분야 및 배경지식
- 유머
- 유머는 크게 3가지 이론으로 분류될 수 있음
- hostility (적대감)
- 누군가 혹은 무언가에 대한 우위를 주장
- release of a constraint (제약의 완화)
- incongruity (부적합, 불일치)
- 일반적으로 공존할 수 없는 문맥들을 소개
- New Yorker caption contest의 만화들은 대개 이러한 상황을 가정
문제점
- AI 모델은 농담을 생성해낼 수 있으나, 유머를 실제로 이해하는 지는 미지수
해결책

- New Yorker caption contest와 관련된 3개의 태스크 제안
농담과 만화를 연결짓기 (match a joke to a cartoon)
- 주어진 만화의 최종(=우승한) 캡션을 선택하도록 함
- 다른 선택지들은 주어진 만화가 아닌 다른 만화의 최종 캡션들 (랜덤 선택)
우승한 캡션 식별하기 (identify a winning caption)
- 주어진 만화의 여러 캡션들 중 최종(=우승한) 캡션을 선택하도록 함
- 다른 선택지들은 동일한 만화의 다른 캡션들
우승한 캡션이 재밌는 이유를 설명하기 (explain why a winning caption is funny)
- 왜 해당 캡션이 재밌으며 적절한지 설명하도록 함
- 저자가 작성한 설명과 모델이 생성한 설명의 쌍이 사람(judge)에게 주어졌을 때, 저자가 작성한 설명에 선호를 보이지 않는다면 모델이 해당 태스크를 성공적으로 수행했다고 판단
평가
- from pixels
- 모델이 computer vision 태스크를 수행할 수 있어 만화 이미지를 직접 분석
- vision + language model
- CLIP, OFA Huge
- from description
- 모델이 computer vision 태스크를 수행할 수 없어 만화에 대한 설명이 주어짐
- language model
- T5-large, T5-11B, GPT-3, GPT-3.5, GPT-4
- 평가 기준
- 정확도: NYAcc (New Yorker의 공식적인 최종 캡션), CrowdAcc (대중에 의해 선택된 최종 캡션)
- 사람의 평가
- 자동 평가: BLEU-4, 단어 수준 Perplexity
- 데이터 (annotation)
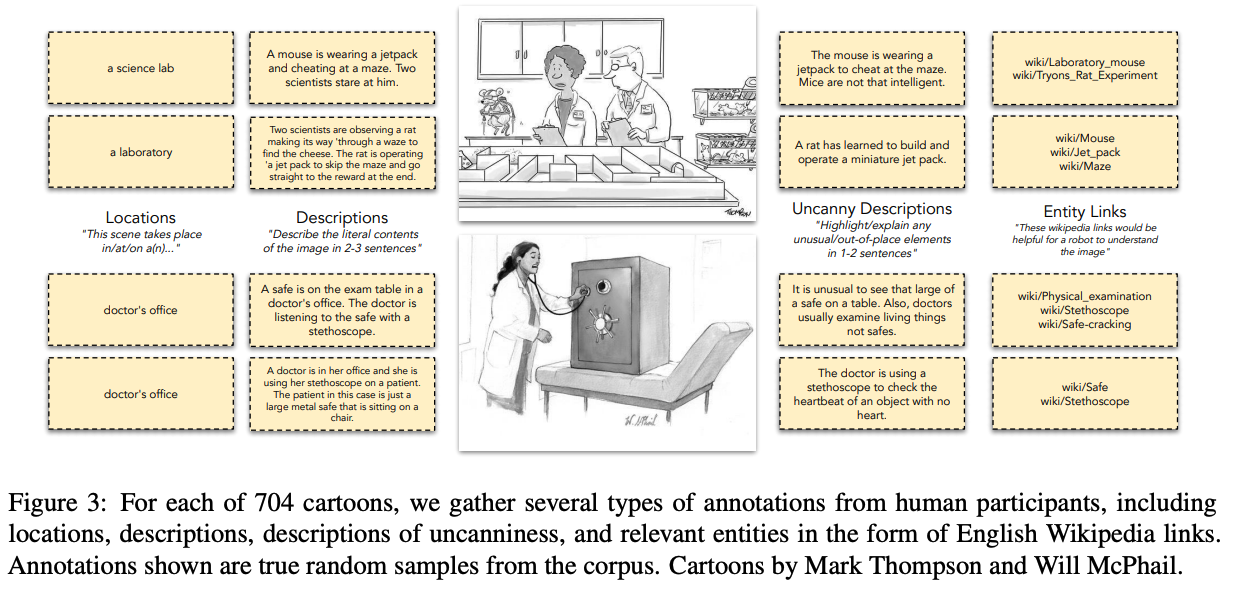
- from pixel의 경우 학습 단계에서 추가적인 정보로 사용됨
- from description의 경우 모델의 input으로 사용됨
- 결과
- GPT-4(5-shot)가 전반적으로 1, 2번 태스크에서 가장 좋은 성능을 보임
- image context가 주어질 때 caption만 주어진 것보다 더 좋은 성능
- vision + language model의 경우 vision 성능이 bottleneck이 될 수 있음
- 설명 생성 태스크에서 in-context와 fine-tuned 방식이 유사한 성능을 보임
- 사람이 작성한 설명이 모델이 작성한 설명에 비해 훨씬 선호됨
한계
- 모델이 가진 유머의 이해도를 New Yorker caption contest라는 특정한 분야로 한정
- 모든 종류의 유머를 포괄하는 연구는 아님
- 설명(explanations in annotated corpus)의 경우 단일 저자에 의해 작성됨 (다양성 문제)
의의
- 모델이 유머를 이해하는가라는 이전에 다루어지지 않은 새로운 주제를 분석

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
정보 감사합니다.