2025년 3월 공개된 Cohere의 111B 모델: Command A (HuggingFace 모델 링크, Technical Report 링크)
소개
- 실제 기업 사용 특화 목적으로 개발된 LLM
- 에이전트 최적화, 다국어 지원 (23개 언어), RAG 성능 우수
- 연산 오버헤드 적음
- 1초당 최대 156토큰 처리 가능 (GPT-4o의 1.75배, DeepSeek V3의 2.4배)
학습
사전학습 (Pre-training)
- self-supervised 학습 (e.g. next token prediction) 활용
- 특정 다운스트림 태스크에 파인튜닝될 수 있는 다재다능한(versatile) 모델 학습
데이터
- 웹에 공개된 텍스트 및 코드 데이터
- 교육 샘플의 비중을 늘리고 저품질 데이터의 비중을 줄임
- 중복 제거, 경험에 기반한(heuristic) 품질 필터링, ML 기반 품질 필터링 등 진행
- 내부적으로 생성된 합성 데이터 (synthetic data)
- 사람이 작성한 instruction-tuning 데이터
- 데이터 판매자들로부터 구매한 고품질의 데이터
모델 아키텍처
- SwiGLU 활성화 함수
- Interleaved Attention 레이어
- sliding window attention 레이어와 full attention 레이어 3:1 비율로 섞어서 사용
- sliding window attention은 RoPE (Rotary Positional Embeddings) 사용
- full attention 레이어는 NoPE (No Positional Embeddings) 사용
- GQA (Grouped Query Attention)
- 서빙 throughput 증가를 위해 사용, 배치에서 각 시퀀스가 각자만 attend할 수 있도록 document masking 적용
- Parallel transformer block
- 일반 transformer block보다 성능은 유사, throughput 향상
- Bias 없음
- 큰 규모에서 학습 안정성 향상
- 인풋, 아웃풋 임베딩 공유
사전학습 레시피
- 작은 규모에서 하이퍼파라미터 스케일링 적용 후 이관
- JAX 기반 분산학습 진행 (NVIDIA H100 GPU)
- Data Parallel (DP)
- 일반적인 데이터 병렬 학습처럼 작동
- 배치 차원에서 activation을 샤딩
- Fully Sharded Data Parallel (FSDP)
- 배치 차원에서의 activation 샤딩과 더불어 명시된 차원에 대해 model state 또한 샤딩
- 데이터 병렬 축을 따라 model state가 복제됨
- Sequence Parallel (SP)
- 시퀀스 차원에 따라 activation을 샤딩
- DP, FSDP를 사용하는 경우보다 GPU 확장에 유리
- Tensor Parallel (TP)
- 메가트론(Megatron) 방식의 샤딩
- 빠른 디코딩과 작은 배치 사이즈일 경우 활용
- 사전학습 시에는 DP, FSDP, SP의 조합을 활용해 activation 통신을 최소화하도록 최적화
- Data Parallel (DP)
- FP8 텐서 코어 등 활용 (Hopper-specific)
- 주요 가중치와 optimizer state는 FP32로 유지, 연산 전에 모델 가중치를 BF16 혹은 FP8로 캐스트
- 민감한 연산 (e.g. exponential, softmax, ...)은 FP32로 진행, attention 연산은 BF16으로 진행행
쿨다운
- 선형적으로 학습률(learning rate)을 감소시킴 (BF16, 고품질 데이터 활용)
- Context length는 8k 토큰부터 시작해 32k, 128k, 256k로 확장
- 긴 문맥을 학습하는 단계에서는 데이터셋의 비율이 도메인별로 균형잡히도록 조정
사후학습 (Post-Training)
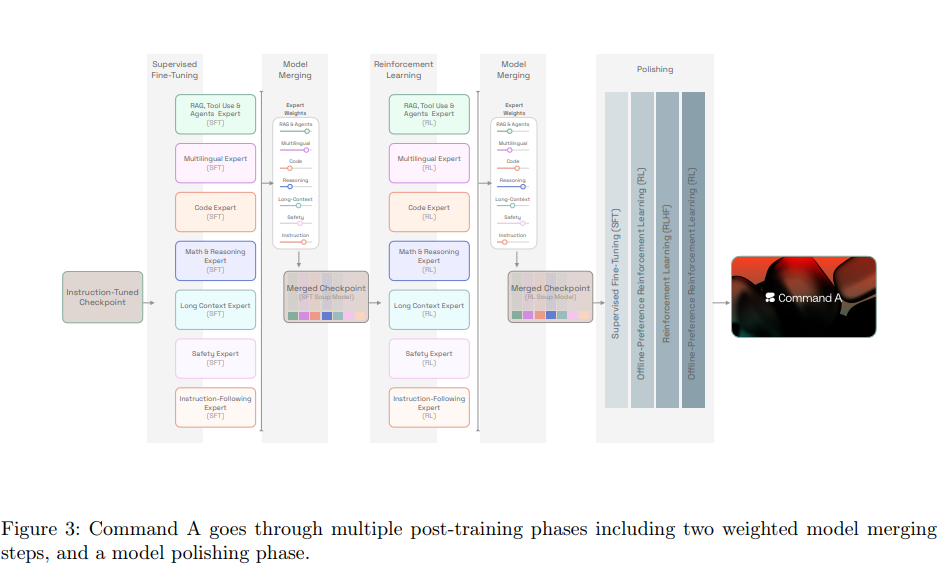
- 모델 머징 기법을 도입
- 여러 개의 서브 단계로 이루어짐
- 1) 사전학습 모델에 지도학습을 통해 Instruct 모델 학습
- 2) Instruct 모델에 특정 능력을 향상시킬 수 있는 데이터 조합으로 6개의 SFT 전문가 모델 학습
- 3) 파라미터 머징을 통해 6개의 전문가 모델을 하나의 Soup 모델로 머징
- 4) SFT Soup 모델에 강화학습 알고리즘을 활용해 각 도메인 맞춤으로 6개의 강화학습 전문가 모델 학습
- 5) 6개의 RL 전문가 모델을 하나의 RL Soup 모델로 머징
- 6) best-of-N, 오프라인 선호, 온라인 강화 알고리즘 등을 통해 사람과의 상호작용 능력을 강화 (Polishing)
- 6개의 전문가 모델은 각각 코드, 안전성, RAG, 수학, 다국어, 일반 Long-Context에 특화
학습 방법론
- 지도 파인튜닝 (Supervised Fine-tuning)
- 모델이 대화하는 방식을 따라 학습할 수 있게끔 파인튜닝
- 프롬프트와 응답(completion)으로 구성
- 프롬프트에는 시스템 프롬프트, tool 명세(specification), 대화 히스토리, special token, 질문 혹은 지시사항 등을 포함
- 응답은 프롬프트가 주어졌을 때 모델이 생성해야 할 토큰 시퀀스
- 특정한 경우 사전학습 데이터의 일부를 포함하거나, L2 페널티 등을 사용
- 강화학습 (Reinforcement Learning)
- 단계나 태스크에 따라 선호도 학습을 활용한 직접 조율(alignment) 혹은 강화학습을 통한 보상 신호 최적화 등을 수행
- 선호도 학습 (preference training)
- 선호 데이터셋을 활용해 오프라인으로 학습
- e.g. Sequence Likelihood Calibration, SLiC, DPO, IPO 등
- 강건성, 자기 개선(self-refinement)에 강점을 가진 새로운 SRPO 방법론 또한 도입
- 보상모델 최적화
- CoPG(Contrastive Policy Gradient) loss 활용
- 보상 모델 (Reward Model)
- Bradley-Terry 보상 모델 학습해 온라인 선호학습, 평가, 데이터 필터링 등에 활용
- 저품질 데이터로 먼저 학습하고 고품질 데이터로 추후 학습하는 2단계 학습
역량 (capability)
지시사항 준수 (Instruction Following)
- 일반적인 지시사항 준수, 포맷에 맞춰 생성, 테이블에 기반한 추론, 구조화된 데이터 활용 등 다양한 지시사항을 준수할 수 있도록 학습
- SFT, 오프라인 선호 학습 활용
데이터 수집
- 각 도메인에 대한 다양한 합성 프롬프트 생성
- 프롬프트마다 다른 temperature를 활용해 두 개의 응답을 생성
- 사람으로 하여금 각 답변에 대해 평가하도록 함
- SFT의 경우 이렇게 확보된 데이터에 사람이 재작성하는 방식으로 구성 (고품질 데이터 위함)
- 선호 데이터셋의 경우 사람이 평가한 점수를 기반으로 구성, 이를 Command A 학습과 보상 모델 학습에 모두 활용
보상 기반 샘플 정제
- 사람이 작성한 응답, 다양한 조건(e.g. temperature) 하의 여러 체크포인트에서 생성한 응답 등을 통해 학습한 내부 보상 모델을 활용
- 반복적인 방식으로 학습
- 즉, 1) 가장 최신의 체크포인트로 응답을 생성하고, 2) 응답을 보상모델로 평가하고, 3) 선호 데이터셋 및 SFT 데이터셋을 생성하고, 4) 모델들을 재학습하는 단계를 반복
시스템 프롬프트
- Cohere에서는 시스템 프롬프트를 preamble이라는 명칭으로 칭함
- preamble은 전체 대화, 모든 모델 인풋에 적용되는 지시사항을 의미
- e.g. 사용 언어, 모델 응답의 형식, 특정 단어 혹은 구문의 제외 등
- 다양한 종류의 preamble에 대해 강건성을 유지하기 위해 preamble을 증강한 데이터를 활용
모델 학습
- SFT, 선호학습을 수행
- SRPO 활용 시 가장 좋은 성능을 보임
RAG, Tool 사용, Agent
- LLM이 도구를 전략적으로 사용할 수 있어야 함
- e.g. API 호출, 결과 분석, 목표 달성을 위한 반복
- 환각 현상을 줄이고 정확한 정보를 보장하기 위해 외부 지식을 활용한 RAG 역량이 중요
- 다양한 행동을 관장하고, 자동화된 워크플로우를 보장하기 위한 Agentic 역량 또한 중요
- ReAct 프레임워크와 유사하게 추론(reasoning)과 행동을 엮어서 활용
데이터 및 학습
- 사람이 작성한 데이터 및 합성 데이터를 활용해 학습
- 사용자 프롬프트, 사용 가능한 도구, 추론 단계, 도구 호출 및 결과 등 포함한 형태로 데이터 구성
- 여러 명의 사람 평가자가 검수, LLM-as-a-judge를 활용한 품질 검수
- 코드 도구 실행, 사용자 업로드 문서, 일반적인 API 환경 등을 포함
- SFT 학습 진행 후 CoPG를 활용해 오프라인 선호 학습
다국어
- 23개 다국어 지원을 위해 다국어 데이터셋 포함
- 기계번역, 다국어 안전성, 다국어 추론, 다국어 강건성 조정, 다국어 RAG, 다국어 Agent 등
다국어 데이터 생성(annotation)
- 다국어 데이터는 전문적으로 훈련받은 다국어 annotator가 생성
- 도메인 특화 RAG, 긴 문맥 추론과 같이 복잡한 태스크의 경우, 1) LLM이 생성한 응답을 사람이 수정하거나 (대량 생성) 2) 사람이 직접 생성한 데이터를 활용 (고품질)
- 다국어 best-of-N을 활용해 반복적으로 합성 데이터 수집
- 모든 전문가 모델로부터 응답을 수집, 보상 모델로 점수 계산, 그 중 최고의 응답을 선택
학습
- SFT, 선호 학습을 통해 다국어 전문가 모델 학습
- SFT 시, 다른 seed와 동일한 configuration으로 학습한 여러 모델을 균등하게 머지할 경우 성능이 약하게 향상되었음 (선호학습은 X)
코드
데이터
- 8개의 프로그래밍 언어와 5개의 SQL 문법 지원
- 코드 생성, 코드 번역, 코드 최적화 등의 태스크 포함
- 합성 데이터와 annotation campaign 등을 통해 데이터 수집, 추가 정보를 활용해 데이터셋 풍성화
- 정답 단위 테스트를 통과하거나, 데이터베이스에서 오류 없이 수행하는 데이터를 우선순위로 둠
- 사전학습 데이터는 실행 기반의 코드를 활용, 강화학습 단게에서는 코드 정합성과 코드 결과에 대한 선호도 기반으로 최적화 수행
학습
- 다양한 코드 데이터(data mixture)를 활용해 지도학습 수행
- top k 시드에 대한 선형 머징을 수행하여 초반의 변동성을 완화
- 고품질 데이터만을 활용한 지도학습 수행
- 고품질 데이터란, 내부 보상모델로부터 높은 점수를 받았거나, 최고의 전문가 모델이 합성한 데이터 혹은 사람이 생성한 데이터를 의미
- 마찬가지로 무작위 시드들로부터 머징 수행
- 선호 데이터셋을 활용한 강화학습 수행 (오프라인 CoPG)
- 안정적인 강화학습을 위해 3가지 정규화 스키마 도입
수학 및 추론 (Reasoning)
- 사람보다 합성 데이터를 활용했을 때 성능이 더 좋았음
- 시드 프롬프트를 정성들여 만들고, LLM-as-judge를 활용해 문제와 정답이 맞는지를 확인
- 지도학습, 선호학습, 머징을 수행
- 지도학습 시 정답이 맞는 데이터셋을 엄격하게 사용하는 게 성능 향상에 반드시 필요하지는 않았음
- 선호학습 시에는 데이터의 정답 여부가 굉장히 중요. 사람이 평가한 선호도로 먼저 학습하고, 이후 정답/비정답 쌍으로 이루어진 합성 데이터를 활용해 학습
긴 문맥 (Long Context)
- 사전학습 시 사용한 긴 문맥의 데이터셋을 샘플링해 Command R+ Refresh 모델로 하여금 질문 정답 쌍을 만들도록 지시 (합성 데이터)
- 보상 모델로 하여금 여러 응답 중 최고의 응답을 선택하도록 함
- SFT 수행 후 쿨다운과 유사한 학습 방법을 진행 (16k: 256k = 3:1)
안전성
- 폭력성, 증오, 잘못된 정보, 자해, 아동학대, 성적 컨텐츠 등 관련 컨텐츠 필터링
- 시스템 프롬프트(preamble)을 활용해 통제 가능하며, contextual(맥락)과 strcit(엄격) 두 가지 모드를 가지고 있음
- 사전학습 시 도메인 기반, 분류기 기반 데이터 필터링을 진행
- 사후학습 시 사람이 직접 수행하거나 자동화된 방식으로 데이터 필터링 진행
- LLM 페르소나, LLM 기반 형식 재구성 등을 통해 사후학습 데이터의 다양성을 높이고자 함
- 모델이 안전성 때문에 모든 응답을 거부하지 않도록, 유용성(helpfulness)과 유해성(harmfulness) 사이의 균형을 고려함
- SFT, 오프라인 선호 학습 모두 수행하였으며, 모델 학습의 맨 마지막 단계인 polishing이 가장 큰 영향
- 선호 학습 수행 시 offline preference loss (IPO)와 SFT loss를 같은 가중치를 두고 활용
모델 머징
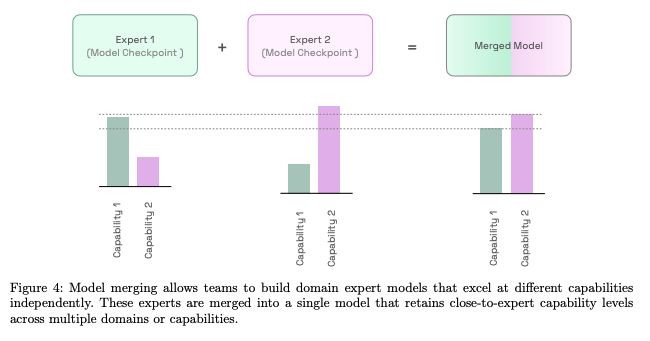
- 여러 개의 모델 파라미터들을 하나의 결합된 모델로 병합하는 과정
- Command A 모델은 각기 다른 역량(capability)를 가진 전문가 모델들을 하나의 모델로 결합하는 전문가 머징이 성능 향상에 주효했음 (Expert Merging)
- 선형 머징(=가중치 평균)이 단순하지만 효과적
- 공통된(일관된) 일반적인 지시사항 준수 모델을 초기 모델로 삼아 전문가 모델을 학습
- 모델 머징 자체는 학습 비용이 크게 들지 않으나, 이의 성능을 평가하는 데에 많은 비용이 소모됨
다듬기 (Polishing)
- 모델 머징 이후 최종 모델을 사람의 선호에 맞춰 조정(align)
- 1) 고품질의 데이터셋 일부를 활용해 SFT 진행
- 2) 오프라인 선호도 학습(preference tuning) 진행
- 3) 온라인 RLHF (Reinforcement Learning from Human Feedback) 진행
평가
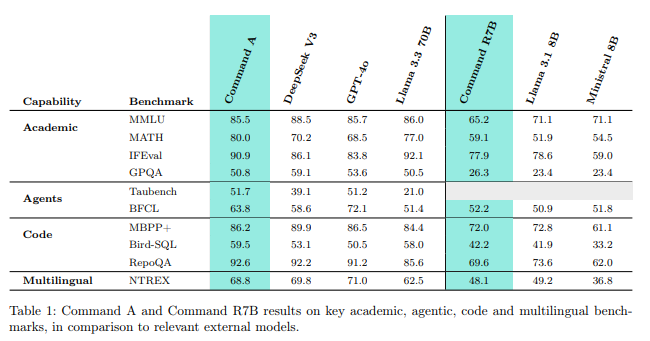
- 일반 언어성능, 에이전트 도구 사용, 다국어, 코드, 수학 및 추론, 안전성, 기업향 벤치마크, 긴 문맥 벤치마크 등에서 우수한 성능을 보임
- 모델들을 1:1로 두고 하는 pairwise 사람 평가에서도 우수한 성능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab