배경지식
- Parallelism이란
- 큰 모델과 대량의 데이터셋을 여러 개의 GPU를 활용해 학습하기 위한 병렬화 방식
- 분산학습을 위해 필수적
- 어떻게 병렬화를 구성하느냐에 따라 기본적으로는 Data Parallelism, Tensor Parallelism, Pipeline Parallelism 등으로 나뉨
- 최근에는 이에 더해 Context Parallelism, Expert Parallelism도 등장
- 하나의 Parallelism만 선택할 수 있는 것이 아니라, 여러 개의 Parallelism 전략을 동시에 사용할 수 있음
- 큰 모델과 대량의 데이터셋을 여러 개의 GPU를 활용해 학습하기 위한 병렬화 방식
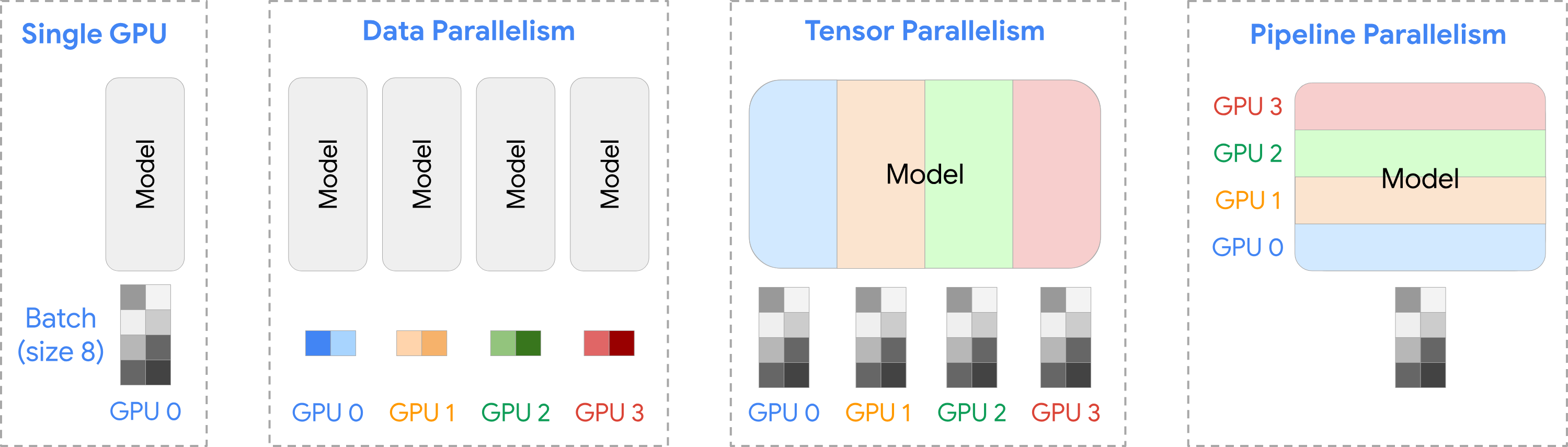
Data Parallelism
- 여러 개의 GPU에 데이터를 동등하게 분배하는 방식
- 각 GPU는 모델의 복사본을 갖고 있고, 각 GPU에 할당된 데이터에 대해 동시에 처리
- 각 GPU에서의 결과가 최종적으로 결합되고 동기화됨
- DataParallel(DP), DistributedDataParallel(DPP) 방식으로 나뉨
- DDP의 경우 GPU간 통신의 오버헤드를 감소시키고, 각 GPU를 더욱 효과적으로 사용할 수 있어 선호됨
Pipeline Parallelism
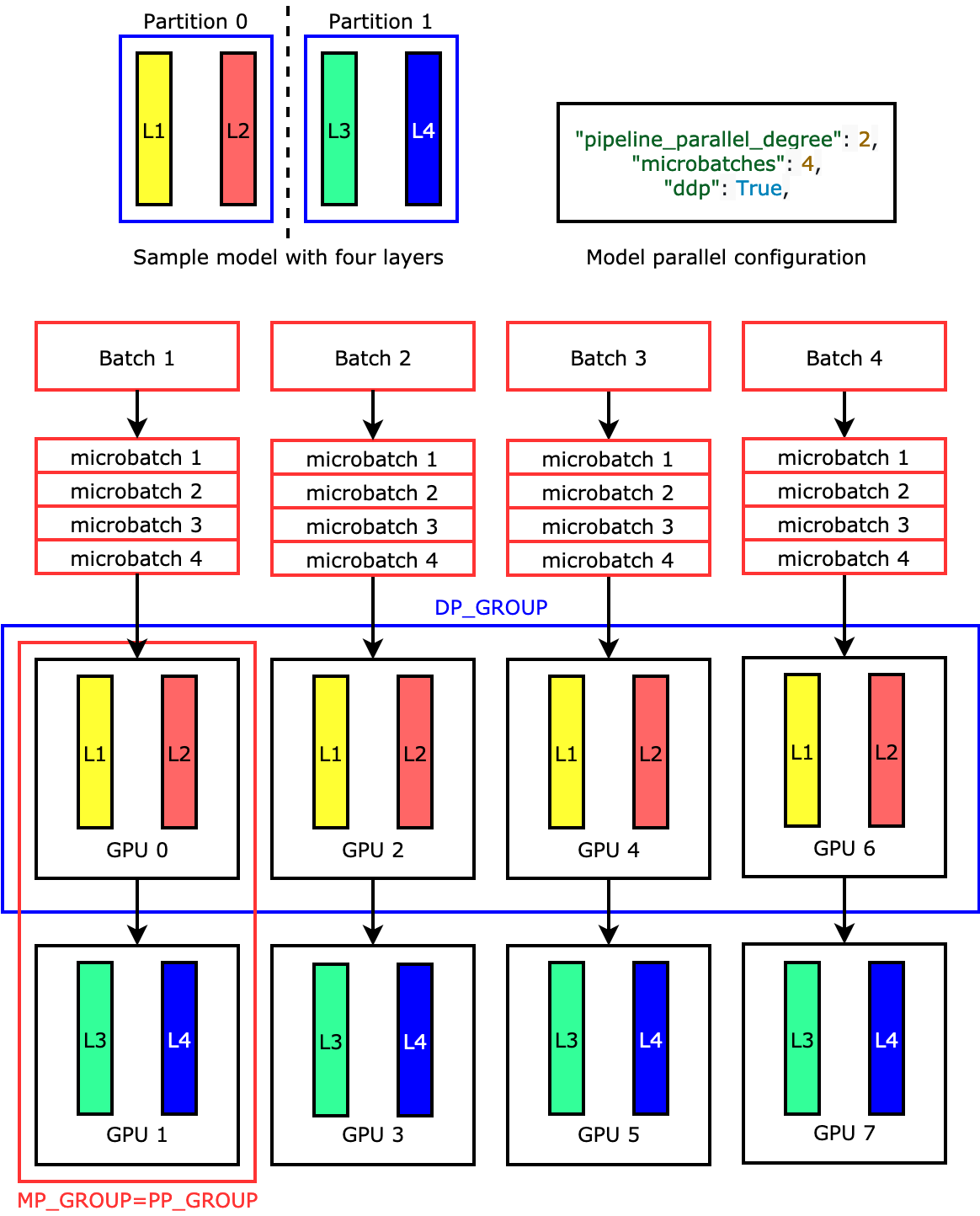
- 하나의 GPU에 모델이 올라가지 않을 때 사용할 수 있는 방법
- 여러 개의 GPU에 모델의 레이어별로 모델을 분산하는 Model Parallelism과 개념적으로 유사
- 하지만 Model Parallelism 대비 GPU가 사용되지 않는 시간(=idle GPU time)을 감소시켜 더욱 효율적
- 각 GPU가 하나의 데이터 배치를 처리할 때까지 기다리는 것이 아니라, 마이크로 배치를 만들어서 각 GPU가 동시에 데이터를 처리할 수 있도록 함
Tensor Parallelism
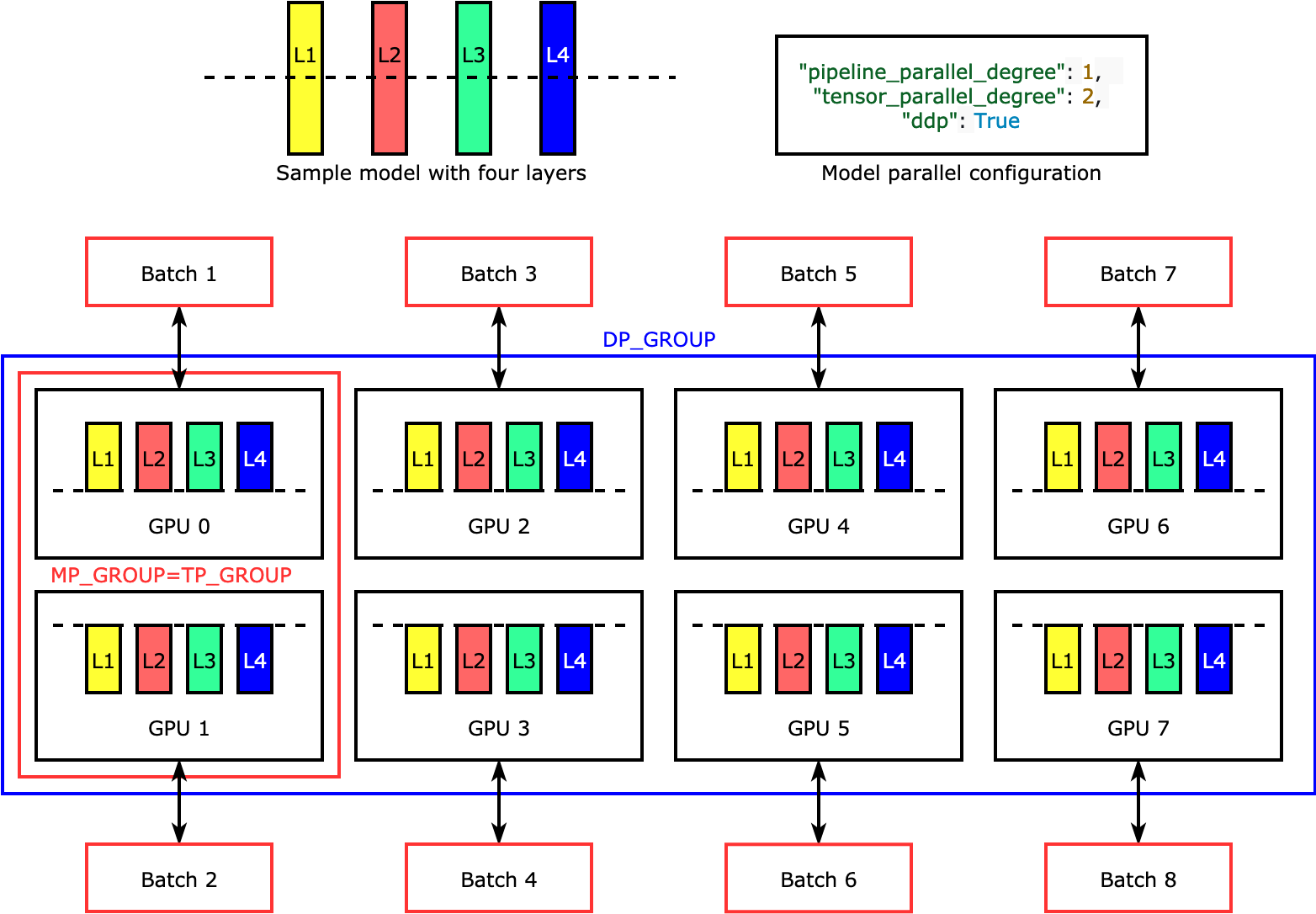
- 하나의 GPU에 모델이 올라가지 않을 때 사용할 수 있는 방법
- 여러 개의 GPU에 거대한 텐서 연산을 분산하는 방식
- 각 GPU는 텐서에 대한 연산을 수행하고, 결과가 동기화되어 마지막에 최종 결과를 재구조화하는 방식
Context Parallelism
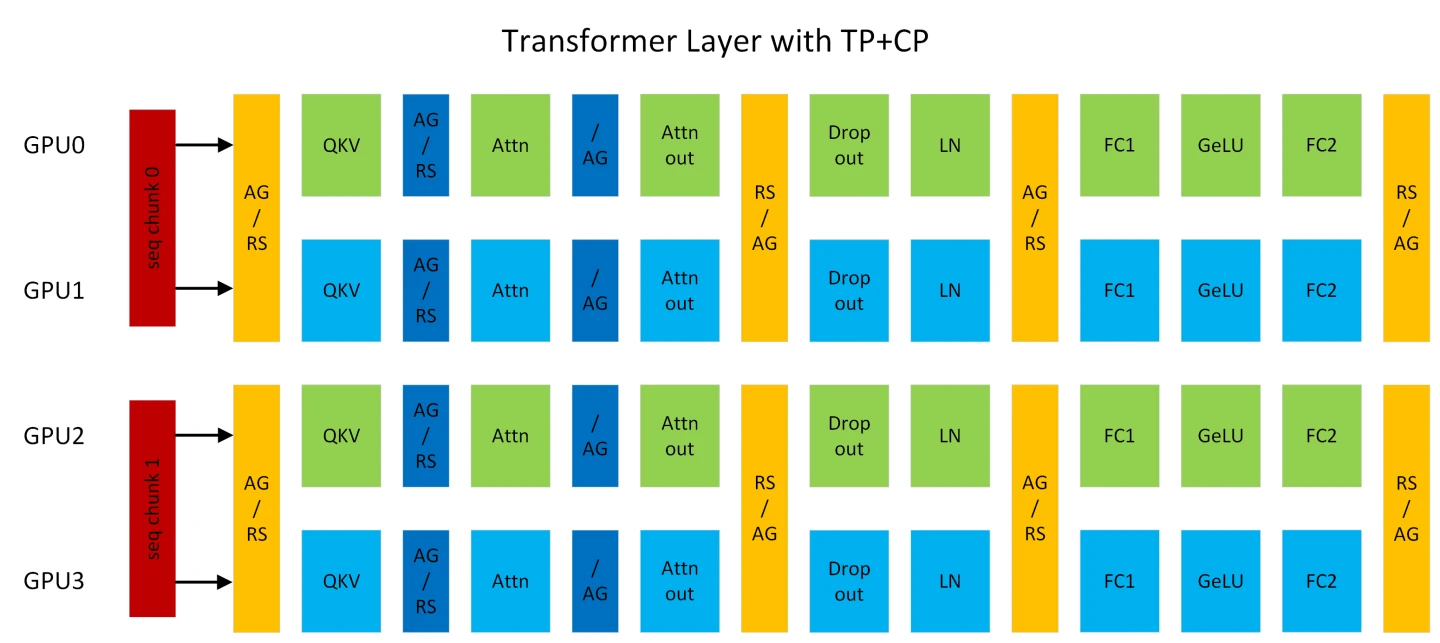
- 시퀀스 길이를 여러 개의 GPU로 병렬화하는 방식
- 긴 컨텍스트를 사용할 때 발생할 수 있는 OOM 이슈를 해결할 수 있음
- Attention을 제외한 모든 모듈은 토큰 간 연산이 없기 때문에 기존 방식대로 동작
- Attention의 경우 각 토큰의 Query는 같은 시퀀스에 있는 모든 토큰과의 KV를 계산해야 하기 때문에 GPU간 all-gather 통신이 필요, 또한 backward propagation(역전파) 시에 reduce-scatter 통신 또한 필요
- 각 GPU가 로컬 어텐션을 계산하고 이를 결합함으로써, 전체 어텐션과 거의 동일한 결과를 얻으면서도 파티션 크기만큼 GPU 메모리 사용량을 줄임
Expert Parallelism
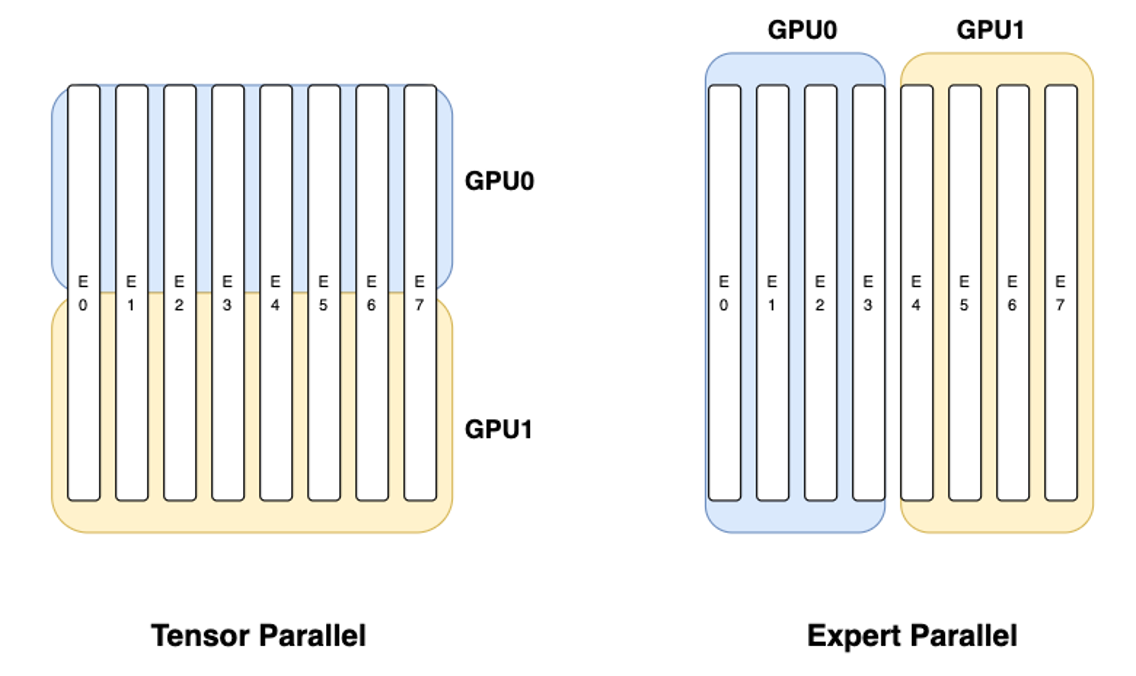
- MoE(Mixture of Experts)란, experts(전문가)라고 불리는 모델의 일부 요소만 각 인풋에 대해 동작하는 네트워크 아키텍처
- 전통적인 LLM이 dense model이라면, sparse한 접근 방식을 취하는 모델
- 효율적인 학습, 빠른 추론 등의 장점을 가짐
- 일반적으로 feed-forward network로 이루어진 여러 개의 expert와, 토큰을 어떤 expert로 보낼지 결정하는 router로 구성됨
- e.g. DeepSeek 모델
- Expert Parallelism이란, MoE 모델의 각 expert를 여러 개의 GPU를 사용해 효율적으로 핸들링하는 병렬화 방식
- 그림에서 E0, E1, E2, ...가 모두 MoE 모델의 expert라고 볼 수 있음
참고 링크

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab