InternImage-H
특이사항
- 아래의 M3I pre-training과 세트임
- CNN도 TF와 같은 모델 size를 갖으면 CNN도 충분히 좋아질 수 있다.
- CNN의 단점은 멀리 떨어지면 잘 모름(Long-range dependency)
- Dynamic sparse kernel로 해결
- TF의 구조를 가져옴
- N개의 블럭 : LN + FFN
- MHA대신 DCN
- 결론 : 기존의 DCN과 효과적인 TF구조를 결합! (MHA -> DCN변경)
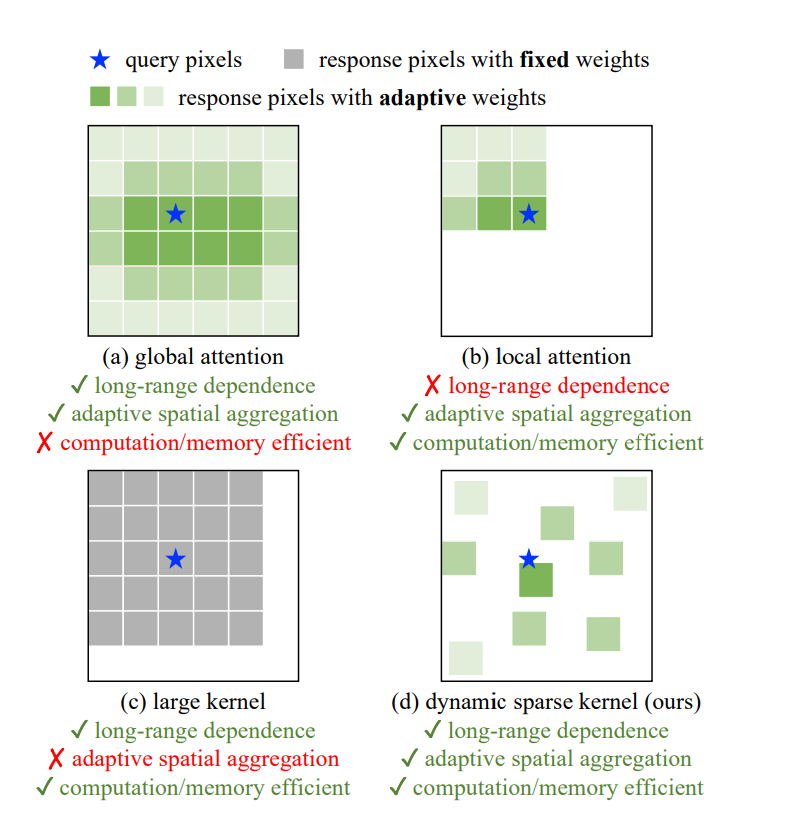
[Core operator 비교]
-
long-range dependence : 멀리 떨어진 정보를 반영할 수 있는가?
-
adaptive spatial aggregation : 결과를 도출할 때 적절한 지역의 정보를 사용하는가?
-
Global Attention : Vit
- patch의 global한 attention연산 수행
- 지나친 computing 리소스 사용
-
Local Attention : Swin Transformer
- 특정 영역을 나누고 해당 영역내에서 attention사용
- (?)layer마다 특정 영역이 달라지고 블럭(stage)마다 patch merge가 있음
-
Large Kernel : ConvNeXt , RepLKNet , SLaK
- 위으 모델 순으로 큰 사이즈 커널 , 큰사이즈 커널 + 작은 사이즈 커널 , 듬성듬성하게 랜덤한 위치에 커널 적용(연산량 줄이기)
- 위으 모델 순으로 큰 사이즈 커널 , 큰사이즈 커널 + 작은 사이즈 커널 , 듬성듬성하게 랜덤한 위치에 커널 적용(연산량 줄이기)
-
Dynamic sparse Kernel(ours)
- deformable convolution(DCN)의 개선 버전 : 3x3커널을 적용한다 하면 9개의 픽셀에 기존 처럼 적용하는 것이 아닌 그 주변의 픽셀에 cnn 적용
- 장점 : 모델이 물체의 다양한 scale을 탐지할 수 있음(커널의 offset이 학습가능)
[모델 구조]
크게 왼쪽의 전체적인 모델구조 / 오른쪽의 DCN구조로 나눌 수 있음
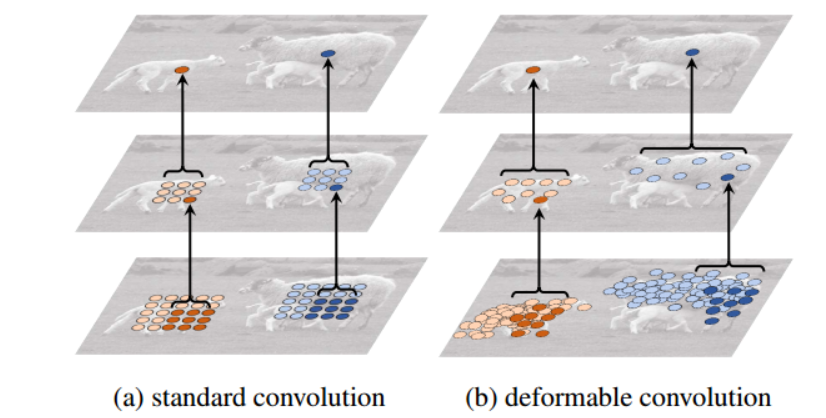
DCN(Deformable Convolution Layer)
(이해하면 지우기)
- V1 : 위의 DCN구조를 제안, 정해진 grid에서 feature추출x 정해지지 않은 위치에서 feature추출o
- V2 : V1 + modulation(weight sum) 중요한 위치의 가중치 up
- V3(our)
- Convolutional weight 공유(그룹마다 공유하는듯)
- Multi-group 메커니즘 : 기존은 모든 input feature에 대해 feature map생성
- 연산량 down , 그룹마다 offset 맵 할당으로 다양한 offset활용
- ex) (이해한게 맞다면) hxwxc의 경우 channel을 axb로 나눔 -> b개의 그룹이 생성 a개의 필터는 weight 공유이므로 1개 -> 따라서 기존의 커널 k x k x (1xaxb)로 나눌 수 있음
- modulation 변경 : 0~1값을 갖기 위해 v2에선 sigmoid사용했음 -> softmax로 변경 => Normalize효과
- sigmoid는 불안정성을 갖을 수 있음
전체 구조
- input image->stem(3x3커널 gelu~)->stage+downsampling 반복)
- stage = (basic block) x N : 기존 트랜스포머 블럭에서 MHA -> DCN


Trendy AI Developer