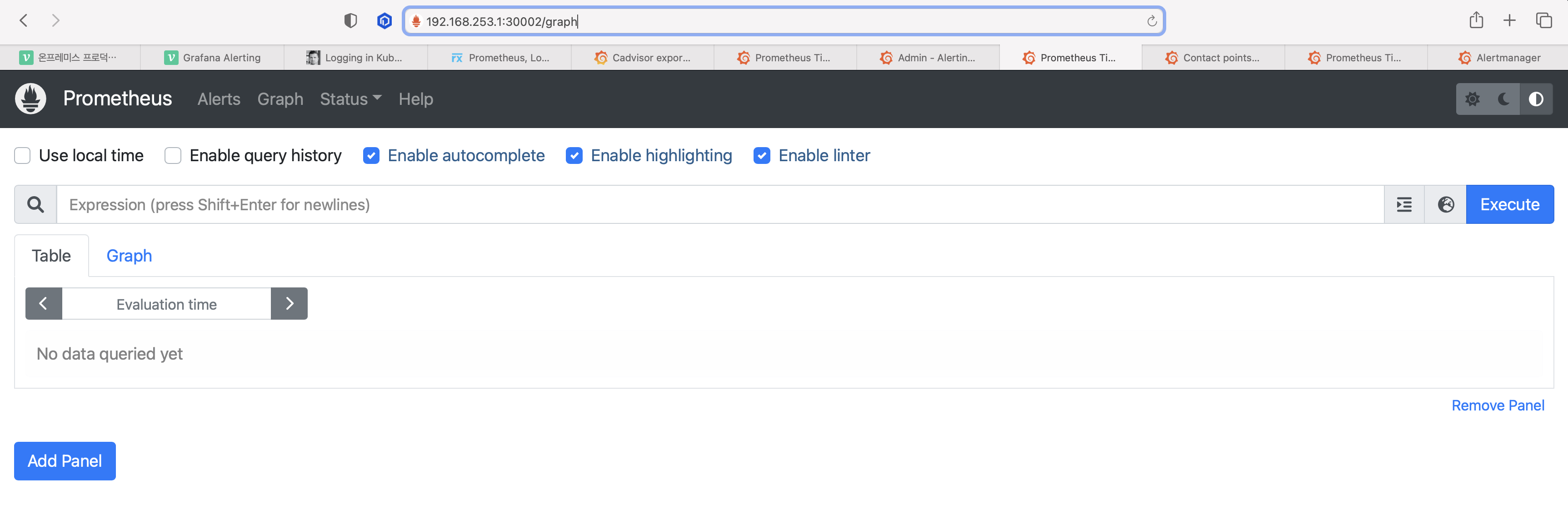
http://{마스터 서버 IP}:{포트}로 접속이 되는 것을 확인 할 수 있다.
Helm Charts + ArogCD
- 3주차에 학습한 GitOps의 일환으로 ArgoCD를 활용해서 프로메테우스 Helm Charts 배포를 진행해 보도록 하겠다
- 현재 회사에서 구성된 파이프라인이다 Github Repo를 활용하여서 쿠버네티스에서 쓰는 Helm Chart들을 모아 일반 Repo에 추가해서 사용하고 있다
Helm Chart를 등록해서 사용 하는 방법은 다음 사이트를 참고하면 좋을 것 같다(github helm cahrt)]
- 회사에서 사용하는 Github action 활용한 배포 및 argocd 활용 파이프라인이다
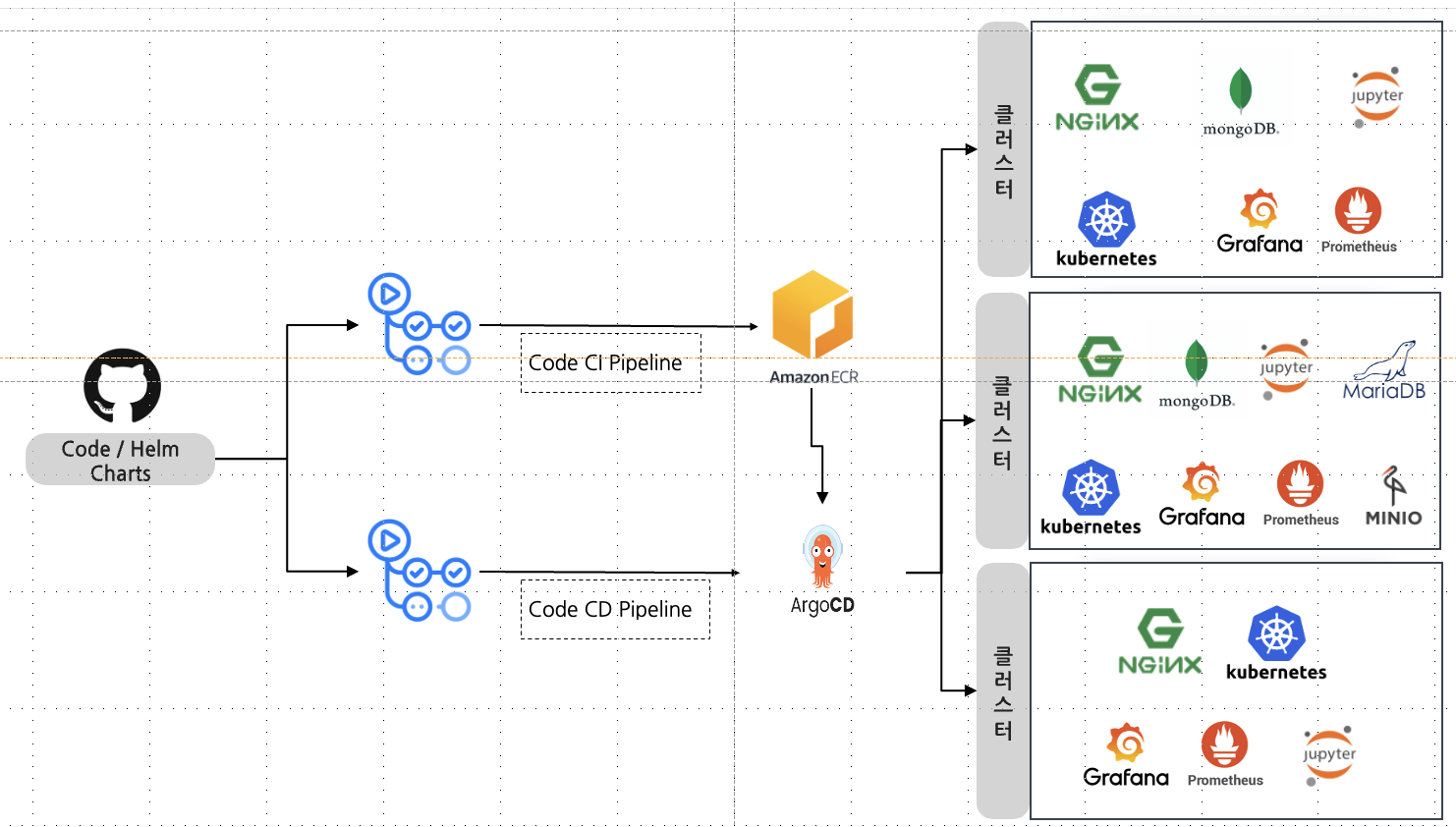
프로메테우스 helm chart를 ArgoCD 를 활용 할 수 있도록 Applications을 등록해 보겠다.
-
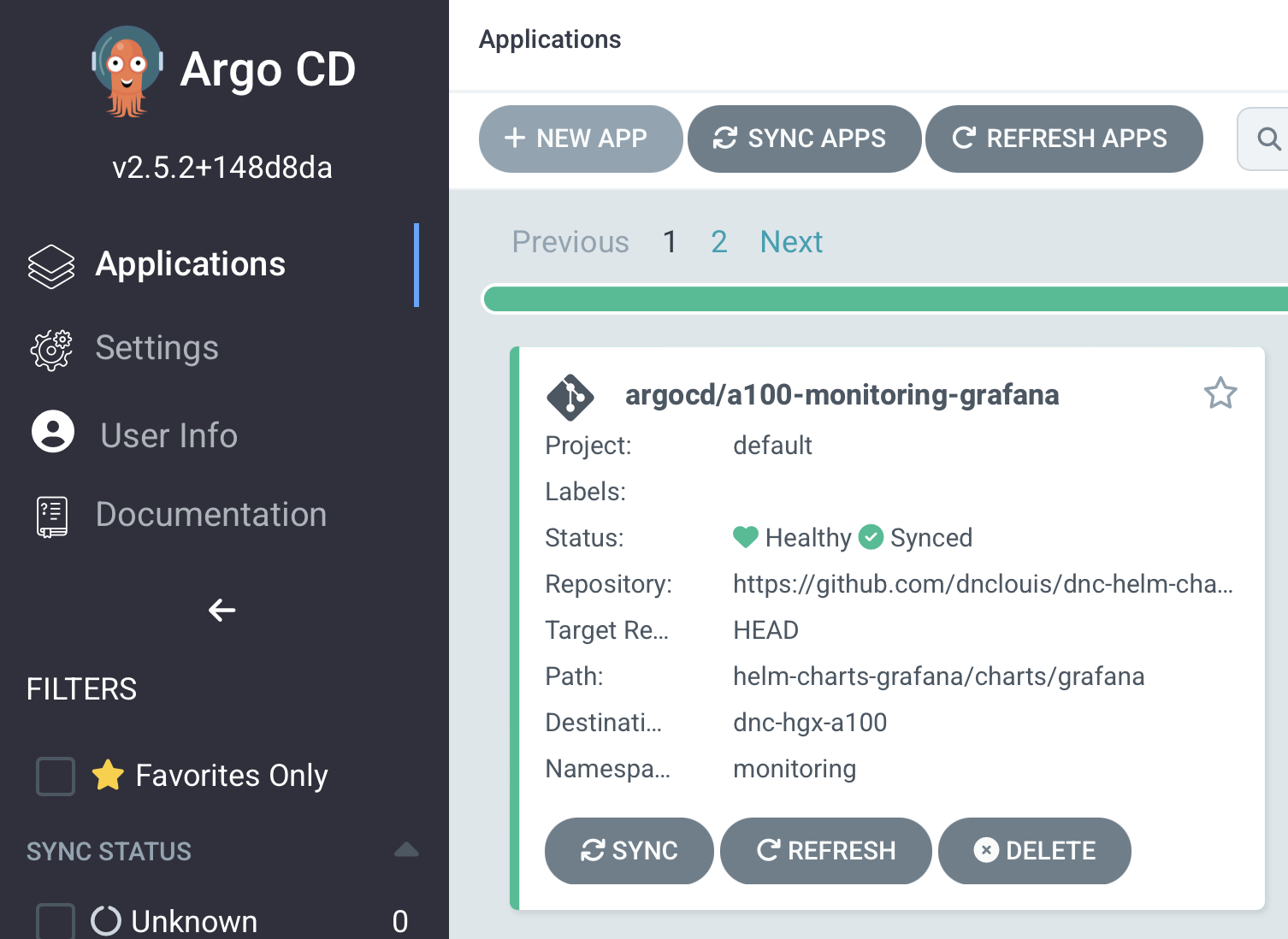
3주차에서 설치한 ArgoCD GUI 화면에서 NEW APP을 클릭해서 등록 작업을 진행한다
-
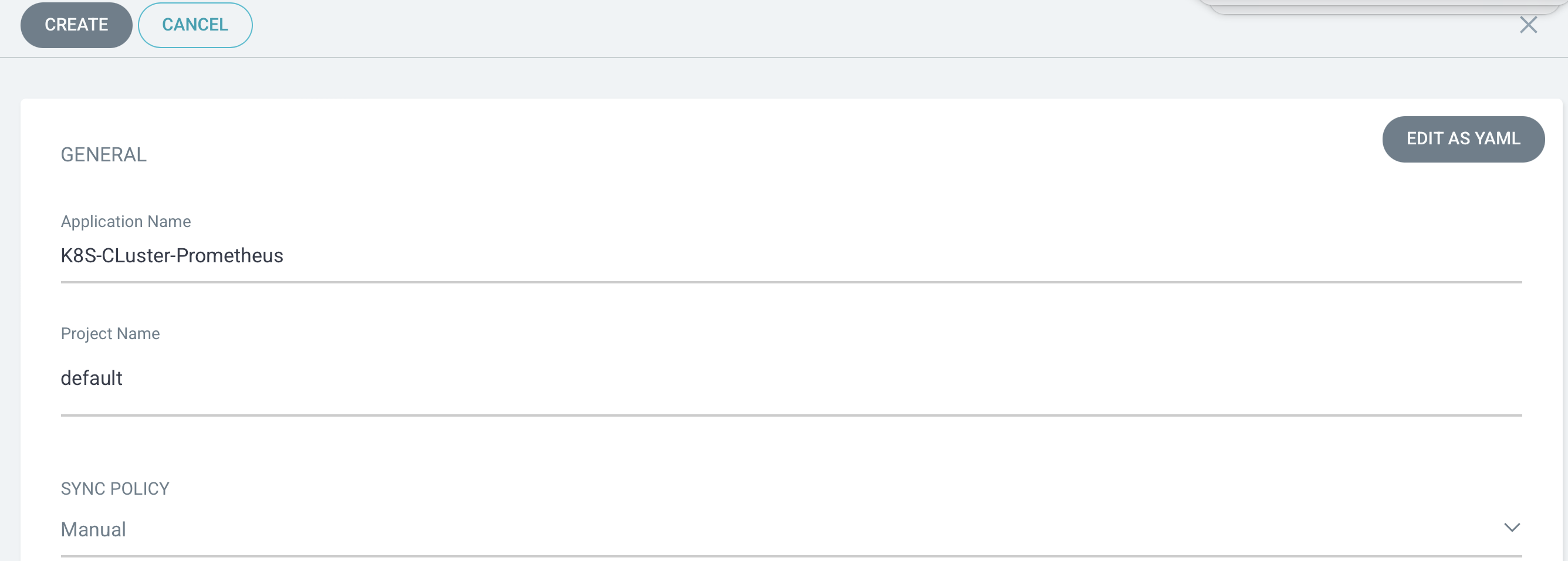
App 이름과 default 설정을 진행
-
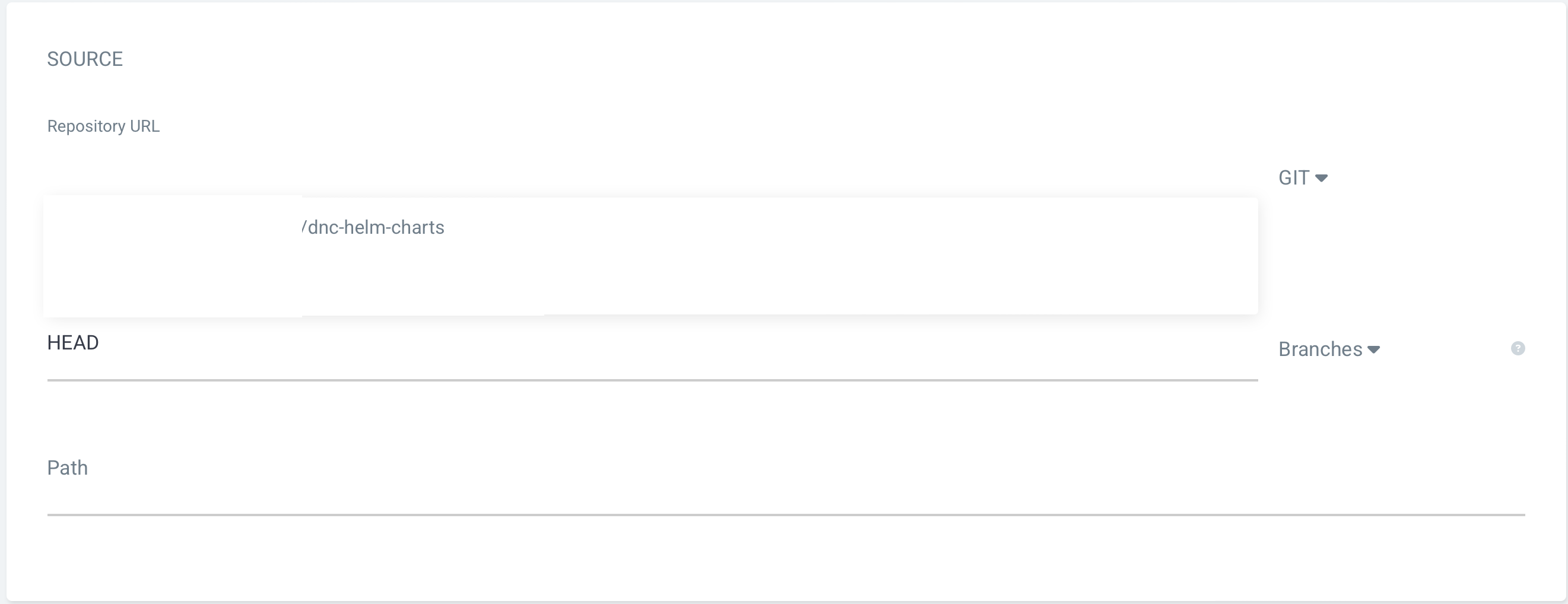
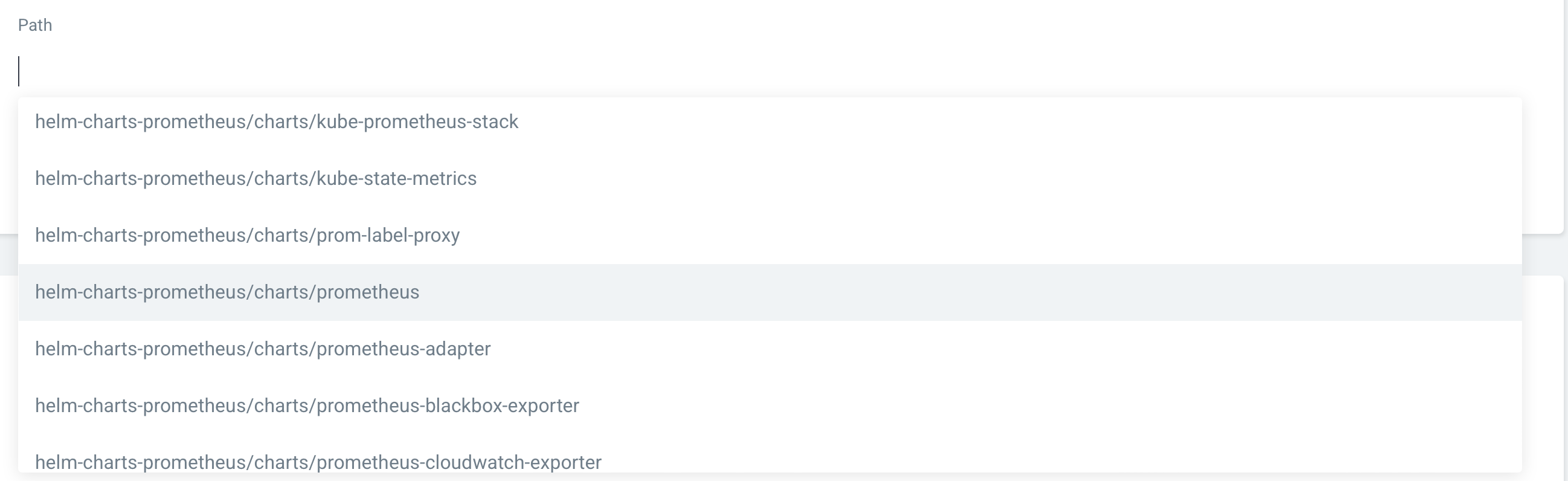
helm chart가 등록된 레포 주소를 지정하고 helm chart prometheus 폴더를 지정한다
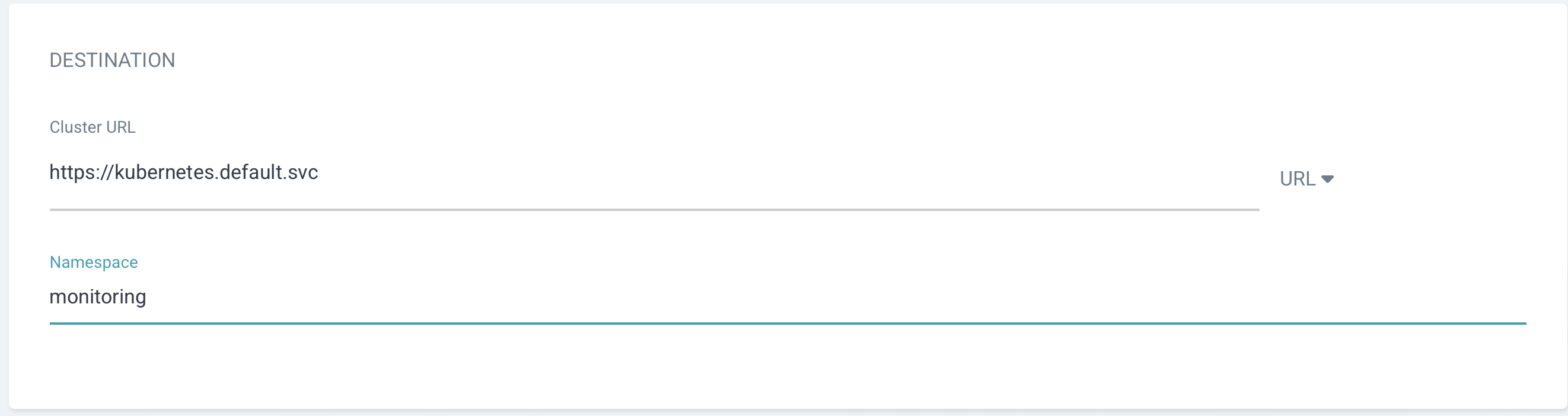
- 배포될 대상 클러스터와 namespace를 지정해 준다
-
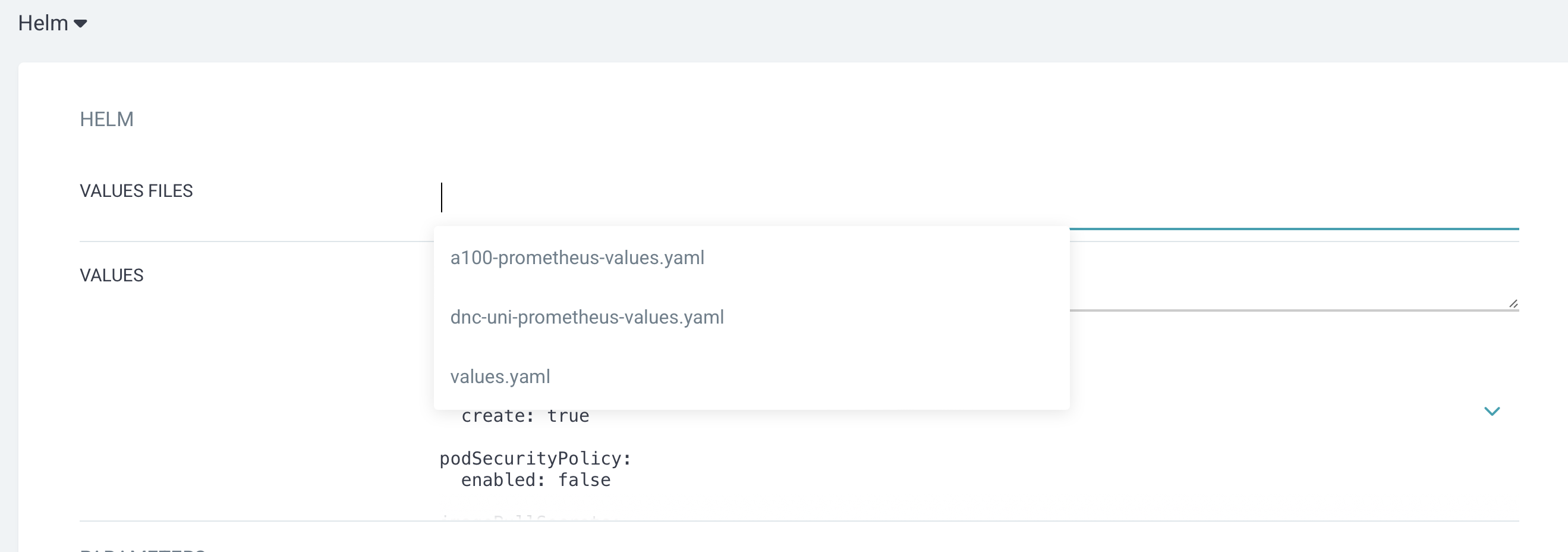
cli로 배포할 때 -f values를 지정하는 것처럼 적용 할 values.yaml을 적어준다.
현재 회사에서는 3개의 클러스터를 갖고 있기 때문에 각 클러스터에 맞게 변경한 values.yaml을 3개 갖고 있다. 그래서 추가 가능한 yaml파일이 3개 보이는 것이고 이중에서 모니터링 대상이 될 클러스터의 yaml을 선택해서 배포 진행하면 된다.
-
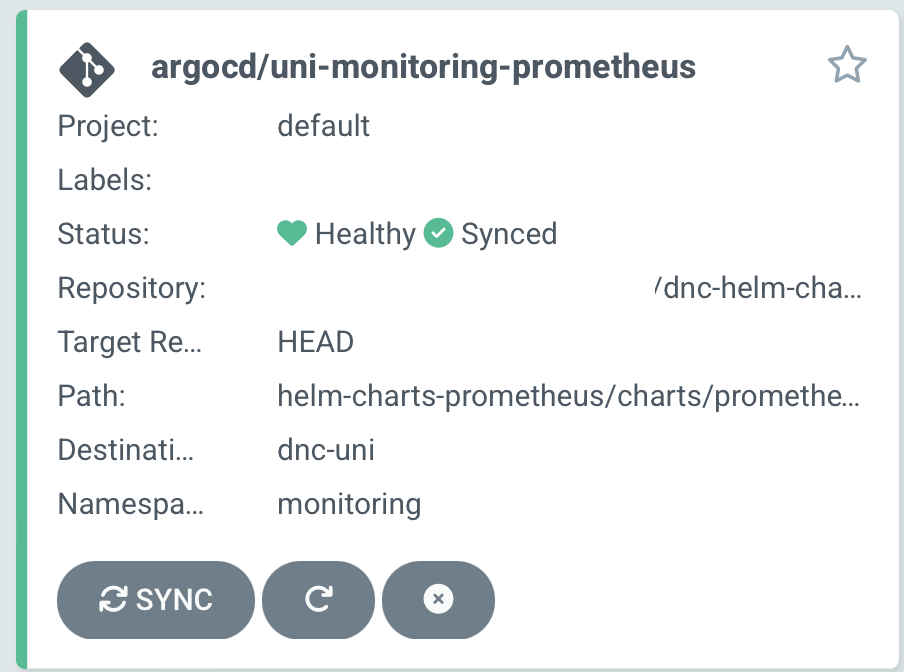
등록 된 Applications을 볼 수 있고 구성을 확인 할 수 있다.
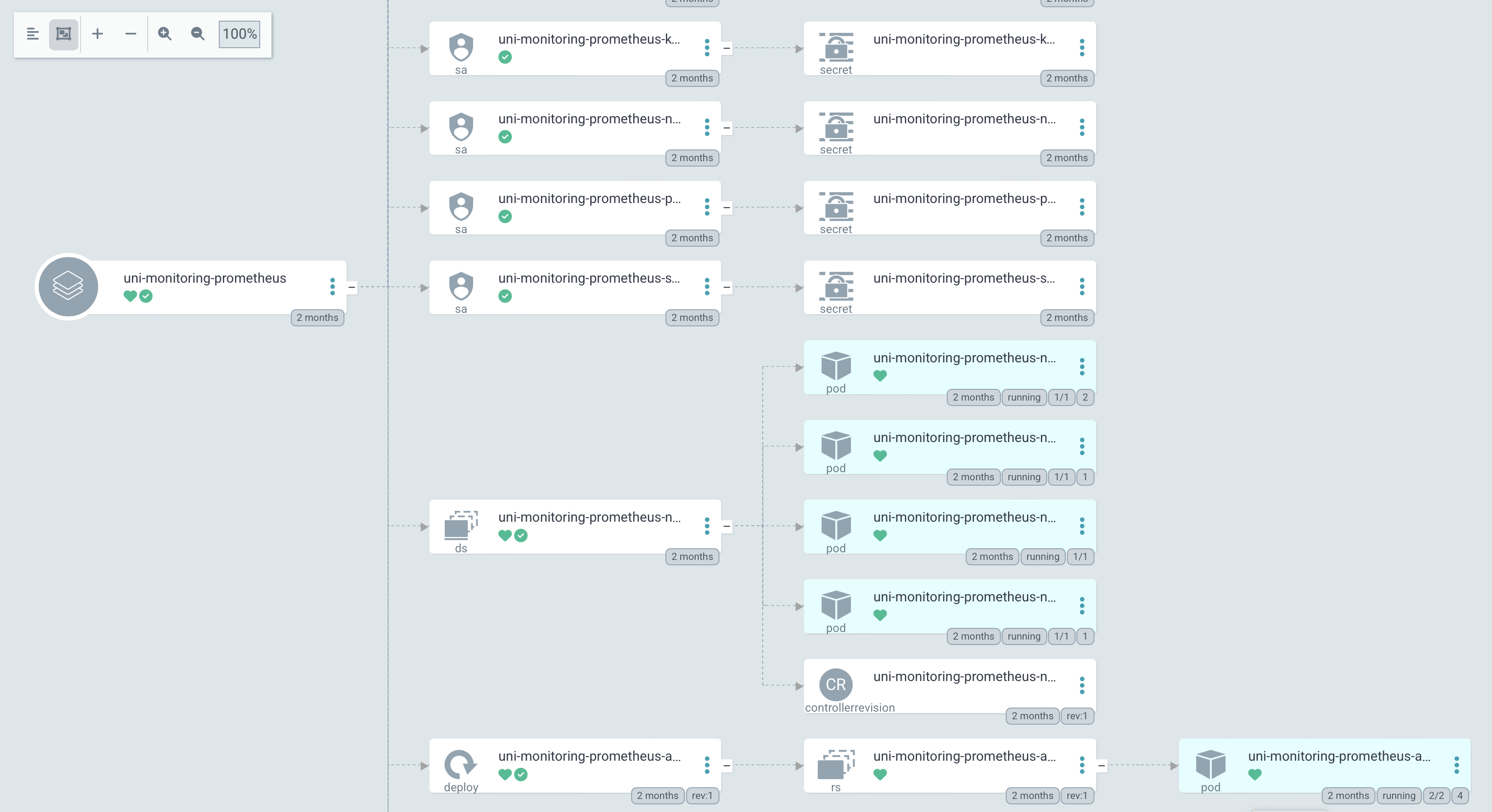
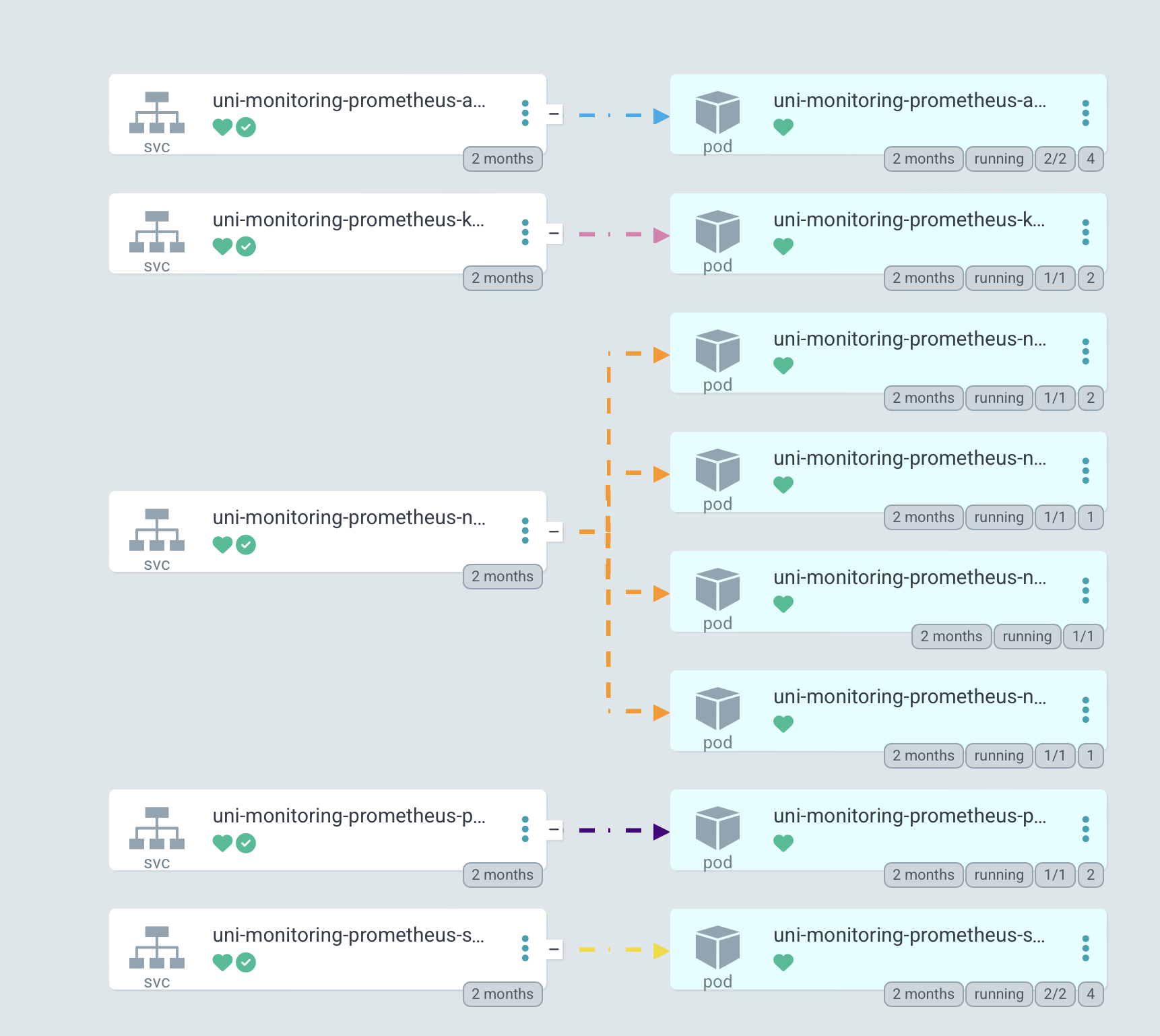
이렇게 2개의 방법으로 프로메테우스 헬름 차트를 배포하는 방법을 정리해 보았다.
CLI를 통해서 설치하는 방법과 ArgoCD 툴을 활용해서 배포하는 방법이였다.
환경에 맞춰서 배포하고 모니터링 환경을 구성하는걸 진행하면 좋을 것 같다.
3. 프로메테우스 화면 구성
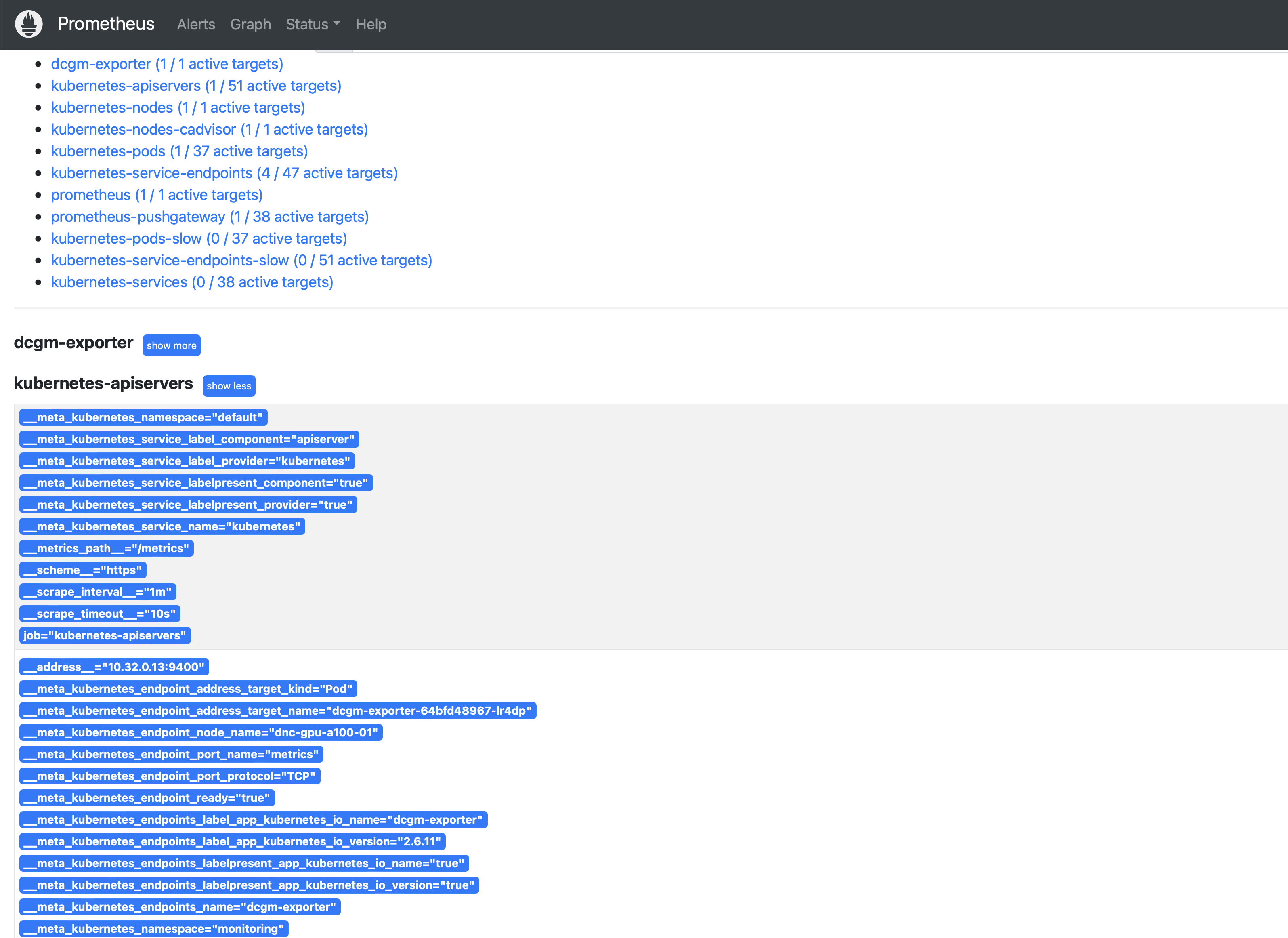
- 상단 메뉴바의 Status를 클릭하여 Tagets 목록을 선택하면 K8S 클러스터를구성하고 필요한 exporter를 설치한 환경의 정보들을 확인 할 수 있다.
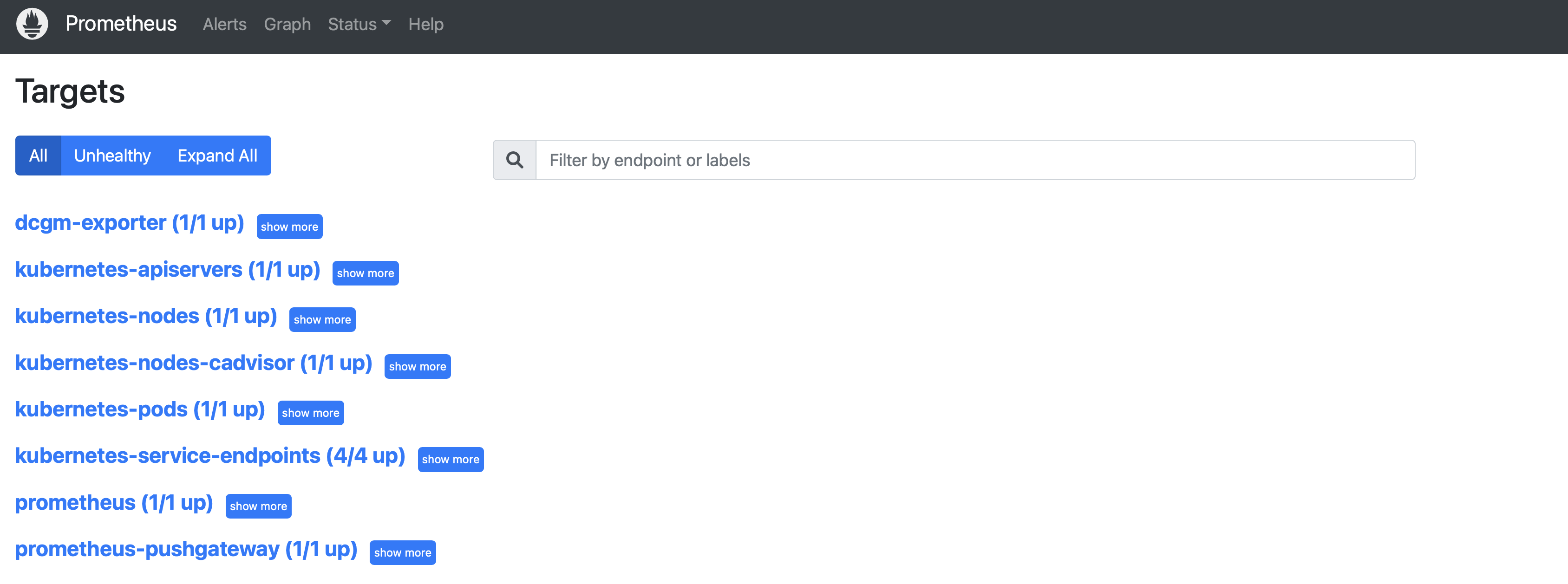
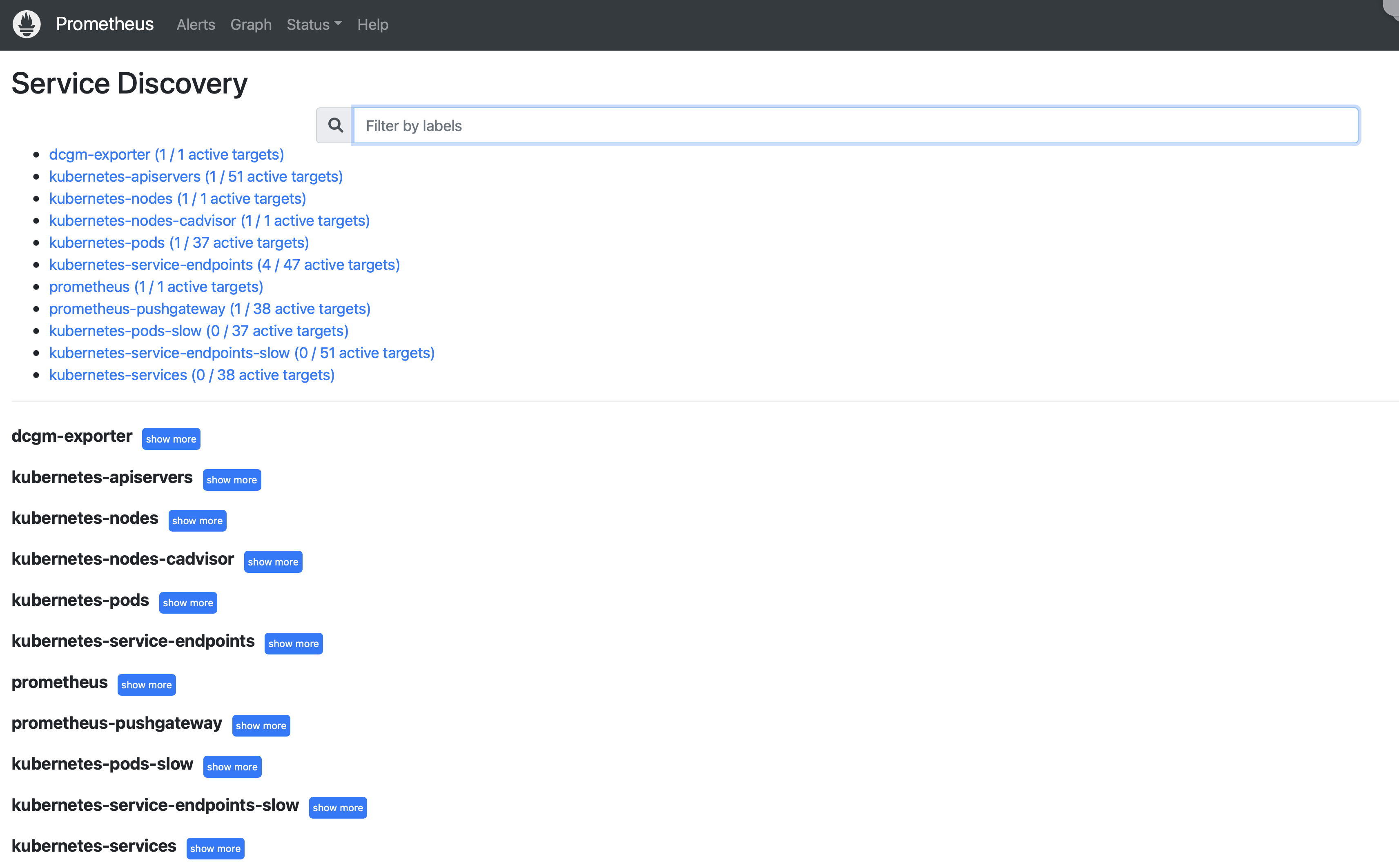
- Tagets 메뉴와 함께 Service Discovery가 있다. 서비스 디스커버리는 타겟 서버에 대한 정보를 가지고 오기 위한 설정이다
라벨을 통해 타겟 서버를 관리할 수 있다.
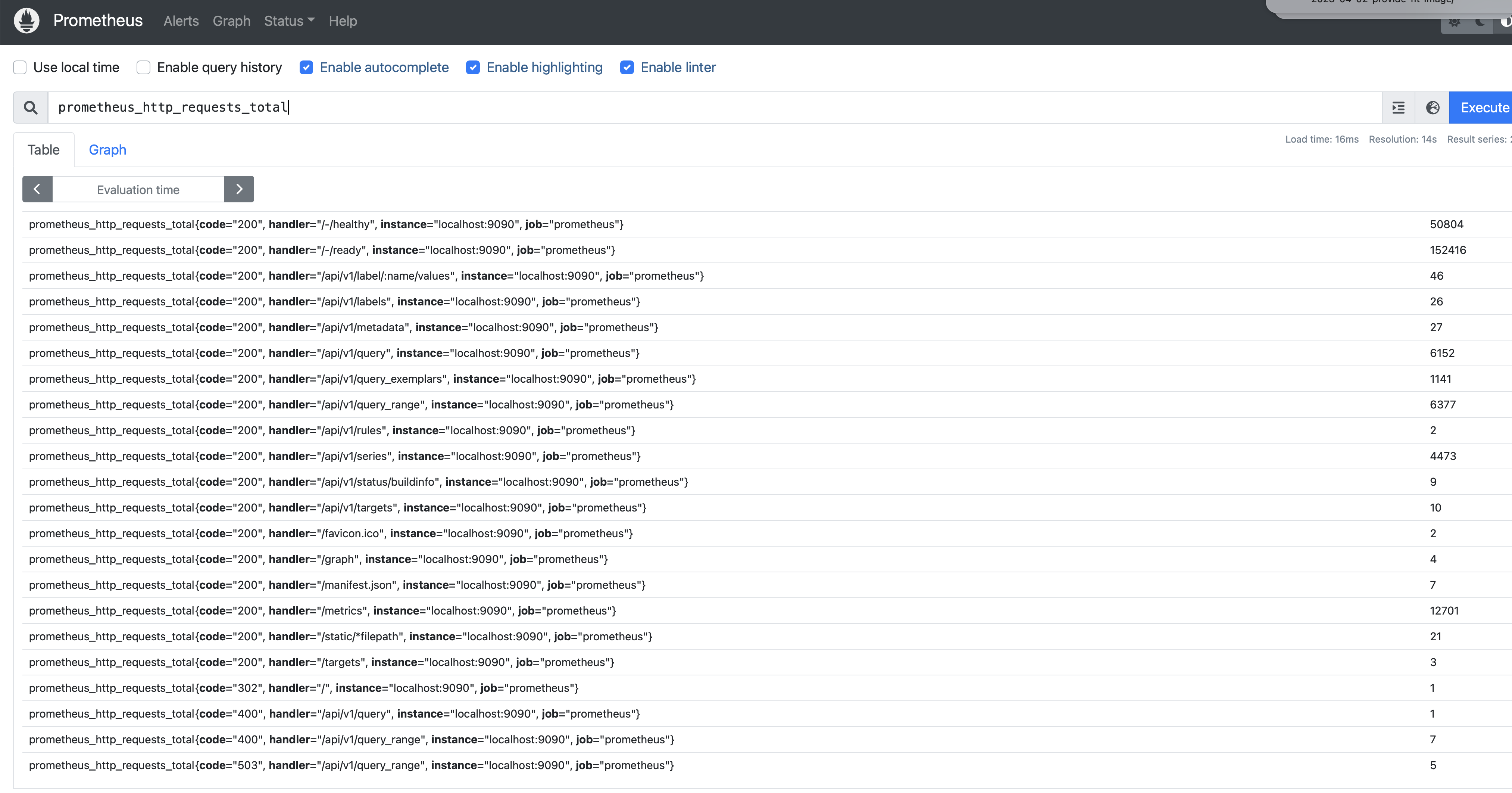
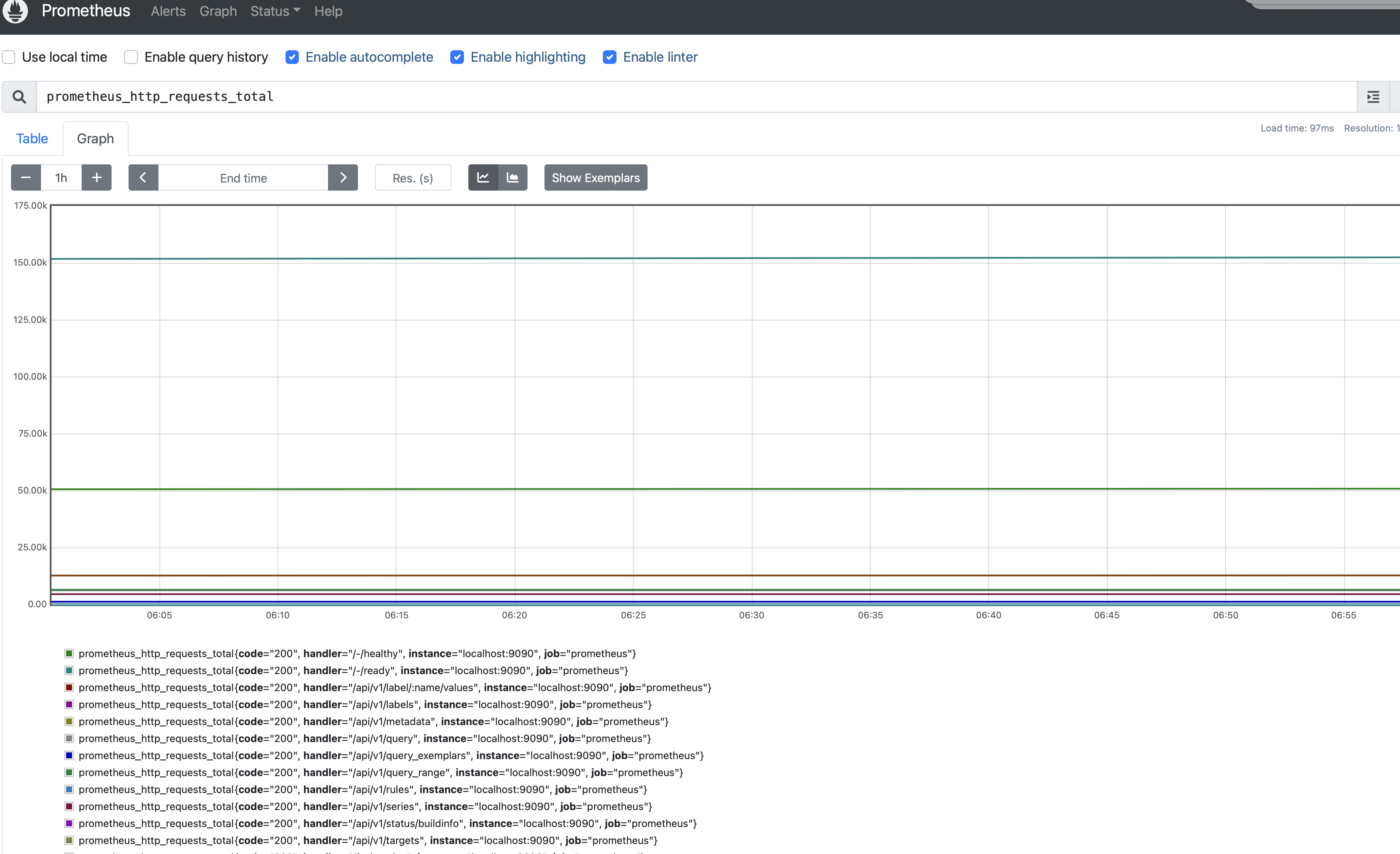
- PromQL 쿼리는 프로메테우스 서버가 얻어온 데이터들을 조회하고 테이블 & 그래프를 만들어서 확인을 한다.
기간과 간단한 수학 키워드를 활용해서 값을 도출해서 대시보드를 구성하여 확인 할 수 있다.
간단하게 모니터링 시스템 & 프로메테우스 소개 및 설치 방법에 대해서 정리해 보았다.
인프라 시스템을 운영하면 모니터링 시스템을 빼고는 운영을 할 순 없다. 다양한 방법 중에서 프로메테우스를 활용한 데이터 얻는 방법에 대해서 이번 포스팅을 정리하였고 다음 포스팅에선 프로메테우스를 통해서 얻어온 데이터를 웹 화면을 통해서 확인하고 특정 조건에서 Alert를 받아서 실시간으로 인프라 환경을 확인하고 컨트롤 할 수 있는 방법에 대해서 정리해 보도록 하겠다.
