Nvidia Jetpack, DeepStream 기반 TensorRT 추론 테스트
오늘은 TAO 툴킷을 이용해 훈련시킨 객체 감지 모델을 TensorRT 모델로 내보내고, 이를 NVIDIA Jetson Nano에서 Deepstream SDK를 활용해 추론하는 과정을 포스팅합니다!
- 아래 과정은 x86 시스템에서(dgpu 사용) Tao로 모델을 학습/프루닝/재학습/내보내기 까지 마친 후 .etlt 모델 파일을 획득했다는 가정 하에 진행됩니다.
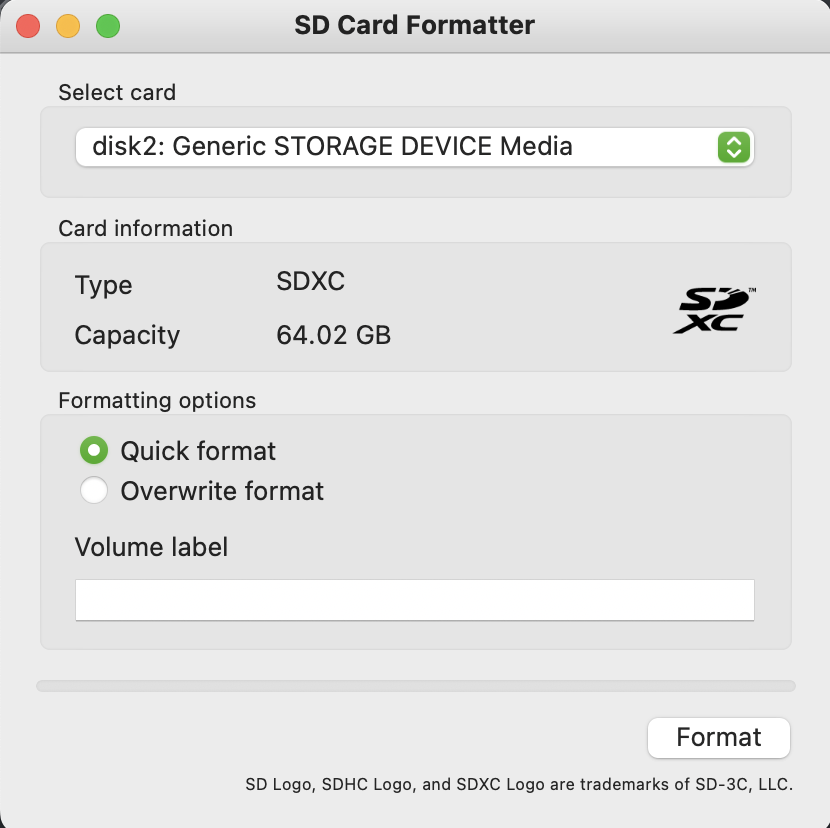
SD 카드 이미지 플래시 전 포맷
혹시 SD카드에 이미 플래시된 이미지가 있다면 포맷하고 진행합니다.
저는 맥의 SD Card Formatter를 주로 이용합니다!
- Quick Format이 아닌, Overwrite Format을 진행합니다!

JetPack 이미지 다운로드
- 진행해보니 젯슨 나노에서 부팅오류가 계속 발생합니다. 이유는 젯슨 나노는 jetpack 4.6.1 이후 지원이 중단되었습니다. latest인 5.0.2버전은 모든 JETSON ORIN 또는 XAVIER 개발자 키트에서만 사용이 가능합니다.(NANO는 불가능)

그래서 아카이브를 찾아가서 이전 버전을 찾아 다운로드합니다!
이번 과정에선 SD Card(64GB 이상)에 JetPack 이미지를 플래시합니다.
위 링크에서 jetpack 4.6.1 버전을 다운로드 받아 진행합니다.
다만 TAO Toolkit(이전의 TLT) 3.0-21.08 또는 이전 버전으로 개발된 모델을 사용하려는 사용자는 DeepStream 6.1.1과 함께 사용하기 전에 INT8 보정 캐시를 다시 생성해야 합니다.
저는 TAO 3.22.05 버전에서 모델을 생성하였고, 가상환경의 TensorRT를 확인해보면 Tao 3.22.05과 동일하게 TensorRT version: 8.2.5.1 버전을 맞추어 두었습니다.
jetpack 5.0.2 버전은 TensorRT 8.4.5.1 버전을 사용하고 있어서 모델이 호환이 될지는 모르겠지만 일단 진행합니다!
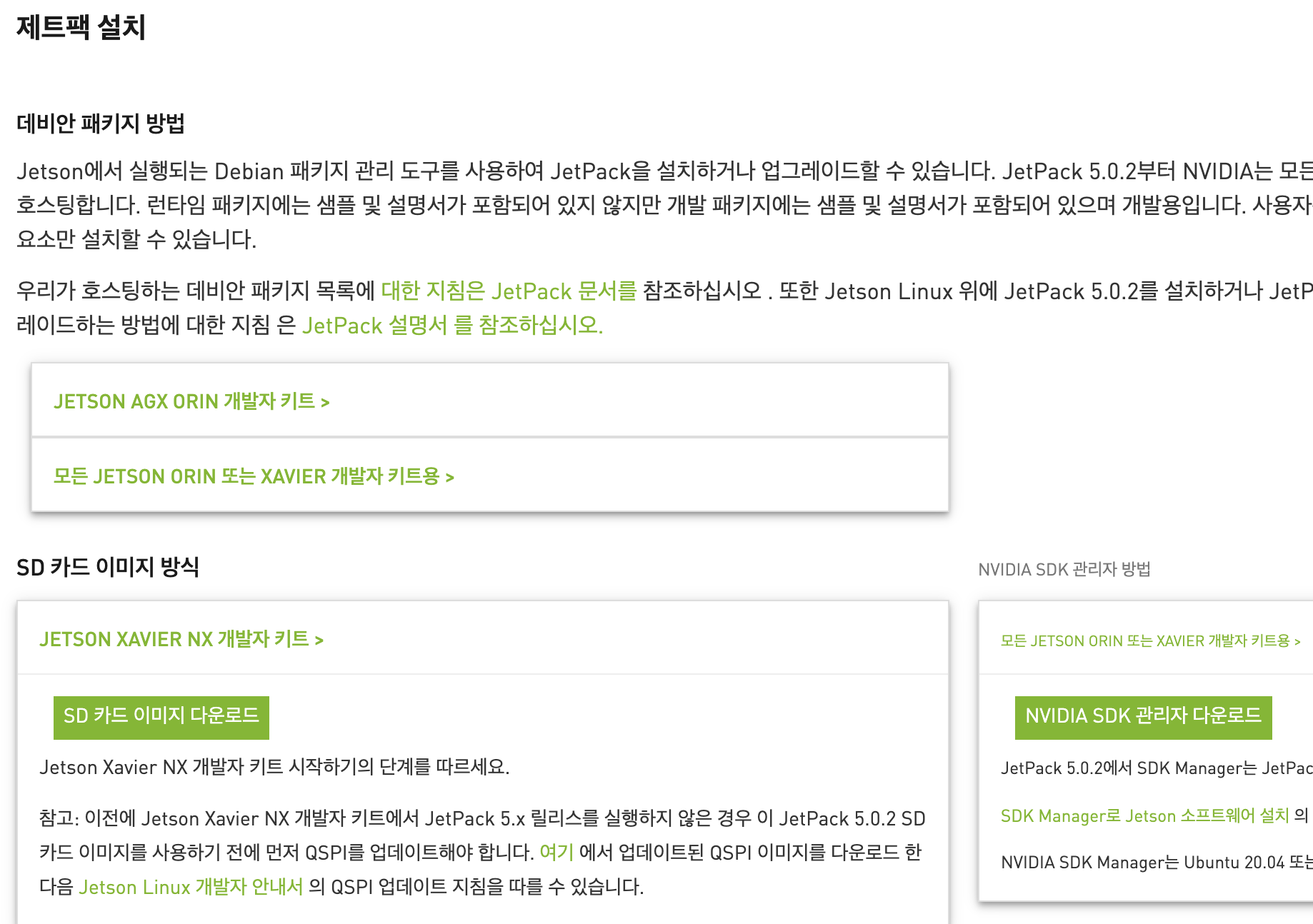
하단의 SD 카드 이미지 다운로드를 클릭하고, 다운로드가 완료되면 압축을 해제하여 이미지 파일을 획득합니다.
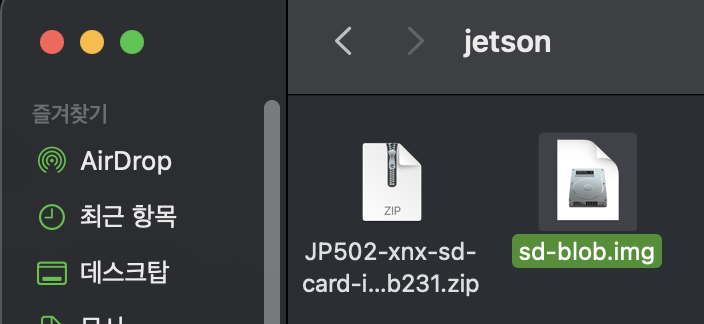
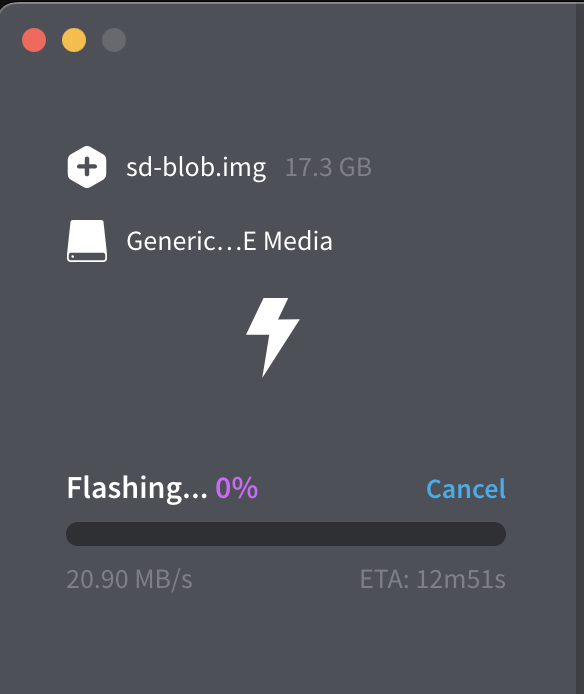
SD 카드 플래시
저는 balenaEtcher라는 애플리케이션을 사용했습니다.
사용할 이미지와 장치를 선택한 후 Flash합니다.

Flashing 및 Validating 과정이 모두 끝날 때까지 기다립니다.
우분투 기본 설정
이번 포스팅의 주 목적은 우분투 세팅이 아니여서 넘어갑니다!
처음 SD카드를 삽입하고 젯슨 모듈에 전원을 넣으면 OS가 부팅됩니다.
이후 우분투 기본 세팅(나라, 언어, 키보드 레이아웃, 파티션 사이즈, CPU 사용률) 등을 설정하게 됩니다.
파티션 사이즈 등은 나와있는 설명에 따라 최대로 설정해주시면 됩니다!
CUDA 경로 등록
jetpack 4.6.1 설치 후 CUDA 10.2를 바로 인식하지 문제가 있다면 아래와 같이 해결합니다.
vim ~/.bashrc
bashrc의 제일 아랫 부분의 아래 경로들을 등록하고 저장 후 터미널을 껐다가 다시 켭니다.
이후 nvcc -V으로 쿠다가 인시되고 있는지 확인할 수 있습니다.
export CUDA_HOME=/usr/local/cuda
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64
export PATH=$PATH:$CUDA_HOME/binJetson TensorRT OSS 빌드
- Jetson Nano 기준입니다.
- Cmake 설치(>=3.13)
sudo apt remove --purge --auto-remove cmake
wget https://github.com/Kitware/CMake/releases/download/v3.13.5/cmake-3.13.5.tar.gz
tar xvf cmake-3.13.5.tar.gz
cd cmake-3.13.5/
./configure
make -j$(nproc)
sudo make install
sudo ln -s /usr/local/bin/cmake /usr/bin/cmake- TensorRT OSS 빌드
#tensorRT 8.2.5.1, cuda 10.2, cudnn 8.2.1
git clone -b release/8.2 https://github.com/nvidia/TensorRT
cd TensorRT/
git submodule update --init --recursive
export TRT_SOURCE=`pwd`
cd $TRT_SOURCE
mkdir -p build && cd build/usr/local/bin/cmake .. -DGPU_ARCHS=53 -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=`pwd`/out
make nvinfer_plugin -j$(nproc)이슈 해결(Cub 관련)
make nvinfer_plugin -j$(noroc) 명령 실행 시
Fatal error: cub/cub.cuh: No such file or directory #include “cub/cub.cuh”
위와 같은 에러가 났다면 아래의 방법으로 해결합니다.
cd $TRT_SOURCE
vim CmakeLists.txt아래 쪽으로 스크롤을 내리다보면 include_directories 섹션이 있습니다.
아래 경로를 포함시킨 후 저장하고 나와주세요!
/home/jetson/TensorRT/third_party/cub
그 후 명령을 재실행하면 정상적으로 설치됩니다.
- 새로 생성된 것으로 "libnvinfer_plugin.so*"을 교체 합니다.
sudo mv /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.2.3 ${HOME}/libnvinfer_plugin.so.8.2.3.bak
sudo cp $TRT_SOURCE/build/libnvinfer_plugin.so.8.m.n /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.x.y
sudo ldconfigDeepStream 다운로드
-
의존성 패키지를 설치합니다.
sudo apt-get install libgstrtspserver-1.0-0 -
딥스트림을 설치합니다.
아카이브 링크
JetPack 4.6.1은 DeepStream 6.0.1 버전을 이용해야합니다!
따라서 latest(6.1.1)이 아닌, NVIDIA 로그인이 필요한 아카이브를 활용해 6.0.1 버전을 다운로드합니다.
여기서부터 전 팀뷰어를 활용해 젯슨 GUI에서 작업을 진행하고 있어서 스크린샷이 미비한 점 양해바랍니다.

젯슨에서 직접 진행하기 때문에 데비안 패키지를 이용하는게 제일 편해서 Download .deb를 진행하였습니다.
다운로드 후 설치합니다!
sudo dpkg -i deepstream-6.0_6.0.0–1_amd64.deb
설치 후엔 터미널에 /opt/nvidia/deepstream/deepstream-6.0에서 소스와 샘플 폴더를 확인할 수 있다는 안내가 나옵니다 :)
NVIDIA Tao 설치
도커 권한 변경
sudo usermod -aG docker $USER
젯슨을 종료한 뒤 다시 시작합니다!
nvcr.io 로그인
docker login nvcr.io
Username: $oauthtoken
Password: 개인 ngc키pip 설치
wget https://bootstrap.pypa.io/pip/3.6/get-pip.py
python3 get-pip.pyTao Launcher 설치
pip3 install nvidia-pyindex
pip3 install nvidia-taoTao-converter 설치
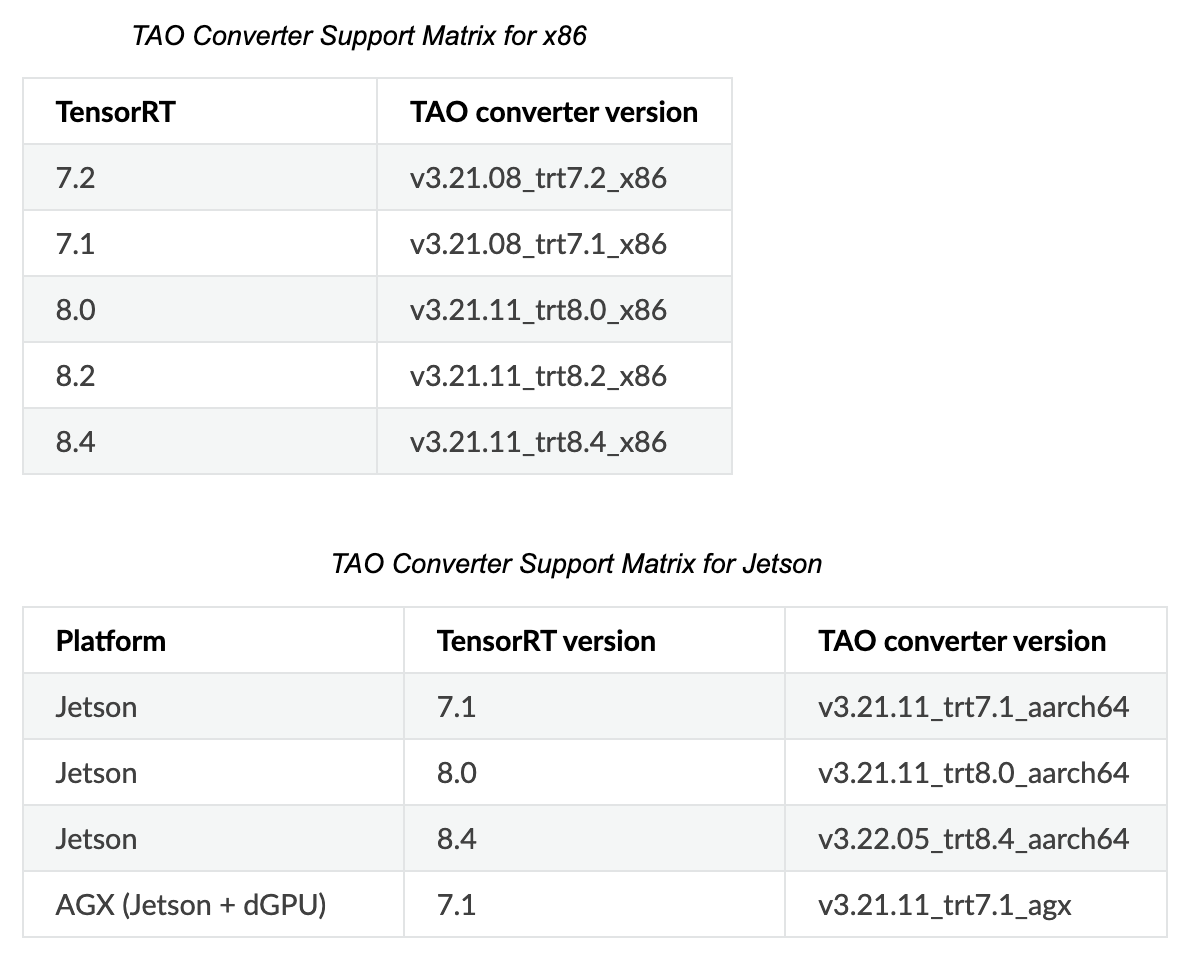
-
다운로드 ngc 링크
-
TensorRT 8.2 버전의 경우
-
8.2 버전이 필요하지만 젯슨엔 없어서 8.0버전을 다운로드했습니다.

-
젯슨 시스템에서 zip 파일의 압축을 풉니다.
-
다음 명령을 사용하여 OpenSSL 패키지를 설치합니다.
sudo apt-get install libssl-dev -
다음 환경 변수를 내보냅니다.
vim ~/.bashrc
export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
tao-converter 테스트
명령어가 동작하는지만 테스트해봅시다. tao-converter를 찾을 수 없다는 오류만 안나면 됩니다.
tao-converter [-h] -k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
input_filesudo ./tao-converter -k $KEY \
-p Input,1x3x384x1248,8x3x384x1248,16x3x384x1248 \
-e /export/trt.fp16.engine \
-t fp16 \
/ws/yolov4_resnet18_epoch_100.etlt
tao-converter 아규먼트
젯슨 나노에서 추론할 것이기 때문에 INT8 아규먼트는 신경쓰지 않아도 됩니다.(INT8 사용 불가)
- Required Arguments
input_file: The path to the .etlt model exported using tao yolo_v4 export.
-k: The key used to encode the .tlt model when training.
-d: A comma-separated list of input dimensions that should match the dimensions used for tao yolo_v4 export.
-o: A comma-separated list of output blob names that should match the output configuration used for tao yolo_v4 export. For YOLOv4, set this argument to BatchedNMS.
-p: Optimization profiles for .etlt models with dynamic shape. Use a comma-separated list of optimization profile shapes in the format <input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format: <n>x<c>x<h>x<w>. The input name for YOLOv4 is Input- Optional Arguments
-e: The path to save the engine to. The default path is ./saved.engine.
-t: The desired engine data type. The options are {fp32, fp16, int8}. The default value is fp32. A calibration cache is generated in INT8 mode.
-w: The maximum workspace size for the TensorRT engine. The default value is 1073741824(1<<30).
-i: The input dimension ordering; all other TAO commands use NCHW. The options are {nchw, nhwc, nc}.The default value is nchw, so you can omit this argument for YOLOv4.
-s: TensorRT strict type constraints. A Boolean to apply TensorRT strict type constraints when building the TensorRT engine.
-u: Specifies the DLA core index when building the TensorRT engine on Jetson devices (only needed if using DLA core).- INT8 Mode Arguments
-c: The path to the calibration cache file (only used in INT8 mode). The default value is ./cal.bin.
-b: The batch size used during the export step for INT8-calibration cache generation (default: 8).
-m: The maximum batch size for the TensorRT engine (default: 16). If you encounter an out-of-memory issue, decrease the batch size accordingly. This parameter is not required for .etlt models generated with dynamic shape (which is only possible for new models introduced since version 3.0).tao-converter로 모델 양자화
sudo ~/tao-converter -k <모델 훈련시킬 때 사용한 ngc 레지스트 키> \
-p Input,1x3x1024x1920,8x3x1024x1920,16x3x1024x1920 \
-e ~/deepstream_tao_apps/models/yolov4/musma.engine \
-t fp16 \
-d 3,1024,1920 \
~/deepstream_tao_apps/models/yolov4/yolov4_resnet18_musma.etlt샘플 애플리케이션 테스트
cd ~/
git clone https://github.com/NVIDIA-AI-IOT/deepstream_tao_apps
cd deepstream_tao_apps
make
https://github.com/NVIDIA-AI-IOT/deepstream_tao_apps./apps/tao_detection/ds-tao-detection -c configs/yolov4_tao/pgie_yolov4_tao_config.txt -i /opt/nvidia/deepstream/deepstream/samples/streams/sample_qHD.h264정보
-
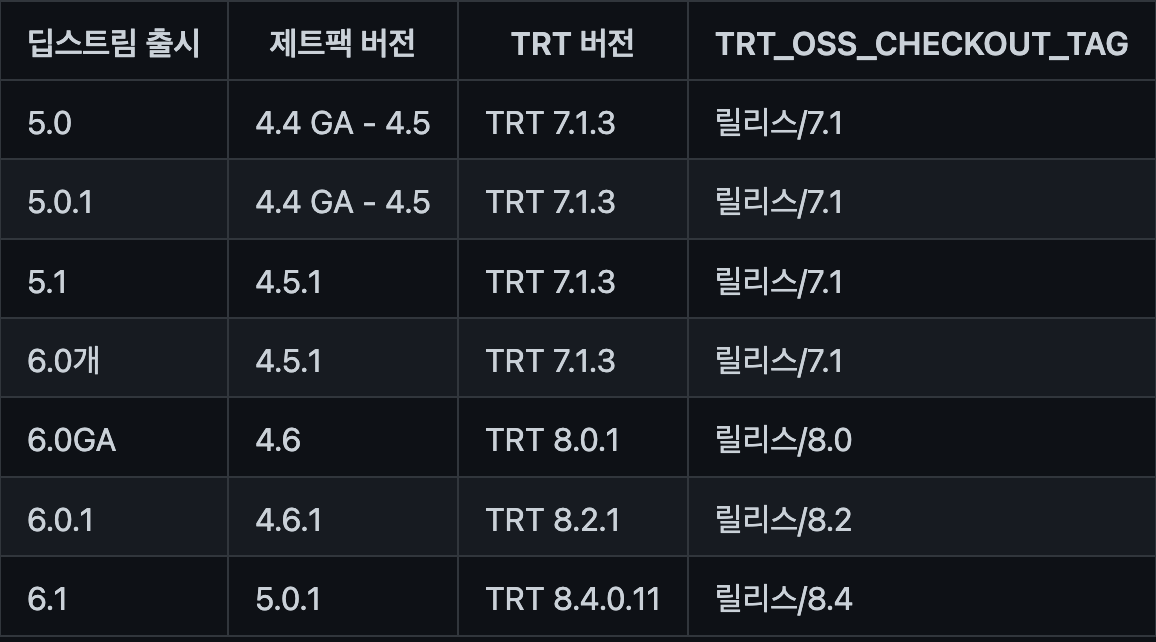
NVIDIA JetPack 4.6.1 Docs
- 모든 Jetson 모듈 지원(Nano 포함!)- TensorRT 8.2.1
- NVIDIA L4T는 부트로더, Linux 커널 4.9, 필요한 펌웨어, NVIDIA 드라이버, Ubuntu 18.04 기반 샘플 파일 시스템 등을 제공
- cuDNN 8.2.1
- CUDA 10.2
- DeepStream SDK 6.0.1 지원
-
Jetson Nano는 하드웨어적 한계로 INT8 추론이 불가능합니다. TAO로 학습 시 FP16이나 FP32를 이용해야합니다.
-
ERROR: [TRT]: 6: The engine plan file is not compatible with this version of TensorRT, expecting library version 8.2.1 got 8.2.5, please rebuild.
- 걱정하던 에러네요. 8.2.x버전은 호환이 될 줄 알았는데 호환되지 않습니다.
trtexec 사용하기
참조: https://eehoeskrap.tistory.com/545
- TensorRT 설치
/usr/src/tensorrt/samples에서 make 하여 빌드하기/usr/src/tensorrt/bin에 실행파일 생성됨/usr/src/tensorrt/bin/trtexec실행

예시: /usr/src/tensorrt/bin/trtexec --batch=1 --useSpinWait --loadEngine=musma.engine
&&&& RUNNING TensorRT.trtexec [TensorRT v8201] # /usr/src/tensorrt/bin/trtexec --batch=1 --useSpinWait --loadEngine=musma.engine
[09/21/2022-13:16:50] [I] === Model Options ===
[09/21/2022-13:16:50] [I] Format: *
[09/21/2022-13:16:50] [I] Model:
[09/21/2022-13:16:50] [I] Output:
[09/21/2022-13:16:50] [I] === Build Options ===
[09/21/2022-13:16:50] [I] Max batch: 1
[09/21/2022-13:16:50] [I] Workspace: 16 MiB
[09/21/2022-13:16:50] [I] minTiming: 1
[09/21/2022-13:16:50] [I] avgTiming: 8
[09/21/2022-13:16:50] [I] Precision: FP32
[09/21/2022-13:16:50] [I] Calibration:
[09/21/2022-13:16:50] [I] Refit: Disabled
[09/21/2022-13:16:50] [I] Sparsity: Disabled
[09/21/2022-13:16:50] [I] Safe mode: Disabled
[09/21/2022-13:16:50] [I] DirectIO mode: Disabled
[09/21/2022-13:16:50] [I] Restricted mode: Disabled
[09/21/2022-13:16:50] [I] Save engine:
[09/21/2022-13:16:50] [I] Load engine: musma.engine
[09/21/2022-13:16:50] [I] Profiling verbosity: 0
[09/21/2022-13:16:50] [I] Tactic sources: Using default tactic sources
[09/21/2022-13:16:50] [I] timingCacheMode: local
[09/21/2022-13:16:50] [I] timingCacheFile:
[09/21/2022-13:16:50] [I] Input(s)s format: fp32:CHW
[09/21/2022-13:16:50] [I] Output(s)s format: fp32:CHW
[09/21/2022-13:16:50] [I] Input build shapes: model
[09/21/2022-13:16:50] [I] Input calibration shapes: model
[09/21/2022-13:16:50] [I] === System Options ===
[09/21/2022-13:16:50] [I] Device: 0
[09/21/2022-13:16:50] [I] DLACore:
[09/21/2022-13:16:50] [I] Plugins:
[09/21/2022-13:16:50] [I] === Inference Options ===
[09/21/2022-13:16:50] [I] Batch: 1
[09/21/2022-13:16:50] [I] Input inference shapes: model
[09/21/2022-13:16:50] [I] Iterations: 10
[09/21/2022-13:16:50] [I] Duration: 3s (+ 200ms warm up)
[09/21/2022-13:16:50] [I] Sleep time: 0ms
[09/21/2022-13:16:50] [I] Idle time: 0ms
[09/21/2022-13:16:50] [I] Streams: 1
[09/21/2022-13:16:50] [I] ExposeDMA: Disabled
[09/21/2022-13:16:50] [I] Data transfers: Enabled
[09/21/2022-13:16:50] [I] Spin-wait: Enabled
[09/21/2022-13:16:50] [I] Multithreading: Disabled
[09/21/2022-13:16:50] [I] CUDA Graph: Disabled
[09/21/2022-13:16:50] [I] Separate profiling: Disabled
[09/21/2022-13:16:50] [I] Time Deserialize: Disabled
[09/21/2022-13:16:50] [I] Time Refit: Disabled
[09/21/2022-13:16:50] [I] Skip inference: Disabled
[09/21/2022-13:16:50] [I] Inputs:
[09/21/2022-13:16:50] [I] === Reporting Options ===
[09/21/2022-13:16:50] [I] Verbose: Disabled
[09/21/2022-13:16:50] [I] Averages: 10 inferences
[09/21/2022-13:16:50] [I] Percentile: 99
[09/21/2022-13:16:50] [I] Dump refittable layers:Disabled
[09/21/2022-13:16:50] [I] Dump output: Disabled
[09/21/2022-13:16:50] [I] Profile: Disabled
[09/21/2022-13:16:50] [I] Export timing to JSON file:
[09/21/2022-13:16:50] [I] Export output to JSON file:
[09/21/2022-13:16:50] [I] Export profile to JSON file:
[09/21/2022-13:16:50] [I]
[09/21/2022-13:16:50] [I] === Device Information ===
[09/21/2022-13:16:50] [I] Selected Device: NVIDIA Tegra X1
[09/21/2022-13:16:50] [I] Compute Capability: 5.3
[09/21/2022-13:16:50] [I] SMs: 1
[09/21/2022-13:16:50] [I] Compute Clock Rate: 0.9216 GHz
[09/21/2022-13:16:50] [I] Device Global Memory: 3956 MiB
[09/21/2022-13:16:50] [I] Shared Memory per SM: 64 KiB
[09/21/2022-13:16:50] [I] Memory Bus Width: 64 bits (ECC disabled)
[09/21/2022-13:16:50] [I] Memory Clock Rate: 0.01275 GHz
[09/21/2022-13:16:50] [I]
[09/21/2022-13:16:50] [I] TensorRT version: 8.2.1
[09/21/2022-13:16:52] [I] [TRT] [MemUsageChange] Init CUDA: CPU +229, GPU +0, now: CPU 265, GPU 2481 (MiB)
[09/21/2022-13:16:52] [I] [TRT] Loaded engine size: 17 MiB
[09/21/2022-13:16:53] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +158, GPU +164, now: CPU 424, GPU 2646 (MiB)
[09/21/2022-13:16:55] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +241, GPU +237, now: CPU 665, GPU 2883 (MiB)
[09/21/2022-13:16:55] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in engine deserialization: CPU +0, GPU +16, now: CPU 0, GPU 16 (MiB)
[09/21/2022-13:16:55] [I] Engine loaded in 5.45783 sec.
[09/21/2022-13:16:55] [I] [TRT] [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 647, GPU 2867 (MiB)
[09/21/2022-13:16:55] [I] [TRT] [MemUsageChange] Init cuDNN: CPU +1, GPU +0, now: CPU 648, GPU 2867 (MiB)
[09/21/2022-13:16:56] [I] [TRT] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +879, now: CPU 0, GPU 895 (MiB)
[09/21/2022-13:16:56] [W] Dynamic dimensions required for input: Input, but no shapes were provided. Automatically overriding shape to: 1x3x1024x1920
[09/21/2022-13:16:56] [I] Using random values for input Input
[09/21/2022-13:16:57] [I] Created input binding for Input with dimensions 1x3x1024x1920
[09/21/2022-13:16:57] [I] Using random values for output BatchedNMS
[09/21/2022-13:16:57] [I] Created output binding for BatchedNMS with dimensions 1x1
[09/21/2022-13:16:57] [I] Using random values for output BatchedNMS_1
[09/21/2022-13:16:57] [I] Created output binding for BatchedNMS_1 with dimensions 1x200x4
[09/21/2022-13:16:57] [I] Using random values for output BatchedNMS_2
[09/21/2022-13:16:57] [I] Created output binding for BatchedNMS_2 with dimensions 1x200
[09/21/2022-13:16:57] [I] Using random values for output BatchedNMS_3
[09/21/2022-13:16:57] [I] Created output binding for BatchedNMS_3 with dimensions 1x200
[09/21/2022-13:16:57] [I] Starting inference
[09/21/2022-13:17:00] [I] Warmup completed 1 queries over 200 ms
[09/21/2022-13:17:00] [I] Timing trace has 17 queries over 3.51529 s
[09/21/2022-13:17:00] [I]
[09/21/2022-13:17:00] [I] === Trace details ===
[09/21/2022-13:17:00] [I] Trace averages of 10 runs:
[09/21/2022-13:17:00] [I] Average on 10 runs - GPU latency: 204.347 ms - Host latency: 206.806 ms (end to end 206.811 ms, enqueue 5.15105 ms)
[09/21/2022-13:17:00] [I]
[09/21/2022-13:17:00] [I] === Performance summary ===
[09/21/2022-13:17:00] [I] Throughput: 4.83602 qps
[09/21/2022-13:17:00] [I] Latency: min = 206.051 ms, max = 208.07 ms, mean = 206.776 ms, median = 206.7 ms, percentile(99%) = 208.07 ms
[09/21/2022-13:17:00] [I] End-to-End Host Latency: min = 206.055 ms, max = 208.075 ms, mean = 206.781 ms, median = 206.706 ms, percentile(99%) = 208.075 ms
[09/21/2022-13:17:00] [I] Enqueue Time: min = 4.70243 ms, max = 5.43433 ms, mean = 5.17578 ms, median = 5.18939 ms, percentile(99%) = 5.43433 ms
[09/21/2022-13:17:00] [I] H2D Latency: min = 2.37451 ms, max = 2.45941 ms, mean = 2.44719 ms, median = 2.45215 ms, percentile(99%) = 2.45941 ms
[09/21/2022-13:17:00] [I] GPU Compute Time: min = 203.671 ms, max = 205.615 ms, mean = 204.321 ms, median = 204.245 ms, percentile(99%) = 205.615 ms
[09/21/2022-13:17:00] [I] D2H Latency: min = 0.00512695 ms, max = 0.00793457 ms, mean = 0.00710162 ms, median = 0.00732422 ms, percentile(99%) = 0.00793457 ms
[09/21/2022-13:17:00] [I] Total Host Walltime: 3.51529 s
[09/21/2022-13:17:00] [I] Total GPU Compute Time: 3.47346 s
[09/21/2022-13:17:00] [I] Explanations of the performance metrics are printed in the verbose logs.