브라우저를 열고 주소창에 url을 입력한 후 엔터 키를 누르면 "짜잔!" 눈 깜짝할 새에 웹 페이지가 나타나게 된다. 그러나 그 짧은 순간 보이지 않는 곳에서는 웹 페이지를 보여주기 위해 여러 가지 일들이 일어난다.
웹이 동작하는 과정, 그 원리에 대해 간단히 알아보자.
1. 웹 클라이언트와 웹 서버
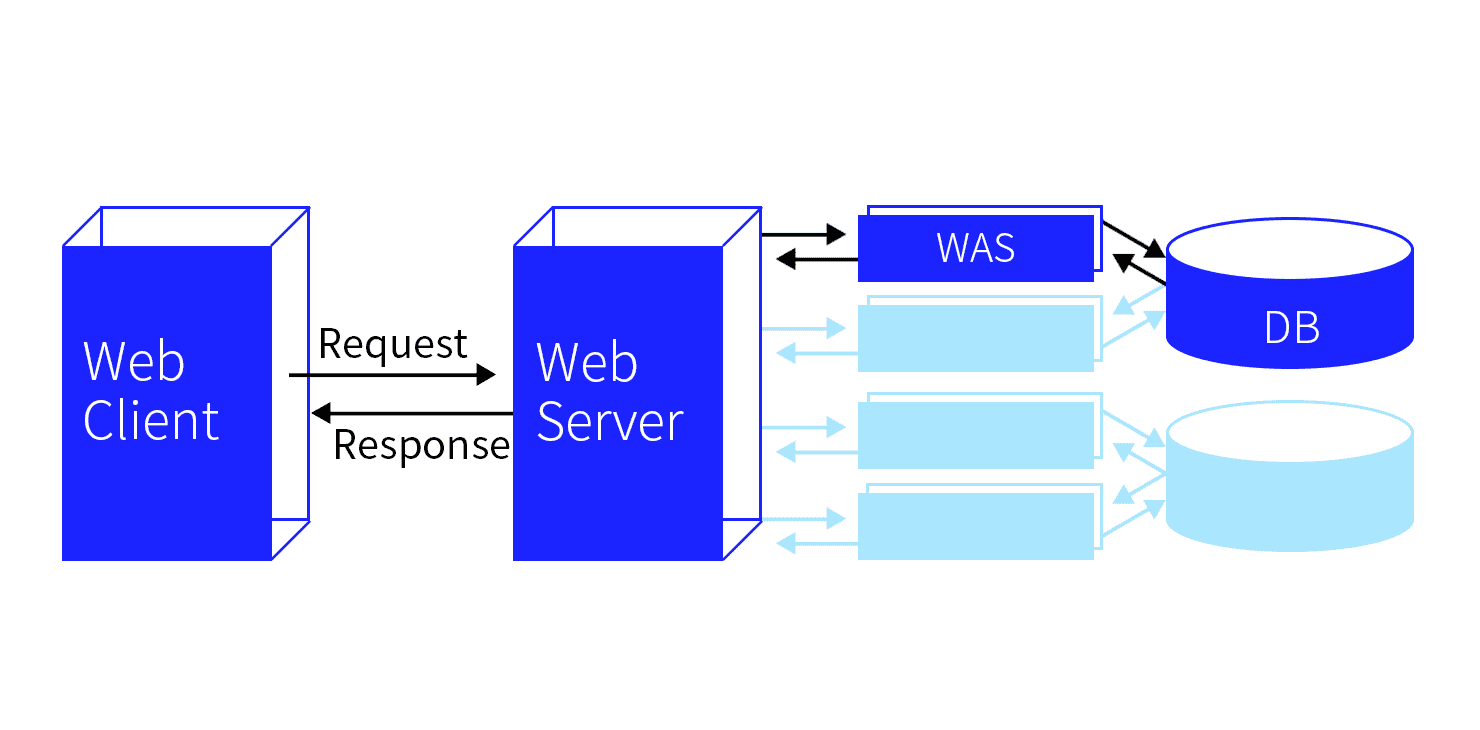
웹 클라이언트(Web client)
웹 클라이언트는 사용자가 웹에 접근하는 프로그램을 말한다. 여기에는 여러 종류가 있지만, 대부분의 사용자는 일반적으로 웹 브라우저를 통해 웹에 접근하며, Internet explorer, Chrome, Firefox, Safari 등의 웹 브라우저가 웹 클라이언트에 해당한다.
브라우저의 주소창에 적절한 url을 입력하고 엔터 키를 누르면 웹 브라우저(웹 클라이언트)는 사용자로부터 받은 url에 대한 정보를 찾아 HTTP 메시지의 형태로 서버에 요청(Request)을 보내게 된다.
웹 서버(Web server)
웹 서버는 웹 페이지, 웹 사이트 혹은 앱을 저장하는 프로그램을 말한다. 서버는 클라이언트로부터 전달받은 HTTP 메시지(Request)를 확인한 후 이에 적합한 형태로 데이터를 처리한 후에 다시 클라이언트에 응답(Response)을 보낸다. 예를 들어 웹 브라우저에서 url(https://velog.io/@mino0121)을 입력하고 엔터 키를 누르면 브라우저는 서버에 "https://velog.io/@mino0121 라는 url에 해당하는 응답(일반적으로 이 경우는 메인 페이지의 html 파일 등)을 보내 달라"고 요청하는 것이고, 서버는 해당 HTTP 요청을 확인하여 그에 적합한 반응(메인 페이지의 html 파일 등)을 보내는 것이다.
웹 서버의 대표적인 예로는 아파치 웹 서버(Apache Web Server), GWS, IIS 등이 있다.
2. WAS(Web Application Server)
WAS의 개요
웹 서버가 단독으로 모든 계산을 수행하고 데이터를 처리 및 관리한다면 단순명쾌하겠으나, 웹 서버 혼자서 모든 일을 처리하게 되면 웹 서버가 과부하될 가능성이 매우 높다. 게다가 웹 서버는 정적인 데이터(html, css 등)의 처리만 가능하므로 동적인 요청은 처리할 수가 없다. WAS는 웹 서버의 일을 도와 동적인 요청을 받아 처리해주는, 일종의 보조 역할을 하는 미들웨어를 말한다.
클라이언트로부터 요청을 받으면 웹 서버는 이 요청에 응답하기 위해 필요한 페이지의 로직이나 데이터베이스와의 연동 등을 확인하여 WAS에 이러한 작업의 처리를 요청한다. 그러면 WAS는 이 요청을 받아 동적인 페이지 처리를 하거나 DB로부터 데이터를 가져오거나 하는 식으로 요청을 처리한 뒤, 생성한 데이터를 다시 웹 서버에 반환한다. 그러면 서버는 이렇게 전달받은 데이터를 적절히 처리하여 정적 데이터로 만든 뒤 클라이언트에 응답을 보내는 것이다.
WAS의 구성
WAS는 보통 웹 서버와 웹 컨테이너로 구성된다. 그리고 여기서 웹 컨테이너는 JSP와 Servlet을 실행시킬 수 있는 소프트웨어를 말한다.
그런데 WAS가 '웹 서버+웹 컨테이너'라면 WAS도 정적 데이터를 처리할 수는 있지 않을까? 답은 '가능하다'이다. 그러나 일반적으로는 웹 서버와 WAS를 분리해서 사용한다.
웹 서버와 WAS를 분리하는 이유
WAS는 DB의 조회 및 다양한 로직을 처리하는 데에 집중해야 한다. 따라서 단순한 정적 데이터의 처리는 웹 서버에 맡기고, 기능을 분리시킴으로써 서버의 부하를 방지하는 것이 적절하다.
만약 WAS가 정적 데이터까지 처리하게 되면 부하가 커지고, 동적 데이터의 처리가 지연되면서 수행 속도가 느려진다.
또한 웹 서버와 WAS를 물리적으로 분리함으로써 웹이 보안을 강화할 수도 있고, 하나의 웹 서버에 여러 대의 WAS를 연결하여 장애 발생 시 장애 극복이 용이하게 만들 수도 있다.
즉, 자원 이용의 효율성이나 장애 극복 용이성, 배포 및 유지 보수상 편의성 등을 위해 웹 서버와 WAS를 분리하여 사용하는 것이다.
3. DB(DataBase)
DB는 말 그대로 데이터를 저장해 두는 공간이다. 웹 서버로부터 요청받은 WAS가 DB에 데이터를 요청하면 DB는 적절한 데이터를 찾아 응답한다.
4. 웹 사이트가 브라우저에 출력되는 과정
이제 위에서 확인한 정보를 바탕으로 웹 사이트가 실제 브라우저에 출력되는 과정을 살펴보자.
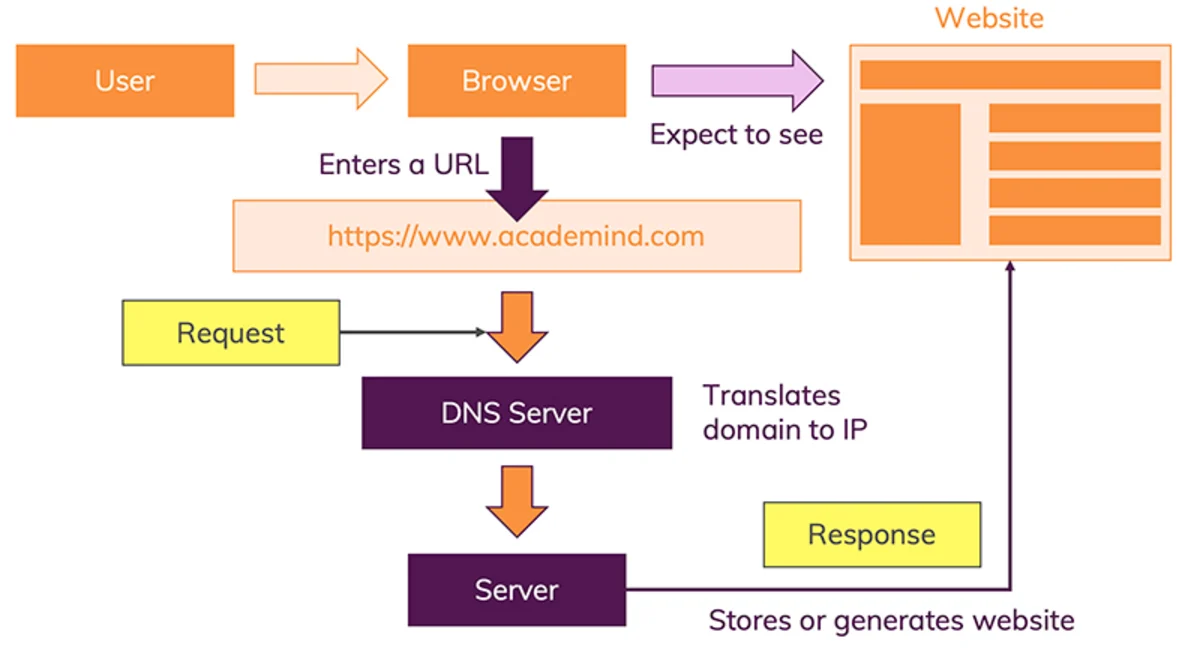
요청(Request)
- 사용자가 브라우저에 입력한 url은 DNS(Domain Name System) 서버에 의해 IP 주소로 변환된다.
DNS는 인터넷 도메인 이름과 실제 숫자로 구성된 인터넷 프로토콜을 서로 연결함으로써 좀 더 편리하게 인터넷에 접속할 수 있도록 하는 시스템을 말한다. 일종의 주소록과 같은 개념으로 이해할 수 있을 것이다.
- 변환된 IP 주소는 HTTP를 통해 웹 서버로 전송된다. 여기에는 요청 방식과 송신자/수신자에 대한 데이터 등이 포함되며, TCP 프로토콜을 이용해 서버로 전송된다.
응답(Response)
- 웹 서버는 HTTP 메시지를 받고 요청된 url에 대한 데이터를 찾는다.
- 요청에 대해 적절한 응답을 보내기 위해 웹 서버는 필요한 경우 WAS에 데이터의 처리를 요청하고, WAS는 웹 서버로부터 받은 요청을 처리하여 다시 웹 서버에 반환한다.
- 서버는 응답 상태 코드, 데이터의 유형, 페이지를 화면에 렌더링하기 위해 필요한 코드 등을 포함한 응답 메시지를 TCP 프로토콜을 통해 브라우저로 전송한다.
- 응답 메시지를 전송받은 브라우저는 파싱 및 렌더링 과정을 거쳐 최종적으로 웹 사이트를 화면에 표시한다.
- 파싱은 HTML, CSS, Javascript 등의 문서를 읽고, 이를 조작할 수 있는 자료 구조로 변환하는 과정을 말한다. 즉, 일련의 문자열을 의미를 가진 토큰 단위로 분해하고, 이들로 이루어진 자료 구조인 파스 트리(parse tree)를 만드는 것이다.
- 렌더링은 파싱을 통해 만들어진 자료 구조(텐더 트리)를 기반으로 하여 브라우저의 화면에 그 내용을 시각적으로 출력하는 것을 말한다.
파싱과 렌더링에 대한 내용은 프론트엔드 영역에 해당하므로 대략적인 개념만 파악하고 넘어가자.참고 자료
