YOLO 특징
- 객체 인식을 regression problem으로 접근
- 단일 네트워크 사용으로 FULL image 에서 bbox, class probabilities 예측
- 빠른 예측 속도 ( 단일 네트워크 때문 )
- 배경에서 오탐지할 가능성이 적음 ( bbox 학습시 각 cell 마다 박스 1개 사용, cell 당 클래스 1개 할당 )
- 일반화 가능한 객체 표현을 학습
- pascal VOC 데이터셋으로 학습하고 다른 데이터셋을 예측해도 성능이 높음.
- 지역 제안 기반 모델보다 정확도가 낮음
- 작은 개체 식별 어려움
- v1 ~ v6 까지 지속적으로 노력
입력 이미지와 산출 벡터 구조
객체의 중심이 있는 cell은 객체 인식의 기준으로 정합니다. ( Pr(obj) = 0 or 1 )
객체의 중심이 있는 cell은 target 을 가지고 있습니다.
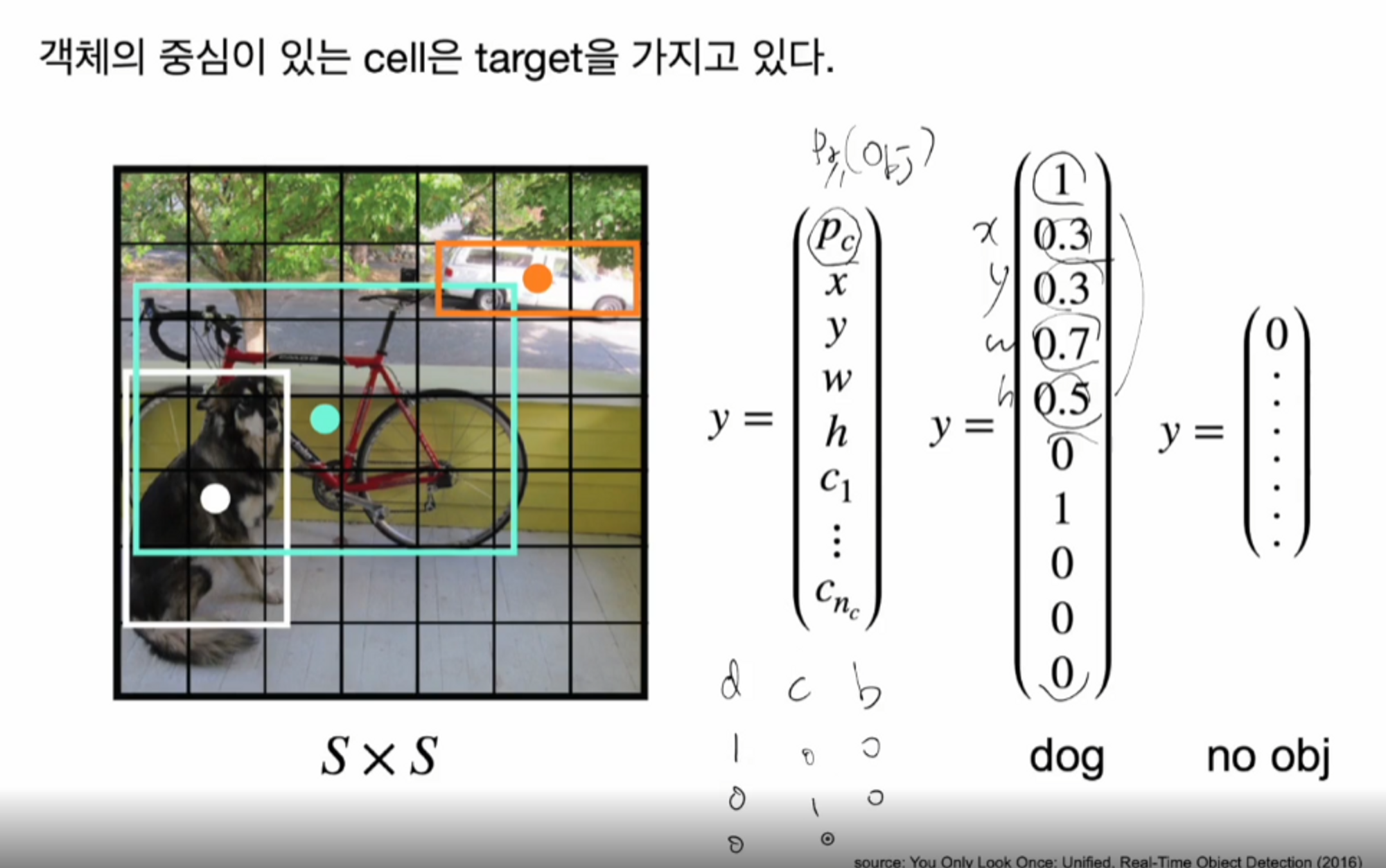
dog 클래스의 벡터를 보면 가장 위에 있는 숫자가 1 인데요,
1은 개의 중심이 있는 셀, 즉 객체가 있는 셀은 1로 표현을 합니다.
그리고 개에 해당하는 타겟 바운딩 박스의 중심이 0.3 0.3 = x , y이고 너비가 0.7 높이가 0.5를 의미합니다.
그 아래에 0 1 0 0 0 은 dog 클래스를 원-핫 벡터로 나타낸 것입니다.
그러면 예측 벡터는 어떻게 될까요?
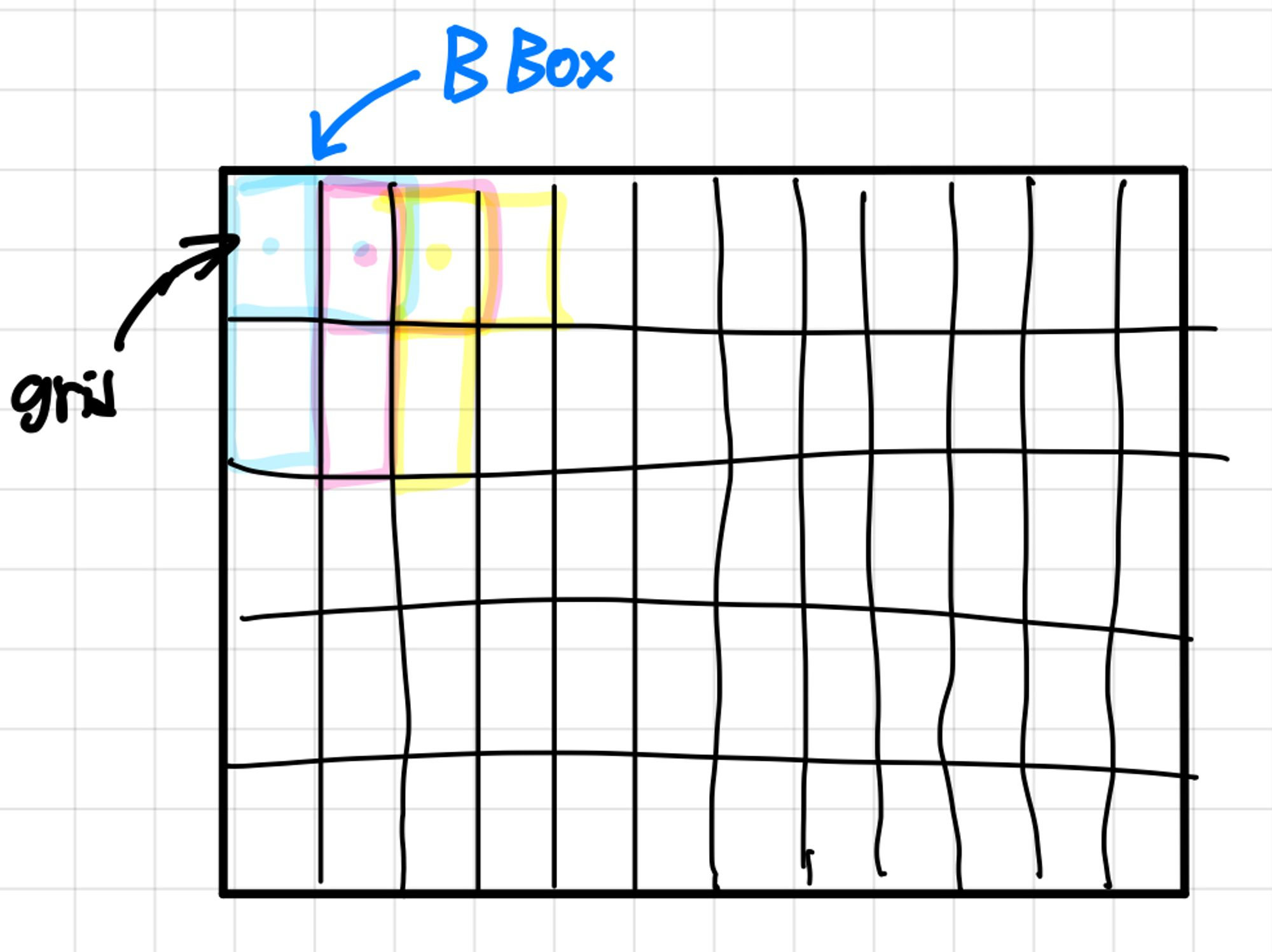
이미지는 grid로 나눠지는데, yolo v1은 각 grid마다 bbox 를 B개 만들어줍니다. 각 grid당 여러 개의 bbox를 사용합니다.
그래서 만약에 B개의 bbox가 있다면 , 각 셀당 박스의 개수가 B개가 있어야하고, 그 박스는 박스의 정보를 가지고 있어야 하기 때문에 중심(x,y)과 너비(w)와 높이(h), 컨피던스 스코어(Pc) 를 가지고 있어야 되겠죠.
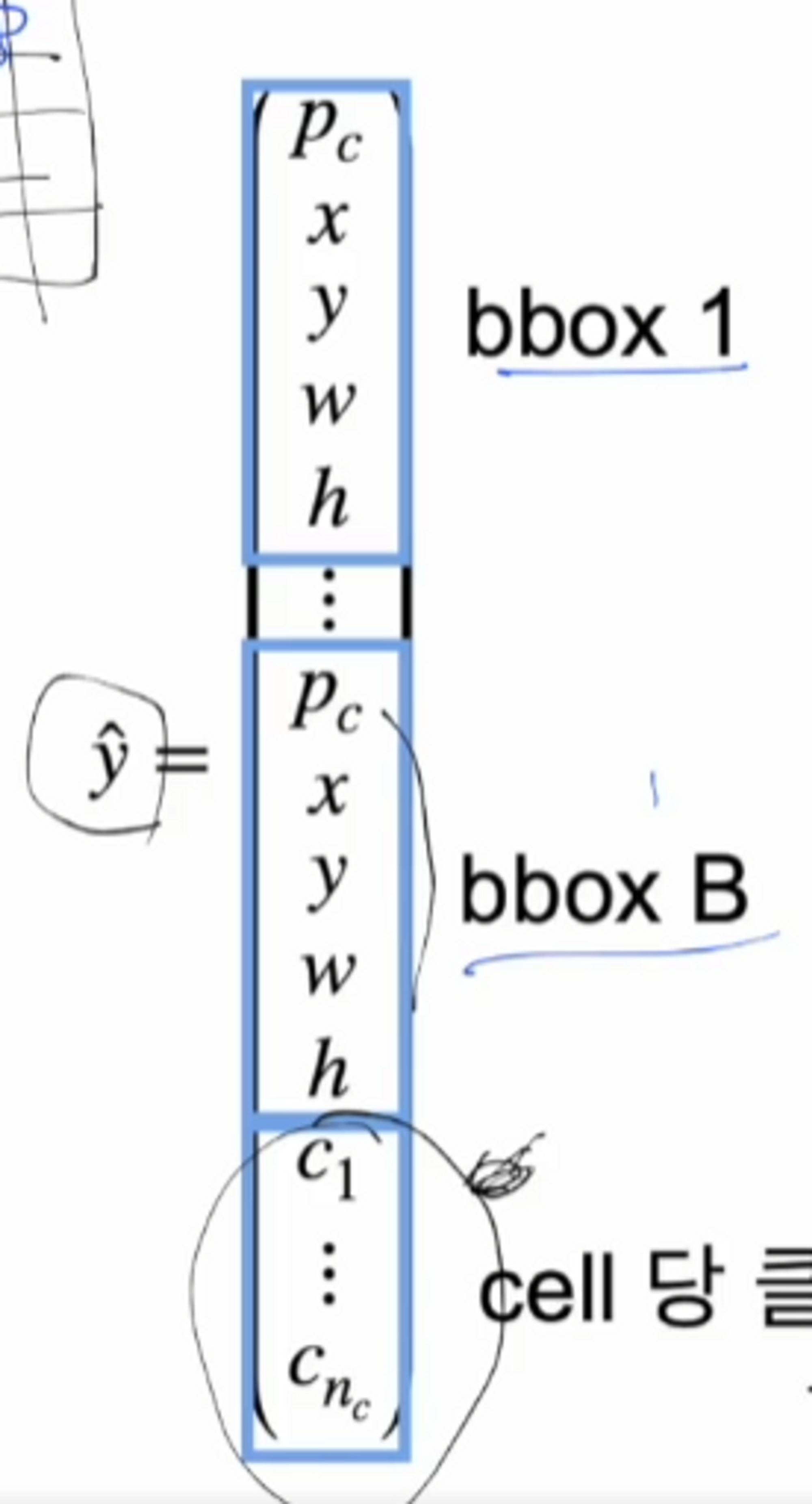
box에 해당하는 부분은 5개의 성분으로 이루어져 있습니다. box가 여러개가 있어도 각 셀 당 하나의 클래스만 예측을 하게 되므로 결국은 각 셀에 배당되는 y햇의 값은 클래스를 하나만 가지고 있습니다. v1에서는 각 cell당 클래스 하나만 다루게 됩니다.
- 각 cell 당 B개의 bbox를 생성
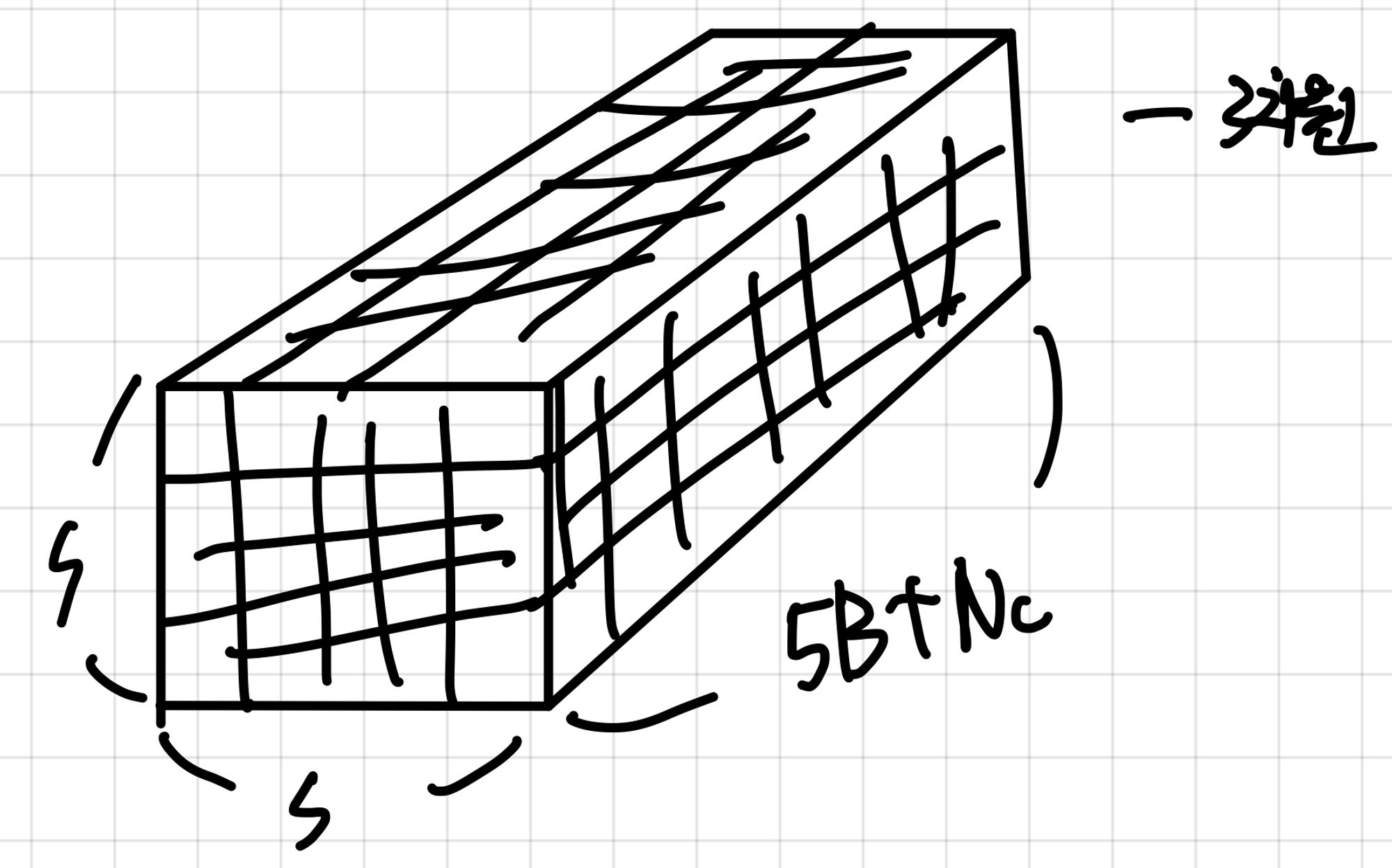
- 즉, y햇의 크기는 5xB+n ⇒ 5 ( 성분이 5개 이므로 ) x B(박스의 개수) + Nc ( 클래스의 개수 )
- 따라서 이미지 한 장에서 나오는 예측 텐서의 크기는 S x S x ( 5 x B + Nc )
- 예측은 정확히 bbox에 맞춰져 있지 않을 수 있어서 IoU로 정의합니다.
target 벡터에서는 우리가 답을 알고 있기 때문에 ( 객체가 있다 or 없다 ) 객체의 중심이 있으면 1 없으면 0을 할당. ( Pr(obj) = 0, 1 )
- 논문에서는 S = 7 , B = 2, pascal VOC C = 20 으로 맞춰줌
- pascal VOC C = 20은 pascal VOC 데이터 ( 클래스 20개 )
모델 + GoogLeNet , MultiStep scheduler, LeakyReLU
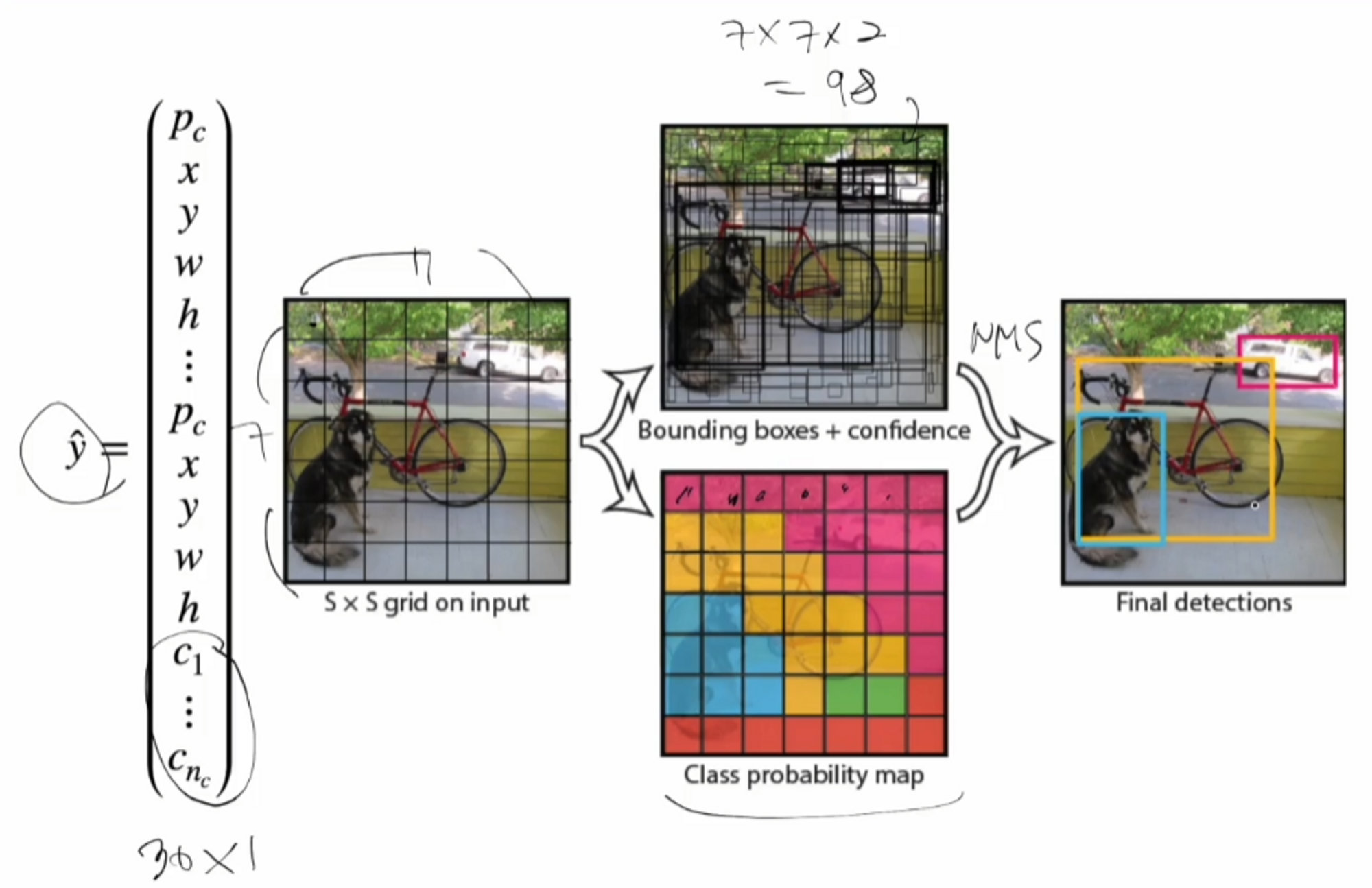
y햇(예측)은 다음과 같은 벡터를 갖게 됩니다. 30 x 1 크기였습니다.
각 cell 마다 bbox를 2개 씩 갖게 되므로 7 x 7 x 2 = 98 개의 bbox가 생성됩니다.
각 cell 마다 클래스 1개를 포함하므로 Class probability map을 만들 수 있습니다.
마지막으로 confidence score와 bbox간의 IoU 값을 통해서 best bbox를 산출할 수 있겠네요 !
→ NMS 알고리즘을 통해서 최종적으로 best box를 산출하게 됩니다.
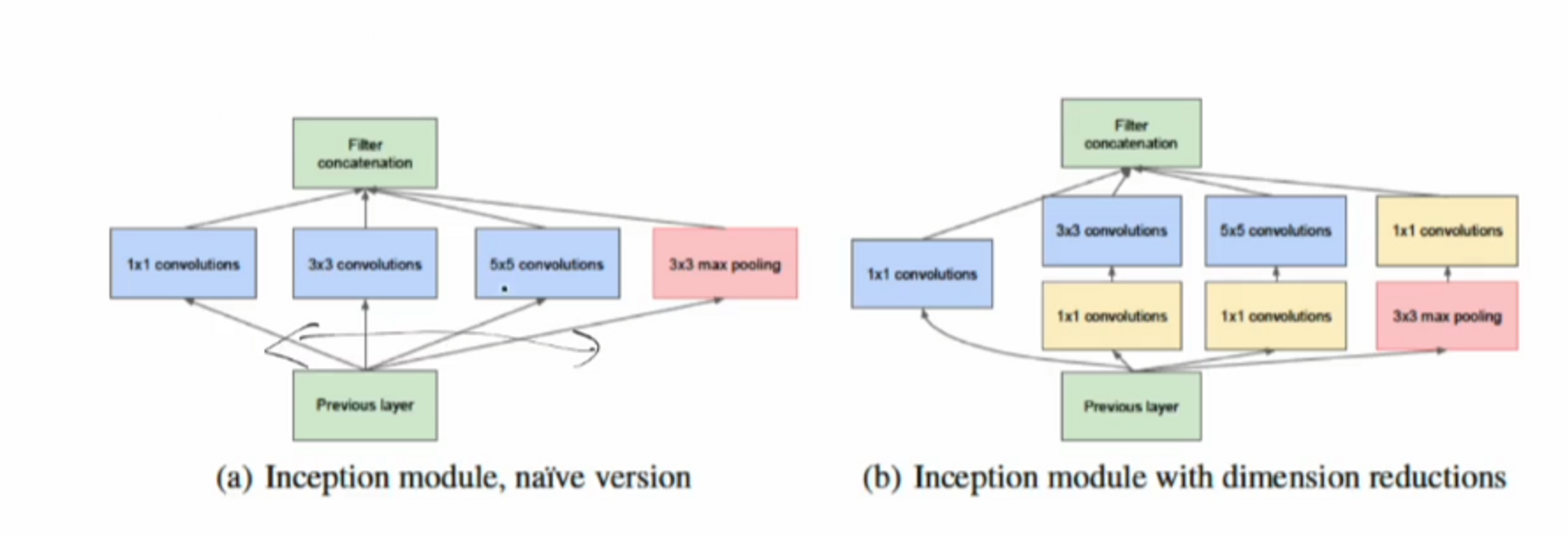
GoogleLeNet ( Inception 1 ) - ILSVRC 2014 우승
yolo v1 에서는 googleLeNet 모델을 사용했습니다.
이 모델의 특징은 한 블록당 y번의 연산을 하는 것이 특징입니다.
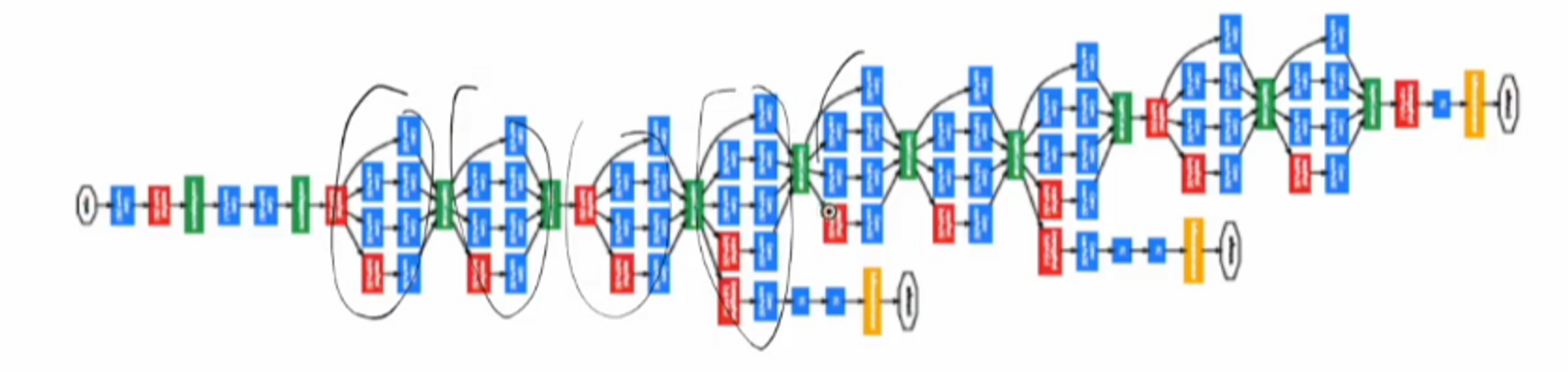
저 블록들을 딥하게 연결하면 네트워크가 구성됩니다.
conv layers : 24 , fc : 2 ( Fast YOLO는 conv layers : 9 )
하지만 논문에서 사용한 구조는 GoogleNet 과 엄청난 유사성을 보이진 않습니다. ( 개인적으로 )
일단 인셉션 블록을 사용하지 않았고
구조를 자세히 보시면 3 x 3 conv 사이에 1 x 1 conv을 넣었습니다.
이는 메모리를 효율적으로 사용하려는 의도인데요, 1x1 conv의 장점은 뭘까요?
Feature map 사이즈를 줄이지 않고 채널 수를 자유자재로 바꿀 수 있다는 것이 장점입니다.
3 x 3 윈도우를 쓰면서 512개의 채널을 운영하면서 중간에 256짜리로 줄여서 다시 한 번 계산을 해서 연산을 한 번 더 늘리되 채널 수를 줄여서 운영하겠다는 것이죠.
실제로 많이 사용하는 방법 중 하나입니다. ( 1x1 , 3x3 , 1x1, 3x3 … )
이런 방법을 ( reduction layer ) 라고 합니다.
Feature map 사이즈를 유지하면서 채널 수를 확 줄여줄 수 있는 방법입니다.
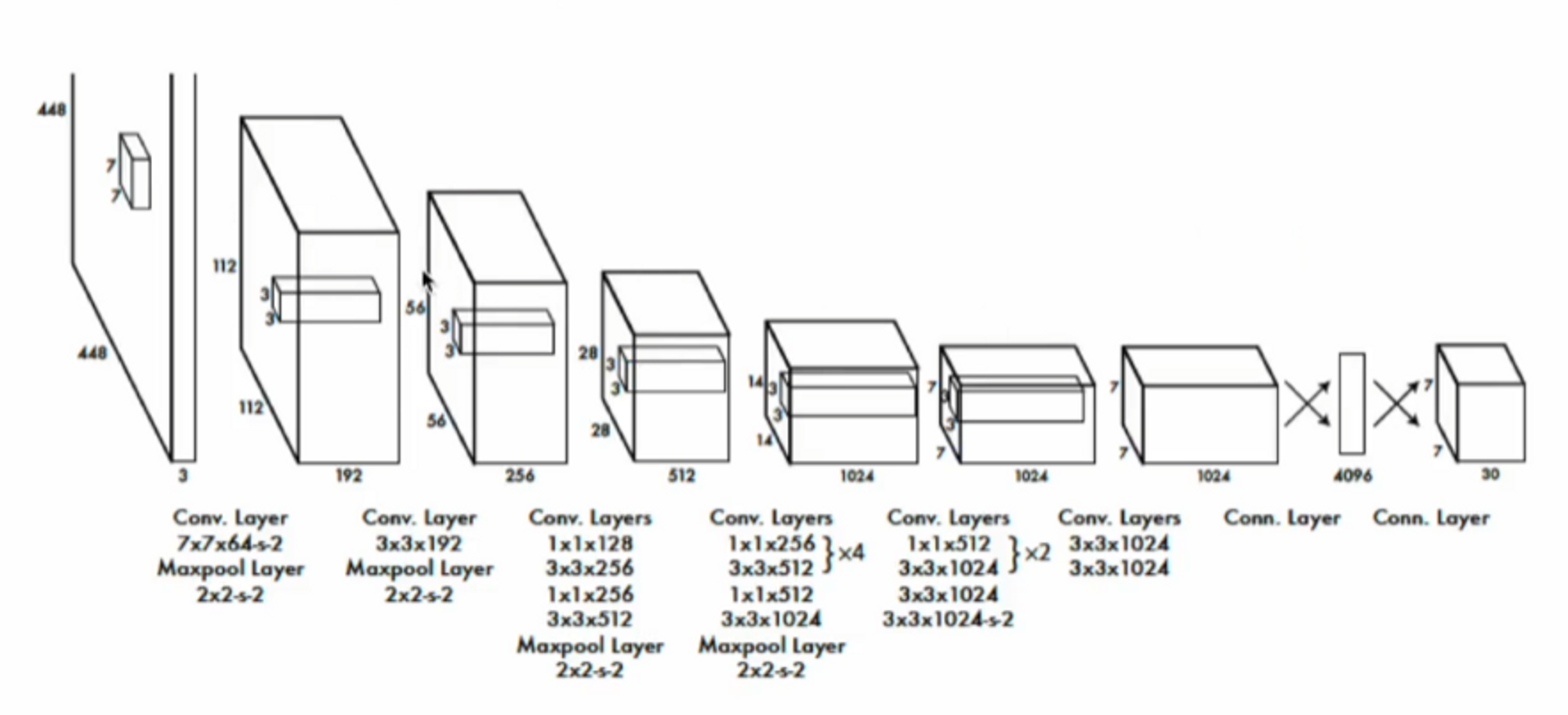
여기서는 conv layer를 24개를 사용했고 , fc는 2개를 사용했습니다.
마지막에 나오는 결과는 7 x 7 x 30 입니다.
S x S x ( 5B + Nc ) 를 산출해주네요.
Fast YOLO 에서는 conv layers를 9개만 사용하는데, 이는 속도가 빨라지고 mAP는 낮아집니다.
모델 학습
- 1000개의 클래스를 가진 224x224 ImageNet 데이터로 conv layers를 사전 학습 ( pretrained )
- 사전 학습에는 20개의 conv와 avg. pooling 1층, fc 1층이 사용
- 추가 학습 ( fine tuning )
- 4개의 conv와 2개의 fc 추가 모델 사용
- 448 x 448 데이터 사용
- 마지막 층을 제외한 모든 층에 Leaky ReLU 적용
- Batch size : 64
- momentum optimizer ( momentum factor = 0.9 ) 사용
- MultiStep 스케줄링 사용
- 이 때는 지금 많이 사용하는 Adam이 나오기 전. momentum + Scheduling은 아직도 많이 사용하는 기법
- 스케줄링 → 에폭마다 lr을 조정한다는 의미. ( 일반적으로 epoch이 커지면 lr은 작게 가져가는 편 ) ***이 부분은 따로 정리
- FC1에 dropout ( drop rate = 0.5 ) 적용
- 마지막 레이어에는 당연하지만 정규화 사용하면 안됌. ( 온전한 값이 나와야 함 )
- Data Augmentation 적용 : 이미지 스케일링(flip ,crop ), 컬러 변환 ( 흑백, 명암, 색조 등 )
활성화 함수는 leaky ReLU 사용.
0.1 부분은 사용자가 바꿔줄 수 있음.

손실 함수
논문에서 가장 중요한 부분인 손실 함수 부분을 다뤄보겠습니다.
전체 손실 함수는 → sum-squared error로 정의를 했습니다.
각 cell 마다 loss를 다 더했고, 일부 기능들을 강화 혹은 약화 시키기 위해서 가중 함수를 사용했습니다. 식을 보면 a(알파) 와 b(베타)가 있죠? 이렇게 패널티 값들을 넣어줍니다.
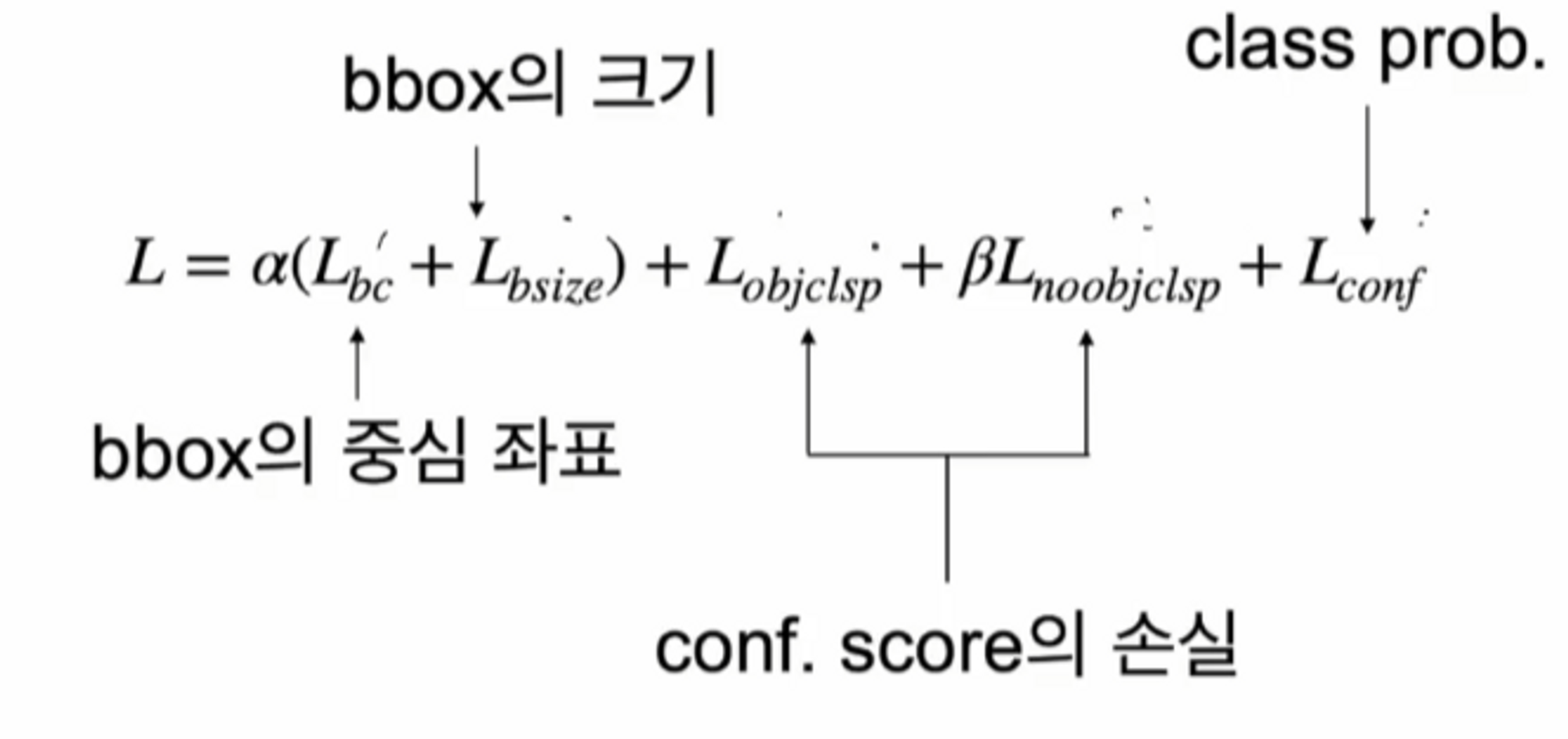
3가지의 loss 로 나눠집니다.
- bbox의 loss → bbox의 중심에 대한 loss ( Lbc ) : 중심에 얼마나 가까운지를 구해서 그 거리를 줄이기 위함. 그리고 bbox의 너비와 높이를 이용한 loss.
-
conf score의 loss → 일반적인 사진에는 객체보다 배경에 해당하는 grid가 더 많습니다. 객체가 아닌 부분이 더 많기 때문에 객체가 아닌 grid를 기준으로 conf score를 계산하면, 0이 됩니다. 최적화 할 때마다 모든 conf score가 0에 가까워지는 경향이 있습니다.
그래서 Object의 유무에 따라 cell을 나눠서 계산 해줍니다. B(베타) 패널티가 붙어있는 함수가 Object가 없는 loss이죠. Object가 없는 cell은 모델 최적화에 덜 영향을 주기 위해서 작은 값의 B(베타)를 주게 됩니다. 이 논문에서는 0.5를 사용했습니다. 그리고 bbox의 예측 성능 강화를 위해 a(알파) 값으로 5를 주게 됩니다.
- class의 loss → cross entropy를 사용하지 않고 squared error를 사용.
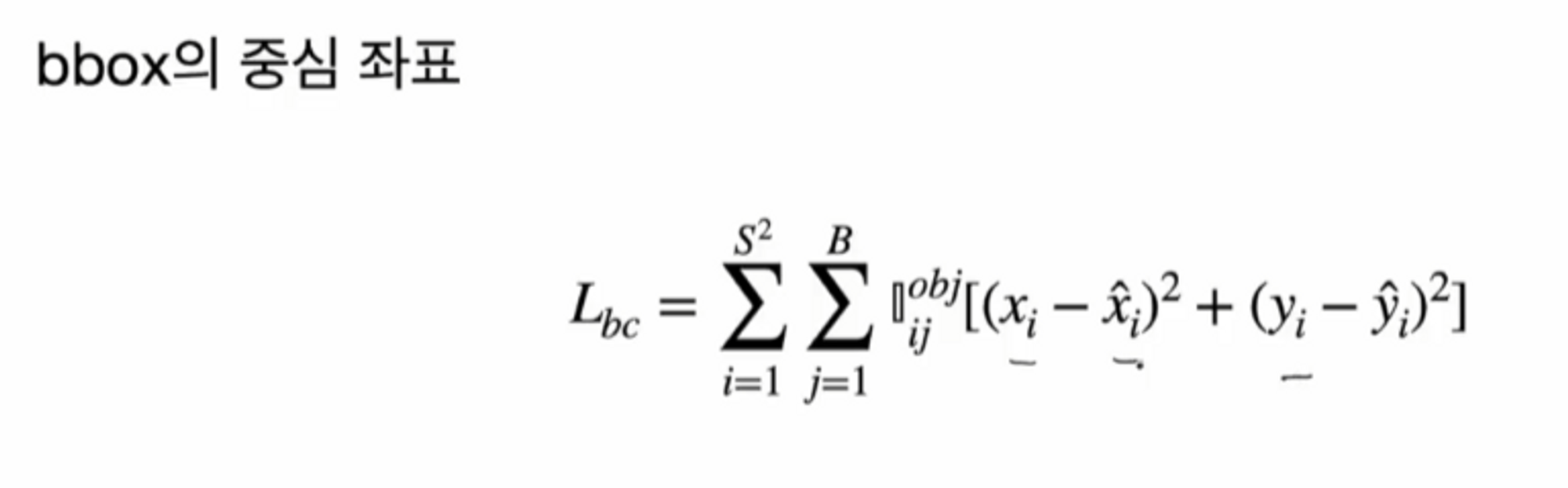
bbox의 중심 좌표에 대한 loss는 당연히 타겟 박스의 중심과 예측 박스의 중심의 차의 제곱의 합으로 이루어져 있습니다.
i , j 가 무엇을 의미하는지 체크해볼게요.
i는 cell의 개수만큼 서메이션하고 있죠? S의 제곱만큼 가니까요. 따라서 i는 cell에 대한 서메이션으로 알 수 있고
j는 bbox에 대한 서메이션으로 볼 수 있겠네요.
서메이션 식 다음에 나오는 obj , ij 는 무엇을 의미할까요?
‘i 번째 cell에서 responsible한 j번째 box만 사용하도록 하는 함수’를 의미합니다.
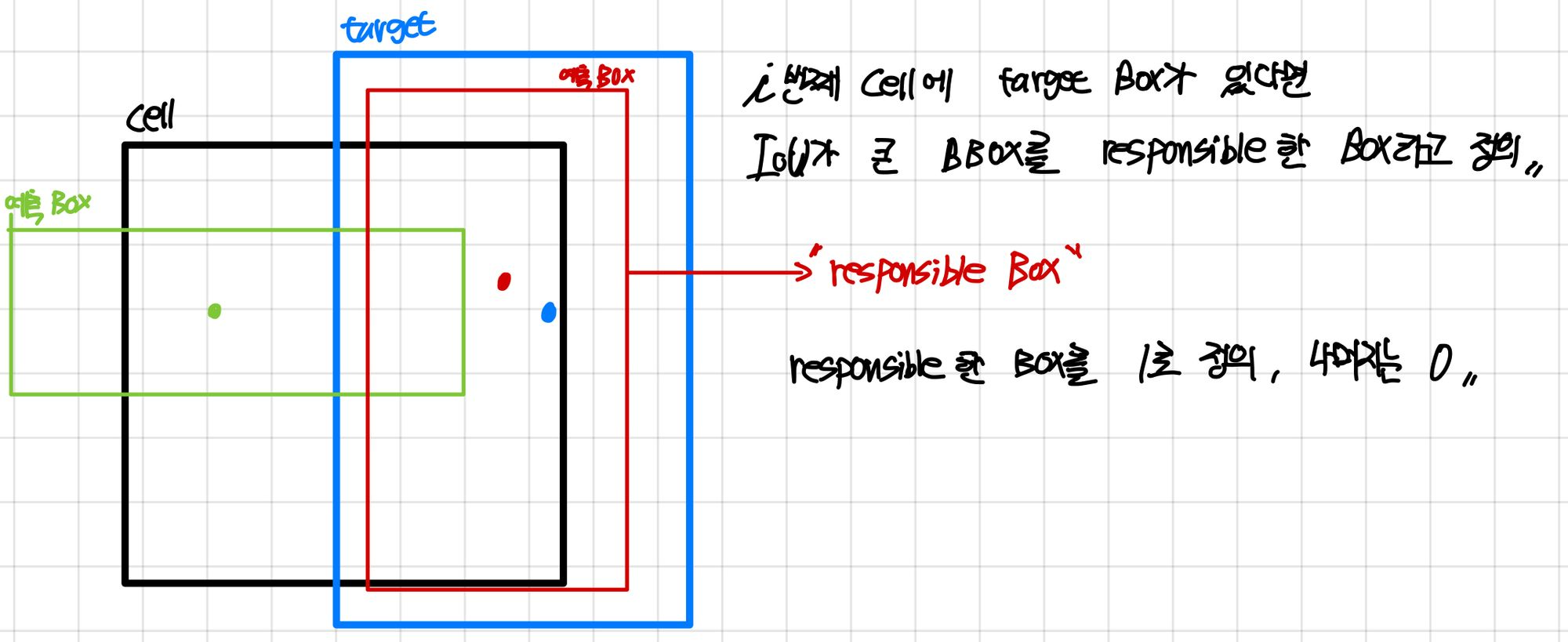
i번 째 cell에 target box가 있다면 IoU가 큰 bbox를 responsible한 box라고 정의합니다.
아래 그림에서는 빨간색 box가 responsible한 box로 되겠죠 ?
responsible한 box를 1의 값으로 두고 나머지는 0으로 처리합니다.
그래서 yolo v1의 특징은 뭐냐면 bbox의 중심을 계산할 때는 최적의 box 하나로 loss를 계산한다는 것입니다.

따라서 각 cell당 최적의 box만 고려합니다.
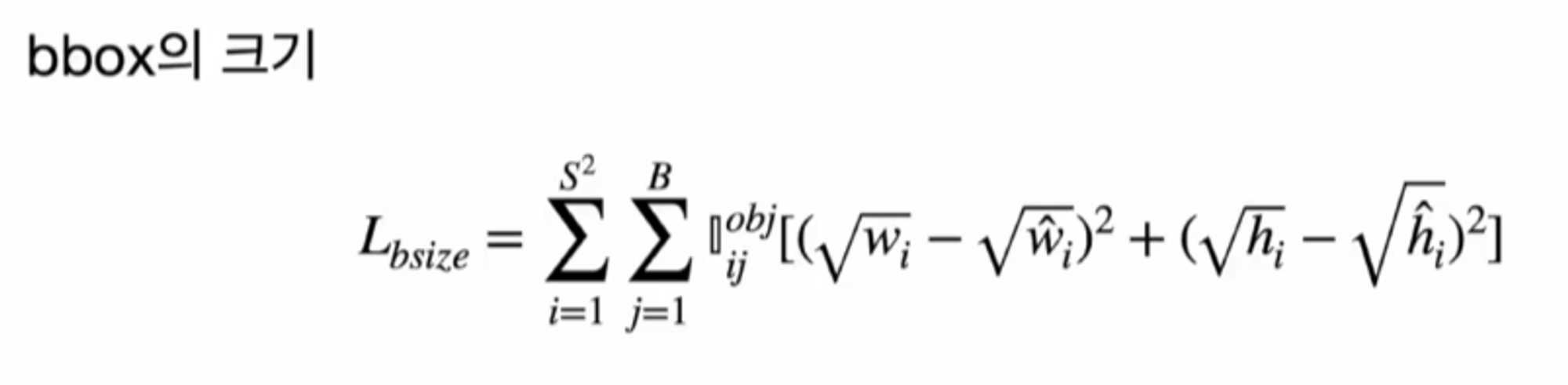
bbox의 크기도 마찬가지로 최적의 box를 기준으로 적용이 되고 ( 즉, IoU가 큰 box만 고려 )
여기서는 w에 루트를 씌웠어요. 왜 그럴까요 ?
만약 bbox의 크기가 100 50 인 box1 과 99 49인 box2가 있다고 가정해보면
( 100 - 99 ) 2 + ( 50 - 49 ) 2 = 2 라는 결과가 나옵니다.
그리고 bbox의 크기가 4 5 인 box1 과 3 4인 box2가 있다고 가정해보면
( 4 - 3 ) 2 + ( 5 - 4 ) 2 = 2 라는 결과가 나옵니다.
큰 박스와 작은 박스의 구분이 없이 그냥 거리의 차이로 계산을 해보면 2가 되는데
여기서 문제가 뭐냐면 앞의 예시처럼 큰 box는 1만큼 빗겨나가도 상관이 없습니다.
많은 부분들이 겹치기 때문이죠. 하지만 작은 box는 큰 box와 동일한 격차가 벌어지더라도 예측에 대해서는 큰 영향으로 다가올 수 있습니다.
객체가 작기 때문에 조금만 차이가 나도 객체가 잘 안잡힐 수도 있습니다.
이런 부분을 방지하기 위해서 큰 값이 작은 값보다 덜 중요하게 하기 위해서 루트를 씌워줍니다.
루트를 씌워주면 값이 더 작게 나오겠죠?
큰 값일수록 square를 씌워주니까 감소폭이 더 큽니다. 앞의 예시에 루트를 씌워서 계산하면
0.0076이 나옵니다.
하지만 두 번째 예시는 루트를 씌워 계산하면 0.12가 나옵니다.
따라서 그냥 squared를 하면 박스의 크기에 상관없이 차이에 대해서만 계산하겠다는 것이지만
루트를 씌우면 크기를 어느 정도 반영을 해줄 수 있습니다.
그리고 덜 민감한 큰 박스에 대해서는 영향력을 덜 주겠다는 것입니다.

Ci는 0아니면 1입니다. 타겟 벡터에 객체가 있다면 1 없으면 0이구요.
앞서 말씀드린 것처럼 Object가 있는 것과 없는 것을 분리해서 loss를 계산했습니다.
Ci의 햇은 예측된 confidence score

i번째 grid cell에 j번 째 bbox가 객체에 responsible 하지 못하면 1입니다.
responsible 하다면 0의 값을 가집니다.
그래서 앞의 Object가 있는 loss랑 반대로 생각하면 됩니다.

마지막으로 Object가 있는 경우에 class의 probability를 구하는 것입니다.
cross entropy를 사용하지 않았다는 점이 중요하겠네요.
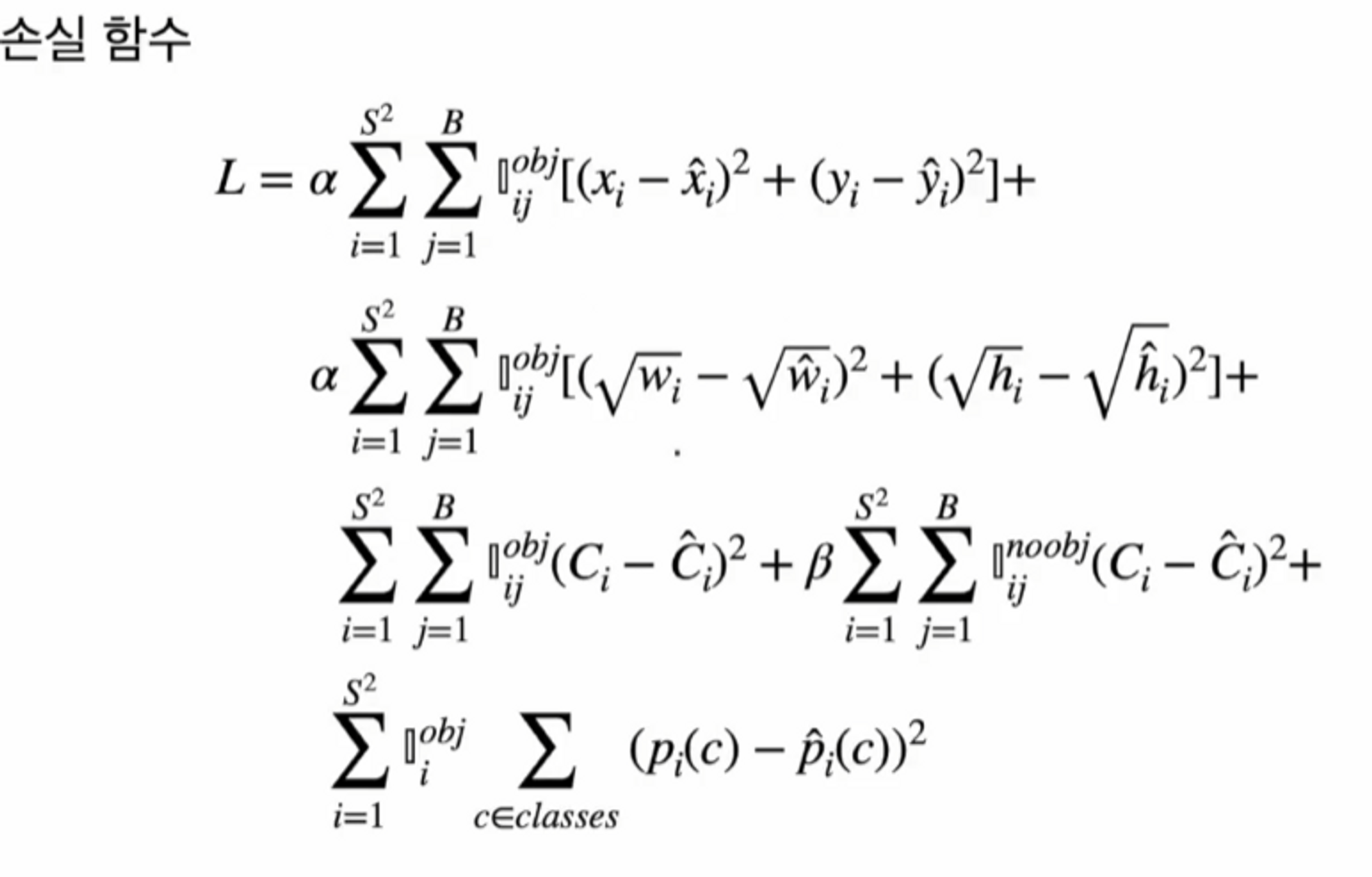
전체적인 손실함수를 보면 이렇게 쓸 수 있겠네요 !
다음 포스팅에서는 yolo v1을 from scratch로 코드를 짜보겠습니당
