[paper]An Image is Worth One Word(2022) - Textual Inversion의 후속 논문
My summary - 인코더를 추가하고 Attention weight를 건드려 기존의 방법론(DreamBooth , Textual Inversion)에 비해 아주획기적으로 시간 단축과 성능향상을 이끌어냈다.
해당 논문의 코드가 발표되면 SNOW에서 바로 적용할듯...?
이미 구현하고 있을지도
해당 논문 , TI는 엔비디아 DB는 구글에서 발표
스노우에서 AI아바타(유료)를 생성하려면 사진 10개 이상이 필요하며 10분이상이 소요된다.
안해봄
스노우(+렌사)에서 Personalization을 어떤 방법을 썼는진 모르겠지만 DB일듯 해당 논문 방법을 사용한다면 게임체인저가 될 것은 분명해 보인다.
텍스트
Main Idea
객체 S에 대해 특징을 추출하여 Image Generation을 할 때 S의 특징을 반영한다.
객체 S가 속한 Domain으로 훈련된 모델에 S를 적용할 수 있으며 인코더 구조로 객체S의 latent 특징을 추출 , 기존 Domain weight에 추출한 weight Offset을 더하여 이미지 생성
Key Architectures
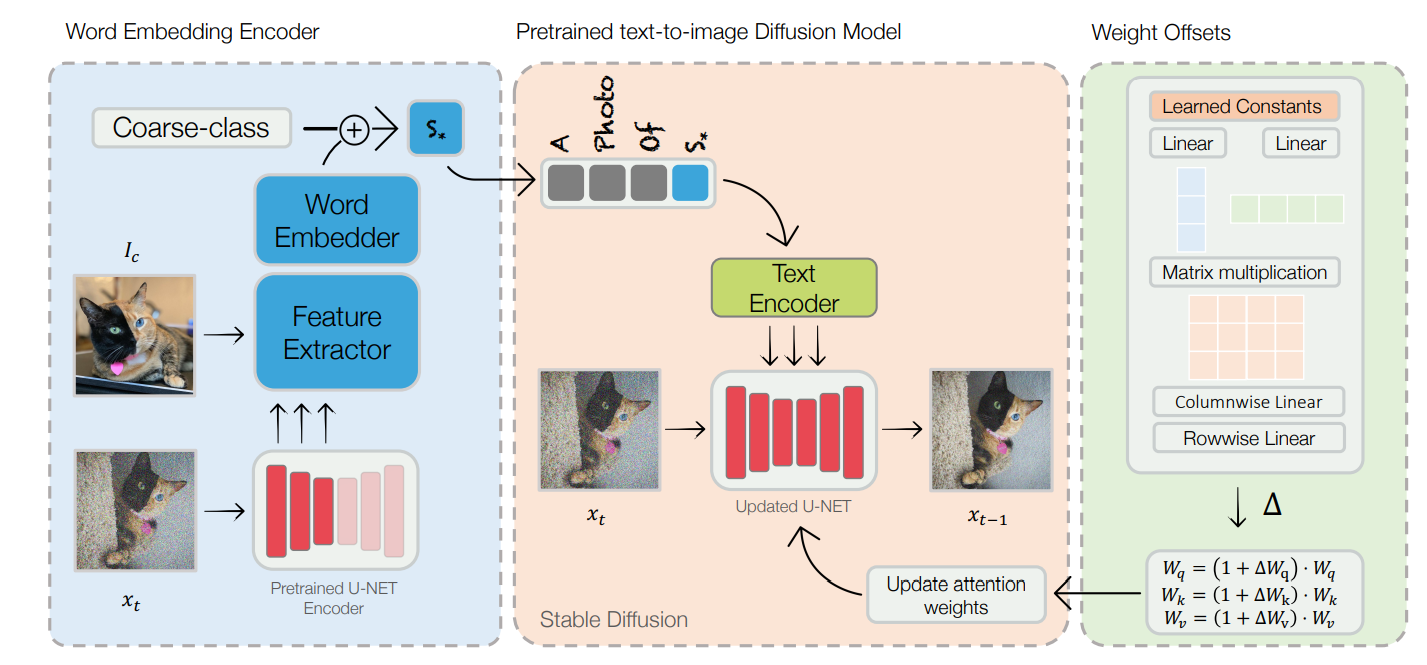
Domain-tuning : 기존의 Diffusion Model은 가운데의 빨간 박스 부분으로 새롭게 Encoder와 weight offset 갱신을 추가함
Encoder
우선, Textual Inversion에서 사용한 것 처럼 word embedding space에서 추출을 시도했음 -> 많이 바꿀 수록 S의 특징이 덜 반영됨 (trade-off reconstruction and editability)
S의 특징을 Latent 단위에서 추출해야하고 추출한 Offset으로 Generator tuning을 진행해야한다.(Pivotal Tuning for Latent-based Editing of Real Images[2021]의 접근법 사용)
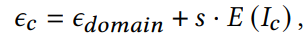
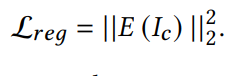
Encoder(E)를 통해 객체의 특징 추출 , s는 보통 0.1을 씀(도메인에 따라 다른듯)
E-domain은 pretrained model의 임베딩
인코더의 규제식 : S concept의 과적합 방지
Encoder Architectures
블럭의 top부분엔 이미지-텍스트 매핑하는 CLIP ViT-H/14모델이 있고,
각각의 Feature vector는 Linear layer - 평균 Pooling - LeakyReLU를 거치며 마지막엔 임베딩레이어(Linear layer)를 거쳐 E(Ic) 출력
Iteration refinement
내가 원하는 이미지에 대한 latent code가 있을 것이다.
요놈을 fine-tuning? 내가 원하는 이미지 + Personalization하는 과정
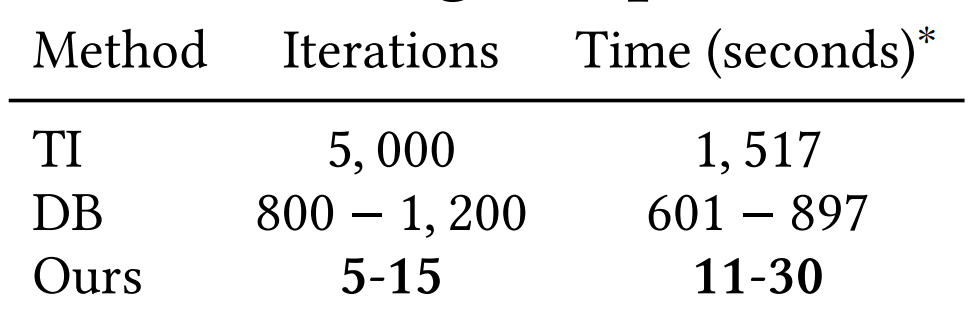
우리의 저자들은 단 5~15회만에 끝내셨다.
단 이미 널리 쓰이는 LDM모델은 논문에서 사용한 Feature추출 인코더와 맞지 않아 저자들은 U-net의 인코더를 사용함 (LDM사용하면 메모리와 시간 낭비가 생긴다고 함)
???????????? (수정하기)
weigt offset
????????????????개념이 모호한 부분 추후 수정 필요!
U-NET에서 Iteration을 거치며 노이징-디노이징을 반복함
이때 어텐션 매트릭스를 매 Iter마다 갱신하여 만족할만한 reconstruct을 얻음
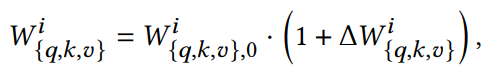
d Wi 는 i Layer에서 배운 어텐션 weight 즉, Weight Offset
위의 식을 통해 Offset이 더해진 어텐션 weight로 사용 가능
성능

신기함~
용어
Latent code : noise
