논문 링크
Github - Facebook research
Inference 예제 코드 - Faceboock 제공
개요
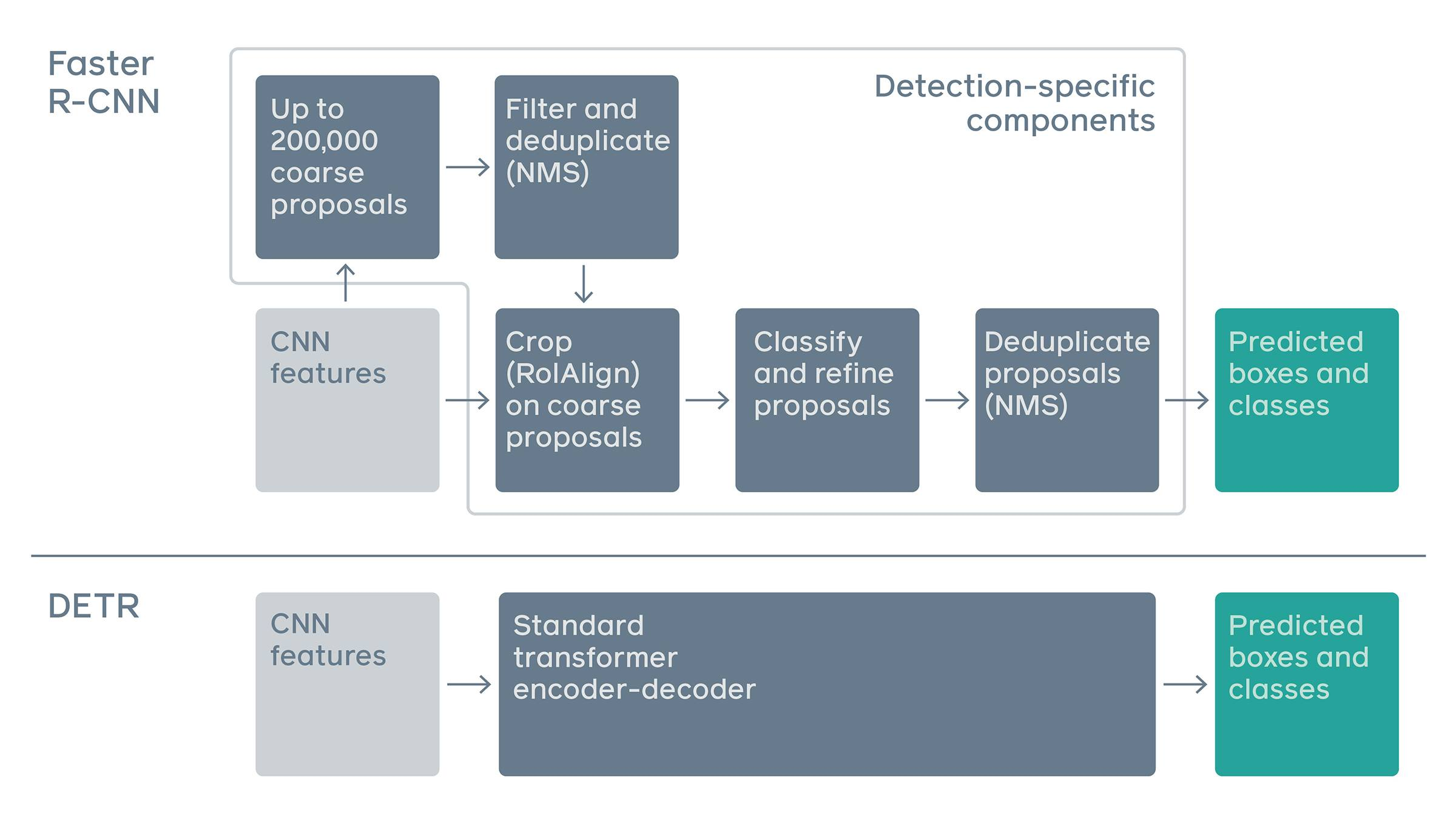
- 기존의 방법론은 one stage건 two stage건 RPN과 NMS등 필요한 개념이 많고 복잡함
- RPN과 Anchor box ,NMS는 몇 천개의 영역을 처리해야함(post-processing)
- 이는 구현하기도 어렵고 복잡함
- DETR은 매우 간단한 구조 + 괜찮은 성능
- 기존의 방법론은 몇년에 걸쳐 개선됬음(YOLO , mask-rcnn 등)
- DETR이 압도적인 성능은 나타내지 못했지만 발전 가능성을 보여줌
- 실제로 Deformable , swin , SSL로 후속 모델은 SOTA
- DETR의 contribution
- 이분 매칭 손실 함수
- Encoder-Decoder의 Transformer구조 모델 제안
< Prior Object Detection Model vs DETR>
- 기존의 방법은 End to End 구조라고 말하긴 힘들다
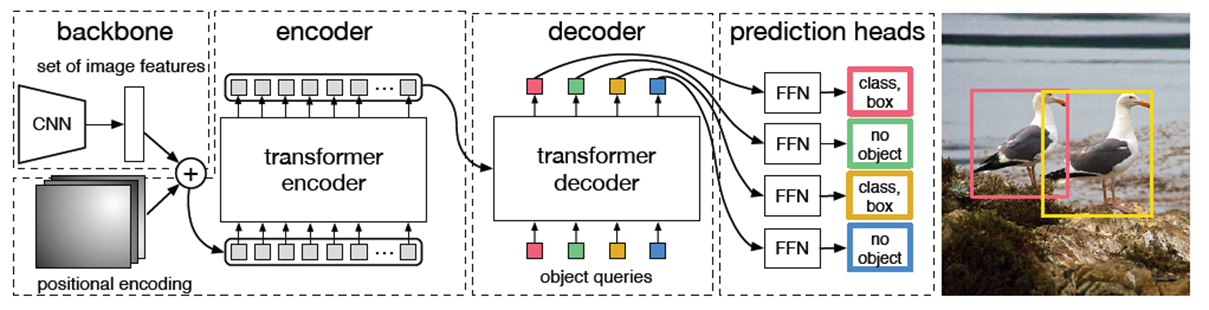
모델 아키텍처
- Backbone : Transformer에 들어가는 Feature map을 뽑아내는 모델
- 논문에선 ResNet50,101 사용
- 논문에선 ResNet50,101 사용
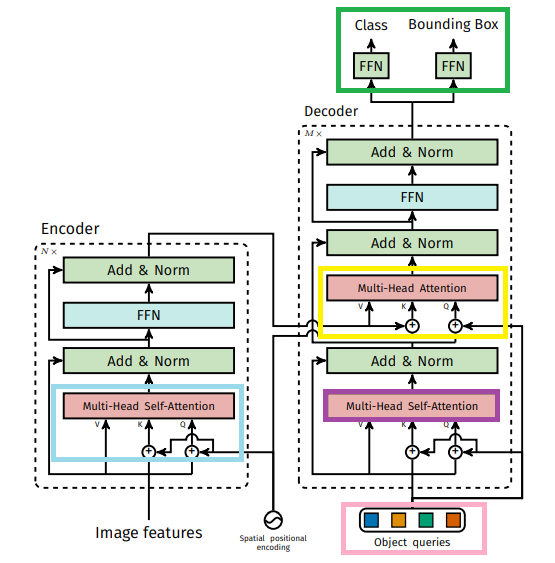
- Embedding : Transformer의 입력으로는 x 의2차원 구조여야 함
- x x 의 3차원 Feature map을 -> 으로 x -> 로 바꿔 2차원의 구조로 변경
- 1x1 Convolution으로 channel -> D (C>D)
- Positional encoding은 Q,K,V 중 Q와K에만 적용
(지금은 중요하지 않으니 패스)
- 기존 TF에선 Q,K,V모두 적용
- x x 의 3차원 Feature map을 -> 으로 x -> 로 바꿔 2차원의 구조로 변경
- Encoder의 역할
- 같은 Instance끼리 높은 attention을 가짐(시각화)
- <Encoder의 마지막 layer의 Attention map(weight) 시각화>
- 어떻게 4개가 나오지? - head마다 각각??????

- Decoder의 역할
- N개의 object query : 최대 N개의 Instance 검출 가능 / x 의 크기를 가짐
- 각각의 Object query는 Self-Att와 Encoder를 K,V를 쓰는 Co-Att을 통해 각각 곂치지 않게 예측하게 됨
- ??? : object query이 co-att(encoder의 output)과 att하므로 가까운 위치 즉 , encoder input과 가까운 위치의 객체로 매핑? (예제코드엔 object q에 positional없음)
- ??? : object query이 co-att(encoder의 output)과 att하므로 가까운 위치 즉 , encoder input과 가까운 위치의 객체로 매핑? (예제코드엔 object q에 positional없음)
- <Decoder의 마지막 layer의 Attention map(weight) 시각화>
- 박스에 접하는 부분에 높은 값 -> 테두리를 잘 학습한다.

- 출력
- N개의 unit은 FFN을 통과하여 class와 Box를 예측함
- 이분 매칭 : 헝가리안 알고리즘 - A>B일 때 cost가 최소로하여 A개중 B개를 B로 매칭
- N개의 object unit / M개의 Ground truth box가 있다면
- brute fore의 시간복잡도는 / 헝가리안 알고리즘은
- cost
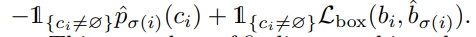
-
트랜스포머 구조
-
Loss 함수
- N개의 Unit에 대해서
- 앞에 -logPc는 결국 크로스 엔트로피 수식과 동일
- 뒤는 class가 존재한다면 박스 크기와 위치 맞추는 L1 loss + GIOU
- IOU의 단점 때문에 개선된 GIOU

참고
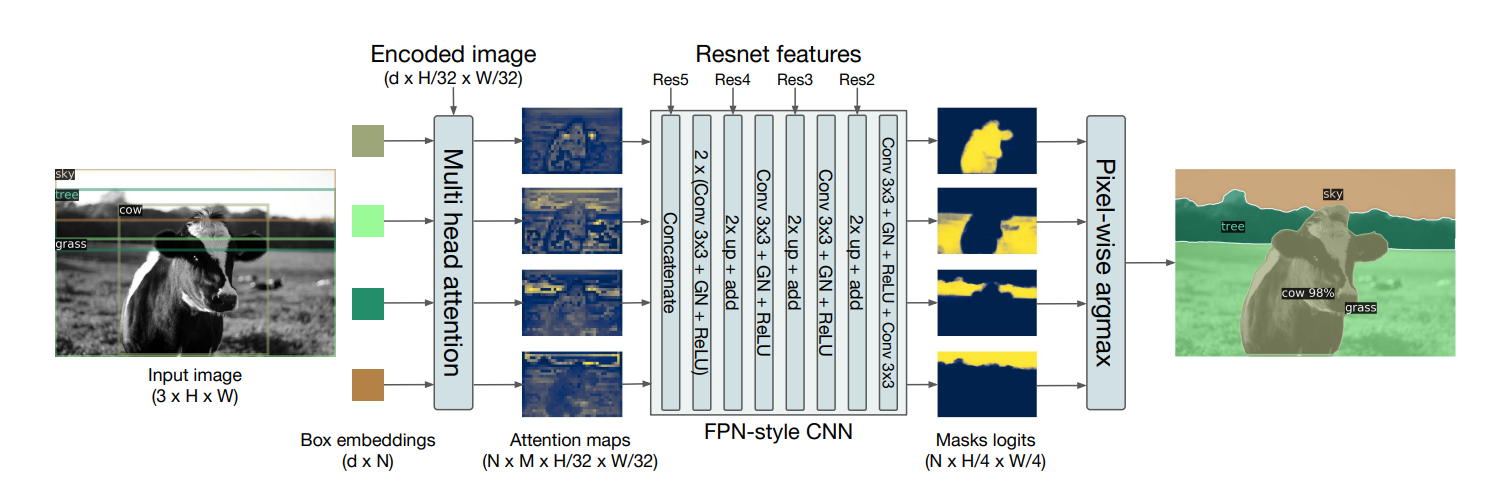
후처리를 다르게 해주면 segmentation도 동일하게 수행가능함
마무리
- 단점
- TF이므로 학습에 많은 시간
- small object 탐지 성능 떨어짐
- 장점
- TF를 object detection에 사용
- 깔끔한 End to End구조
- 후에 나온 Deformable(att할 때 효율) , swin(다양한 scale) , SSL로 성능향상

Trendy AI Developer