🖥️ 컴퓨터 구조
컴퓨터의 구성 요소
- 프로세서(CPU): 메모리로부터 명령어를 받아와 기계어로 변환 (CU)하고 연산 (ALU)을 수행한다.
- 메모리(1,2차 메모리): 명령어 및 데이터가 적재되는 공간이다. RAM, HDD(SSD) 가 존재한다.
- 입출력 장치: 데이터를 입력/출력하기 위한 컴퓨터의 외부 장치이다. 모니터, 키보드, 스피커 등
프로세서(CPU)의 동작 과정
- 제어 유닛 (Control Unit): 메모리로부터 명령어를 얻어 기계어로 (CPU에 정의된 일련의 명령어 집합, RISC/CISC) 변환한 후 만들어 ALU에게 전달한다.
- 레지스터: 명령어 주소, 코드, 데이터를 임시로 저장한다.
- 산술/논리 연산 장치 (Arithmetic/Logic Unit): 제어 유닛으로 부터 전달받은 명령어를 바탕으로 사칙연산, 논리합, 논리곱 등의 연산을 수행하고 결과 값을 제어 유닛에게 전달한다.
고급 언어, 어셈블리어, 기계어
- 고급 언어: C, JAVA, Python과 같은 일반적인 프로그래밍 언어를 고급 언어라 한다. 고급 언어를 컴파일러가 어셈블리어로 변환한다.
- 어셈블리어: 기계 사고 방식의 언어다. 어셈블리어를 어셈블러가 기계어로 변환한다.
- 기계어(저급 언어): 컴퓨터가 이해할 수 있는 비트의 집합이다. 즉, CPU가 명령을 처리할 때 사용하는 언어로 2집법으로 구성된다.
32비트 CPU와 64 비트 CPU
프로그램 실행을 요청받은 CPU가 한번에 처리할 수 있는 메모리의 크기이다. 즉, 32비트 CPU는 주어진 데이터를 32비트씩 잘라서 수행하고, 64비트 CPU는 64비트씩 잘라서 수행한다. 한번에 수행하는 데이터가 많을수록 데이터 입출력이 줄고 연산이 빨라지기 때문에 64비트 CPU가 훨씬 빠르다.
Base 64(베이스 육십사)란
8비트 이진 데이터(예를 들어 실행 파일이나, ZIP 파일 등)를 문자 코드에 영향을 받지 않는 공통 ASCII 영역의 문자들로만 이루어진 일련의 문자열로 바꾸는 인코딩 방식을 가리키는 개념입니다.
GPU와 CPU의 차이에 대해 설명하세요.
CPU는 최상위 계층의 '중앙처리장치'로써 컴퓨터의 두뇌와 같은 역할을 담당합니다. 따라서 데이터 처리와 더불어 프로그램에서 분석한 알고리즘에 따라 다음 행동을 결정하고 멀티태스킹을 위해 나눈 작업들에 우선순위를 지정하고 전환하며 가상 메모리를 관리하는 등 컴퓨터를 지휘하는 역할을 수행합니다.
GPU는 픽셀로 이루어진 영상을 처리하는 용도로 탄생했습니다. 반복적이고 비슷한 대량 연산을 병렬적(Parallel)으로 수행하기 때문에 CPU보다 훨씬 빠릅니다. 영상, 렌더링을 비롯한 그래픽 작업의 경우 픽셀 하나하나에 대해 연산을 하기 때문에 연산능력이 비교적 떨어지는 CPU가 GPU로 데이터를 보내 재빠르게 처리합니다.
CPU는 GPU보다 적은 코어를 갖고 있지만 각 코어가 GPU보다 강력하므로 순차 작업(Sequential task)에 좋습니다. 반면 GPU는 병렬 작업을 효율적으로 처리할 수 있는 수천 개의 코어를 가지므로병렬 작업(Paralell task)에 좋습니다.
애플리케이션의 연산 집약적 부분을 GPU로 넘기고 나머지 코드만을 CPU에서 처리하는 GPU 가속 컴퓨팅은 딥러닝, 머신러닝 영역에서 강력한 성능을 제공합니다. 사용자 입장에서는 연산 속도가 놀라울 정도로 빨라졌음을 느낄 수 있죠.
RISC와 CISC
프로세서가 가진 명령어 세트를 기준으로 RISC와 CISC로 나누니다.
-
RISC (Reduce Instruction Set Computer): 핵심적인 명령어를 기반으로 최소한의 명령어 세트를 구성한 프로세서다. 고정적인 길이와 간단한 명령어로 빠른 동작 속도를 자랑하한다. 적은 명령어 세트를 가지고 있으므로 프로그램을 구성하는 명령어가 단순하지만 다수의 명령어를 필요로 한다.
-
CISC (Complex Instruction Set Computer): 연산을 처리하는 복잡한 명령어들을 수백개 이상 탑재하고 있는 프로세서다. 명령어 길이가 다양하며 개수가 많아 프로그램의 구성이 복잡해지지만 소수의 명령어로 구현할 수 있다.
현대 CPU들의 RISC vs CISC 특징
RISC(Reduced Instruction Set Computer)와 CISC(Complex Instruction Set Computer)는 프로세서의 명령어 세트 설계 철학을 나타냅니다. 현대 CPU들은 이러한 기본적인 개념을 바탕으로 발전해 왔으며, 때로는 경계를 넘나드는 특징을 보이기도 합니다.
1. ARM 프로세서: RISC의 대표 주자
- 기반: 대표적인 RISC 기반 아키텍처
- 특징:
- 간결하고 고정적인 길이의 명령어: 빠른 디코딩 및 실행 속도
- Load-Store 아키텍처: 메모리 접근은 Load/Store 명령어, 연산은 레지스터 간 수행
- 단순화된 명령어 구조로 파이프라이닝에 유리
- 낮은 전력 소모: 효율적인 에너지 사용
- 활용: 스마트폰, 태블릿, 임베디드 시스템 등 저전력 및 고효율이 요구되는 분야에서 dominant
2. Apple M1: ARM 기반의 혁신
- 기반: ARM 아키텍처 기반의 고성능 프로세서
- 특징:
- ARM의 에너지 효율성과 높은 성능 동시 제공
- 자체 설계 최적화: Apple 하드웨어 및 소프트웨어에 맞춘 설계로 성능 극대화
- 통합된 시스템 온 칩(SoC): CPU, GPU, 뉴럴 엔진 등 통합으로 데이터 처리 속도 및 전력 효율 향상
- 의미: ARM 아키텍처가 고성능 데스크톱 및 노트북 환경에서도 강력한 경쟁력을 가짐을 입증
3. 인텔 프로세서: 전통적인 CISC 강자
- 기반: 전통적인 CISC 기반의 x86 아키텍처
- 특징:
- 복잡하고 다양한 명령어: 메모리 직접 접근, 복잡한 연산 등을 하나의 명령어로 처리 가능
- 가변적인 길이의 명령어: 프로그램 크기 최적화에 유리하나 디코딩 복잡성 증가
- 소수의 명령어로 복잡한 작업 수행 가능
- 현대적인 변화:
- 내부적으로 CISC 명령어를 더 작고 단순한 마이크로 연산(Micro-operation)으로 분해하여 처리
- 마이크로 연산은 RISC와 유사한 특징을 가지며, 파이프라이닝 및 병렬 처리에 최적화
- CISC 아키텍처의 복잡성을 숨기고 RISC의 장점을 활용하는 방식
- 활용: 데스크톱, 서버 등 다양한 분야에서 폭넓게 사용되며, 소프트웨어 호환성 및 복잡한 연산에 강점
결론
현대 CPU들은 RISC와 CISC라는 명확한 경계 없이, 각 아키텍처의 장점을 융합하여 특정 목적에 최적화된 형태로 발전하고 있습니다. ARM은 RISC의 효율성을 바탕으로 모바일 시장을 선도하고 있으며, 인텔은 CISC의 강력한 명령어 세트에 RISC의 효율성을 더하여 고성능 컴퓨팅을 지원하고 있습니다. Apple M1은 ARM 아키텍처의 가능성을 더욱 확장하며 새로운 가능성을 제시하고 있습니다.
작업 관리자에서 CPU 코어, 논리 프로세서란?
좀 더 자세히 설명하면 다음과 같습니다.
코어(Core)
CPU 내부에 실제로 존재하는 물리적인 처리 장치입니다. 각 코어는 독립적으로 명령어를 실행할 수 있습니다. 예를 들어, 쿼드 코어 CPU는 4개의 독립적인 코어를 가지고 있습니다.
논리 프로세서(Logical Processor) 또는 스레드(Thread)
하나의 물리적인 코어가 동시에 처리할 수 있는 명령어 스트림의 수입니다. 현대적인 CPU 기술 중 하나인 SMT (Simultaneous Multithreading) 또는 인텔의 하이퍼스레딩(Hyper-Threading) 기술을 통해 하나의 물리 코어가 여러 개의 논리 프로세서로 인식될 수 있습니다.
하이퍼스레딩/SMT의 원리
코어의 유휴 자원을 활용하여 여러 개의 명령어 스트림을 번갈아 가며 처리함으로써, 마치 여러 개의 코어가 있는 것처럼 보이게 합니다. 예를 들어, 하나의 코어가 두 개의 논리 프로세서를 지원한다면, 운영체제는 해당 코어를 2개의 독립적인 처리 장치로 인식합니다.
따라서 작업 관리자에서 보이는 "논리 프로세서"의 수는 CPU가 동시에 처리할 수 있는 스레드의 총 개수를 나타냅니다.
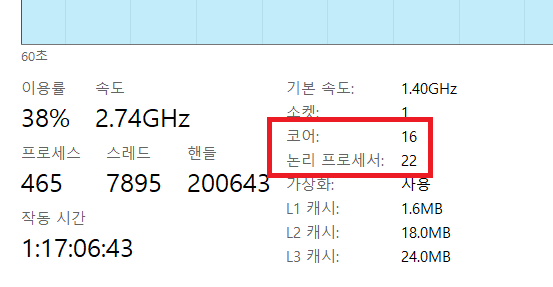
정리
코어: 실제 물리적인 처리 단위
논리 프로세서: 운영체제가 인식하는 가상의 처리 단위 (스레드와 동일한 개념으로 이해하시면 됩니다.)
스레드: 프로그램 실행의 가장 작은 단위이며, 논리 프로세서를 통해 병렬로 실행될 수 있습니다.
작업 관리자에서는 CPU의 병렬 처리 능력을 보여주기 위해 논리 프로세서의 수를 표시하며, 이는 곧 CPU가 동시에 처리할 수 있는 스레드의 수를 의미합니다.
프로그램 실행 순서
1) 사용자가 운영체제에게 프로그램 실행을 요청한다.(run)
2) 운영체제(OS)는 프로그램의 정보를 HDD로부터 읽어 할당된 메인 메모리 (code, data, stack, heap)에 각각 적재한다.
3) CPU는 메인메모리에서 읽어온 정보를 바탕으로 차례로 코드를 실행한다.
메인 메모리의 영역 (code, data, stack, heap)
프로그램이 실행되면 운영체제는 메인 메모리(RAM)에 실행에 필요한 메모리 공간을 할당해준다. 이 메모리 공간은 크게 4가지 영역으로 나뉜다.
- 코드 영역: 프로그램의 소스 코드가 저장되는 영역이다. CPU는 코드 영역에 저장된 명령어 (소스, 함수, 제어문)를 가져와서 처리한다.
- 데이터 영역: 전역 변수와 정적 변수가 저장되는 영역이다. 프로그램 시작과 함께 할당되며, 프로그램이 종료되면 소멸한다.
- 스택 영역: 프로그램이 사용하는 임시 메모리 영역이며 함수의 호출과 관계되는 지역 변수와 매개 변수가 저장되는 영역이다. 함수의 호출과 함께 할당되며, 함수가 종료되면 소멸한다. 함수의 호출 구조가 스택 자료 구조 (LIFO)와 동일하기에 스택으로 구현된다. 컴파일 타임에 영역의 크기가 결정된다.
- 힙 영역: 사용자에 의해 메모리 공간이 동적으로 할당되고 해제되는 영역이다. 즉, 동적 할당을 통해 생성된 동적 변수를 관리하기 위한 영역이다. 런타임에 영역의 크기가 결정된다.
힙 영역과 스택 영역은 사실 같은 공간을 공유한다. 힙이 메모리 위쪽 주소부터 할당되면 스택은 아래쪽부터 할당되는 식이다. 그래서 각 영역이 상대 공간을 침범하는 일이 발생할 수 있는데 이를 각각 힙 오버플로우, 스택 오버플로우라 한다.
Compile과 Interpret
Compile과 Interpret은 소스 코드를 변환하고 실행시키는 방식을 말한다.
- Compile: 소스 코드가 runtime되기 전에 기계어로 한번에 변환 및 해석되는 방식이다. 그렇기 때문에 소스 코드에 문제가 있다면 실행되지 않고 오류를 알린다. 기존 코드는 원시 코드, 변환된 코드를 object code라 한다. 대표적인 compile 언어는 C/C++, JAVA가 있다.
- Interpret: 소스 코드가 먼저 runtime 된 후에 코드 한 줄씩 변환 및 해석되는 방식이다. 그렇기 때문에 소스 코드에 문제가 있더라도 그 코드 전까지는 실행된 후, 오류를 알린다. 가상머신 위에서 컴파일되기에 소스 코드의 이동이 자유롭다. 대표적인 interpret 언어는 python이다.
☑️ 시각적으로 한번에 이해하기 좋은 영상입니다!
https://youtu.be/Dx2tSsd3aFc?si=BMogwgVC9EqWFNNO
자료형의 종류와 크기
자료형에 대한 정보가 미리 정의되어 있으므로 자료형의 이름을 통해 메모리 공간을 할당할 수 있다. 이는 효율적인 메모리 공간 사용을 보장한다.
- char
문자형
1 byte (8bit)
표현 범위: -128 ~ 127 - short
정수형
2 byte (16bit)
표현 범위: -32,768 ~ 32,767 - int
정수형
4 byte (32bit)
포현 범위: -2,147,483,648 ~ 2,147,483,647 - float
실수형
4 byte (32bit) - long
실수형
4 byte (32bit) - double
실수형
8 byte (64bit)
정수형의 표현 범위보다 큰 수를 사용하려 할 때 오버플로우가 발생하며 작은 수를 사용하려 할 때를 언더플로우가 발생한다. unsigned 명령을 통해 양수 범위만 사용할 수 있다.
📜 자료구조
스택, 큐, 트리, 힙
- 스택: 원소들의 삽입과 삭제가 리스트의 한쪽 끝에서만 수행되는 자료구조이다. 후입선출, LIFO 방식을 따른다.

-
큐: 리스트의 한쪽 끝에서는 원소들이 삭제되고, 반대쪽 끝에서는 삽입만 가능하게 만든 순서화된 자료구조이다. 선입선출, FIFO 방식을 따른다. 원소 값 삭제가 발생하면 리스트 내의 모든 원소가 한칸씩 앞으로 이동하여야 하므로 연산이 오래 걸린다.
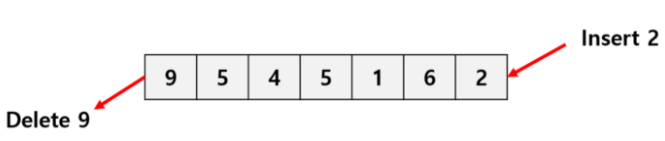
-
힙: 이진 트리의 일종으로 최대 힙 트리, 최소 힙 트리로 나뉜다. 최대 힙은 최대 값을 루트로 하여 부모 노드의 값이 항상 자식 노드의 값보다 큰 트리 구조이며, 최소 힙은 최소 값을 루트로 하여 부모 노드의 값이 항상 자식 노드의 값보다 작은 트리 구조다.

-
트리: 하나의 뿌리에서 가지로 나뉘어 데이터가 저장됨으로서 계층 구조를 갖는 자료구조이다.
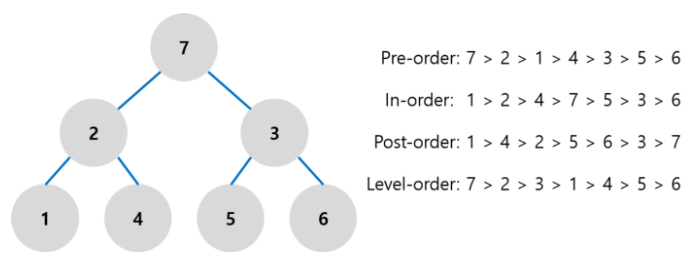
트리 순회
- 중위 순회 (In-order Traversal) : 왼쪽 자식, 루트, 오른쪽 자식 순서로 방문하는 순회 방법이다. 이진 탐색 트리를 중위 순회하면 정렬된 결과를 얻을 수 있다.
- 전위 순회 (Pre-order Traversal) : 루트, 왼쪽 자식, 오른쪽 자식 순서로 방문하는 순서 방법이다.
- 후위 순회 (Post-order Traversal) : 왼쪽 자식, 오른쪽 자식, 루트 순서로 방문하는 순서 방법이다.
- 레벨 순서 순회 (Level-order Traversal) : 너비 우선 순회 (BFS) 라고도 한다. 위의 세 가지 방법은 스택을 활용하여 구현할 수 있는 반면, 레벨 순서 순회는 큐를 활용해 구현한다.
BFS와 DFS
정점과 간선으로 이루어진 그래프 자료구조를 탐색하는 방식이다.
- DFS (깊이 우선 탐색): 루트 노드에서 시작해서 해당 branch를 완벽하게 탐색한 후 다음 branch를 탐색하는 방법이다. 스택을 이용하여 구현한다.
- BFS (너비 우선 탐색): 루트 노드에서 시작해서 인접한 노드를 먼저 탐색하는 방법이다. 큐를 이용하여 구현한다.
배열 (Array)과 링크드 리스트 (Linked list)
- 배열: 순차적으로 데이터가 저장되며 데이터가 저장된 물리적 주소 또한 순차적이다. 인덱스를 가지고 있기 때문에 원하는 데이터에 한번에 접근가능하지만 삽입/삭제를 위해서는 일부 배열을 밀고 당기는 위치 변경이 발생하기에 시간이 오래 걸린다.
- 링크드 리스트: 배열과 마찬가지로 데이터가 순차적으로 저장되어 있지만 물리적 주소는 순차적이지 않을 수 있다. 그리고 인덱스가 없기 때문에 원하는 데이터에 한번에 접근이 불가능하다. 다만, 현재 데이터가 다음 데이터의 주소를 가지고 있기에 연결된 링크를 따라 원하는 데이터에 접근할 수 있다. 다음 데이터의 주소 변경만으로 데이터 삽입/삭제가 가능하다.
💿 데이터베이스
RDBMS (관계형 데이터베이스)와 NoSQL
-
RDBMS
엄격하게 정해진 스키마 (Fields, Records의 제약 조건에 대한 명세)에 따라 데이터를 저장하기에 명확한 데이터 구조를 보장하는 데이터베이스이다. 그렇기에 중복 데이터가 존재하지 않아 저장 공간을 절약할 수 있으며, 데이터 수정 (update)이 용이하다.
그리고 테이블 간의 관계를 통해서 큰 규모의 데이터를 여러 개의 테이블 (ex. user, item, buying)에 분산 저장할 수 있다. 분산 저장을 통해 보안을 철저히 하고, 테이블를 구조적으로 도식화 함으로 효율적으로 관리할 수 있다. 다만, 테이블 관계가 복잡해 질수록 JOIN이 많은 SQL 쿼리가 만들어 질 수 있다.
데이터 수정 (update)가 자주 발생하는 시스템이거나, 명확한 스키마가 중요한 경우 RDBMS가 적합하다. -
NoSQL
스키마없이 유연하게 데이터를 저장/관리할 수 있는 데이터베이스이다. MongoDB가 대표적인 NoSQL이다.
데이터 중복이 허용되기에 수정 (update)을 위해서는 중복으로 저장된 데이터를 검색하여 모두 수정해야하는 번거로움이 있으며, 엄격한 스키마가 없다보니 데이터에 대한 규격화된 결과 값을 얻을 수 없다.
정확한 데이터 구조를 알지 못하거나, 데이터 수정 (update)보다는 쓰기 (write)와 읽기 (read)가 더 자주 발생하는 경우 NoSQL이 적합하다.
🧑💼 운영체제
운영체제에 대해 설명
운영체제는 사용자에게 편리한 인터페이스 환경을 제공하고 컴퓨터 시스템의 자원을 효율적으로 관리하는 소프트웨어입니다.
운영체제는 인터페이스(GUI)와 시스템 호출(System call), 커널(Kernel)과 드라이버(Driver)로 구성됩니다. 이 중 사용자와 으용 프로그램에 인접하여 커널에 명령을 전달하고 실행 결과를 사용자와 응용 프로그램에 돌려주는 인터페이스와 운영 체제의 핵심 기능을 모아놓은 커널로 구분됩니다.
운영체제의 역할과 목적은 아래와 같습니다.
- 효율적인 자원 관리
- 안정적인 자원 보호
- 확장성 높은 하드웨어 인터페이스 제공
- 편리한 사용자 인터페이스 제공
시스템 호출에 대해 설명
시스템 호출(System call)은 커널이 자신을 보호하기 위해 만든 인터페이스입니다.
커널은 보안을 위해 사용자나 응용 프로그램이 자원에 직접 접근하는 것을 차단하므로 자원을 이용 하려면 시스템 호출이라는 인터페이스를 이용해야 합니다.
커피를 마시기 위해 준비하는 과정을 예를 들어볼까요? 우리는 커피를 만들기 위해서 커피머신과 재료를 찾고, 이를 조제하여 마십니다. 그러기 위해서는 재료를 구비하고 커피머신의 사용법을 명확히 알아야 하죠. 이 과정 중 커피머신이 망가지거나 더러워질 수 있습니다.
반면 카페에서 커피를 주문한다고 생각해봅시다. 위의 번거로운 과정을 겪지 않아도 되는 것이죠! 이것이 직접 접근(사용자가 컴퓨터 자원에 직접 접근하여 작업)과 시스템 호출(작업을 요청하고 결과만 전달)입니다.
가상머신이란 무엇인가요?
가상 머신(Virtual Machine, VM)은 물리적 하드웨어 시스템에 구축되어 자체 CPU, 메모리, 네트워크 인터페이스 및 스토리지를 갖춘 가상 환경입니다.
커널 기반 가상 머신(KVM)과 같은 하이퍼바이저가 탑재된 물리적 머신을 호스트 머신, 호스트 컴퓨터, 호스트 운영 체제 또는 간단히 호스트라고 부릅니다. 리소스를 사용하는 여러 VM을 게스트 머신, 게스트 컴퓨터, 게스트 운영 체제 또는 간단히 게스트라고 부릅니다. 하이퍼바이저는 CPU, 메모리, 스토리지 등의 컴퓨팅 리소스를 처리하는 리소스의 풀로, 기존 게스트 간 또는 새로운 가상 머신에 쉽게 재배치할 수 있습니다.
VM은 시스템의 나머지 부분과 격리되며, 서버처럼 하나의 하드웨어에 여러 VM이 존재할 수 있습니다. 이는 수요에 따라 또는 더 효율적인 리소스 사용을 위해 호스트 서버 간에 이동할 수 있습니다.
하이퍼바이저란 무엇인가요?
가상 머신을 생성하고 구동하는 소프트웨어입니다.
가상 머신 모니터(Virtual Machine Monitor, VMM)라고도 불리는 하이퍼바이저는 하이퍼바이저 운영 체제와 가상 머신의 리소스를 분리해 VM의 생성과 관리를 지원합니다.
하이퍼바이저로 사용되는 물리 하드웨어를 호스트라고 하며 리소스를 사용하는 여러 VM을 게스트라고 합니다.
하이퍼바이저는 CPU, 메모리, 스토리지 등의 리소스를 처리하는 풀로, 기존 게스트 간 또는 새로운 가상 머신에 쉽게 재배치할 수 있습니다.
모든 하이퍼바이저에서 VM을 실행하려면 메모리 관리 프로그램, 프로세스 스케줄러, I/O(입력/출력) 스택, 기기 드라이버, 보안 관리 프로그램, 네트워크 스택과 같은 운영 체제 수준의 구성 요소가 필요합니다.
하이퍼바이저는 할당되었던 리소스를 각 가상 머신에 제공하고, 물리 리소스에 대해 VM 리소스의 일정을 관리합니다. 물리적 하드웨어는 계속해서 실행 작업을 수행하므로 하이퍼바이저가 일정을 관리하는 동안 CPU가 VM에서 요청한 대로 CPU 명령을 계속 실행합니다.
서로 다른 여러 개의 운영 체제를 나란히 구동할 수 있으며, 하이퍼바이저를 사용해 동일한 가상화 하드웨어 리소스를 공유합니다. 바로 이러한 부분이 가상화의 핵심적인 이점입니다. 가상화가 없다면 하드웨어에서 운영 체제를 1개만 구동할 수 있습니다.
컨테이너와 VM은 유사하다고 볼 수 있습니다. 이 두 가지 모두 다양한 IT 요소를 결합해 시스템의 나머지 부분으로부터 분리하는 패키지 컴퓨팅 환경이기 때문입니다. 중요한 차이점은 확장 방식과 이식성
메모리 누수(memory leak)란?
컴퓨터 프로그램(프로세스)이 필요하지 않은 메모리를 계속 점유하고 있는 현상
메모리 관리 전략에 대해 알려주세요.
메모리는 CPU 가 직접 접근하는 유일한 저장장치입니다.
메모리 시스템(하드웨어)은 주소(메모리 위치)를 관리하며 할당과 접근을 제어하는데, 이는 제한된 물리적 메모리의 효율적인 사용(할당)과 효율적인 메모리 참조(논리-물리주소 할당)를 위함입니다.
이러한 관리에는 여러 전략이 있습니다.
- 스와핑(Swapping) : CPU에서 실행 중이지 않은 프로세스의 메모리 이미지를 저장 장치에 이동시켜 메모리 사용의 효율성을 증가시킵니다.
- 연속 메모리 할당(Contiguous Memory Allocation) : 각 프로세스가 필요로 하는 메모리 요구량을 분석한 뒤, 필요한 메모리를 연속으로 할당(연속된 물리 메모리이므로 시작 주소만 필요해요)합니다.
- 페이징(Paging) : 프로세스가 사용하는 주소 공간을 여러 개로 분할하여 비연속적인 물리 메모리 공간에 할당, 가상 메모리를 모두 같은 크기의 블록으로 편성합니다.
- 세그멘테이션(Segmentation) : 프로세스가 필요로 하는 메모리 공간을 분할하여 비연속적인 물리 메모리 공간에 할당합니다.
메모리 할당 알고리즘에 대해 알려주세요.
새로 적재되어야 할 데이터를 주기억장치 영역 중 어느 곳에 배치할지를 결정하는 전략입니다.
페이지, 세그먼트 등이 적재될 위치를 결정하는 정책으로, 종류는 아래와 같습니다.
- 최초 적합(First-fit) : 가용공간 중 수용가능한 첫번째 기억공간을 할당합니다.
- 최적 적합(Best-fit) : 모든 공간 중에서 수용가능한 가장 작은 곳을 선택합니다.
- 최악 적합(Worst-fit) : 모든 공간 중에서 수용가능한 가장 큰 곳을 선택합니다.
따라서, 공간 효율성은최적 적합 > 최초 적합 > 최악 적합순으로, 시간 효율성은최초 적합 > 최적적합 ≒ 최악적합순이 됩니다.
가상 메모리와 페이지 폴트
- 가상 메모리: 프로그램 실행에 필요한 메모리 용량 전체를 ram에서 할당받는 것이 아니라, 최소한의 메모리를 ram에서 할당받아 저장하고, 나머지는 HDD (가상 메모리 공간)에 저장하는 것이다.
- 페이지 폴트: 가상 메모리를 사용하게 된다면 프로그램이 사용하는 페이지는 물리 메모리인 ram과 가상 메모리인 hdd에 나뉘어 저장된다. 이때, 프로그램이 필요로 하는 페이지가 물리 메모리에 없을 경우 페이지 폴트라 한다.
- 요구 페이징: 페이지 폴트가 발생하면 운영 체제가 가상 메모리에서 해당 페이지를 찾아 물리 메모리의 불필요한 페이지와의 교체를 요구한다. 그리고 이 과정 동안은 모든 스레드가 대기한다.
페이지 교체 알고리즘
요구 페이징이 발생했을 때 교체할 물리 메모리의 페이지를 선정하는 알고리즘이다.
- FIFO (First In First Out): 물리 메모리에 적재된지 가장 오래된 페이지를 교체한다. 페이지의 사용 빈도를 무시하기 때문에 활발하게 사용하는 페이지가 교체될 수 있다는 문제점이 있다. 페이지가 적재된 순서를 Queue에 저장하는 방식을 사용한다.
- LRU (Least Recently Used): 가장 오랜 기간 사용되지 않은 페이지를 교체한다. 많은 운영체제가 사용하는 알고리즘이다.
- LFU (Least Frequently Used): 참조 횟수가 가장 적은 페이지를 교체한다. 만약 교체 대상이 여러 개일 경우에 LRU를 사용한다. LFU는 초기에 한 페이지를 집중적으로 참조하다가, 이후에 참조하지 않는 경우에 메모리에 계속 남아있을 수 있다는 문제점이 있다.
- MFU (Most Frequently Used): LFU와 반대로 참조 횟수가 가장 많은 페이지를 교체하는 알고리즘이다.
메모리 단편화 (Memory Fragmentation)
- 내부 단편화: 교체된 페이지의 크기가 할당된 공간의 크기보다 작은 경우 내부 단편화가 발생한다. 이는 저장 공간 낭비로 이어진다.
- 외부 단편화: 메모리가 할당되고 해제되는 작업이 반복될 때 작은 메모리가 중간중간 존재하게 되는데, 이 때 총 메모리 공간은 충분하지만 교체된 페이지의 크기가 할당된 공간의 크기보다 큰 경우 외부 단편화가 발생한다.
페이징과 세그먼테이션
메모리 단편화를 해결할 수 있는 기법이다.
페이징
페이지가 연속적인 물리 메모리 공간에 들어가야하는 제약을 해결하기 위한 방법이다. 가상 메모리는 페이지, 물리 메모리는 프레임이라는 고정 크기의 블록으로 나눈 후, 페이지 테이블의 매핑을 통해 1:1 대응 시킨다. 이는 외부 단편화를 해결할 수 있다. 페이지 단위를 작게하면 내부 단편화(Internal fragmentation) 역시 해결할 수 있지만 페이지에 공간을 할당한 후, 남는 공간이 적어지기 때문에 그 만큼 page mapping 과정이 증가할 수 있다.
세그멘테이션
method, function, object, variables 등 프로그램의 논리적 단위를 바탕으로 서로 다른 크기의 블록으로 나누는 방법이다. 세그먼트들의 크기가 서로 다르기 때문에 메모리를 페이징 기법처럼 미리 분할해 둘 수 없고, 메모리에 적재될 때 빈 공간을 찾아 할당하는 사용자 관점의 가상 메모리 관리 기법이다. 각 세그먼트 별로 길이 값을 가지고 있어 내부 단편화를 해결할 수 있다.
스레드 세이프한 프로그래밍 조건엔 무엇이 있나요?
스레드 세이프(Thread-safe)란 어떤 함수, 변수, 객체가 여러 스레드로부터 동시 다발적인 접근이 일어나도 프로그램 실행이 보장되는 것입니다.
스레드 세이프한 프로그래밍이란 아래의 조건이 충족되어야 합니다.
- 재진입성 보장(Re-entrancy)
어떤 함수가 한 스레드에 의해 호출되어 실행 중일 때, 다른 스레드가 그 함수를 호출하더라도 그 결과가 각각에게 올바로 반환되어야 합니다. - 스레드별 지역 변수 사용(Thread-local storage)
공유 자원의 사용을 최대한 줄이고 각각의 스레드에서만 접근 가능하게 설정하여 스레드가 공유 자원에 동시 접근하는 것을 방지합니다.
동기화 방법(Synchronization)과 관련이 있습니다. - 상호 배제(Mutual exclusion)
공유 자원을 반드시 사용해야 할 경우 해당 자원의 접근을 세마포어(Semaphore) 등의 락으로 통제합니다. - 중단되지 않는 연산(Atomic operations)
공유 자원 접근 시 이 연산을 이용하거나 원자적(Atomic)으로 정의된 접근 방법을 사용함으로써 상호 배제를 구현할 수 있습니다.
프로세스와 스레드
- 프로세스: 운영체제로부터 프로세서, 주소 공간, 메모리과 같은 시스템 자원을 할당받는 작업의 단위로 실행된 프로그램을 의미한다. 프로세스는 실행될 때 운영 체제로부터 독립된 메모리 영역 (Code, Data, Stack, Heap)을 할당받으며 다른 프로세스의 자원에는 접근할 수 없다.
- 스레드: 프로세스 내에서 동작되는 실행의 단위로서 Stack 외에 프로세스가 할당받은 자원 (Code, Data, Heap)을 스레드끼리 공유, 이용하면서 실행된다. 하나의 프로세스가 실행되면 기본적으로 하나의 메인 스레드가 생성된다.
~
- 멀티 프로세스: 하나의 프로그램을 프로세스 여러 개로 구성하여 Context switching을 통해 실행하는 것을 말한다. 하나의 프로세스에 문제가 생기더라도 다른 프로세스에 영향을 미치지 않는다.
- 멀티 스레드: 하나의 프로그램을 한 프로세스 내에 여러 개의 스레드로 구성하여 실행하는 것을 말한다. 멀티 프로세스보단 멀티 스레드가 더 효율적인데 그 이유는 스레드 간의 통신 비용이 훨씬 적기 때문이다. 하지만 스레드 간의 자원 공유는 전역 변수를 이용하기에 동기화를 신경써야한다.
ThreadLocal
말 그대로 스레드 내부에서 사용되는 지역변수를 말한다. 각각의 thread scope 내에서 공유되어 사용될 수 있는 값으로 다른 스레드에서 공유 변수에 접근할 시 발생할 수 있는 동시성 문제의 예방을 위해 만들어졌다.
Context Switching
프로세서가 멀티 프로세싱을 구성하여 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때, 기존 프로세스의 상태 또는 레지스터 값 (context)을 저장하고 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값을 교체하는 작업을 Context switching이라 한다.
멀티 프로세싱을 Computer multitasking을 통해 빠른 속도로 Task를 바꿔 가며 실행하여 실시간 처리에 근사하도록 하는 기술이다.
교착 상태 (Deadlock) 발생 4가지 조건
교착 상태란 서로 다른 프로세스가 서로의 자원을 요구하며 무한정 기다리는 현상을 말하며, 아래의 4가지 조건 중 하나라도 만족하지 않으면 교착 상태는 발생하지 않는다.
- 상호배제 (Mutual exclusion): 한번에 한 프로세스만이 자원을 점유할 수 있다.
- 점유대기 (Hold and wait): 프로세스가 이미 자원을 점유하는 상태에서 다른 자원을 무한정 기다린다.
- 비선점 (No preemption): 프로세스가 어떤 자원의 점유를 끝낼 때까지 그 자원을 뺏을 수 없다.
- 순환대기 (Circular wait): 각 프로세스들이 원형으로 구성되어 순환적으로 자원을 요구한다.
뮤텍스와 세마포어
이 둘의 궁극적인 목표는 ‘다수의 프로세스나 스레드가 공유 자원에 동시에 접근하는 것을 제어하는 것’이다.
-
뮤텍스: 한 스레드, 프로세스에 의해 소유될 수 있는 Key를 기반으로 한 상호배제 기법이다. 한 스레드가 임계 영역에 들어갈 때 lock을 걸어 다른 스레드가 접근하지 못하도록 하고, 임계 영역에서 나올 때 unlock한다.
-
세마포어: 현재 공유 자원에 접근할 수 있는 스레드, 프로세스의 수를 나타내는 값을 두는 상호 배제 기법이다. 그 값만큼 동시에 스레드가 해당 공유 자원에 접근할 수 있다.
🛜 네트워크
OSI 7 Layer
네트워크에서 통신이 일어나는 과정을 7단계로 캡슐화하여 서로 다른 동작을 각 layer에서 담당하는 것을 말한다. 이로서 통신이 일어나는 과정을 단계적으로 파악할 수 있으며 layer 별로 각기 다른 동작을 수행하기에 오류 탐지가 용이하다.
- Physical layer: 전기적, 기계적 특성을 바탕으로 비트 흐름을 전송한다. 이 계층은 데이터를 전달만 할 뿐, 데이터가 무엇인지 전혀 신경쓰지 않는다. (케이블, 리피터, 허브 등)
- DataLink layer: 안전한 정보 전달을 보장한다. 물리 계층에서 전달 받은 프레임의 오류를 찾고 필요시 재전송을 요청한다.
- Network layer: 오류 없는 패킷을 목적지까지 안전하고 빠르게 전달하는 경로 (라우팅)를 찾는 계층이다.
- Transport layer: 전송을 통해 통신을 활성화하는 계층이다. 패킷의 전송이 유효한지 확인하고 실패한 패킷을 재전송한다. end-to-end 통신의 신뢰성을 보장하고, 오류 검출, 흐름제어, 중복 검사를 수행한다.
- Session layer: 그 전까진 물리적 측면의 통신이었다면 포트를 연결하여 논리적인 통신을 가능케하는 계층이다.
- Presentation layer: 응용 프로그램을 위해 형식상 차이를 갖는 데이터를 인코딩하여 일관된 형태의 데이터를 표현하는 계층이다.
- Application layer: 사용자와 직접 상호작용하는 계층이다. 크롬, 파이어폭스가 대표적 예시이다.
TCP와 UDP
이 둘은 전송 계층에서 패킷을 보내기 위한 프로토콜이다.
- TCP (Transmission Control Protocol): 연결형 서비스로 3-way handshaking 과정을 통해 연결을 설정하고, 4-way handshaking을 통해 해제한다. 그렇기에 높은 신뢰성과 전송 순서를 보장한다. 1:1 통신에서 사용된다. UDP보다는 속도가 느리다.
- UDP (User Datagram Protocol): 비연결형 서비스로 패킷을 주고 받을 때 신호 절차를 거치지 않는다. 그렇기에 신뢰성이 낮으며 전송 순서가 바뀔 수 있다. 1:N 이나 N:N 통신에서 사용된다. TCP보다 속도가 빠르다.
3-way handshaking과 4-way handshaking (TCP)
- 3-way handshaking: 장치들 사이의 접속을 성립하기 위한 절차로 양 장치 모두 데이터 통신 준비가 되었다는 것을 보장한다.
과정: SYN (Client) → SYN + ACK (Server) → ACK (Client)
- 4-way handshaking: 장치들 사이의 통신을 종료하기 위한 절차이다.
과정: FIN (Client) → ACK (Server) → FIN (Server) → ACK(Client)
참고
