안녕하세요. 밍기뉴와제제입니다. 오랜만에 논문리뷰를 합니다. 아마 이번에 하고 약 2~3주간 못하다 종강 이후에 다시 하지 않을까 싶습니다. 후...요즘 연구실 일이 줄어드니까 과제가 많아지네요. 쉽지 않습니다.
이번에 리뷰할 논문은 Densely Connected Convolutional Networks입니다. 그 유명한 DenseNet을 제시한 논문이죠. 간단히 말씀드자면, DenseNet은 각 레이어들끼리 모두 연결하는 기법(Dense connection)을 도입한 딥러닝 네트워크입니다. DenseNet은 경쟁상대로 지목한 ResNet보다 더좋은 성능을 보여줬습니다.
그렇기 때문에 DenseNet에 흥미가 생겼고 이번에 리뷰를 해보기로 했습니다. 그러면 지금부터 Densely Connected Convolutional Networks, DenseNet의 리뷰를 시작하도록 하겠습니다.
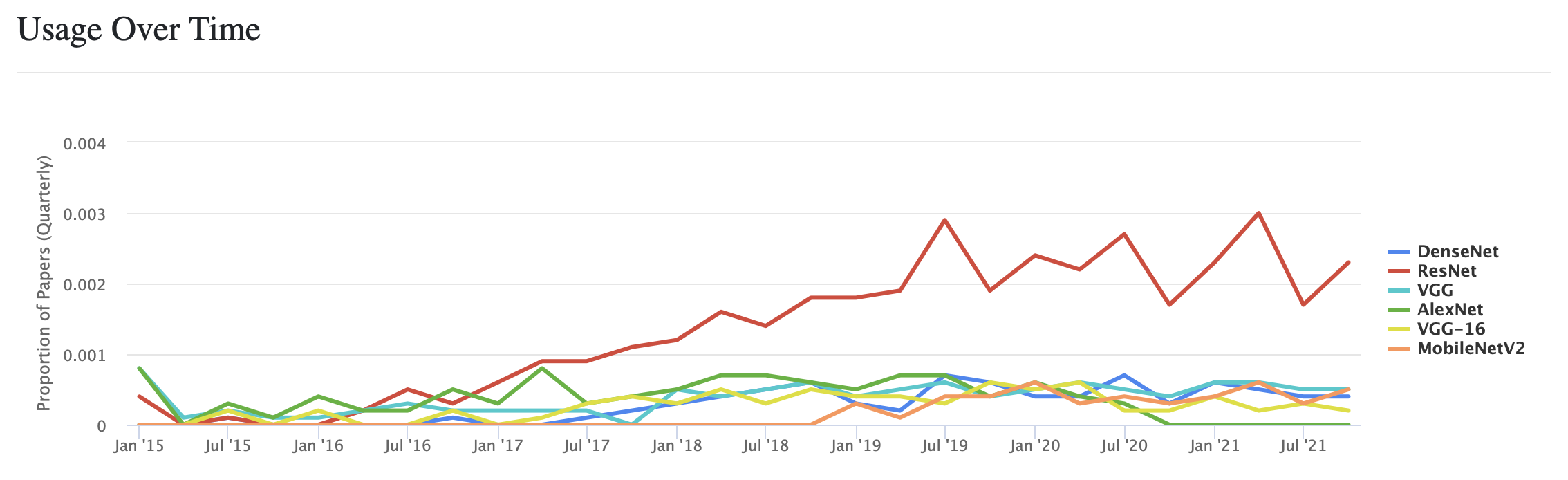
그리고 검색을 하며 흥미로운 점을 발견했습니다. 바로 ResNet이 더많이 쓰이고 있다는 겁니다. 출처
해당 자료가 있는 paperswithcode는 머신러닝, 딥러닝을 주제로 하는 논문들이 다 등록되어있는 사이트라고 볼 수 있기에 이 자료의 신뢰도는 상당히 높습니다. 시간이 흐를수록 ResNet의 비율이 더 높아진다는 것이 신기합니다. 그나저나 저기에 포함된 네트워크들은 다 비율이 낮네요 ㅜ.ㅜ 트랜스포머 이 나쁜자식...
1. Introduction
우선 Convolutional neural networks, CNN의 발전 역사에 대해 간략하게 언급됩니다. '태초에 ~가 있었다...'같은 내용 말이죠. 시간이 흐르며 하드웨어 등이 발전함에 따라 더 많은 레이어를 쌓은 네트워크가 등장했습니다. 1998년, 5개의 레이어를 쌓은 LeNet5이 등장했고 2014년, 19개의 레이어를 쌓은 VGG16가 등장했죠. 그리고 2016년, 무려 151층의 레이어를 쌓은 ResNet이 등장하며 100층의 벽을 돌파했습니다.
ResNet을 아시면 DenseNet을 이해하기 쉬울겁니다. ResNet의 설계 방식을 기반으로 만들어진게 DenseNet이기 때문이죠.
CNN의 레이어 층수가 많아지면서, 연구자들에게는 하나의 고민이 생겼습니다. 바로 역전파되던 그레이던트가 레이어를 지나며 점점 줄어들다 끝내 소실되는 Vanishing gradient입니다. 역전파를 거치며 각 레이어에 전달되어야할 그레디언트가 소실되어 레이어들을 학습시킬 수 없다는 점으로 인해 쌓을 수 있는 레이어의 개수가 제한적이었죠.
그래서 이를 해결하기 위해 ResNet(identity mapping), Stochastic depth(randomly dropping layers during training), FractalNets(repeatedly combine several parallel layer sequences with different number of convolutional blocks) 등이 등장했습니다.
앞서 말씀드린 네트워크들은 각자 다른 방식으로 gradient를 살렸습니다. 허나 이들의 방식들은 한가지 공통점이 있었죠. 바로 "레이어들을 연결하는 short path를 생성해 early layer와 later layer를 연결했다"는 겁니다. 여기서 Short path가 뭘까요? ResNet을 구성하는 Residual Block을 통해 알아봅시다.
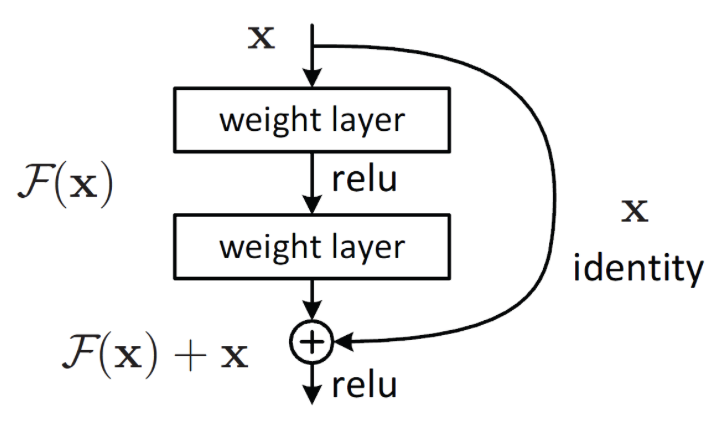
ResNet은 Residual Block들이 여러개 쌓여있습니다. 우리는 여기서 early layer에서 나온 X라는 데이터가 다음 레이어, later layer로 가는길이 2개가 있음을 알 수 있습니다.
- weight layer -> relu -> weight layer
- identity
첫 번째 길은 레이어를 두 번이나 거쳐야합니다. 허나 두 번째 길은 바로 다음 레이어로 건너갈 수 있습니다. 이게 바로 Short path입니다. 역전파를 할 때 우리는 미분을 수행합니다. 이 때 Short path, 즉 값을 그대로 더하는 덧셈 연산이기 때문에 그레디언트가 소실되지 않고 그대로 다음 레이어에 전파됩니다. 그래서 깊은 레이어가 있는 네트워크에서도 모든 가중치에 그레디언트가 전달되는 것이죠.
"기술 등의 발전을 거치며 더 많은 레이어를 쌓아올린 CNN이 등장했다. Vanishing gradient라는 문제로 레이어를 쌓아올리는데 한계가 있었지만 ResNet 등이 이를 해결하며 100층 넘게 레이어를 쌓은 네트워크가 등장했다. 근데 얘들이 제안한 방식은 'short path'를 만들어 early layer와 later layer를 연결한 방식이다."
여태까지 논문에 나온 내용을 요약하면 이렇습니다. 여기까지 논문을 읽은 뒤, 저는 다음과 같은 생각이 들었습니다.
'아, 저자들이 다른 방식을 이용해 더 높이 쌓은 네트워크를 만들었구나.'
저의 생각이 맞는지 확인해봅시다. 저자는 기존에 있던 것들을 설명한 뒤 자신들이 고안한 방식을 제안했습니다. '기존 방식보다 더 단순한 연결 패턴'을 만들었다고 하네요. 정리하면 다음과 같습니다.
- 모든 레이어들을 서로 연결해 레이어간 정보의 흐름량을 최대한으로 한다.
- feed-forward nature을 보존하기 위해 이전까지 연산을 하며 얻은 모든 feature map을 입력값으로 받는다.
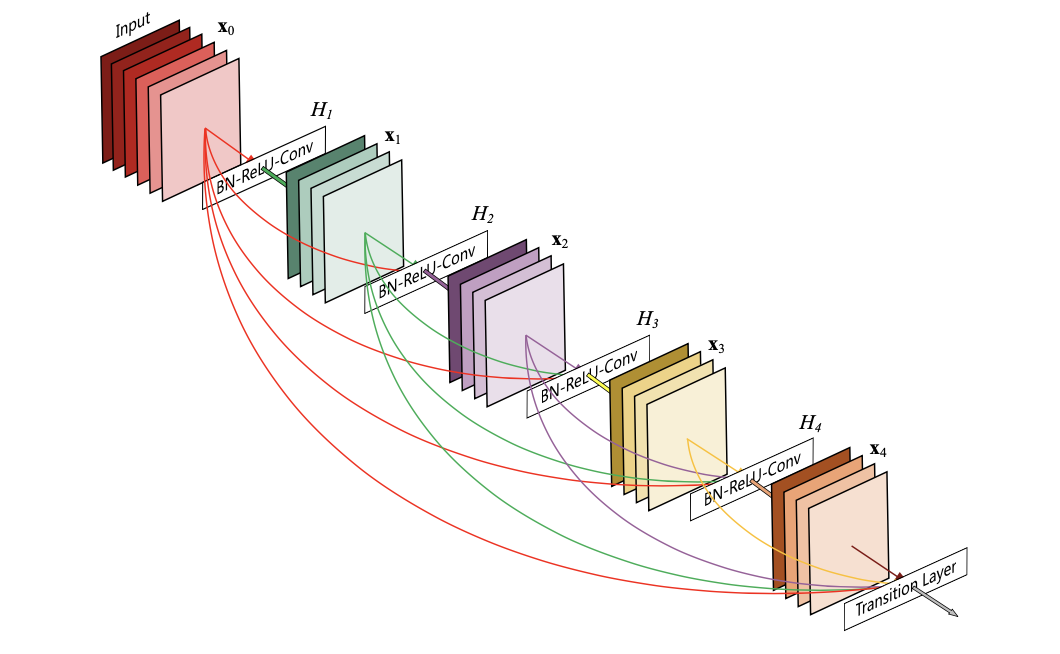
이를 그림으로 표현하면 다음과 같습니다.

위 그림은 저자가 제안한 방식으로 이루어진 5층짜리 네트워크를 나타낸 그림입니다. 모든 레이어가 선을 이용해 서로 이어진 모습을 확인할 수 있습니다. H1, H2, H3, H4가 우리가 아는 CNN 레이어입니다. 보시면 각 x0 -> x1일 때는 x0만 들어가는데 x2는 x0과 x1이 같이 H2 = [BN -> ReLU -> Conv]를 통과하는 것을 확인하실 수 있고 x3는 x0, x1, x2가 H3을 통과하는 것을 확인할 수 있습니다. 어느부분을 말씀드리는건지 쉽게 확인하실 수 있게 표시도 해놨습니다.
이를 한문장으로 나타내면 다음과 같습니다.
"L개의 레이어로 이루어진 네트워크에서 i번 째 레이어는 i개의 특성맵을 입력값으로 받으며 i번 째 레이어에서 나온 특성맵은 (L-i)개의 레이어에 입력값으로 들어간다."
그러면 위 네트워크는 총 몇개의 연결이 있는걸까요? 첫 번째 특성맵에서 입력값으로 5번, 두 번째 특성맵에서 입력값으로 4번, ...마지막 특성맵에서 입력값으로 1번, 총 1+2+3+4+5 = 15개의 연결선이 있습니다. 레이어가 5개라 1부터 5까지 더한 값이 된 것이죠. 그러니 N개의 레이어가 있는 네트워크에서는 [N*(N+1)]/2개의 연결이 있음을 알 수 있습니다. 실제로 논문에서 [L(L+1)]/2개의 direct connection이 있다고 말했습니다.
이 때 유의할 점이 있습니다. 저렇게 입력되는 특성맵들은 하나로 더해서(combine) 입력값으로 넣는게 아니라 연결해서(concatenate) 입력값으로 넣는겁니다. combine하는 방식은 기존의 방식, ResNet의 identity mapping을 말합니다.
ResNet과 비교해보면 굉장히 연결이 많습니다. 그래서 저자들도 자신들이 설계한 네트워크 이름을 Dense Convolutional Network (DenseNet)로 정했습니다. 저자는 DenseNet이 가질 수 있는 장점을 몇가지 꼽았는데요, 다음과 같습니다.
- 많은 parameter를 요구하지 않습니다.
- ResNet 대비 정보와 그레디언트의 흐름이 향상되었습니다. 그래서 학습시키기 쉬워졌습니다. 왜냐하면 이는 곧 역전파를 계속해도 그레디언트의 손실이 적다는 뜻이기 때문입니다. 그레디언트가 더 멀리, 더 확실히 전달된다면 손실함수가 원하는 방향으로 모델이 쉽게 학습됩니다.
- regularizing effect도 있습니다. 그래서 학습에 사용할 데이터셋이 작아도 과적합(overfitting)이 일어나지 않습니다.
저자는 DenseNet이 성능평가를 해보니 적은 parameter를 갖고도 좋은 성능을 냈고 당시 잘나가던 네트워크들보다 더 좋은 성능을 냈다고 말했습니다. 이는 Experiment에서 알아보도록 하겠습니다.
2. DenseNets
여기서는 Introduction에서 설명드린 DenseNet의 작동원리를 더 자세히 설명해보겠습니다.
설명해드리기 전에 정의해야할 개념들이 몇가지 있는데요, 다음과 같습니다.
- X_0 : 단일 이미지, 네트워크에 입력값으로 들어갈 데이터입니다.
- 네트워크 : L개의 H_l(·)로 구성되었습니다.
- H_l(·) : 네트워크를 구성하는 레이어입니다. Batch Normalization -> ReLU -> Pooling or CNN순으로 구성되어 있습니다.
- x_l : l번째 레이어의 출력값을 말합니다.
표현 예시 )
feed-forward CNN : [x_l = H_l(x(l−1) )]
ResNet의 skip connection : [xl = H_l(x(l−1)) + x_(l−1)]
저자는 DenseNet의 핵심인 Dense Connection을 설명하기 전에 ResNet의 skip connection는 레이어의 출력값과 identity function으로 넘어오는 입력값이 하나로 합쳐지기(summation) 때문에 네트워크 속 정보의 흐름을 방해한다고 말하며 또다시 ResNet에 태클을 거는 모습을 보여줬습니다. ResNet을 넘어보겠다는 마음가짐이 정말 절실했던게 아닌가 싶습니다.
Dense connectivity
앞서 말씀드렸듯 DenseNet은 모든 레이어들 사이에 direct connection이 되어있습니다. 그리고 레이어에 입력되는 값들은 하나로 합쳐진게(summation) 아니라 연결되어(concatenate) 있다고 말씀드렸습니다. 그러므로 l번째 레이어 이전에 생성되거나 존재했던 모든 특성맵 x0, x_1,...,x(l-1)을 입력값으로 받는 l번째 레이어의 출력값 xl을 앞서 정의한 것들을 이용해 식으로 나타내면

위와 같습니다. 보시면 입력값으로 [x_0, x_1,...,x(l-1)]인 것을 확인할 수 있습니다. 하나의 값으로 합쳐진게 아니라 서로 연결되어 하나의 데이터가 된 것이죠. 이러한 dense connectivity을 모든 레이어에서 거치기 때문에 저자는 자신들이 만든 네트워크를 Dense Convolutional Network (DenseNet)이라 불렀습니다.
입력 데이터들의 concatenate는 하나의 텐서로 만드는 방식으로 구현했습니다. 쉬운 구현을 위해 그렇게 했다고 하네요.
Composite function
H_l(·)에 대한 설명이 나오는 부분입니다. 저자는 H_l(·)을 [BN->ReLU->3x3 CNN레이어]로 구성된 함수라고 정의했습니다.
Pooling layers
여기서 Hl의 입력값에 들어가는 [x_0, x_1,...,x(l-1)]를 구성할 때 특성맵의 크기가 바뀌면 연결할 수가 없습니다. 그런데 CNN layer로 데이터를 처리하면 특성맵의 크기를 바꾸는 down-sampling의 과정은 필수입니다. 어떻게든 down-sampling을 해야된다는 것이죠.
그래서 down-sampling을 하면서 DenseNet을 구현하기 위해 네트워크를 dense block 단위로 나눴습니다. 그리고 block 단위로 CNN -> pooling을 수행하는 것이죠.

여기서 CNN, CNN->pooling 구조로 이뤄진 레이어들을 transition layers라고 불렀고 저자는 구현할 당시 BN -> 1x1 CNN layer ->2x2 pooling layer 순으로 연산하는 transition layers를 구현했다고 말했습니다.
Growth rate
레이어를 거칠 수록 이전 레이어 개수가 많아지니까 입력값으로 들어오는 특성맵 개수도 많아질겁니다. Growth rate에서는 많아지는 비율이 얼마나 되는지 설명하는 부분입니다.
만약 네트워크에 존재하는 H_l(·)에서 k개의 특성맵을 추출한다고 가정해봅시다. 여기에 k채널 데이터 x_0을 네트워크의 입력데이터로 넣으면 첫 번째 H_l에서 k개의 특성맵이 나올겁니다. 그리고 x_0과 첫 번째 H_l에서 얻은 k개의 특성맵, 즉 을 다음 레이어의 입력값에 넣을겁니다. k_0 + k개의 채널을 가진 특성맵이 입력값으로 들어가는 것이죠. 그러면 또다시 k개의 특성맵을 얻을테고 그다음 레이어에 k0 + 2k개 채널의 특성맵을 입력값으로 넣겠죠. 이러한 과정은 최종 출력값이 나올 때까지 계속 반복될겁니다.
이를 일반화 시켜보면 다음과 같이 한문장으로 정리할 수 있습니다.
l번째 레이어는 k0 + k*(l-1) 채널의 특성맵을 입력값으로 받는다.
그런데 자세히 보시면, 레이어를 거칠 수록 입력되는 특성맵의 채널이 k개씩 증가한다는 사실을 알 수 있습니다. 그래서 k를 네트워크의 'growth rate'라고 부릅니다.
저자는 상대적으로 작은 k를 지닌 DenseNet이 더 좋은 성능을 보여줬다고 합니다. 이는 모든 레어어는 이전까지 휙득했던 모든 특성맵들이 입력값으로 들어오기 때문에 휙득했던 모든 정보를 이용할 수 있기 때문입니다. 즉, 네트워크의 'collective knowledge'을 이용하기 때문이라는 것이죠.
모든 레이에서 얻은 특성맵을 다 이용할 수 있어 좋은 성능을 보여준다는 말은 이해했는데 이게 k랑 어떤 관계가 있는지는 잘 이해하지 못했습니다.
저자는 growth rate를 "각 레이어가 생산하는 '새로운 정보'가 global state에 얼마나 기여하는지 결정하는 수치"라고 말했습니다.
그리고 global state는 네트워크 내에 있는 모든 곳에서 접근할 수 있고 기존의 방식과는 달리 layer to layer로 global state를 재생성할 필요가 없다고 말했습니다. 아마 기존의 방식은 이전 레이어에서 추출한 특성맵에서 또다시 특성맵을 추출하는, 다시 말해 이전 레이어에서 얻은 정보만 사용하는 방식인데 이 때 각 레이어가 얻는 특성맵이 이전 레이어에서 추출되는 특성맵 하나뿐이기 때문에 재생성(replicate)된다고 말한게 아닌가 싶습니다.
Bottleneck layers
DenseNet에 있는 대부분의 레이어들은 엄청나게 많은 데이터를 입력받아 k개의 특성맵만 추출합니다. 저자는 3X3 CNN 레이어에 값을 넣기 전에 1X1 CNN 레이어를 사용해 특성맵의 채널 숫자를 줄이는 방식을 사용해 효율적인 계산(computational efficiency)력을 향상시켰습니다. CNN이 처리할 특성맵의 채널수가 줄어들면 계샨량이 줄어드는 점을 이용한 것이죠. 이와 같이 특성맵의 채널수를 줄여 계산의 효율성을 증가시키는 기법을 Bottlneck 기법이라고 합니다. 저는 ResNet에서 이 기법을 처음 들었으며 설명 링크에 들어가시면 명쾌한 설명을 확인하실 수 있습니다.
아무튼, 저자는 BottleNeck이 DenseNet 설계에 효율적일 것이라 판단했고 DenseNet에 도입했습니다.
도입 예
DenseNet-B : [Batch normalization -> ReLU -> 1x1 CNN layer-> Batch normalization -> ReLU -> 3x3 CNN layer]로 구성된 BottleNeck layer를 H_l에 도입. 저자는 experiment 항목에서 사용한 DenseNet의 1x1 CNN layer들이 4k개의 특성맵을 추출하게끔 만들었습니다.
Compression
저자는 모델의 Compactness를 강화하기 위해 Dense block에서 다음 Dense block으로 이동하기 전에 거치는 transition layer에서 특성맵의 채널 숫자가 줄어들 수 있게끔 설계했습니다.
만약 Dense block에서 m개의 특성맵이 추출된다면, 다음 Dense block에 가기 전에 지나가는 transition layer에서 특성맵 개수를 θm개로 만들 수 있습니다. 이 때 θ는 [0 < θ ≤ 1]의 범위를 가지는 compression factor이며 θ=1이면 특성맵의 채널 개수를 유지하며 다음 Dense block으로 넘어가게 되겠죠.
저자는 DenseNet-C의 θ는 1보다 작은 값이 되게끔 정했고 experiment에서는 θ를 0.5로 정했습니다. 그리고 bottleneck, transition layer의 θ가 모두 1보다 작은 DenseNet을 DenseNet-BC로 정의했다고 하네요.
Implementation Details
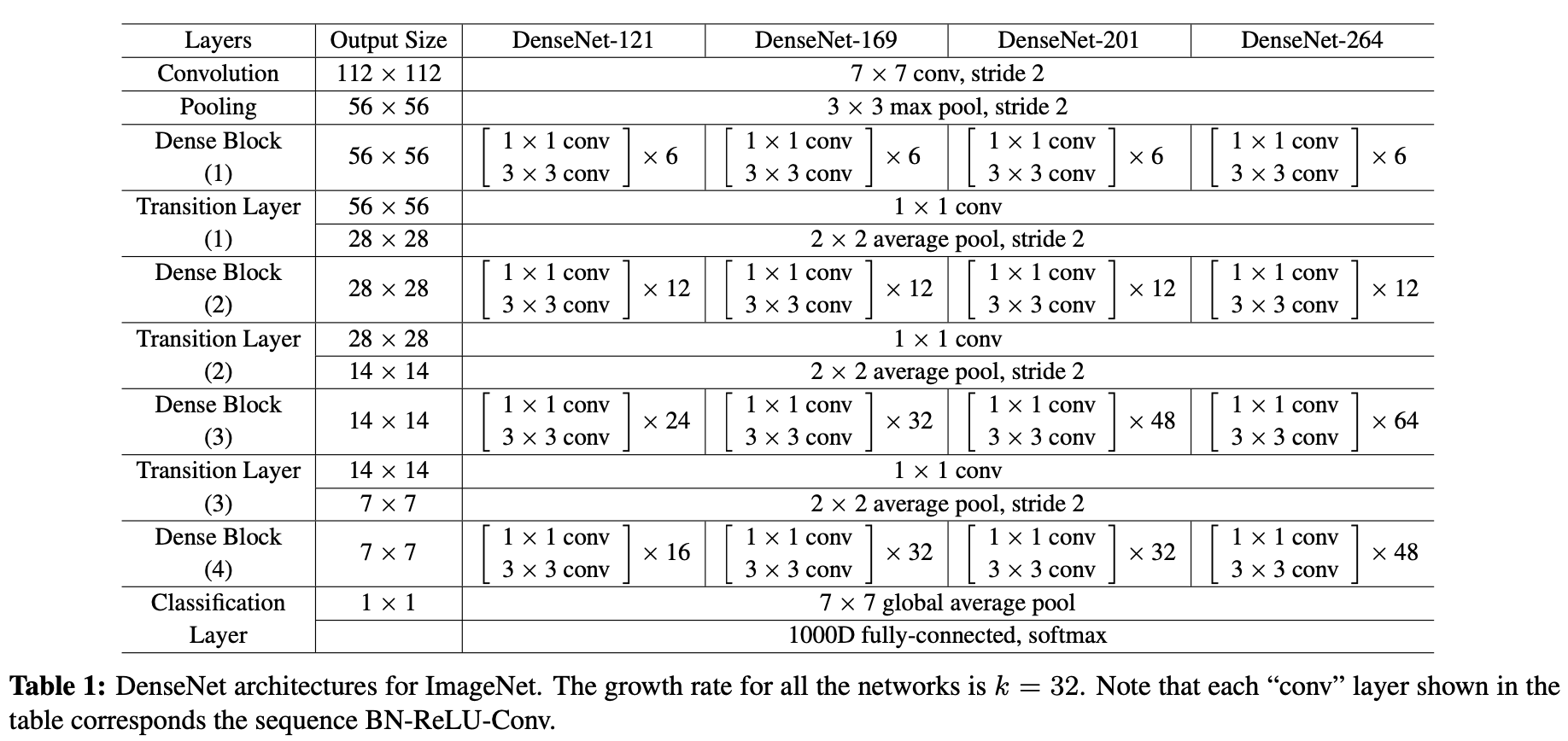
DenseNet를 구현하기 위한 내용이 담겨있습니다. 저자는 3x3 CNN 레이어는 1픽셀만큼 zero padding을 사용하였고 두 개의 Dense Block 사이에 있는 transition block에서는 average pooling 레이어를, 마지막 Dense block과 연결된 transition block에서는 global average pooling 레이어를 사용했습니다. 그 외 자세한 구현 내용은 Table 1을 통해 확인하실 수 있습니다.
(저자가 실험에서 사용한 DenseNet-BC의 구조입니다.)
3. Experiments
Datasets
실험결과는 다음과 같습니다. 데이터셋에 따른 네트워크들의 Error rate(%)를 표시해놓은 표입니다.

여기서 Depth는 Layer 개수, Params는 네트워크에 있는 weight 개수입니다.
그리고 C10, C10+ C100, C100+, SVHN는 데이터셋에 대한 설명인데요, 각 항목에 대해 정리하면 다음과 같습니다.
C10, C100
CIFAR dataset을 말합니다. Classification을 목표로 만든 네트워크를 학습시킬 때 많이 쓰는 32X32 크기의 3채널 이미지 데이터셋입니다. 이중 C10은 10개의 객체로 구성된 데이터셋, C100은 100개의 객체로 구성된 데이터셋입니다. 데이터셋은 50,000장의 학습용 데이터셋과 10,000장의 테스트용 데이터셋으로 구성되었으며 저자는 학습용 데이터셋에 있는 사진 중 5,000장은 검증용 데이터셋으로 사용했습니다. 그리고 '+'가 붙은 것들은 데이터 증강(data augmentation)을 적용한 것들입니다.
저자는 학습용 데이터셋으로 학습시킨 뒤 마지막에 테스트용 데이터셋으로 test error를 측정해 표에 실었습니다.
SVHN
The Street View House Numbers dataset을 말합니다. 32X32 해상도의 digit 이미지로 구성된 데이터셋이며 73,257장의 훈련용 데이터셋과 26,032장의 테스트용 데이터셋으로 구성되어 있는데 여기에 additional training용으로 531,131장의 사진이 추가되었습니다. 그리고 학습용 데이터셋에서 6,000장을 검증용 데이터셋으로 사용했다고 하네요. 그리고 0~255 범위의 픽셀 데이터 범위를 0~1로 Normalizing했으며 학습시키는 동안 검증 에러(validation error)가 가장 작은 모델을 선정, 테스트용 데이터셋으로 test error를 측정해 표에 실었습니다.
Table에서 확인할 수 있는 추가적인 정보들
- Capacity : L과 k가 증가할 수록 성능이 더 좋아졌습니다.
- Parameter Efficiency : 250개의 레이어를 가진 DenseNet은 1530만개의 parameter(가중치)만 가지고 있습니다. 허나 3000만개보다 더많은 parameter를 가진 FractalNet and Wide ResNets보다 더좋은 성능을 보여줬습니다.
- Overfitting : DenseNet은 parameter가 비교적 적습니다. 그래서 overfitting이 적게 진행되는 경향이 있습니다.
Training
저자는 최적화 방식을 SGD로 정했습니다. 그리고 나머지 부분을 표로 정리하면 다음과 같습니다.

Classification Results on CIFAR and SVHN
앞서 보여드린 결과 외에도 다양한 실험결과가 있습니다.
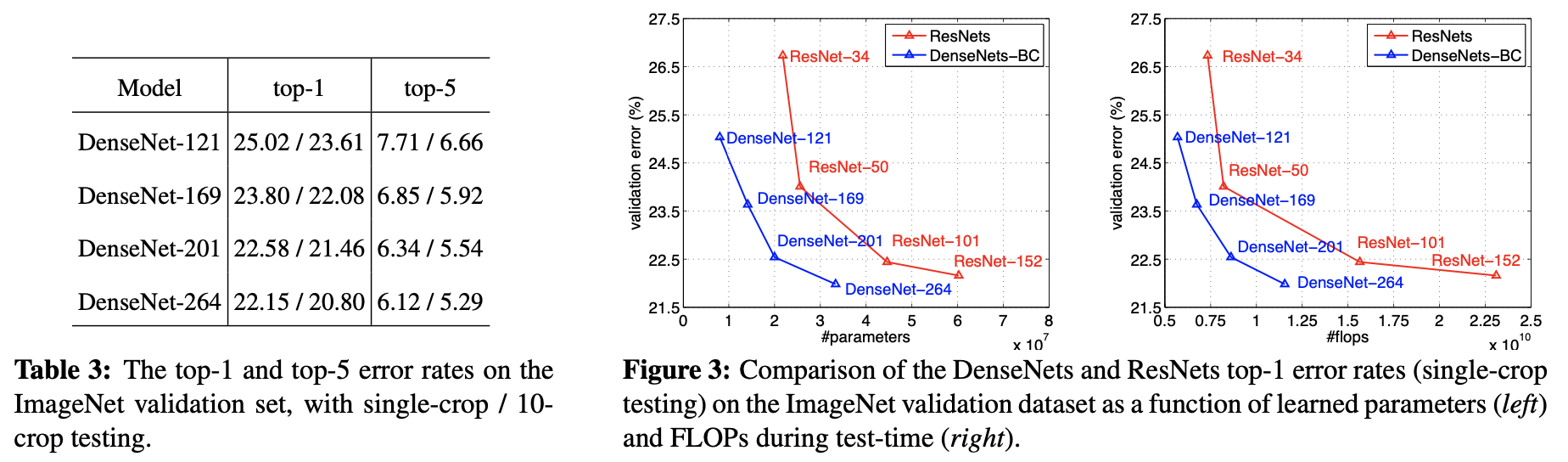
(여기 Table에서 사용된 네트워크들은 ImageNet으로 학습시켰습니다.)
top-1 error : 네트워크가 예측한 클래스(가장 확률 높다고 예측한 객체)와 실제 객체가 다를 확률
top-5 error : 네트워크가 예측한 5개의 클래스(가장 확률이 높은 상위 5개 객체)에 실제 객체가 없을 확률
출처
4. Discussion
여기서는 ResNet과 DenseNet은 별다른 차이가 없는데 그 미세한 차이로 인해 상당히(substantially) 다른 모습을 보여준다고 말하며 [Model compactness, Implicit Deep Supervision, Stochastic vs. deterministic connection, Feature Reuse]를 주제로 다양하게 두 모델을 비교합니다. 정말 ResNet을 뛰어넘고 싶었구나 느껴진 부분이었습니다. 정말 자세히 적어놨으니 기회가 된다면 읽어보시길 추천하는데 DenseNet이라는 네트워크 구조를 알고자 읽으시는 분들은 넘겨도 되는 부분이라 생각됩니다.
5. Conclustion
결론 부분입니다. 저자는 새로운 convolutional network architecture를 제시했고 Dense Convolutional Network (DenseNet)라고 이름 지었습니다. DenseNet은 같은 특성맵 크기를 가진 레이어들 사이의 direct connection을 구현했으며 레이어가 수백층 쌓여도 학습에 어려움이 없음을 보여줬습니다.
그리고 성능을 측정했을 때, parameter의 증가에 따라 정확도가 늘어나는 모습을 꾸준히 보여줬습니다. 레이어를 쌓는 것에 비례해 성능도 계속 증가했다는 것이죠. 즉, performance degradation이나 overfitting가 나타나지 않았다는 겁니다. 그리고 다른 네트워크들보다 비교적 더 적은 parameter를 가져 계산량이 줄어들었지만 오히려 더 좋은 성능을 자랑했습니다. 저자는 자신들이 ResNet이 사용했던 hyperparameter settings을 그대로 사용했는데 좋은 결과가 나왔으니 DenseNet에 최적화된 hyperparameter settings를 적용하면 더 좋은 성능이 나올 것이라 믿고 있다고도 말했습니다.
그리고 앞서 말했던 DenseNet의 장점을 요약해서 계속 설명해주고 마지막에 'such feature transfer with DenseNets'을 연구할거라고 하며 논문을 끝냅니다.
리뷰 후기
어우...너무 긴 리뷰였습니다. 최대한 간단하게 쓰려고 했는데 이것 저것 넣다보니 너무 길어졌습니다.
그래도 쓰고나니까 뿌듯했습니다.
아마 내일부터, 정확히는 이번주가 기말고사 2주 전이라 시험공부를 해야되서 최소 2주간 논문 리뷰는 못할듯 합니다. 아쉽네요. 얼른 종강하고 논문 리뷰를 할 날이 왔으면 좋겠습니다.
그럼 다음글에서 뵙겠습니다.
