2023년 6월 인용수 302회
Introduction
- 기존의 audio represent sota는 CNN+ Attention 메커니즘이었다.
- 해당 논문에선 CNN을 쓰지 않고 오로지 Attention만 사용한 최초의 Audio Transformer를 제시한다.
- CNN을 사용하지 않는 장점
- 성능
- CNN은 spatical lacality(지역성)를 기저로 한 메커니즘이다.
- 따라서 TF 모델은 Inductive bias 없이 Only Attention만 사용하기 때문에 모델의 고점이 더 높다.
- 하지만 많은 data가 필요(TF의 단점) -> ImageNet Vit로 해결
- Input format
- CNN은 고정된 shape의 input값만 넣을 수 있음
- TF을 이용한 방법은 MAX_LENGTH이하의 input을 넣을 수 있음
- AST에선 1 ~ 10초의 Audio data 를 사용가능
- 성능
Model Architecture
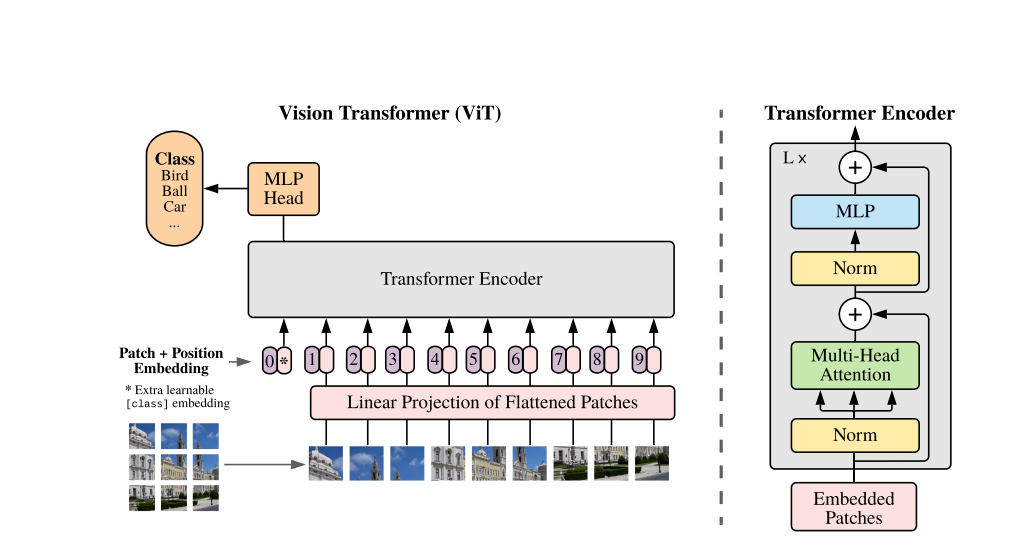 vit architecture
vit architecture
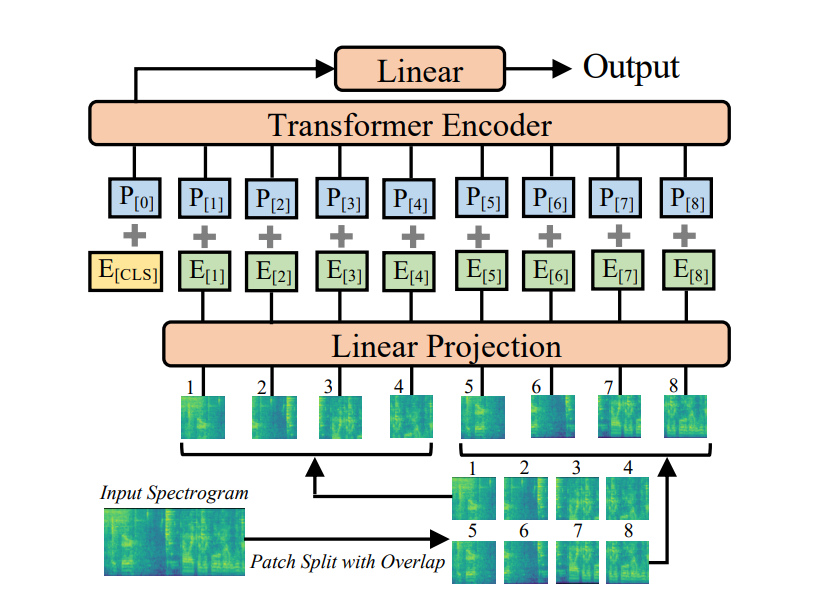
- Input data : 음성(waveform) -> Mel-spectogram
- 1초 = 1000ms / window_size = 25ms / 10ms마다 / 128 mel-filter 사용
- t초의 음성은 128x100t 의 shape을 갖게 됨
- Patch : 16 x 16 + overlap
- time과 frequenct 방향으로 6씩 overlap하게 만듦
- 128x100t -> 12x(100t-16)/10개의 patch가 생성
- Embedding patch (linear projection)
- 16x16 -> 1x768
- +positional Embedding 추가 : 1x768
- Linear layer :
- 분류를 위한 linear layer
- encoder의 output (B,N,D_model) -> reduce mean : (B,D_model) 후 classify
- vit의 구조와 동일
- But, vit의 input image는 R,G,B 3채널을 갖는다.
- AST는 patch embedding에서 3개의 weight를 average해서 사용
- ImageNet으로 pretrained vit모델을 약간의 조정으로 바로 사용
- 이렇게 한 이유 : 사용하기 쉬우라고
- 이렇게 한 이유 : 사용하기 쉬우라고
- But, vit의 input image는 R,G,B 3채널을 갖는다.
- Normalization
- spectrogram을 평균 0 , 표준편차 0.5로 정규화
실험
-
Dataset : Audioset
- classification sota달성
- classification sota달성
-
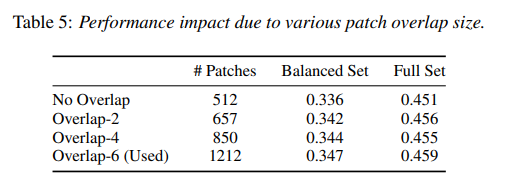
overlap
- overlap을 통해 frequency와 time에 따른 세세한 변화를 볼 수 있지만 patch수가 많아지는 단점이 존재.
- overlap이 없어도 이미 sota
- 미미한 성능차이 , 다른 논문에선 안쓰임
-
patch size
- 128x2 가 가장 성능이 좋았지만 사용하지 않음 -> ImageNet pretrained model이 없음
- positional Embedding을 했지만 시간순서로 하는게 좋다.
- 32x32보다 16x16이 좋음 -> patch는 작을수록 좋다.

- 128x2 가 가장 성능이 좋았지만 사용하지 않음 -> ImageNet pretrained model이 없음

Trendy AI Developer