자바스크립트 자료구조와 자료형 파트 중 배열과 메서드에 대해 공부하겠습니다.
배열과 메서드
배열은 다양한 메서드를 제공한다.
요소 추가·제거 메서드
배열의 맨 앞이나 끝에 요소(item)를 추가하거나 제거하는 메서드는 이미 학습한 적이있다.
이 외에 요소 추가와 제거에 관련된 메서드에 대해 알아보자.
1. 삭제
splice
배열에서 요소를 하나만 지우고 싶다면 어떻게 해야 할까?배열 역시 객체형에 속하므로 프로퍼티를 지울 때 쓰는 연산자 delete를 사용해 볼 수 있다.

원하는 대로 요소를 지웠지만 배열의 요소는 여전히 세 개이다. arr.length == 3를 통해 확인할 수 있다.
이는 자연스러운 결과이다. delete obj.key는 key를 이용해 해당 키에 상응하는 값을 지우기 때문이다. 그렇다면 빈 공간을 나머지 요소들이 자동으로 채워지게 하려면 어떻게 해야할까
그럴땐 arr.splice(start)를 사용하자. 이 메서드는 요소 추가, 삭제, 교체가 모두 가능하다.
문법을 확인해보자.

첫 번째 매개변수는 조작을 가할 첫 번째 요소를 가리키는 인덱스(index)이다.
두 번째 매개변수는 deleteCount로, 제거하고자 하는 요소의 개수를 나타낸다.
elem1, ..., elemN은 배열에 추가할 요소를 나타낸다.
splice 메서드를 사용해 작성된 예시를 살펴보자.
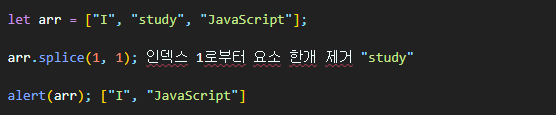
인덱스 1이 가리키는 요소부터 시작해 요소 한 개(1)를 지웠다.
다음은 요소 세 개(3)를 지우고, 그 자리를 다른 요소 두 개로 교체해보자.

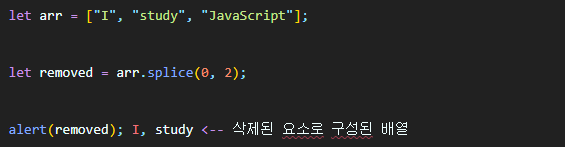
splice는 삭제된 요소로 구성된 배열을 반환한다. 아래 예시를 통해 확인해보자.

TMI - 음수 인덱스도 사용할 수 있다.
splice 메서드 뿐만 아니라 배열 관련 메서드엔 음수 인덱스를 사용할 수 있다. 이때 마이너스 부호 앞의 숫자는 배열 끝에서부터 센 요소 위치를 나타낸다.
2. 복사
slice
arr.slice는 arr.splice와 비슷한데 훨씬 간단하다.문법을 살펴보자.

이 메서드는 "start" 인덱스부터 ("end"를 제외한) "end" 인덱스까지의 요소를 복사한 새로운 배열을 반환한다. start와 end는 둘 다 음수일 수도 있는데 이때는 배열 끝에서부터의 요소 개수를 의미한다.
arr.slice는 문자열 메서드인 str.slice와 유사하게 동작하는데 arr.slice는 서브 문자열(substring) 대신 서브 배열(subarray)을 반환한다는 점이 다르다.

arr.slice()는 인수를 하나도 넘기지 않고 호출하여 arr의 복사본을 만들 수 있다.
이런 방식은 기존의 배열을 건드리지 않으면서 배열을 조작해 새로운 배열을 만들고자 할때 자주 사용된다.
3. 요소 추가
concat
arr.concat은 기존 배열의 요소를 사용해 새로운 배열을 만들거나 기존 배열에 요소를 추가하고자 할 때 사용할 수 있다.문법을 살펴보자.

인수엔 배열이나 값이 올 수 있는데, 개수엔 제한이 없다.
메서드를 호출하면 arr에 속한 모든 요소와 arg1, arg2 등에 속한 모든 요소를 한데 모은 새로운 배열이 반환된다.
인수 argN가 배열일 경우 배열의 모든 요소가 복사된다. 그렇지 않은 경우(단순값인 경우)는 인수가 그대로 복사된다.

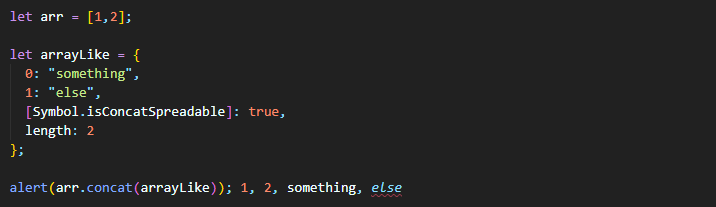
concat 메서드는 제공받은 배열의 요소를 복사해 활용한다. 객체가 인자로 넘어오면 (배열처럼 보이는 유사 배열 객체이더라도) 객체는 분해되지 않고 통으로 복사되어 더해진다.

그런데 인자로 받은 유사 배열 객체에 특수한 프로퍼티 Symbol.isConcatSpreadable이 있으면 concat은 이 객체를 배열처럼 취급한다. 따라서 객체 전체가 아닌 객체 프로퍼티의 값이 더해진다.
forEach로 반복작업 하기
arr.forEach는 주어진 함수를 배열 요소 각각에 대해 실행할 수 있게 해준다.
아래는 요소 모두를 얼럿창을 통해 출력해주는 코드이다.

아래는 인덱스 정보까지 더해서 출력해주는 좀 더 정교한 코드이다.

인수로 넘겨준 함수의 반환값은 무시된다.
배열 탐색하기
배열 내에서 무언가를 찾고 싶을 때 쓰는 메서드에 대해 알아보자.indexOf, lastIndexOf와 includes
arr.indexOf와 arr.lastIndexOf, arr.includes는 같은 이름을 가진 문자열 메서드와 문법이 동일하다. 물론 하는 일도 같다. 연산 대상이 문자열이 아닌 배열의 요소라는 점만 다르다.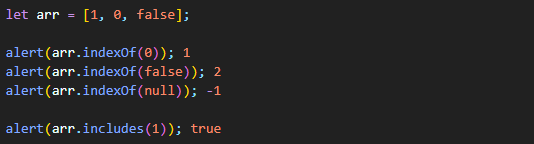
위 메서드들은 요소를 찾을 때 완전 항등 연산자 ===을 사용한다는 점에 유의해야한다.
위와 같이 false를 검색하면 정확히 false만을 검색하지, 0을 검색하진 않는다.
요소의 위치를 정확히 알고 싶은게 아니고 요소가 배열 내 존재하는지 여부만 확인하고 싶다면 arr.includes를 사용하는 게 좋다.
indecludes는 NaN도 제대로 처리한다는 점에서 indexOf/lastIndexOf와 약간의 차이가 있다.

find와 findIndex
객체로 이루어진 배열이 있다고 가정해보자. 특정 조건에 부합하는 객체를 배열 내에서 어떻게 찾을 수 있을까이럴 땐 arr.find(fn)을 사용할 수 있다.

요소 전체를 대상으로 함수가 순차적으로 호출된다.
함수가 참을 반환하면 탐색은 중단되고 해당 요소가 반환된다. 원하는 요소를 찾지 못했으면 undefined가 반환된다.
id와 name 프로퍼티를 가진 사용자 객체로 구성된 배열을 예로 들어 배열 내에서 id == 1 조건을 충족하는 사용자 객체를 찾아보자.
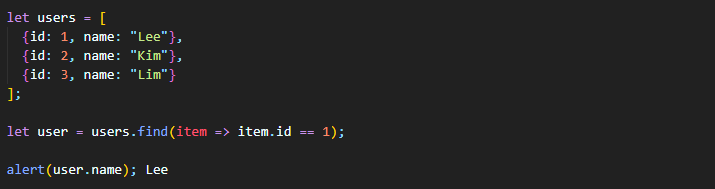
실무에선 객체로 구성된 배열을 다뤄야 할 일이 잦기 때문에 find 메서드 활용법을 알아두는 것이 좋다고 한다.
그런데 위 예시에서 find 안의 함수가 인자를 하나만 가지고 있다는 점에 주목해보자.
(item => item.id == 1), 이런 패턴이 가장 많이 사용되는 편이다. 다른 인자들(index, array)은 잘 사용되지 않는다고 한다.
arr.findIndex는 find와 동일한 일을 하지만, 조건에 맞는 요솔르 반환하는 대신 해당 요소의 인덱스를 반환한다는 점이 다르다. 조건에 맞는 요소가 없으면 -1이 반환된다.
filter
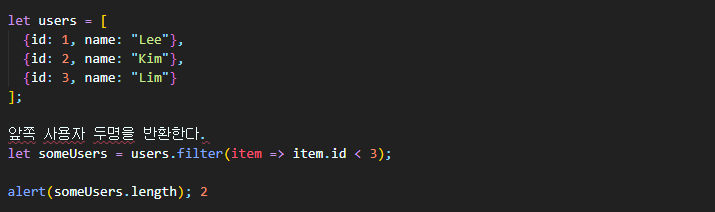
find 메서드는 함수의 반환 값을 true로 만드는 단 하나의 요소를 찾는다.조건을 충족하는 요소가 여러 개라면 arr.filter(fn)를 사용하면 된다.
filter는 find와 문법이 유사하지만, 조건에 맞는 요소 전체를 담은 배열을 반환한다는 점에서 차이가 있다.

배열을 변형하는 메서드
배열을 변형시키거나 요소를 재 정렬해주는 메서드에 대해 알아보자.map
arr.map은 유용성과 사용 빈도가 아주 높은 메서드 중 하나이다. map은 배열 요소 전체를 대상으로 함수를 호출하고, 함수 호출 결과를 배열로 반환해준다.
아래 예시에선 각 요소(문자열)의 길이를 출력해준다.

sort(fn)
arr.sort()는 배열의 요소를 정렬해준다. 배열 자체가 변경된다.메서드를 호출하면 재정렬 된 배열이 반환되는데, 이미 arr 자체가 수정되었기 때문에 반환 값은 잘 사용되지 않는 편이다.

위 예시에선 문제가 있다
재정렬 후 배열 요소가 1, 15, 2가 되었다. 기대하던 결과(1, 2, 15)와는 다르다. 왜 이런 결과가 나왔는지 생각해보자.
요소는 문자열로 취급되어 재 정렬되기 때문이다.
모든 요소는 문자형으로 변환된 이후에 재 정렬된다. 앞서 배웠듯이 문자열 비교는 사전편집 순으로 진행되기 때문에 2는 15보다 큰 값으로 취급된다.("2" > "15")
기본 정렬 기준 대신 새로운 정렬 기준을 만들려면 arr.sort()에 새로운 함수를 넘겨줘야 한다.
인수로 넘겨주는 함수는 반드시 값 두 개를 비교해야 하고 반환 값도 있어야 한다.

이제 배열 요소를 숫자 오름차순 기준으로 정렬해보자.

이제 기대했던 대로 요소가 정렬되었다.
여기서 잠시 멈춰 위 예시에서 어떤 일이 일어났는지 생각해보자.
사실 arr엔 숫자, 문자열, 객체 등이 들어갈 수 있다. 알 수 없는 무언가로 구성된 집합이 되는 것이다.
이제 이 비 동질적인 집합을 정렬해야 한다고 가정한다면, 정렬 기준을 정의해주는 함수 (ordering function, 정렬 함수)가 필요하다. sort에 정렬 함수를 인수를 넘겨주지 않으면 이 메서드는 사전편집 순으로 요소를 정렬한다.
arr.sort(fn)는 포괄적인 정렬 알고리즘을 이용해 구현되어있다. 대개 최적화된 퀵소트(quicksort)를 사용하는데, arr.sort(fn)는 주어진 함수를 사용해 정렬 기준을 만들고 이기준에 따라 요소들을 재배열 하므로 개발자는 내부 정렬 동작 원리를 알 필요가 없다. 우리가 해야 할 일은 정렬 함수 fn을 만들고 이를 인수로 넘겨주는 것이다.
정렬 과정에서 어떤 요소끼리 비교가 일어났는지 확인하고 싶다면 아래 코드를 활용하자.

정렬 중에 한 요소가 특정 요소와 여러 번 비교되는 일이 생기곤 하는데 비교 횟수를 최소화 하려다 보면 이런 일이 발생할 수 있다.
TMI - 정렬함수는 어떤 숫자든 반환할 수 있다.
정렬함수의 반환 값엔 제약이 없다. 양수를 반환하는 경우 첫 번째 인수가 두 번째 인수보다 '크다'를 나타내고, 음수를 반환하는 경우 첫 번째 인수가 두 번째 인수보다 '작다'를 나타내기만 하면 된다.이 점을 이용하면 정렬 함수를 더 간결하게 만들 수 있다.

TMI - 화살표 함수를 사용하자.
화살표 함수를 사용하면 정렬 함수를 더 깔끔하게 만들 수 있다.
화살표 함수를 활용한 코드와 함수 선언문을 사용한 코드는 동일하게 작동한다.
TMI - 문자열엔 localeCompare를 사용하자.
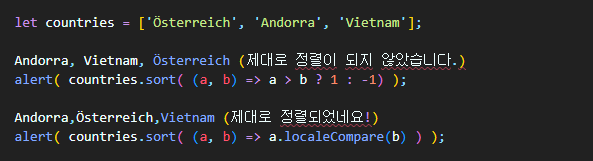
strings에서 배운 비교 알고리즘을 기억한다면, 이 알고리즘은 유니코드를 기준으로 글자를 비교한다는 것을 알 수 있다.Ö같은 문자가 있는 언어에도 대응하려면 str.localeCompare 메서드를 사용해 문자열을 비교하는 게 좋다.
독일어로 나타낸 국가가 요소인 배열을 정렬해보자.
reverse
arr.reverse는 arr의 요소를 역순으로 정렬시켜주는 메서드이다.
반환 값은 재 정렬된 배열이다.
split과 join
메시지 전송 애플리케이션을 만들고 있다고 가정해보자. 수신자가 여러 명일 경우, 발신자는 쉼표로 각 수신자를 구분할 것이다. Lee, Kim, Lim 같이 말이다. 개발자는 긴 문자열 형태의 수신자 리스트를 배열 형태로 전환해 처리하고 싶을 것이다. 입력받은 문자열을 어떻게 배열로 바꿀 수 있을까그것은 str.split(delim)을 이용하면 우리가 원하는 것을 정확히 할 수 있다.
이 메서드는 구분자(delimiter) delim을 기준으로 문자열을 쪼개준다.
아래 예시에선 쉼표와 공백을 합친 문자열이 구분자로 사용되고 있다.

split 메서드는 두 번째 인수로 숫자를 받을 수 있다. 이 숫자는 배열의 길이를 제한해주므로 길이를 넘어서는 요소를 무시할 수 있다. 실무에서 자주 사용하는 기능은 아니다.

TMI - 문자열을 글자 단위로 분리하기
split(s)의 s를 빈 문자열로 저장하면 문자열을 글자 단위로 분리할 수 있다.
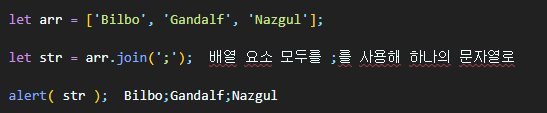
arr.join(glue)은 split과 반대 역할을 하는 메서드이다. 인수 glue를 접착제처럼 사용해 배열 요소를 모두 합친 후 하나의 문자열을 만들어준다.
reduce와 reduceRight
forEach, for, for..of를 사용하면 배열 내 요소를 대상으로 반복 작업을 할 수 있다.각 요소를 돌면서 반복 작업을 수행하고, 작업 결과물을 새로운 배열 형태로 얻으려면 map을 사용하면 된다.
arr.reduce와 arr.reduceRight도 이런 메서드들과 유사한 작업을 해준다. 그런데 사용법이 조금 복잡하다. reduce와 reduceRight는 배열을 기반으로 값 하나를 도출할 때 사용된다.

인수로 넘겨주는 함수는 배열의 모든 요소를 대상으로 차례차례 적용되는데, 적용 결과는 다음 함수 호출 시 사용된다.
함수의 인수는 다음과 같다.
이전 함수 호출 결과는 다음 함수를 호출할 때 첫 번째 인수(previousValue)로 사용된다.
첫 번째 인수는 앞서 호출했던 함수들의 결과가 누적되어 저장되는 '누산기(accumulator)'라고 생각하면 된다. 마지막 함수까지 호출되면 이 값은 reduce의 반환 값이 된다.
reduce를 이용해 코드 한 줄로 배열의 모든 요소를 더한 값을 구해보자.

reduce에 전달한 함수는 오직 인수 두 개만 받고 있다. 대개 이렇게 인수를 두 개만 받는다.
이제 어떤 과정을 거쳐 위와 같은 결과가 나왔는지 자세히 알아보자.
-
함수 최초 호출 시, reduce의 마지막 인수인 0(초깃값)이 sum에 할당된다. current엔 배열의 첫 번째 요소인 1이 할당된다. 따라서 함수의 결과는 1이 된다.
-
두 번째 호출 시, sum = 1이고 여기에 배열의 두 번째 요소(2)가 더해지므로 결과는 3이 된다.
-
세 번째 호출 시, sum = 3이고 여기에 배열의 다음 요소가 더해진다. 이런 과정이 계속 이어진다.
계산 흐름
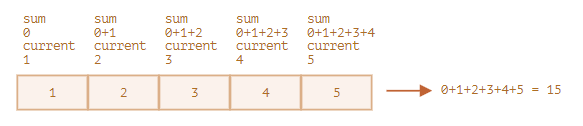
표를 이용해 설명하면 아래와 같다. 함수가 호출될 때마다 넘겨지는 인수와 연산 결과는 각 열에서 확인할 수 있다.
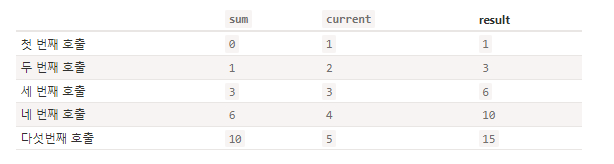
이제 이전 호출의 결과가 어떻게 다음 호출의 첫 번째 인수로 전달되는지 알았다.
또, 아래와 같이 초깃값을 생략하는 것도 가능하다.
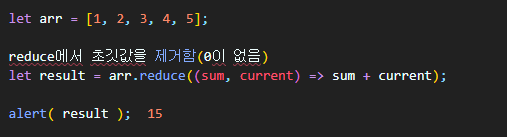
초깃값을 없애도 결과는 동일하다. 초깃값이 없으면 reduce는 배열의 첫 번째 요소를 초깃값으로 사용하고 두 번째 요소부터 함수를 호출하기 때문이다.
위 표에서 첫 번째 호출에 관련된 줄만 없애면 초깃값 없이 계산한 위 예제의 계산 흐름이 된다.
하지만 이렇게 초깃값 없이 reduce를 사용할 땐 극도의 주의를 기울여야 한다. 배열이 비어있는 상태면 reduce 호출 시 에러가 발생하기 때문이다.

이런 예외 상황 때문에 항상 초깃값을 명시해 주는 것이 좋다.
arr.reduceRight는 reduce와 동일한 기능을 하지만 배열의 오른쪽부터 연산을 수행한다는 점이 다른 메서드이다.
Array.isArray로 배열 여부 알아내기
자바스크립트에서 배열은 독립된 자료형으로 취급되지 않고 객체형에 속한다.따라서 typeof로는 일반 객체와 배열을 구분할 수가 없다.

그런데 배열은 자주 사용되는 자료구조이기 때문에 배열인지 아닌지를 감별해내는 특별한 메서드가 있다면 아주 유용하다.
Array.isArray(value)는 이럴 때 사용할 수 있는 유용한 메서드이다.
value가 배열이라면 true를, 배열이 아니라면 false를 반환해준다.

배열 메서드와 'thisArg'
함수를 호출하는 대부분의 배열 메서드(find, filter, map 등. sort는 제외)는 thisArg라는 매개변수를 옵션으로 받을 수 있다.thisArg는 아래와 같이 활용할 수 있다.

thisArg는 func의 this가 된다.
아래 예시에서 객체 army의 메서드를 filter의 인자로 넘겨주고 있는데, 이때 thisArg는 canJion의 컨텍스트 정보를 넘겨준다.

thisArgs에 army를 지정하지 않고 단순히 users.filter(army.canJoin)를 사용했다면 army.canJoin은 단독 함수처럼 취급되고, 함수 본문 내 this는 undefined가 되어 에러가 발생했을 것이다.
users.filter(user => army.canJoin(user))를 사용하면 users.filter(army.canJoin, army)를 대처할 수 있긴 한데 thisArg를 사용하는 방식이 좀 더 이해하기 쉬우므로 더 자주 사용된다.
