DB Lock
Database(DB)에는 많은 데이터가 저장되어 있고, 그러한 데이터에 대해 동시에 접근하는 경우가 발생할 수밖에 없다. 그런데 그럴 경우 앞서 트랜잭션 포스트에서 살펴보았던 여러 가지 문제가 발생하면서 데이터의 일관성 및 무결성이 훼손될 수도 있다.
이러한 상황에서, 대부분의 DBMS는 데이터의 일관성과 무결성을 보장하기 위한 방법으로 Lock을 사용한다.
Lock이란 트랜잭션 처리의 순차성을 보장하기 위한 방법이다. 그런데 DBMS마다 Lock을 구현하는 방식이나 세부적인 방법 등에는 다소 차이가 있다. 따라서 DBMS를 효과적으로 이용하기 위해서는 사용하는 DBMS의 Lock에 대해 이해해야 한다.
DBMS의 Lock은 크게 Shared lock과 Exclusive lock의 두 가지로 구분할 수 있다.
Shared lock
Shared lock, 또는 Read lock은 말 그대로 데이터를 읽을 때 사용되는 lock으로 앞 글자를 따 주로 S로 표기된다. 데이터를 변경하지 않기 때문에 Shared lock이 걸려 있는 경우 동시에 데이터에 접근이 가능하며, 여러 Shared lock을 동시에 적용하는 것도 가능하다.
다만 Shared lock이 걸려 있는 데이터에는 Exclusive lock을 적용할 수 없다. 이는 Exclusive lock이 무엇인지를 이해하면 당연한 이야기로 이해할 수 있는데, 간단히 말해 Exclusive lock은 데이터를 변경할 때 사용하는 lock이기 때문이다.
Exclusive lock
Exclusive lock, 또는 Write lock은 데이터를 변경할 때 사용하는 lock으로서 주로 X로 표기한다. 이름에서 알 수 있듯 다른 세션이 해당 데이터에 접근하는 것 자체를 막는 락으로, 트랜잭션이 commit되어 lock이 해제될 때까지 다른 트랜잭션의 접근을 막는다.
Update lock
아래에서 설명할 데드락(Dead lock)을 방지하기 위하여 사용되는 lock으로 UPDATE 쿼리의 필터(WHERE)가 실행되는 과정에서 적용된다.
Intent lock
Intent lock은 상기 세 가지 lock과는 조금 다른 기능을 하는데, 사용자가 요청한 범위에 대하여 lock을 걸 수 있는지 여부를 빠르게 파악하기 위해 사용되는 lock이다. 각 lock 앞에 I를 붙여 IS, IX, SIX 등으로 구분된다.
예를 들어 사용자 A가 테이블의 row 하나에 대하여 Exclusive lock을 건경우, 다른 사용자 B가 테이블 전체에 대하여 lock을 걸기 위해서는 사용자 A의 트랜잭션이 끝날 때까지 기다려야 한다. 그런데 이때 사용자 B가 테이블에 lock을 걸 수 있는지 여부를 파악하기 위해 테이블 내에 존재하는 모든 row와 관련된 lock을 찾아보는 것은 매우 비효율적이다.
따라서 DB는 사용자 A가 row에 lock(X)을 거는 시점에 해당 row의 상위 객체(페이지, 테이블 등)에 대하여 lock(IX)을 걸어 다른 사용자가 더 큰 범위의 데이터에 lock을 걸 수 있는지 여부를 빠르게 파악할 수 있도록 돕는다.
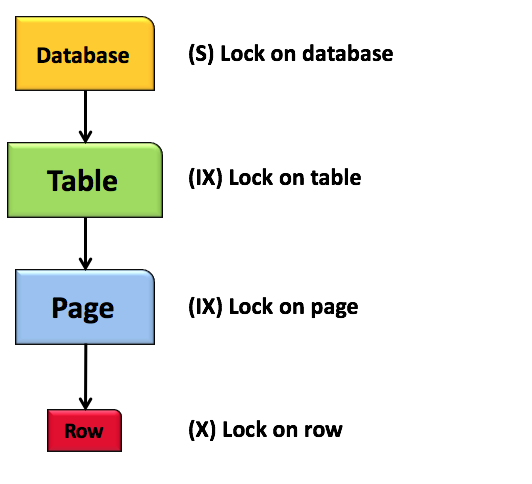
Lock의 설정 범위(Level)
Database
전체 DB를 기준으로 Lock을 설정하는 것이다. 즉 1개의 세션(트랜잭션)만이 DB에 접근 가능하다. 따라서 일반적으로는 거의 사용되지 않으며, DB의 버전 업데이트 등 제한된 경우에만 사용된다.
File
데이터베이스 파일을 기준으로 Lock을 설정하는 것으로, 이때 파일은 테이블, 로우(Row) 등과 같은 실제 데이터가 작성되는 물리적인 저장소를 말한다. 이 경우는 거의 사용되지 않는다.
Table
테이블을 기준으로 Lock을 설정한다. 이는 테이블의 모든 행을 업데이트하는 등 전체 테이블에 영향을 주는 변경, 즉 DDL(CREATE, ALTER, DROP 등) 구문을 수행할 때 유용하게 사용되며, 따라서 DDL lock이라고도 불린다.
Page & Block
File의 일부인 Page 혹은 Block을 기준으로 Lock을 설정하는 방법이며, 이 역시 잘 사용되지는 않는다.
Page : SQL Server에서 8KB 단위로 데이터를 저장하는 단위
Block : Oracle에서 2KB, 4KB, 8KB 등 다양한 크기의 단위로 데이터를 저장하는 단위
Column
Column을 기준으로 Lock을 설정한다. 다만 이 방법은 Lock의 설정 및 해제 시 리소스가 많이 필요하며, 따라서 일반적으로는 잘 사용되지 않는다(지원하는 DBMS도 많지 않다).
Row
1개 행(Row)을 기준으로 Lock을 설정하는 방법으로 가장 일반적으로 사용되는 lock이다.
Blocking
Blocking은 Lock 간의 경합이 발생하여 특정 트랜잭션의 작업이 진행되지 못하고 멈춘 상태를 말한다. 공유 락(Shared lock)끼리는 블로킹이 발생하지 않지만 배타 락(Exclusive lock)은 블로킹을 발생시키며, 따라서 베타 락-베타 락 혹은 베타 락-공유 락 간의 관계에서 블로킹이 발생할 수 있다.

블로킹이 해소되기 위해서는 이전의 트랜잭션이 완료되어야 하며, 이후에 들어온 트랜잭션은 앞선 트랜잭션이 마무리된 이후에야 진행이 가능하다. 이는 당연히 성능에 악영향을 미치므로 Lock 간의 경합이 최소화되도록 할 필요가 있다. 이는 다음과 같은 방법을 통해 가능하다.
- 한 트랜잭션의 길이를 가능한 짧게 정의한다.
- 같은 데이터를 갱신하는 트랜잭션이 동시에 수행되지 않도록 하며, 트랜잭션이 활발한 시기에는 대용량의 갱신 작업을 수행하지 않도록 한다..
- 트랜잭션 격리 수준을 불필요하게 상향 조정하지 않는다.
- 쿼리를 오랜 시간 잡아 두지 않도록 적절히 튜닝한다.
Deadlock
Deadlock은 두 트랜잭션이 각각 lock을 설정한 뒤 서로의 lock에 접근하여 데이터를 얻어오려고 할 때, 이미 각 트랜잭션에 의해 lock이 설정되어 양쪽 트랜잭션 모두가 영원히 처리되지 않게 되는 상태를 말한다. 조금 복잡한데, 다음의 예를 통해 이해해 보자.
만약 트랜잭션 A가 game_master 테이블의 2번 row를 수정하였고 이어 game_detail 테이블의 2번 row를 수정하려고 한다. 동시에 트랜잭션 B는 game_detail 테이블의 2번 row를 수정하였고 이어 game_master 테이블의 2번 row를 수정하려고 한다.
이 경우 트랜잭션 A는 game_master 테이블의 2번 row에 대하여 exclusive lock을 설정하였고, 트랜잭션 B는 game_detail 테이블의 2번 row에 대하여 exclusive lock을 설정한 상태이다. 그리고 서로 교차하여 트랜잭션 A는 game_detail 테이블의 2번 row에, 트랜잭션 B는 game_master의 2번 row에 각각 lock을 설정하려고 한다.

말로 풀어서 설명하려니 복잡하지만, 간단히 정리하면 서로 동시에 다른 트랜잭션이 lock을 설정한 row에 대하여 lock을 설정하려고 시도하는 것이다. 이미 각 row들은 서로 다른 트랜잭션에 의해 lock(X) 설정이 되어 있으며, 따라서 두 트랜잭션은 모두 이 lock이 해제될 때까지 기다리게 된다. 그런데 두 트랜잭션 모두 완료되지 않았으므로 lock은 해제되지 않으며, 따라서 영원히 대기하는 상태가 이어지게 된다. 이를 Deadlock이라 한다.
DBMS는 Deadlock이 발생할 경우 둘 중 한 트랜잭션에 에러를 발생시킴으로써 문제를 해결한다. 그러나 가능하면 Deadlock을 발생시키지 않도록 트랜잭션의 접근 순서를 정리하는 것이 좋을 것이다. 위의 예에서라면 game_master의 업데이트가 모두 완료된 후 game_detail을 업데이트하는 득의 규칙을 정함으로써 테이블 간 교차하여 접근하는 것을 방지할 수 있을 것이다.
참고 자료
