기술 면접을 대비하여 자바 관련 예상 질문과 답변을 정리합니다.
절차 지향 프로그래밍이란?
절차지향은 순차적인 작업방식. C언어가 그런 방식.
한 데이터를 사용하는 프로시저(함수)가 많아질수록 그 데이터의 타입을 변경하기 어려워진다. 요구 사항 변경에 변경할 데이터를 사용하는 모든 프로시저들을 다 변경해야 해서 유지보수성이 굉장히 취약해지는 방식.
하지만 순차적인 방식으로 하는 프로그래밍 방식에는 적합하다. 머신러닝 방식이 그런 방식으로 알고 있다.
- <개발자가 반드시 알아야할 객체지향과 디자인 패턴> 발췌
OOP(객체 지향 프로그래밍)이란? -> 내가 생각하는 클린코드란?
객체를 통해 프로그램을 동작하는 방식. 여기서 객체는 현실의 물체를 의미함. 객체지향은 사람의 사고와 가장 비슷하게 한 프로그래밍 방식이라 생각.
사람이 살아가는 세상에 물체를 모델링해서 객체라는 구조체계로 만들고 그 객체들이 메서드(행위)를 가지고 서로 메시지(상태)를 전달해 협력하는 구조로 프로그래밍하는 형식.
그걸 객체 지향의 기술인 4가지 기술(캡.상.추.다)를 그리고 SOLID 원칙을 기준삼아 이의존성,결합도를 줄이고 응집도 있게 하여 코드의 재사용, 유지보수성을 용이하게 하게 프로그래밍함.
비즈니스적으로 구조화한 데이터들이 변하고 사용자들의 요구사항이 빈번할 때인 현재상황에 유지보수성을 용이하게 하는 객체지향프로그래밍 방식이 각광받는 것.
그에 반대되는 프로그래밍 방식은 절차지향임.
OOP의 특징
1) 추상화 : 모델링 ex. 도메인 클래스, 인터페이스
2) 캡슐화 : private 키워드로 데이터 노출을 줄이는 것, 인터페이스 사용
3) 상속 : 재사용성
4) 다형성 : 하위타입이 변경이 가능, 오버라이딩/로딩
객체지향을 위한 SOLID 원칙
1) SRP : 응집도 얘기. 한 클래스에 너무 많은 기능(메서드)들을 넣지 말라.
2) OCP : 추상화된 클래스, 인터페이스에 의존해 impl한 클래스들이 추가 확장에는 열려 있고 클라이언트 객체인 상위 클래스가 변하는 것에 하위 클래스들이 영향을 안받게 하는 것.
3) LSP : 하위타입이 대체되더라도 문제가 없어야 한다.
4) ISP : SRP랑 비슷. ISP에 너무 많은 기능(메서드)들을 넣지 말고 쪼개라.
5) DIP : OCP랑 비슷. 구체 클래스에 의존하지 말고 추상화된 클래스, 인터페이스에 의존해서 의존관계를 역전시키는 것.
자바 장점
-
자바 가상머신인 JVM위에서 동작하기 때문에 언어가 OS에 독립적임. <-> C언어
-
아파치, 스프링과 같은 자바를 지원하는 많은 오픈소스 프로그램이 존재해 단기간에 개발시간을 단축과 더불어 안정성 좋게 개발할 수 있다.
-
단점인 비교적 속도 느리다는 것이 이제는 하드웨어 성능이 워낙 압도적으로 좋아져서 무색한 말인 것 같다.
-
따로 동적 메모리 할당시, 해제를 개발자가 하지 않고 알아서 JVM의 GC(Garbage Collector)가 해준다.
자바 단점
-
언어적 불편함 : 대부분의 클래스 선언 등을 이름을 명사형으로만 강요되며 명사 외를 지양한다. 또한 외부 범위에서 변수를 함수 내부로 바인딩하는 기술인 클로저 기능이 미 지원된다. C언어에 있는 전역 변수 개념이랑 유사하다 본다. 자바 언어의 경우 전역, 지역 변수는 모두 클래스 내부에 캡슐화로 진행되기 때문이다.
-
실시간 응용 시스템에 부적합 :
가비지 컬렉션이언제 어떻게 작동될지는 아무도 모르기 때문에 중간에 끊김 현상이 발생할 수 있어서 실시간 응용 시스템으로는 부적합하다. -
Oracle사의 Java 유료화 : 본인은 프로그래밍 업데이트 지원이 유료화되는 것이 큰 타격이라 본다. 프로그래밍 언어가 본격적으로 유료화되면서 적은 금액이라도 프로젝트에 투입되는 인력 비용 + 프로그램 인프라 비용 등등이 부담이 될 수 있다.
자바의 특성
- 다형성
- 은닉성(캡슐화)
- 상속
Oracle JDK vs Open JDK
-
Oracle JDK : 폐쇄적인 상업 기반의 코드로 이루어짐, 재산권이 걸린 플러그인을 제공하고 있다 ex.Java Web Start 그리고 글꼴 라이브러리
-
Open JDK : 오픈소스 기반, 무료임.
옛날 자바 6에서는 Open JDK이 성능이나 안정성이 크게 떨어졌지만 현재에는 Oracle 제공하고 있는 일부 기능을 제외하고는 크게 차이가 없다.
메모리 영역?
method영역 : static이 붙은 변수/메서드(ex.main 메서드), 전역변수, class 정보들 저장.stack: 지역변수, 파라미터, 복귀주소값 저장heap: new 연산자를 통한 동적 할당 된 객체 저장. 가비지 컬렉션에 의해 관리.
JVM 의 역할?
JVM(Java virtual machine)은 자바를 실행하기 위한 가상 기계이다. 여기서 가상 기계란 말이 어색하다면 한다디로 가상 OS 라고 해석할 수 있겠다.
JVM은 Byte Code를 OS에 맞게 해석해주는 역할을 한다. Java Compiler가 java 파일을 컴파일을 하면 .class라는 java byte code로 변환시켜 주며, Byte Code는 기계어가 아니기 때문에 OS에서 바로 실행이 되지 않는다.
이 때 JVM이 OS가 이해할 수 있도록 이 byteCode를 (여기서 JIT 컴파일러+인터프리터) 기계어로 해석해준다.
Class loader란?
자바 클래스들은 시작 시 한번에 로드되지 않고, 애플리케이션에서 필요할 때 로드된다. 클래스 로더는 JRE의 일부로써 런타임에 클래스를 동적으로 JVM에 로드 하는 역할을 수행하는 모듈이다. 자바의 클래스들은 자바 프로세스가 새로 초기화되면 클래스로더가 차례차례 로딩되며 작동한다.
ClassLoader 쉽게 이해하기
클래스 로더를 쉽게 이해하기 위해 책을 읽는 과정에 비유해 볼게요!
우리가 아주 두꺼운 책을 처음부터 끝까지 한 번에 다 읽지 않죠? 보통 필요한 부분만 찾아서 읽거나, 순서대로 읽더라도 앞부분을 읽고 나서야 다음 페이지를 펼쳐보는 것처럼요.
자바 프로그램도 마찬가지예요. 프로그램이 시작될 때 모든 코드를 한 번에 다 불러오는 게 아니라, 필요한 순간에 필요한 코드 조각 (클래스)만 JVM (자바 가상 머신)이라는 실행 환경으로 가져오는 역할을 하는 것이 바로 클래스 로더 (Class Loader) 입니다.
클래스 로더는 JRE (자바 실행 환경)의 일부로, 마치 도서관 사서처럼 필요한 클래스를 찾아서 JVM이라는 책상 위에 올려주는 역할을 한다고 생각하시면 돼요.
자바 프로그램이 처음 실행될 때, 클래스 로더들이 순서대로 필요한 클래스들을 JVM으로 가져오면서 프로그램이 작동하게 됩니다. 마치 책의 첫 페이지부터 필요한 내용을 순서대로 읽어나가는 것처럼요.
이제 좀 더 구체적으로 클래스 로더의 종류를 살펴볼까요?
1. 부트스트랩 클래스로더 (Bootstrap ClassLoader) - "책의 기본 재료 준비 담당"
- 역할: JVM이 처음 시작될 때 가장 먼저 실행되는 특별한 클래스 로더입니다. 얘는 직접 자바 클래스를 로드하는 게 아니라, 자바 클래스를 로드할 수 있는 기본적인 도구와 아주 기본적인 자바 클래스들 (예:
java.lang.Object,Class,ClassLoader- 모든 자바 클래스의 조상, 클래스 정보를 담는 클래스, 클래스를 로드하는 클래스) 만을 로드합니다. - 비유: 마치 책을 만들기 위한 종이, 잉크, 제본 도구 같은 기본적인 재료들을 준비하는 역할이라고 생각하시면 돼요. 이 기본적인 것들이 있어야 다른 책 내용도 담을 수 있겠죠?
2. 확장 클래스로더 (Extension ClassLoader) - "추가 기능 모듈 담당"
- 역할: 부트스트랩 클래스로더의 "자식" 같은 존재예요. 얘는 자바의 확장 기능들을 담고 있는 클래스들을 로드합니다. 예를 들어, 특정 기능을 제공하는 표준 라이브러리 같은 것들이죠.
- 찾는 위치: 주로 특정 폴더 (
JAVA_HOME/jre/lib/ext)에 있는.jar파일 형태의 클래스들을 찾아서 로드합니다. 마치 책에 추가적인 챕터나 부록 같은 확장 기능을 더해주는 역할이라고 생각하시면 돼요.
3. 애플리케이션 클래스로더 (Application ClassLoader) - "내가 만든 책 내용 담당"
- 역할: 우리가 실제로 개발한 자바 애플리케이션의 클래스들과, 우리가 사용하기 위해 추가한 외부 라이브러리 (
.jar파일)들을 로드하는 역할을 합니다. - 찾는 위치: 우리가 프로그램을 실행할 때 지정하는 Classpath 라는 경로에 있는 클래스 파일이나
.jar파일들을 찾아서 로드합니다. 마치 우리가 직접 쓴 책의 내용과, 우리가 참고하기 위해 가져온 다른 책들을 읽어오는 역할이라고 생각하시면 됩니다.
핵심 정리:
- 클래스 로더는 필요할 때 클래스를 JVM으로 동적으로 가져오는 역할을 합니다. (책을 처음부터 다 읽지 않고 필요한 부분만 읽는 것과 같아요!)
- 부트스트랩 클래스로더는 JVM 작동에 필요한 기본적인 재료를 준비합니다.
- 확장 클래스로더는 자바의 추가적인 기능 모듈을 로드합니다.
- 애플리케이션 클래스로더는 우리가 만든 애플리케이션 코드와 외부 라이브러리를 로드합니다.
이렇게 이해하시면 클래스 로더가 더 이상 추상적으로 느껴지지 않고, 자바 프로그램이 어떻게 실행되는지 조금 더 명확하게 이해하실 수 있을 거예요!
자바의 GC에 대해
1. GC의 기본 원리:
- JVM은 더 이상 사용되지 않는 객체를 자동으로 회수하여 메모리를 관리합니다.
- GC의 주요 대상 영역은 힙(Heap) 영역입니다.
- 객체의 Reachability (GC Root로부터의 참조 가능성)를 기준으로 살아있는 객체와 쓰레기 객체를 구분합니다.
2. 힙 영역의 구조:
- Young Generation (Young Gen): 새롭게 생성된 객체들이 위치하는 영역입니다.
- Eden: 처음 객체가 할당되는 공간입니다.
- Survivor 0 (S0), Survivor 1 (S1): Eden 영역에서 살아남은 객체들이 이동하는 공간입니다. 두 개의 Survivor 영역 중 하나는 항상 비어있습니다.
- Old Generation (Old Gen): Young Gen에서 여러 번의 GC 후에도 살아남은 오래된 객체들이 이동하는 영역입니다.
3. GC 종류 및 처리 과정:
- Minor GC (Young GC): Young Gen 영역에서 발생하는 GC입니다.
- 새로운 객체는 Eden 영역에 할당됩니다.
- Eden 영역이 꽉 차면 Minor GC가 발생합니다.
- Eden 영역과 현재 사용 중인 Survivor 영역(S0 또는 S1)에서 살아남은 객체는 다른 Survivor 영역으로 이동합니다.
- 이때, 객체의 age (GC 생존 횟수)가 증가합니다.
- Minor GC는 비교적 자주 발생하며, Stop-The-World (STW) 시간이 짧습니다.
- Major GC (Old GC) / Full GC: Old Gen 영역에서 발생하는 GC입니다.
- Old Gen 영역이 꽉 차거나, Minor GC 후에도 Old Gen으로 이동할 공간이 부족하면 Major GC가 발생합니다.
- Major GC는 전체 힙 영역을 대상으로 수행되므로 STW 시간이 길고 애플리케이션 성능에 큰 영향을 줄 수 있습니다.
- GC 종류별 특징:
- Serial GC: 싱글 스레드로 Minor GC와 Full GC를 순차적으로 처리합니다. 단순하지만 성능이 낮습니다.
- Parallel GC: 여러 스레드를 사용하여 Minor GC를 병렬로 처리하여 성능을 향상시킵니다. Full GC는 Serial GC와 동일하게 동작합니다.
- CMS (Concurrent Mark-Sweep) GC: STW 시간을 최소화하기 위해 Mark와 Sweep 단계를 동시에 수행하려고 시도합니다. 메모리 파편화 문제가 발생할 수 있습니다.
- G1 (Garbage-First) GC: Young Gen과 Old Gen을 Region 단위로 나누어 관리하며, STW 시간을 줄이고 높은 처리량을 목표로 합니다. 현재 Java의 기본 GC입니다.
- ZGC (Z Garbage Collector): 낮은 지연 시간(low-latency)을 목표로 하는 GC입니다. STW 시간을 매우 짧게 유지하며, 큰 힙 크기 환경에 적합합니다.
4. 객체의 생존 주기:
- 새로운 객체는 Eden 영역에 생성됩니다.
- Minor GC가 발생할 때마다 살아남은 객체는 Survivor 영역으로 이동하며 age가 증가합니다.
- 일정 age 이상이 된 객체는 Old Gen 영역으로 이동합니다.
- Old Gen 영역이 꽉 차면 Major GC가 발생합니다.
- 어떤 GC에서도 살아남지 못한 객체는 메모리에서 해제됩니다.
https://velog.io/@mooh2jj/JVM-GC의-처리-과정
클래스 vs 객체
클래스: 객체를 정의하는 틀 또는 설계도와 같은 의미로 사용객체: 클래스 정의를 기반으로 실제로 메모리에 올라온 상태. new로 생성된 객체, 인스턴스라 불린다.
객체란?
원래 의미는 식별 가능한 개체 또는 사물이라는 뜻. 객체는 구별 가능한 식별자, 특징적인 행동, 변경 가능한 상태를 가지며 이 상태들을 관장하고 책임을 져야 한다.(객체 지향과 사실과 오해)자바의 main문
자바로 만든 모든 프로그램의 공통된 특징은 main문이 있으며 그곳에서 시작된다는 점.
main문을 가진 클래스는 context 즉, 객체들의 heap 정보를 가지고 있다. (by 메타코딩)
자바 Interpreter -> JIT Compiler
Java는 초기 개발 단계에서 인터프리터(Interpreter) 방식으로 동작했지만, 이후에 성능 개선을 위해 JIT(Just-In-Time) 컴파일러를 도입하며 발전했습니다.
Interpreter: 초기에 Java는 바이트코드를 하나씩 해석하여 실행하는 인터프리터 방식을 사용했습니다. 이렇게 하면 플랫폼 독립성이 보장되지만, 실행 속도가 느리다는 단점이 있었습니다.
JIT Compiler: 성능 문제를 해결하기 위해 JVM(Java Virtual Machine)은 JIT 컴파일러를 도입했습니다. JIT 컴파일러는 프로그램 실행 중에 자주 사용되는 바이트코드를 기계어로 변환하여 캐싱합니다. 이로 인해 동일한 코드가 반복 실행될 때 더 빠르게 수행될 수 있습니다.
Primitive type vs Reference type
-
기본형 (primitive): stack 메모리 영역에실제 값을 저장하는 데이터 타입. byte, short, int, long, float, doublle, char, boolean / call by vaue 호출 방식을 사용함. -
참조형 (reference): stack 메모리 영역에 객체가 있는주소값을 저장하는 데이터 타입. String, 클래스, 인터페이스 등이 그렇다. new 연산자로 정의. 실제 값은 heap에 저장되고 stack에는 메모리 주소만 저장하는 걸 잊지 말자. call by reference 호출 방식을 사용함.
사실은 자바는 엄연히 call by vaue 호출 방식으로 사용할 뿐이다.
왜 스레드는 stack만 독립적인 메모리 공간을 가지고 있는가?
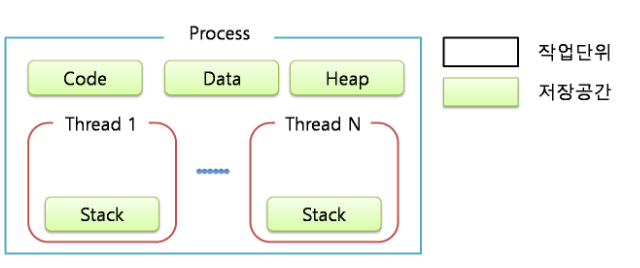
스택은 함수를 호출할시 사용한 파라미터, PC값(복귀주소값), 지역변수가 저장되는데 쓰레드함수가 호출하고 그역할이 끝나면 복귀하기 위해 stack을 독립적으로 가져야 한다.
스레드의 장단점
장점)
- 응답성 증가 : 프로그램의 일부분(스레드)이 중단되거나 긴 작업을 수행하더라도 프로그램의 수행이 계속되어 사용자에 응답성이 증가한다.
- 경제성 증가 : 프로세스 내의 자원을 공유하여 메모리와 시스템 자원을 경제적으로 사용할 수 있다.
- 쓰레드 사이의 작업량이 상대적으로 작아 Context Switching이 빠릅니다.(시스템 처리량 증가-처리비용 감소)
- 독립적인 프로세스에 비해 공유 메모리만큼의 시간, 자원 손실이 감소하여 전역변수와 정적변수에 대해 공유 가능
단점)
- 오류로 인해 하나의 스레드가 종료되면 전체 스레드가 종료될 수 있다.
- 동기화 작업(뮤텍스, 세마포어)을 통해 스레드의 처리순서와 공유자원에 대한 처리를 할 때 병목현상을 발생시켜 성능이 저하 될 수 있다.
- Context Switching, 동기화 등의 이유 때문에 싱글 코어 멀티 쓰레딩은 쓰레드 생성 시간이 오래걸려 오히려 오버헤드로 작용할 수 있다.
- 안전성 문제. 하나의스레드가 데이터 공간을 망가뜨리면, 모든 스레드가 작동 불능 상태-> 이는 임계구역(Critical Section 기법으로 예방/해결할 수 있다.
Process vs Thread
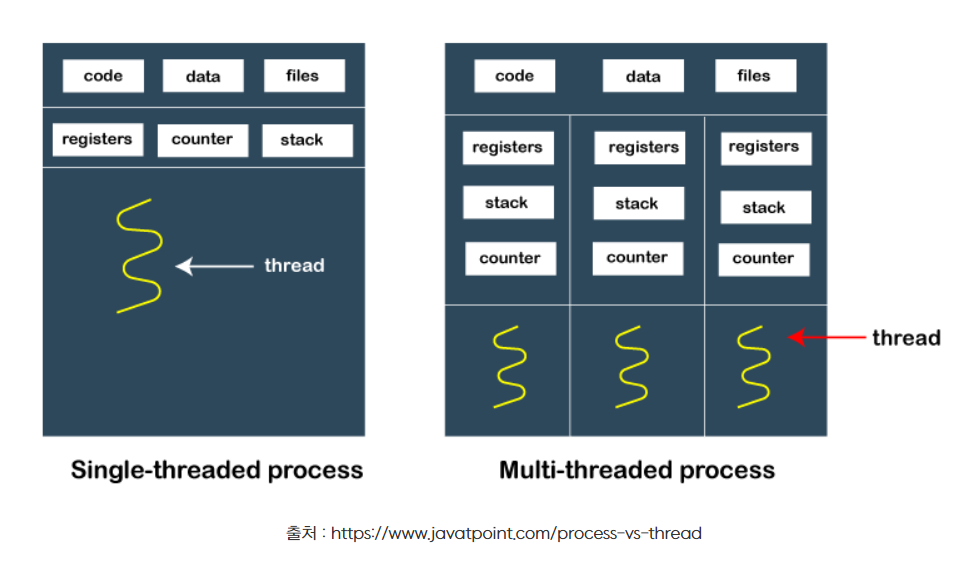
- Process : disk에 있는 프로그램이 cpu가 연산, 즉, 컴파일하여 메모리의 로드된 프로그램 상태
- Thread : 그 프로세스 안 있는 cpu의 최소 작업(실행) 단위이다.
이 둘의 차이는 "메모리 공유"이다.
process는 os에게 독립적인 메모리공간을 할당받는다. 반대로 Thread는 stack을 제외하고 나머지 메모리공간(method, Heap)을 공유해서 context swiching에서 overhead가 적다는 이점이 있다.
단점은 공유하는 영역이 많아(Code, Heap, Data 부분) 여러 스레드가 많은(멀티스레드) 환경에서는 공유변수에 스레드가 변경할 이슈가 생기는 동시성 이슈가 생겨 결과값이 예상과 달라질 수 있다는 점이다.
동시성과 병렬성 차이
둘 다 멀티 스레드의 동작 방식이라는 점은 동일하지만 목적이 다르다.
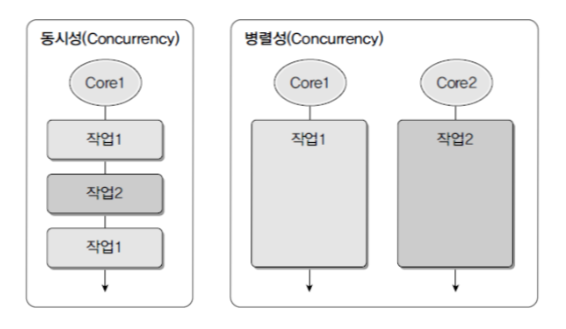
-
동시성(Concurrency)
멀티 작업을 위해 멀티 스레드가 번갈아가며 실행하는 성질이다. 싱글 코어 CPU를 이용한 멀티 작업은 병렬적으로 실행되는 것처럼 보이지만 실제로는 동시성 작업이다. -
병렬성(Parallelism)
병렬성은 멀티 작업을 위해 멀티 코어를 이용해 동시에 실행하는 성질이다.
가비지 컬렉션?
Heap 영역에서 시스템에서 더 이상 사용하지 않는 동적 할당된 메모리 블록을 찾아 다시 사용 가능한 자원으로 회수하는 것. 자동으로 이루어지므로 따로 개발자가 메모리 영역을 관리할 필요 없음.
객체란?
클래스가 메모리에 로드되어 컴파일된 것을 말함. 클래스가 실체화된 것.
클래스/인스턴스란?
- 클래스 : 설계도, 틀. 클래스를 통해서 인스턴스 객체 생성 가능.
- 인스턴스 : 객체가 메모리에 할당되어 실제 메모리를 차지 하는 것.
클래스변수 vs 인스턴스변수 vs 전역변수 vs 지역변수
- 클래스변수(
Method영역-클래스 변수) : 함수 바깥에 선언하여 클래스 전체에서 사용가능한 변수. 여러 메소드에서 공통적으로 사용 가능. - 인스턴스변수(
heap영역) : 객체 생성 후 메서드 내 지역변수에 들어갈 수 있는 변수 - 파라미터, 전달인자(알규먼트) : : 메서드가 호출될 때 생명이 시작되고, 메서드가 끝나면 소멸. 단, 호출한 메서드에서 넘겨준 레퍼런스자료형은 그대로 살아 남는다.
- 지역변수(
Stack영역-메서드 안에 변수) : 함수 속에서 선언하여 해당 함수 속에서만 사용가능한 변수. 선언한 메서드가 끝나면 자동으로 소멸.
Wrapper클레스란?
포장객체라 불린다. 기본타임(byte,char,short,int,long,float,double,boolean)을 객체로 생성하는 클레스이다.
Byte, Character, String, Short, Integer, Long, Float, Double, Boolean 들이 있다.
Wrapper클래스는 불변객체로써 값을 변경할 수가 없다.
형변환시,
- Wrapper 객체 <- 기본타입 : Boxing(감싸)
- 기본타입 <- Wrapper 객체 : Unboxing(풀어내)
int obj = 0;
Integer obj1 = (Integer) obj; // 명시적 변환, 박싱, null 초기화 가능
int value = obj1; // 묵시적 변환, 언박싱
// 박싱, 언박싱에도 자동형변환이 가능하다.static 의미?
정적 멤버 (static) : 메모리 공간 할당 시 처음 설정된 메모리 공간이 변하지 않는 것. 프로그램이 끝날 때까지 계속 상주함.
객체를 생성하지 않고도 사용할 수 있는 필드와 메소드.
객체마다 가지고 있을 필요가 없는 공용적인 데이터라면 static으로 선언.
객체 생성을 하지 않고 사용 가능하기 때문에 객체에서 호출불가능.
주의할 점)
Garbage Collector의 관리 영역 밖에 존재하므로 Static을 자주 사용하면
프로그램의 종료시까지 메모리가 할당된 채로 존재하므로 자주 사용하게 되면 시스템의 퍼포먼스에 악영향(메모리 누수)을 주게 된다.
자바의 메모리 누수
메모리 누수 또는 릭(Memory Leak): 프로그램이 필요하지 않은 메모리를 계속 점유하고 있는 현상
자바에서 메모리 누수는 더이상 사용하지 않는 객체가 가비지 컬렉션(GC)에 의해서 회수되지 않고 계속 누적되는 현상.
Old 영역에 누적된 객체로 인해서 메이저 GC가 빈번하게 발생하게 되고, 프로그램의 응답속도가 늦어지다. 결국 OOM(OutOfMemory) 오류로 프로그램이 종료됩니다.
주로 빈번한 전역변수의 선언(static)이나, List나 HashMap 같은 콜렉션에 저장한 객체를 해제하지 않고 계속 유지하게 되면서 주로 발생합니다.
출처: https://118k.tistory.com/608 [개발자로 살아남기:티스토리]
자바의 메모리 누수 예제
- Integer, Long 같은 래퍼 클래스(Wrapper)를 이용하여, 무의미한 객체를 생성하는 경우
- 컬렉션에 캐쉬 데이터를 선언하고 해제하지 않는 경우
- 스트림 객체를 사용하고 닫지 않는 경우
- 컬렉션(Map)의 키를 사용자 객체로 정의하면서 equals(), hashcode()를 재정의 하지 않아서 같은 키로 착각하여 데이터가 계속 쌓이게 되는 경우
- 맵의 키를 사용자 객체로 정의하면서 equals(), hashcode()를 재정의 하였지만, 키값이 불변(Immutable) 데이터가 아니라서 데이터 비교시 계속 변하게 되는 경우
- 자료구조를 생성하여 사용하면서, 구현 오류로 인해 메모리를 해제하지 않는 경우
- Connection 객체, Driver 객체 try~catch finally 객체.close()를 안해줘서 리소스가 흘러가게 되는 경우,
출처: https://118k.tistory.com/608 [개발자로 살아남기:티스토리]
static 에 public, final을 붙이는 이유
static은 주로 상수(final)화 시키는데 많이 쓰인다. (주의할 점은 상수화란 건 초기화가 필수이다. 그래서 static만 붙인다고 상수가 아니다!)
다른 클래스에도 사용할 수 있게 public을 붙여서 사용하는 경우가 많다!
final 키워드를 사용하는 이유
final 키워드를 붙이면 무언가를 정의하는 것이 안된다라는 의미를 가진다. 이 키워드는 변수, 메서드, 클래스에 final을 붙일 수 있고 각각의 의미는 다음과 같다.
- 변수(variable): 이 변수는
수정할 수 없다는 의미를 가집니다.(상수화)
만약 초기화하지 않고 final이 붙어있다면컴파일에러가 납니다. - 메서드(method): override를 제한하게 됩니다.
- 클래스(Class): 상속 불가능 클래스가 됩니다.
Enum 이란?
`헷갈리는 부분
1) Enum은 상수가 아니다! 정확히는 상수의 열거타입이다.
enum 자체로 보면 상수들의 모음이기 때문에 상수가 계속 바뀔 수 있기에 enum 자체를 상수라고 표현하면 안된다.
2) Enum 존재 자체가 Thread-safe하다는 걸로 오해하면 안된다. 나중에 바뀔 수 있는 값이 Thrad-safe 할리가 없다.
단순히 initialization에서는 Thrad-safe할 수 있겠지만, 그 뒤부턴 보장이 안된다.(상수가 아니기에!)
메모리 상수풀 영역이란?
힙영역 내 Perm(영구적) 영역에 생성되어 자바 프로세스 종료까지 계속 유지되는 메모리영역이다.
기본적으로 JVM에서 관리하며 프로그래머가 작성한 상수에 대해 최우선적으로 찾아보고 없으면 상수풀에 추가한 이후 그 주소값을 리턴한다. 그로 인해 메모리 절약 효과가 있는 것이다.
String의 리터럴 방식을 사용하여 생성할 경우 상수풀 영역에 등록한다.
super()의 의미는?
자식클래스의 생성자 안에 부모클래스 생성자를 적지않아도 자동실행이 되는 생성자가 있다.
그 자동실행되는 부모의 생성자가 super()이며, 매개변수 없는 생성자가 실행되는 것이다.(안써도 무방하다.)
그러나, 부모의 생성자 중 매개변수 있는 생성자가 실행되도록 해야 하려면 super(arg1, arg2, ...) 를 반드시 써서 매개변수를 넣어주어야 한다.
volatile
volaite : 변수에 붙이는 키워드, 이 키워드를 변수에 붙이면, 스레드가 cpu내 캐시에 있는 변수를 재사용안하고 메인메모리에 참조하게 되고 최신화된 데이터만 접근할 수 있다.
transient
transient 예약어를 사용하여 선언한 변수는 Serializable의 대상에서 제외된다.
그러면 뭐하러 이것을 사용하나 싶을 수 있지만, 패스워드와 같이 보안상 중요한 변수나 꼭 저장해야 할 필요가 없는 변수에 대해서는 transient를 사용할 수 있습니다.
String vs StringBuffer vs StringBuilder
String은 new 연산자를 통해 생성되면 인스턴스 메모리 공간이 절대 변하지 않으므로 +, concat과 같은 연산시 메모리의 내용이 변하는 것이 아니라 새로운 String 인스턴스가 생성됨. 이렇게 새로운 문자열이 만들어지면 기본의 문자열은 가비지 콜렉터에 의해 제거되야 함. 문자열 연산이 많아지는 경우 성능이 떨어짐. 하지만 불변하기 때문에 조회가 빠르고 멀티스레드 환경에서 동기화를 신경 쓸 필요 없음.
가변(mutable)객체인 StringBuffer나 StringBuilder의 값들은 변하기 때문에 append()메서드를 통해 계속 값을 갱신할 수 있다. 내부적으로 문자열 편집을 위한 Buffer(버퍼)가 존재하기 때문이다.
즉, 한 번만 만들고 메모리의 값을 변경시켜서 문자열을 변경할 수 있다 그러므로 문자열 연산이 String을 쓸 때보다 자주 사용하면 좋다.
그러나 StringBuffer은 멀티 스레드 환경에서 synchronize 키워드가 가능하므로 동기화가 가능, 멀티 스레드 환경에서 적합하다.
StringBuilder는 synchronize 키워드가 없어 동기화를 지원하지 않기 때문에 단일 스레드 환경에서만 적합하다. 하지만 synchronize 키워드가 없기에 연산 속도가 가장 빠르다.
https://velog.io/@mooh2jj/String-말고-StringBuffer-StringBuilder
접근제한자
1) private : 같은 클래스에서만 접근 가능
2) default : 같은 패키지에서만 접근 가능
3) protected : 같은 패키지 + 다른 패키지(상속받으면)
4) public : 같은 프로젝트 어디서든 접근 가능
-
접근 가능 순서
private < default < protected < public -
접근 제한자를 사용하는 이유는 외부에 보여주고 싶은 정보들을 선택적으로 제공하기 위함이며, 자바의 특성 중
캡슐화와 통하는 면이 있다.
추상 클래스란?
추상 메소드를 하나 이상 가진 클래스
자식 클래스에게 강제성 부여 가능. 이를 통해서 기능 확장 가능.
직접적으로 객체 생성이 불가능하고 클래스를 상속 받아서 오버라이딩하여 사용해야 함.
- 일반 클래스와의 차이
객체화 가능 여부: 추상 클래스는 불가, 일반 클래스는 가능
인터페이스란?
모든 메서드가 구현부가 없는 추상메서드로 이루어진 클래스
ex) 키보드. 키보드를 누른다 라는 행위는 같지만 엔터/스페이스바를 눌렀을 때의 결과는 다름. 메소드는 같지만 동작 방식은 다르게 다형성을 주고 싶은 경우 사용.
협업시 객체의 내부 구조(구현부)를 모르더라도 인터페이스의 메서드 명만 알면 사용 가능 = 협업에 유리.
interface, implements, abstract pubilc 메소드, public static final 상수
다중 상속(구현) 가능. ex. interface extends interface1, interface2
추상 클래스와 인터페이스의 공통점과 차이점은 ?
둘 다 서로 하위 클래스에게 공통적으로 사용하는 방식을 뽑아 전달하는 객체들인 공통점이 있다.
그러나 목적이 다르다. 추상 클래스는 추상 메서드를 자식 클레스가 구체화해서 기능 확장에 목적이 있지만,
인터페이스는 서로 관련이 없는 클래스에게 공통적으로 사용하는 방식이 필요하지만 기능을 각각 모두 반드시 구현케 하는 경우에 사용한다.
그리고 추상 클래스는 단일 상속, 인터페이스는 다중 상속 가능하다.
그외 차이
추상클래스: 클래스, 필드값(변수) 설정/메서드 내부 코딩 가능, 상속을 통한재사용/기능확장 목적이 큼인터페이스:클래스x, 필드값 설정 불가(상수만 가능), 메서드(기능) 이름만 지정 가능, 기능 명세화,강제구현, 컴포지션 등 추상화에 의존하는 하는 방식의 대표 객체
오버라이딩 vs 오버로딩
-
오버라이딩 : 상속에서 나온 개념. 부모 클래스의 메소드를 자식 클래스의 메소드로 재정의 하는 것. 기능의 확장을 위해서 사용함.
런타임 다형성이라고 부름.
추가로, @Override 어노테이션은 꼭 써주면 좋다. 컴파일 타임에 오버라이딩에 대한 안정성을 부여해 주기 때문이다. -
오버로딩 : 같은 클래스 내에서
같은 이름의 메소드를 여러개 정의 하는 것(메서드 시그니쳐)으로 매개변수의 타입이 다르거나 개수가 다름. return 타입과 접근 제한자는 영향 없음.컴파일 다형성이라고 부름
다형성이란?
하나의 클래스나 함수가 다양한 방식으로 동작 가능 한 것. 오버라이딩과 오버로딩을 통해서 다형성 구현 가능.
ex) 게임 > 다양한 캐릭터들에 대해서 동일한 버튼을 클릭해서 다른 스킬을 사용하게 하는 것.
캡슐화(은닉성)이란?
데이터 보호, 불필요한 부분은 감출 수 있음.
클래스내 상태정보들은 private로 은닉하고 getter/setter 같은 메서드는 pulbic 을 붙여, 이 메서드로만 접근할 수 있게 하는 것.
상속이란?
부모 클래스가 가지고 있는 상수, 메소드를 자식 클래스에서 물려 받아 같이 공유하면서 확장하는 것
자식 클래스의 부모 클래스 오버라이딩
코드 중복 방지, 공통적인 코드 변경 할 때 시간 단축 가능.
상속 vs 다형성
-
상속 : 기본적으로 클래스에서 구현,
단일 상속, 다중 상속 등의 방식을 씀. -
다형성 : 기본적으로 함수(메소드)에서 구현,
컴파일 타임 다형성 (오버로딩) 과 런타임 다형성 (오버라이드)의 방식을 씀.
상속 vs 컴포지션
상속은 재사용으로 확장 기능으로 유용하지만, 상위클래스가 릴리스(업데이트)때마다 내부 구현이 달라질 수 있으며, 그 여파로 하위 클래스가 오동작, 유지보수가 쉽지 않아진다.
그래서 상속으로 기존 클래스를 확장하는 대신, 새로운 클래스를 만들고 private 필드로 기존 클래스의 인스턴스를 참조하는 컴포지션은 유지보수하기 더 좋아 더 애용된다.
내부 클래스란 ?
클래스 안의 클래스(중첩 클래스)
종류
- 내부 클래스 앞에 static: 정적 내부 클래스
- 인스턴스 내부 클래스
쓰레드란 ?
프로세스 내에서 실제로 작업을 수행하는 주체를 의미하며 모든 프로세스에는 한 개 이상의 스레드가 존재하여 작업을 수행함. 두개 이상 스레드를 가지는 프로세스를 멀티 스레드 프로세스라고 함.
Thread 클래스, Runnable 인터페이스를 통해 구현 가능
- 장점 : 빠른 프로세스 생성 가능, 정보 쉽게 공유 가능.
- 단점 : 교착 상태 : 다중 프로그래밍 체제에서 하나 또는 그 이상의 프로세스가 수행 할 수 없는 어떤 특정 시간을 기다리고 있는 상태.
- 멀티 스레드 : 하나의 프로그램에서 둘 이상의 작업이 필요한 경우 사용.
자바에서 함수형 프로그래밍을 사용하는 이유는?
더 이상 싱글 코어로는 한계에 다다르게 되면서 멀티코어 CPU가 대중화 되고 있다. Java 8 은 시대 흐름에 맞게 병렬 프로세싱을 활용하고자 했고, 그로 인해 기존 Java 에서는 구현하기 어려웠던 부분을 Java 8 을 기점으로 함수형 프로그래밍과 비동기 논블로킹 방식(NIO)을 도입을 통해 해결할려고 했다.
그러나 자바 8버전의 병렬 프로세싱이 성능적인 퍼포먼스를 만드는 것이 힘들어(참고: https://woodcock.tistory.com/28) 현재는 많이 사용하지 않고 있다. 현재로는 멀티스레싱 환경에서 불변화 특성을 이용한 Thread-safe한 방식으로 많이 사용되고 있다.(참고: https://velog.io/@mooh2jj/왜-함수형-프로그래밍인가)
JDBC란?
자바에서 DB의 종류에 상관 없이 데이터베이스에 더욱 쉽게 접근 할 수 있도록 하는 API. OOP의 OCP원칙의 예시이기도 함.
Connection, PreparedStatement, ResultSet 등 여러개의 클래스를 생성하고 Exception 처리도 해야 하는 번거로움이 있음 > 반복적인 코드 발생, 생산성 저하.
Spring JDBC : 기존의 JDBC 단점 극복, 반복적으로 해야 하는 많은 작업들을 대신 해줌. Connection 열기 닫기, Statement 준비, 실행
ConnectionPool : DB와 항상 연결되어 있는 객체들. DB와의 연결을 위해서 사용하는 객체
DataSource : ConnectionPool 관리 객체. 커넥션풀 이용해서 연결, 반납하는 작업 수행.
pom.xml에서 dependency 추가
싱글톤 패턴
하나의 클래스에 대해 하나의 인스턴스만 만들어서 사용하기 위한 패턴. 커넥션 풀과 같은 객체의 경우 인스턴스를 여러개 만들게 되면 자원 낭비가 되므로 하나만 생성하는 것이 효율적.
생성자에 private 접근 제어자를 지정해 인스턴스 생성에 제약을 걸고, 단일 객체를 반환 할 수 있도록 정적 메소드를 지원해야 함.
직렬화 vs 역직렬화?
직렬화의 목적은 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 자바 시스템에서도 사용할 수 있도록 바이트 형태로 데이터 변환하는 것이다. 바이트로 변환된 데이터를 다시 변환하는 기술을 역직렬화라고 하는 것이다.
자바에서 입출력에 사용되는 것은 스트림이라는 데이터 통로를 통해 이동한다. 하지만 객체는 바이트형이 아니라서 스트림을 통해 파일에 저장하거나 네트워크로 전송할 수 없다. 따라서 객체를 스트림을 통해 입출력하려면 바이트 배열로 변환하는 것이 필요한데, 이를 '직렬화' 라고 한다.
자바에서는 Serializable 이라는 인터페이스를 구현받아 생성하면 되는데.
반대로 스트림을 통해 받은 직렬화된 객체를 원래 객체로 만드는 과정을 역직렬화라고 한다.
serialVersionUID를 선언해야 하는 이유
자바가상기계 (JVM)은 직렬화와 역직렬화를 하는 시점의 클래스에 대한 버전 번호를 부여한다. 만약 그 시점에 클래스의 정의가 바뀌어 있다면 새로운 버전 번호를 할당한다. 그래서 직렬화할 때의 버전 번호와 역직렬화를 할 때의 버전 번호가 다르면 역직렬화가 불가능하게 될 수도 있다. 이런 문제를 해결하기 위해 SerialVerionUID를 사용한다.
간단명료하게 serialVersionUID값을 저장할 때 클래스 버전이 맞는지 확인하기 위한 용도다.
만약 직렬화할 때 사용한 serialVersionUID의 값과 역직렬화 하기 위해 사용했던 serialVersionUID값이 다르다면 InvalidClassException이 발생할 수 있다.
리플렉션이란?
리플렉션은 컴파일러를 무시하고 런타임 상황에서 메모리에 올라간 클래스나 메서드등의 정의를 동적으로 찾아서 조작할 수 있는 일련의 행위를 말한다.
즉 동적인 언어의 특징이라 말 할 수 있다. 프레임워크에서 유연성이 있는 동작을 위해 자주 사용하기도 하다.
변수 초기화 순서?
자바의 클래스 멤버 변수 초기화 순서에 대해서 설명
-
static 변수 선언부 : 클래스가 로드 될 때 (메모리 모델상 Methd area 에 올라감) 변수가
제일 먼저 초기화됨 -
필드 변수 선언부 : 객체 생성 될 때 (메모리 모델상 Heap area에 올라감) 생성자 block 보다 앞서 초기화 함
-
생성자 block : 객체 생성 될 때 (메모리 모델상 Heap area에 올라감)
JVM이 내부적으로 locking (thread safe 영역임)
필드 변수 중 final 변수의 가시화는 (다른 스레드에 공개하는 시점은) 생성자 block이 끝난 다음.
필드 변수 선언부에서 이미 초기화 되었다면 그 값들은 덮어 씀
-
초기화 시점
- 클래스변수의 초기화시점 : 클래스가 처음 로딩될 때 단 한번 초기화 된다.
- 인스턴스변수의 초기화시점 : 인스턴스가 생성될 때마다 각 인스턴스별로 초기화가 이루어진다.
-
초기화 순서
- 클래스변수의 초기화순서 : 기본값 -> 명시적초기화 -> 클래스 초기화 블럭
- 인스턴스변수의 초기화순서 : 기본값 -> 명시적초기화 -> 인스턴스 초기화 블럭 -> 생성자
제네릭?
클래스 내부에서 사용할 데이터 Type을 외부에서 지정하는 기법. 제네릭은 컴파일과정에서 데이터 타입을 체크해주는 기능이다.
내가 따로 만든 객체를 지정할 수 있음.
코드의 안정성과 재사용성을 높여줌 > 객체 타입을 컴파일 시에 체크하고, 형변환을 하지 않아도 됨.
ArrayList<MemberDto> // ArrayList 객체 내부에 어떤 형태의 클래스가 있는지 확인 가능.컬렉션?
다수의 데이터를 다루는데 표준화된 클래스들을 자료구조를 직접 구현하지 않고 편하게 사용 가능 함.
배열과 다르게 객체를 보관하기 위한 공간을 미리 정의하지 않아도 됨 객체의 수를 동적으로 할당 가능하므로 효율성 증대.
List, Set, Map (인터페이스)
1) List : 순서 있는 데이터의 집합. 데이터의 중복 허용.
- ArrayList : 단방향 포인터 구조. 각 데이터에 대한 인덱스를 가짐. 검색에 적합. 삽입, 삭제시 데이터 이후 모든 데이터가
복사됨으로 빈번한 경우에는 부적합. - LinkedList : 양방향 포인터 구조. 데이터의 삽입, 삭제시 해당 노드의 주소지만 바꾸면 되므로 삽입, 삭제가 빈번한 데이터에 적합. 처음부터 노드 순회하므로 검색에는 부적합.
2) Set : 순서를 유지하지 않는 데이터 집합. 데이터 중복 허용하지 않음.
- HashSet : Hashing을 이용해서 구현한 컬렉션이다.
equals()나 hashCode()를 오버라이딩해서, 인스턴스가 달라도 동일 객체를 구분해 중복 저장을 막을 수 있다. O(1) - LinkedHashSet : HashSet 클래스를 상속받은 LinkedList이다.
데이터에 삽입된 순서대로 데이터를 관리한다. O(1) - TreeSet : 이진탐색트리(Red-Black Tree)의 형태로 데이터를 저장한다. 데이터 추가, 삭제에는 시간이 더 걸리지만, 검색과 정렬이 더 뛰어나다. 기본적으로 오름차순으로 데이터를 정렬한다. O(logN)
3) Map : Key와 value의 쌍으로 이루어진 데이터 집합. 키는 중복을 허용하지 않고 순서를 유지하지 않음.
- HashMap
- containsKey / containsValue : key와 value가 포함되어 있는지 알려준다.
- put : key, value 형태로 set에 저장함.
- get : 지정된 key값을 반환함.
- size() : 개수 반환
컬렉션(collection) 클래스에서 제네릭을 사용하는 이유
컬렉션 클래스에서 제네릭을 사용하면 컴파일러는 특정 타입만 포함 될 수 있도록 컬렉션을 제한한다.
컬렉션 클래스에 저장하는 인스턴스 타입을 제한하여 런타임에 발생할 수 있는 잠재적인 모든 예외를 컴파일타임에 잡아낼 수 있도록 도와준다.
Wrapper Class
원시형(Primitive type)으로 표현할 수 있는 간단한 데이터를 객체로 만들어야 할 경우가 있는데 그러한 기능을 지원하는 클래스
묵시적 vs 명시적 형변환
-
묵시적 : 프로그래머가 임의로 박싱을 해주는 것이 아니라 자동으로 박싱이 되는 것을 말한다.
-
명시적 : 프로그래머가 코딩하여 명시적으로 wrapper로 변환하는 것을 말한다.
박싱 vs 언박싱
- 박싱 : 원시형 -> Wrapper Class로 변환 박싱
값 형식은 스택에 저장되어 있지만, 박싱되어질때 힙에 데이터가 복사되어 저장된다. - 언박싱 : Wrapper Class -> 원시형으로 변환 언박싱, 명시적 형변환이 발생한다.
여기에 명시적, 묵시적으로 변하는 것을 설명
박싱과 언박싱이 이루어질 때,
저장되는 공간이 다르고 불필요한 형변환이 이루어지기 때문에 Overhead(오버헤드)가 발생할 수 있다.
'==' / equals() 차이
-
== : 주소, 값 모두 비교(동일성 비교),
원시 타입 비교에 쓰임 -
equals() : 값만 비교(동등성 비교), String 객체 등
레퍼런스 타입 비교에 쓰임 -
equals() 메서드 재정의
기본적으로 자바에서는 Object 클래스에 정의된 equals() 메서드가 동일성(주소, 값 모두) 비교를 합니다. 따라서, 개발자는 원한다면 equals() 메서드를 오버라이딩해서 동등성(값만 비교)의 판단 기준을 정의해둘 수 있습니다.
length , length(), size()
- length : 배열
- length() : 문자열 길이
- size() : 컬렉션 프레임워크(arraylist) 타입의 길이
자바 예외 처리 방법
예외(Exception) 처리라 함은 비정상적인 상황이 예측하여 처리하는 것이다. 개발자는 자신이 구현한 로직에서 예외를 예측하고 그에 따른 예외처리를 신경써야 한다. 그중에 unchecked, RuntimeException 처리가 특히 그렇다.
그리고 자바는 예외처리방법 3가지를 쓴다.
1) try-catch (finally) : 예외처리 코드를 직접적으로 제어할 수 있다.
2) throws : throws는 자신을 호출하는 메소드에 예외처리의 책임을 넘기는 것
ex) public void throwTest(int a, int b) throws ArithmeticException{...}
3) throw : throws랑 확연히 다르다. 제일 헷갈렸던 부분이었는데,
throw는 개발자가 직접 예외를 발생시키고싶을 때 쓰는 것이다.
ex) throw new ArithmeticException();
stateless vs immutable
An object that has no state is stateless. All stateless objects are immutable (because there is nothing to mutate); this is a tautological technicallity
참고: https://stackoverflow.com/questions/12980884/what-is-the-difference-between-stateless-and-immutable
: stateless한 객체들은 모두 immutable한 것이다. 반대는 성립이 안된다.
Thread-safe한 context에서 둘은 같은 의미가 될 수 있지만, 엄밀히 말하면 같은 뜻은 아니다.
Thread vs Transaction
-
쓰레드
쓰레드는 자바 프로그램의 실행흐름단위, 자바 프로그램의 컨셉? 정도로 받아들여야... -
트랜잭션
DB와 연관된 개념인데, 롤백, 커밋하는 독립성을 가진 단위로 만들어져야 함. 여러 query들을 가질 수 있다.
보통 한 쓰레드 안에 여러 트랜잭션이 있는 것. 그래서 개발자는 이런 트랜잭션들이 모여서 공유하는 자원을 최대 줄이거나, 불변화 시켜 데드락같은 현상을 없애게 하는 것!
https://stackoverflow.com/questions/66045195/db-transaction-vs-java-thread
DeadLock(Thread vs Transaction)
데드락에서 쓰레드 데드락, 트랜잭션 데드락은 다르다.
개념은 같다. 데드락은 '언제' 발생할지는 알 수 없다. 그저 '발생할 수 있을' 뿐이다. 이건 둘 다 공통이다.
쓰레드 데드락
다수의 쓰레드가 같은 lock 을, 동시에, 다른 명령에 의해, 획득하려 할 때 발생할 수 있다.
// 전제: addChild setParent 동기화 메서드임
Thread 1: parent.addChild(child); //locks parent
--> child.setParentOnly(parent);
Thread 2: child.setParent(parent); //locks child
--> parent.addChildOnly()-> parent 객체는 Thread 1 에 의해 lock 이 걸린 상태이고 Thread 2 블록 상태가 된다.
-> child 객체는 Thread 2 에 의해 lock 이 걸린 상태이고,Thread 1 은 블록 상태가 된다.
서로 블록이 되어 데드락이 되어진다.
자세한 내용은 여기 블로그 참고
https://parkcheolu.tistory.com/19
트랜잭션 데드락
데드락이 발생할 수 있는 더 복잡한 상황은, 데이터베이스 트랜젝션이다. 데이터베이스 트랜젝션은 많은 SQL 업데이트 요청으로 구성되곤 한다. 한 트랜잭션에서 어떤 레코드에 대해 업데이트가 수행될 때, 이 레코드는 업데이트 수행을 위해 다른 트랜잭션의 접근을 막도록 lock 이 걸린다. 이 lock 은 업데이트를 수행하는 트랜젝션이 끝날 때까지 지속된다. 같은 트랜잭션 안에서의 각 업데이트는 데이터베이스의 레코드들에 lock 을 걸 수 있다.
다수의 트랜젝션이 동시에 같은 레코드들을 업데이트한다면, 이는 데드락에 빠질 위험성이 있다.
Transaction 1, request 1, locks record 1 for update
Transaction 2, request 1, locks record 2 for update
Transaction 1, request 2, tries to lock record 2 for update.
Transaction 2, request 2, tries to lock record 1 for update.여기서 lock 은 서로 다른 요청에 의해 잡혀있고, 어느 쪽도 먼저 알려져 있지 않기 때문에, 데이터베이스 트랜젝션에서의 데드락은 감지하거나 방지하기가 어렵다.
