Sound 특성
소리는 파동이다. - 진동방향과 진행방향이 서로 직각인 횡파
- 이미지는 R,G,B의 세가지 요소로 이루어져 있다면
- 소리는 크기 , 높낮이 , 음색의 3요소로 이루어져 있다.

-
크기
- 단위는 DB(데시벨) , 폰(phon) , 손(sone)
- 파동의 진폭의 크기에 따라 결정된다.
- 진폭의 크기가 클 수록 큰 소리가 남
특징 - 크기에 을 사용하기 때문에 10dB가 높다면 크기는 10배 큼 , 20dB가 높다면 10^2=100배가 큼
-
높낮이(Pitch)
- 단위는 Hz(헤르츠) , CPS(cycle per second)
- 파동의 주기에 따라 결정된다.
- 초당 진동수(hz)가 높을수록 높은 음의 소리가 난다.
- 한사이클이 전부 지나가야 1번 진동했다고 카운트한다.
특징 - 한 옥타브가 높아질수록 주파수는 2배가 된다 , 인간의 가청주파수는 20~20kHz
-
음색(Timbre)
- 같은 음량 , 주기를 가진 소리라도 파형의 형태가 다를 수 있다.
- ex) 바이올린과 피아노의 음색은 다름
특징 - 현실의 음은 여러 주파수의 결합이다. -> Frequency Spectrum으로 이어짐
sample & bit rate
가로의 촘촘함 = sample rate => 보통 44.1khz
세로의 촘촘함 = bit rate => 16bit or 32bit ex)float32 , float16

주파수 분석
주파수 분석 : waveform -> Frequency represent
소리는 다양한 주파수의 합으로 볼 수 있다.
푸리에 변환 : 소리를 다양한 주파수의 sin , cos 주기함수로 분해
- 푸리에 변환을 통해 모든 신호를 sin,cos의 주기성분으로 분해 가능하다.
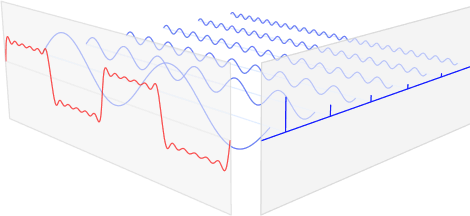
- Spectrum : 신호(소리)를 주파수 대역 별로 분해한 것
- 전체 time에 대해 처리를 하므로 시간축이 없음.
- 전체 time에 대해 처리를 하므로 시간축이 없음.
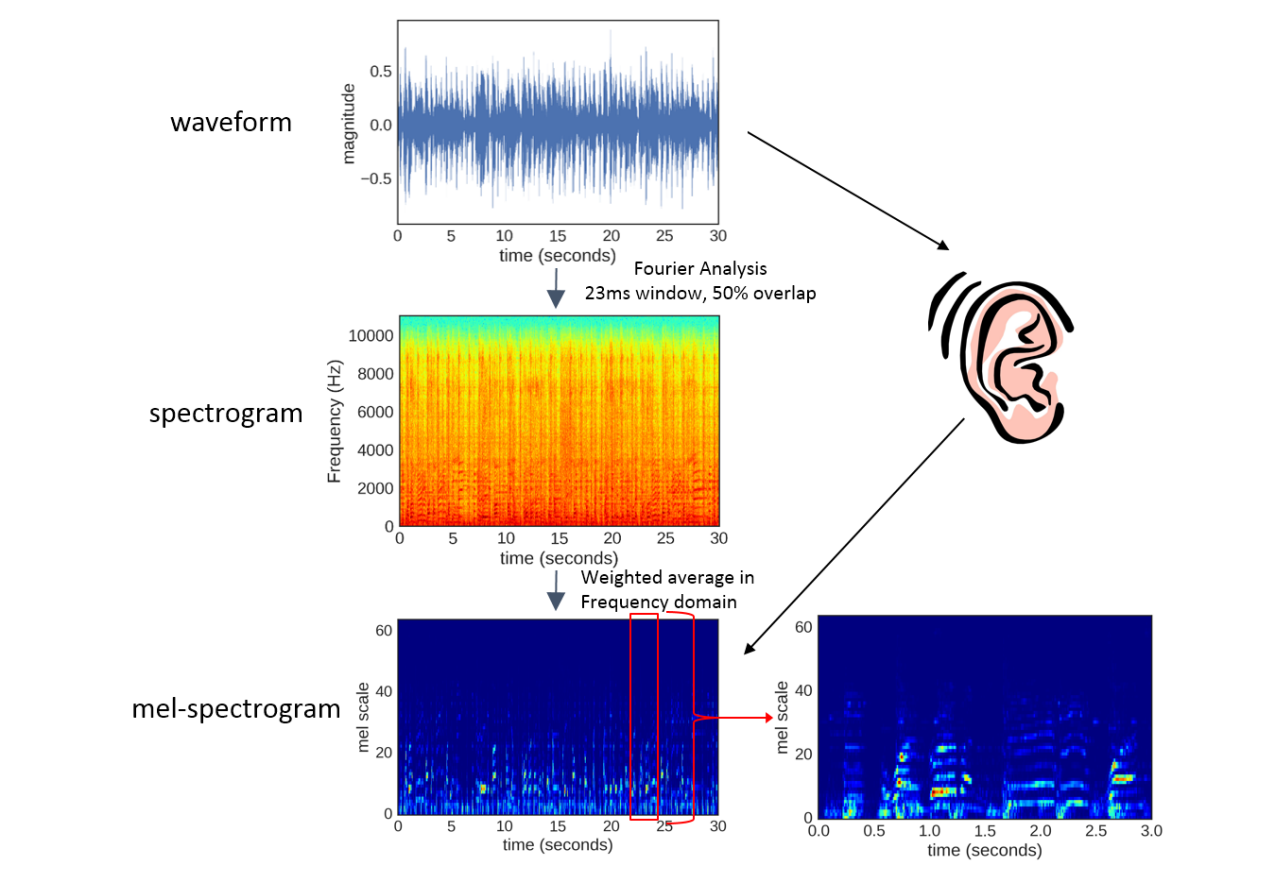
- Spectrogram : STFT로 일정한 시간마다 푸리에 변환을 함.
- 일정시간(window)마다 소리의 특성을 나타낼 수 있음
- 2D형태지만 시간,주파수대역,크기의 3차원 정보를 내포하고 있음
- Mel-spectrogram : 사람이 잘 인식하는 주파수에 가중치를 줌.
- 일반 spectrogram은 linear한 주파수를 사용하는 반면 mel filter는 log scale
- 일반 spectrogram은 linear한 주파수를 사용하는 반면 mel filter는 log scale
- MFCC : Mel-spectogram 에서 배음을 추출하기 위한 알고리즘.
- 소리는 여러 주파수로 이루어져있고, 주파수(기음:가장 큰 주파수)는 배음을 가지고 있음
- ex) 1000hz 주파수는 1000hz보다 작은 2000hz를 가지고 있고 더 작은 3000hz를 가지고 있음.
Librosa
librosa.stft(y, *, n_fft=2048, hop_length=None, win_length=None, window='hann', center=True, dtype=None, pad_mode='constant', out=None- y : 입력 오디오값으로 1차원 배열이 되어야 한다.(waveform)
- n_ftt : FFT진행할 윈도우 크기
- n_ftt가 크면 주파수에 대한 분석을 잘할수 있지만 시간에 따른 분석은 힘듦
- 주파수 해상도와 시간해상도의 Trade-off가 존재
- hop_length : 자연스러운 spectrogram을 위해 몇개의 sample을 겹치게 할 것인지.
- default : n_ftt//4 즉, 1/4는 겹치게 한다.
- win_length : n_ftt에서 자른 window에서 얼마나 사용할지
- defalut : n_ftt와 동일
- n_mels : n_mels차원의 filter
- return값은 (n_mels x 길이)의 mel-spectrogram]
- fmin , fmax : fmax의 default값은 sr/2.0
- fmin ~ fmax의 주파수를 n_mels으로 나눔

Trendy AI Developer