
안녕하세요!
오늘은 DVC(Data Version Control)을 이용해서 ML 파이프라인에 사용되는 데이터와 모델의 레지스트리를 관리하는 방법에 대해 알아보려고 합니다.
서버 내에 코드(프로젝트)와 NFS(Network File System) 내에 데이터를 따로 구성해놓고 마운트해서 사용하는 아키텍처입니다.
이 때 프로젝트에 DVC를 설정해서, NFS에 연결하여 데이터를 읽고, 쓰는 것도 가능하며 버전 별로 git처럼 commit을 해놓고, 필요하면 버전을 변경해서 사용하는 것도 가능한 환경을 구축해보도록 하겠습니다.(Model도 NFS 내에 저장해두고 있기 때문에 동시에 진행합니다.)
DVC가 왜 필요한가요?
ML모델이 가치를 갖기위해서는 reproducibility(재현성)이 보장되어야합니다.
seed가 같다고 가정할 때 연구를 통해 얻는 인공지능 모델의 결과는 재현성을 보장해야 합니다. 많은 대회나 논문 검증 과정에서 사용한 데이터를 명시하고, 재현가능한 결과를 결과를 낼 수 있도록 제약사항을 두기도 하죠.
하지만 데이터는 항상 변화합니다. 사람에 의해서 변경될 수도 있고(수정, 삭제, 추가 등) 자동으로 습득하도록 만들어 놓은 데이터는 데이터가 계속 추가되기도 합니다. 마지막으로 예를 들면 매분 온도를 취득하는 데이터에서 7일치를 사용하여 모델을 학습시킨다고 했을 때, 각 1분의 온도 차이는 전혀 크지 않아 1~7일치 데이터나 2~8일치 데이터나 결과가 비슷하겠지만, 여름과 겨울의 데이터는 전혀 다른 성능을 가진 모델을 내놓게 되겠죠.
그래서 MLOps에선 데이터와 모델의 버전을 관리해서 재현가능한 결과를 만들길 원합니다. 언제나처럼 나올 수 밖에 없는 이야기지만 논란이 되었던 이루다의 경우, 악의적인 데이터가 수집되기 전의 데이터가 버저닝되어 있었다면 이전 버전의 모델로 그대로 돌아갈 수 있었겠죠?
기초과정
DVC install
공식설치 지원 : https://dvc.org/
- 데비안/우분투의 경우
- 다운로드 파일을 얻어옵니다.
wget https://github.com/iterative/dvc/releases/download/2.10.2/dvc_2.10.2_amd64.deb - 설치를 진행합니다.
sudo apt install ./dvc_2.10.2_amd64.deb - 설치파일을 삭제합니다.
sudo rm -rf ./dvc_2.10.2_amd64.deb
- 다운로드 파일을 얻어옵니다.
- 잘 설치되었나 확인합니다.
dvc --version

번외. pip install 'dvc[all]'==2.8.1
- dvc[all]: dvc 의 remote storage 로 s3, gs, azure, oss, ssh 모두를 사용할 수 있도록 관련 패키지를 함께 설치하는 옵션입니다.
dvc init
DVC는 Git과 마찬가지 개념으로 사용하실 수 있습니다.
보통 Git Repository 내에서 DVC를 운용합니다.
먼저 사용하고자 하는 프로젝트에서 git init 혹은 git clone을 통해 git 정보를 받아옵니다.
후에 dvc init을 통해 해당 프로젝트에 dvc 정보를 초기화시킵니다.
- [서버 측에서 수행] 서버 스토리지(데이터를 내보낼 주체)에서 데이터를 DVC에 올려 Tracking합니다.
$ git clone <프로젝트 url>
$ cd <프로젝트폴더>
$ dvc destory # 기존에 작업하던 dvc 진행상황이 있다면.(cache 등 모든 내용이 삭제됩니다)
$ dvc initdvc remote
원격으로 사용할 데이터 스토리지를 지정합니다.
예를 들어 클라이언트에서 추가/변경/삭제한 데이터가 원격 스토리지에 반영(dvc add, push)될 수 있고,
원격 스토리지에서 추가/변경/삭제한 데이터가(dvc add, push) 클라이언트로 반영될 수도 있습니다.
S3, Google cloud, NAS, SSHFS 등 다양한 스토리지를 지원합니다.
현재 진행중인 프로젝트는 클라우드 과금이 필요하지 않은 온프레미스 인프라 구축을 기반으로 하기 때문에 파이프라인에 사용하고 있는 NAS(NFS로 마운트)를 기반으로 ssh 접속을 통해 설정하는 예제입니다. 참고바랍니다!
$ mkdir /mnt/nfs/cache
# 데이터 캐시를 저장할 디렉토리를 생성합니다.
# 캐시는 많은 디렉토리, 파일이 생성되니 사용중인 데이터 디렉토리와 섞이지 않도록 따로 생성해주었습니다.
$ dvc remote add -d <사용할 remote이름> ssh://<external-ip><경로>
# 원격 스토리지 설정합니다. 저는 ssh를 이용해 서버 내에 스토리지(NFS)를 활용했습니다.
# 예시 : dvc remote add -d data ssh://xxx.xxx.xxx.xxx/mnt/nfs/cache
$ dvc remote default data
$ dvc remote modify <설정한 remote이름> user <서버 유저 이름(접속정보)>
$ dvc remote modify <설정한 remote이름> port <열어놓은 포트(서버에 접근 가능한 포트를 열어두어야 합니다)>
$ dvc remote modify <설장한 remote이름> password <서버 비밀번호>dvc add
버전 1.0의 데이터를 dvc에 올려봅시다.
다음 버전은 중복 파일을 검사하고 dvc에 캐시를 등록할 예정입니다.(작성 예정)
dvc add는 DVC는 파일 내용을 캐시로 이동합니다.
또한 캐시된 데이터를 식별하기 위해 경로와 해시를 사용하여 파일을 추적하기 위해 데이터 폴더에 .dvc명명된 해당 파일 을 생성합니다. data.dvc또한 파일 .gitignore이 Git 리포지토리에 커밋되지 않도록 데이터 폴더에 파일을 추가합니다.
일단 올리고자 하는 데이터/mnt/nfs/* 를 프로젝트 내 ./data/ 폴더 안으로 옮겨줍니다.
그리고 dvc add를 통해 data 내부의 폴더를 추적합니다.
dvc push를 통해 데이터의 캐시를 생성하고(/mnt/nfs/cache/ 내에 생성됩니다)
dvc remote, add 등을 통해 만들어진 .dvc(config, cache 등)와 data.dvc(데이터 메타파일)을 git add로 Stage로 올려줍니다.(버전관리)
이후 커밋과 태그로 데이터 버전과 코드 버전을 지정하고 push하여 마무리합니다.
mkdir data # DVC를 통해 공유할 실제 데이터 폴더입니다.(cache만 github에 올라갑니다.)
cp -r /mnt/nfs/* ./data/ # 실제 데이터가 존재하는 스토리지(여기선 NFS)에서 저장할 데이터를 프로젝트 데이터 폴더내로 복사합니다.
dvc add data # data 폴더의 변경된 데이터의 모든 내용을 커밋합니다.
dvc push
git add .
git commit -m "Test: upload Dataset v1.3"
git tag -a "v1.3" -m "dataset v1.3" # 커밋에 태그를 달아 추후에 버전관리로 활용합니다.
git push
- [클라이언트에서 수행] git과 함께 수정된 dvc를 토대로 데이터를 받아옵니다.
프로젝트를 생성하고, git pull을 통해 받아온 dvc 정보가 잘 들어왔는지 확인합니다.
git에는 데이터 파일이 업로드되어 있지 않지만
data.dvc에 저장된 내용을 토대로 /mnt/nfs/cache에 push되어 있던 데이터를 받아올 수 있습니다.
git clone <프로젝트 url> # .dvc 내용은 있지만 실제 데이터는 존재하지 않습니다.(대용량 데이터는 git을 통해 전달하지 않음)
cd <프로젝트폴더>
dvc remote default data
dvc pull # .dvc/cache에 저장된 데이터의 내용을 토대로 데이터를 가져옵니다.
dvc checkout
dvc는 데이터/모델의 버전을 변경하기 위해 사용합니다. 버전을 변경하는 방법을 알아봅시다!
train.py에서 일부 하이퍼파라미터를 변경하고 새 모델을 훈련한다고 가정합니다.
훈련 후 model_output에는 새 모델 파일이 있다고 가정합니다.
dvc add model_output
git commit model_output.dvc -m "dvc: Model Updata vx.x"
dvc push
git push origin master위와 같이 새 버전의 데이터/모델을 dvc에 push합니다.
git checkout <commit>
dvc checkout이전 데이터의 버전으로 전환할 때는 위와 같이 사용하고자 하는 해당 커밋으로 돌아와 당시의 dvc 내용으로 돌아가면 됩니다!
심화과정
Docker로 데이터 업데이트를 자동화해보자!
명령어는 리눅스 기준으로 진행합니다. macOS와 Windows의 경우 명령어가 약간 다를 수 있지만 크게 다르지 않으니 서치해서 진행해보시면 되겠습니다.
실무에서 dvc를 어떻게 활용해야 할까 고민이 많았습니다.
시계열 데이터는 실시간으로 쌓여가고, 하루에 한 번 학습을 시킨다고 가정해봅시다.
하루에 한 번 새로운 훈련 데이터가 만들어지고, 새로운 모델도 만들어지겠죠?
당연히 오늘의 훈련 데이터와 모델에 대한 버전관리가 필요하고, ML Pipeline에서 이를 자동화하고 싶습니다.
플로우를 정리해봅시다!
- 데이터를 수집한다. 2. 훈련 데이터로 정제한다. 3. 훈련데이터를 저장한다. 4. 모델을 학습한다. 5. 모델을 검증한다. 6. 모델을 저장한다. 7. 모델을 서빙한다. 8. 모델을 모니터링한다. 9. 모델을 비교한다. 10. 이전 모델로 돌아간다.
아래와 같은 상황에서 (3), (6), (10) 등의 데이터 레지스트리를 관리해야 하는 부분을 도커를 통해 컨테이너화하고, 이를 Kubeflow pipeline으로 연결하여 전체 파이프라인 과정에 삽입하고자 합니다.
일단 자동으로 변경된 데이터를 dvc에 push할 수 있는 도커 이미지를 만들어야겠죠?
먼저 서버 내 스토리지(저의 경우 NFS, 데이터-모델이 모두 저장되어 있습니다.)에 dockerfile을 만들어 데이터를 모두 dvc로 push 할 수 있는 컨테이너를 구축해보겠습니다.
- git에 접근하기 위한 서버 ssh key 생성
Private repository에 접근하기 위해선 다양한 방법이 있겠지만, 저는 서버에서 ssh 키 파일을 생성하고, 이를 레포지토리에 등록해서 인증된 접근 키로 만들어 도커 이미지에 활용하고자 합니다.(도커 이미지에서도 git에 접근하여 코드와 데이터 버전을 관리하고, checkout하기 위해선 인증 정보가 필요하기 때문입니다.)
ssh-keygen -t rsa: 서버의 ssh 공개 키, 비밀 키를 생성합니다.
- 키 파일의 위치는 어디로 하는지 등 입력값을 두 번 물어보는데, 그냥 두 번 엔터쳐서 기본값으로 진행해주세요!
- id_rsa라는 private_key와 id_rsa.pub라는 public_key가~/.ssh에 생성됩니다.- 해당 파일을 Dockerfile 내에 복사해서 사용할 예정입니다.(물론 보안을 위해 도커 이미지 내에 복사되지 않으니 내용을 계속 확인해주세요!)
도커파일 :
# 1st Stage
FROM python:3.8-slim-buster AS builder
LABEL maintainer="Roh haram <moey920@naver.com>"
RUN apt-get update && apt-get install -y git python3-pip
RUN pip install 'dvc[ssh]'
RUN mkdir -p -m 0600 /root/.ssh && ssh-keyscan github.com >> /root/.ssh/known_hosts
# ADD SSH Key into Docker container
ADD ./.ssh/id_rsa /root/.ssh/id_rsa
# 2nd Stage
FROM python:3.8-slim-buster
LABEL maintainer="Roh haram <moey920@naver.com>"
#copy all the settings from 1st stage to avoid leak secrets
COPY --from=builder /usr/local/lib/python3.8/site-packages /usr/local/lib/python3.8/site-packages
RUN mkdir /code
COPY . /code/
WORKDIR /code
RUN mkdir ./automl/data
WORKDIR /code/automl[클라이언트 사이드]
1. git fetch origin --tags
2. git tag # 태그 목록 조회
2. git checkout
실험용(따라하지 마세요)
DVC cache
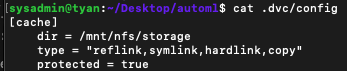
mkdir <NFS 내 캐시폴더로 사용할 경로>dvc cache dir <NFS 내 캐시폴더로 사용할 경로>cat .dvc/configdvc config cache.type "reflink,symlink,hardlink,copy"- 실제 파일이 프로젝트 내로 복사되는 것을 피하기 위해 심볼릭 링크를 활성화합니다.
- ML 데이터는 보통 수십GB부터 TB단위까지 커지기 때문에 실제로 프로젝트내로 복사해서 사용하지 않을 계획입니다. => 그래서 Cache를 활용합니다.
dvc config cache.protected true- 실수로 링크를 손상시키지 않도록 링크를 RO로 만듭니다.
git add .dvc .gitignore- 수정한 내용을 git stage에 올립니다.
git commit -m "Feat: initialize DVC with NFS cache"

이제 NFS 데이터를 버전 컨트롤 하기 위한 초기화가 완료되었습니다!
DVC add
현재 데이터(버전 1.0)을 올려볼까요?
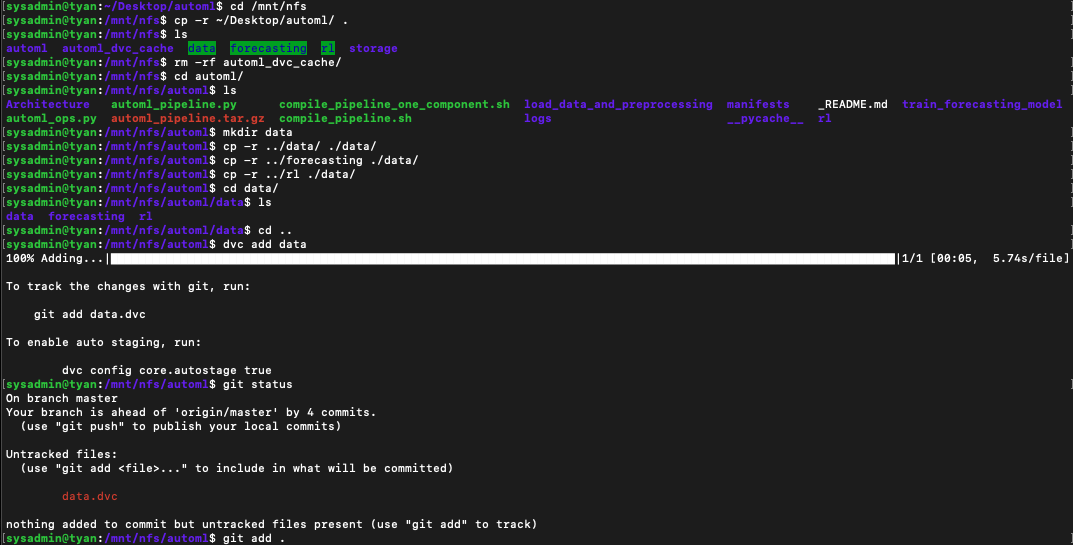
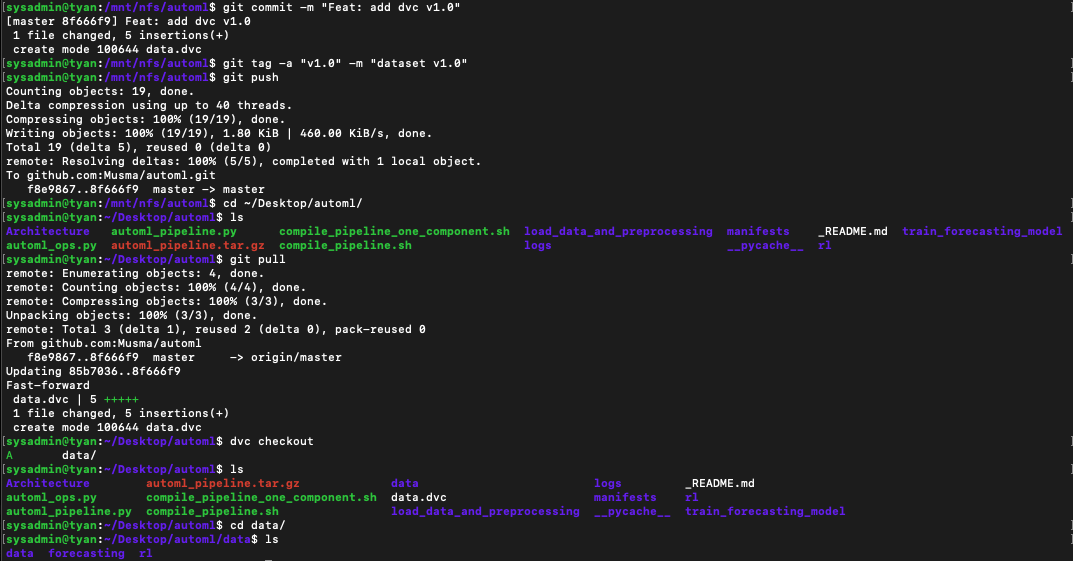
1. cd /mnt/nfs : nfs 폴더로 이동합니다.
2. cp -r ~/Desktop/automl/ . : 프로젝트 폴더를 NFS 폴더 내로 복사합니다.
3. cd automl \ mkdir data : NFS 내 프로젝트 폴더 내에 DVC와 연동할 디렉토리를 생성합니다.
4. cp -r ../data ./data/ : NFS에서 버전을 관리할 데이터들을 프로젝트 내 데이터 폴더 옮겨줍니다.(프로젝트 내 데이터 폴더명은 임의로 설정하셔도 상관없습니다!!)
5. dvc add data : dvc에 데이터 폴더의 변경 내용을 추가합니다.
6. git add . : 변경된 data.dvc 내용을 git에 추가합니다.
7. git commit -m "커밋메세지" : git commit을 진행합니다.
8. git tag -a "v1.0" -m "dataset v1.0" : 태그를 붙여줍니다.
9. git push
10. cd ~/Desktop/automl : 본래 프로젝트 폴더로 이동합니다.
11. git pull : 위에서 커미한 data.dvc를 가져옵니다.
12. dvc checkout : 현재 버전의 dvc 내용을 프로젝트 내로 가져옵니다.
13. ls : 위에서 만들어둔 데이터를 정상적으로 가지고 올 수 있는지 확인합니다.
추가 필요한 기능
-
자동화
-
중복 데이터 탐지
-
실데이터가 아닌 캐시만 넘기기
-
remote config의 서버 비밀번호 숨기는 등 보안 향상하기
- config에서 password 삭제 -> Permission Denied 오류해결! password를 애초에 커밋정보에 넣지 않습니다. password가 필요하다면 개발자에게 문의하라는 README.md만 남겨둡시다.
- 서버사이드에선 dvc add, dvc push를 완료한 후 password 정보를 제거하고 git add, commit을 수행합니다.
- 이후 클라이언트에선 dvc remote config data password 로 패스워드 설정 후 dvc pull을 진행합니다.

안녕하세요, 혹시 '추가 필요한 기능' 부분 구현도 다 완료 되셨을까요?