해당 논문에서는 language model과 neural machine translation에서 input embedding과 output embedding의 weight tying의 효용성을 소개합니다.
[Abstract]
해당 논문에서는 neural network language model에 가장 적합한 weight matrix에 관하여 연구를 수행하였습니다. 해당 논문에서는 이 weight matrix가 적절한 word embedding을 구성한다는 것을 보였습니다. 해당 논문은 language model을 학습할 때 input embedding과 output embedding을 혼합하여 사용하는 것을 추천합니다. 또한 output embedding을 regularizing하는 새로운 방법을 소개합니다. 마지막으로 weight tying을 통해 neural translation model의 성능을 유지한 채로 parameter를 절반까지 줄일 수 있었습니다.
1. Introduction
일반적인 neural network language model에서 current input word는 C차원의 vector c로 표현할 수 있고, vector c는 word embedding matrix U를 통해서 dense representation으로 표현될 수 있습니다. Word embedding (U^T)c에 몇 가지 계산을 통하여 activation h_2를 만들어낼 수 있습니다. h_2 vector는 second matrix V를 통해서 단어 마다 score 값을 갖는 vector h_3=Vh_2로 변환됩니다. Score vector는 softmax function을 통해서 다음 단어 예측의 기반이 되는 확률값으로 변환됩니다.
해당 논문에서는 U를 input embedding, V를 output embedding이라고 부릅니다. 두 행렬 모두에서 유사한 단어의 row는 유사할 것으로 여겨집니다. Input embedding에서는 network가 동의어에서는 유사하게 행동할 수 있도록하고 output embedding에서는 서로 대체할 수 있는 단어들은 유사한 점수를 갖도록 합니다.
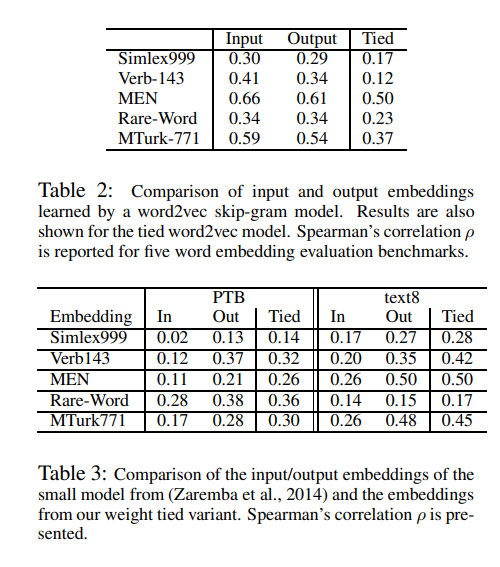
U와 V가 모두 word embedding의 역할을 하고 있지만, 일반적으로 연구 등에서는 U만 실질적인 word embedding의 역할을 수행합니다. 해당 논문에서는 input embedding과 output embedding의 quality를 비교합니다. 비교를 통해서 output embedding이 neural network language model의 성능을 높이는데 사용될 수 있다는 것을 보였습니다.
해당 논문의 주된 발견은 다음과 같습니다.
- Word2Vec skip-gram model에서 output embedding은 input embedding보다 미세하게 성능이 좋지 않았습니다.
- Recurrent neural network based language model에서 output embedding은 input embedding보다 성능이 좋았습니다.
- U=V를 강제하여 두 embedding을 tying했을 때 joint embedding은 개별 input embeddding, output embedding 중 output embedding과 유사하게 학습이 되었습니다.
- Input embedding과 output embedding을 tying했을 때 다양한 language model에서 성능 향상이 있었습니다.
- Dropout을 사용하지 않을 때, V 이전에 적용하는 추가적인 projection P를 통해 P에 regularization을 적용합니다.
- Neural translation model에서 weight tying을 통해 size를 기존에 비해 절반 가량 줄이면서 성능 저하는 피할 수 있었습니다.
2. Related Work
Neural network language model(NNLMs)은 word sequences의 확률 값을 구해줍니다.
Word2Vec skip-gram model은 vocabulary의 각 단어들의 input embedding과 output embedding representation을 학습합니다. 학습이 다 끝나면 input embedding을 통해 얻은 vector를 사용합니다. Output embedding은 일반적으로 무시됩니다. 최근 연구에서는 word2vec skip-gram model의 output embedding은 input embedding과 다르게 접근해야 한다고 주장하기도 했습니다.
해당 논문에서는 input과 output embedding을 tying했을 때 word2vec의 성능을 떨어뜨리는 것을 보였습니다. 하지만 tying을 했을 때 neural network language model의 성능은 향상시켰습니다.
Neural machine translation(NMT)에서 decoder는 input sentence의 번역을 만들어주는데 이는 output sentence와 source sentence가 주어졌을 때의 조건부 language model이라고 볼 수 있습니다. Neural machine translation의 SOTA는 source와 target word를 subword unit으로 BPE 알고리즘 등을 통해 나누었을 때 달성할 수 있었습니다.
3. Weight Tying
해당 논문에서는 NNLMs, word2vec skip-gram, NMT 3개의 분야를 집중적으로 다룹니다. 3 모델 모두에서 weight tying은 유사한 방식으로 이루어집니다.
NNLM model은 input matrix, 2개의 LSTM layer(h_1, h_2), 3번째 hidden score/logits layer h_3와 softmax layer로 이루어져 있습니다. 학습 시 사용되는 loss는 cross entropy loss이며 regularization term은 따로 없습니다.
Large model에서는 regularization으로 dropout을 활용하고, small model에서는 regularization을 수행하지 않습니다. H x H 차원의 projection matrix P는 output embedding 직전에 추가됩니다. 결과적으로 h_3 = VPh_2가 됩니다. Small model의 loss 함수에는 regularizing term lambda * ||P||_2가 추가됩니다.
Projection regularization은 동일한 embedding을 활용할 수 있도록 해줍니다.
Vanilla untied NNLM을 학습할 때 timestep t에서 current input word sequecnce i_1:t = [i_1 ~ i_t] 와 current target output word o_t를 통해서 negative log likelihood loss는 아래 식과 같이 구할 수 있습니다.

간단히 하기 위하여 timestep t에서 i_t != o_t 라고 가정합니다. SGD를 사용하여 model의 최적화가 수행되며 아래 식들과 같이 gradient를 구할 수 있습니다.

Untied model에서 매 timestep마다 input embedding에서 update되는 row는 유일하게 current input word입니다. 이는 곧, 자주 등장하지 않는 단어라면 update가 자주 일어나지 않는다는 것을 의미합니다. 하지만 output embedding은 매 timestep마다 모든 row에서 update가 수행됩니다.
Tied NNLMs 에서 U = V = S로 둡니다. S의 각 row에서 update를 input embedding, output embedding 두 역할을 수행하는 S의 update들의 합으로 얻을 수 있습니다.
k != i_t인 row에 대해서는 k row에서 수행되는 update는 untied NNLMs의 output embedding에서 수행되는 embedding과 동일합니다.(Input embedding에서는 k != i_t일 때 update 값이 0이기 때문)
k = i_t인 k row에서 일어나는 update는 input embedding과 i_t != o_t라는 가정에 의해서 output embedding의 k != o_t case update로 구성됩니다. Output embedding의 update는 word sequence에서 동일한 단어는 2번 이상 거의 등장하지 않기 때문에 p(i_t|i_1:t)이 거의 0의 값을 갖게 되어 update 값 역시 0에 가까워집니다. 그렇기 때문에 이 case에서는 update가 input embedding의 영향을 주로 받게 됩니다.
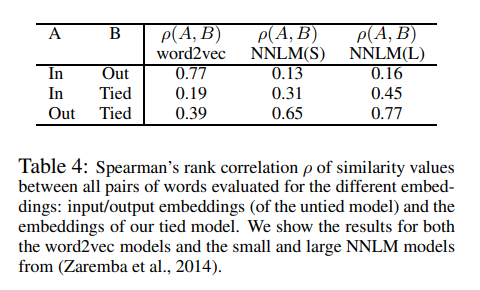
결과적으로 tied NNLM에서 S의 모든 row는 매 timestep마다 update가 이루어지고 하나의 row (k = i_t)를 제외하고서는 update가 untied model의 output embedding의 update와 유사합니다. 이는 tied embedding이 untied model의 output embedding이 input embedding보다 유사하다는 것을 의미합니다.
Word2Vec에서 역시 유사하게 update가 이루어집니다. 단지 (h_2)^(t)가 identity function으로 바뀐다는 것이 차이점입니다. 이 때 weight tying은 적절하지 않게 되는데 이는 p_t(i_t|i_1:t)값이 0에 근사해지면 i_t의 embedding norm이 0에 근사되기 때문입니다. NNLMs에서는 LSTM layer가 input과 output embedding을 따로 떨어뜨려 이런 현상이 일어나지 않습니다.
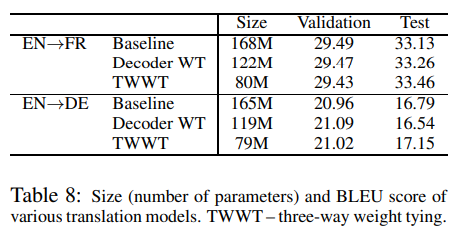
마지막으로 NTM에서 weight tying의 효과를 평가합니다.


해당 논문의 weight tied transaltion model에서는 decoder의 input embedding과 output embedding을 tying 해줍니다.
해당 논문에서는 TWWT(Three way weight tying)을 제안합니다. TWWT는 decoder의 input embedding, deocder의 output embedding, encoder의 input embedding 3개를 tying하는 방식입니다.
4. Results
4.1 Quality of Obtained Embeddings
4.2 Nueral Network Language Models
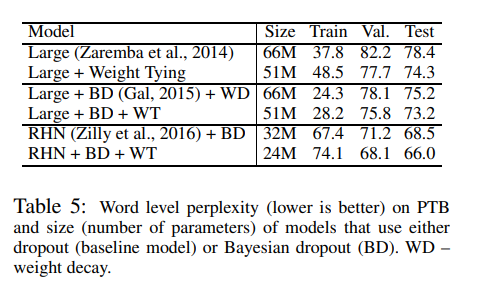
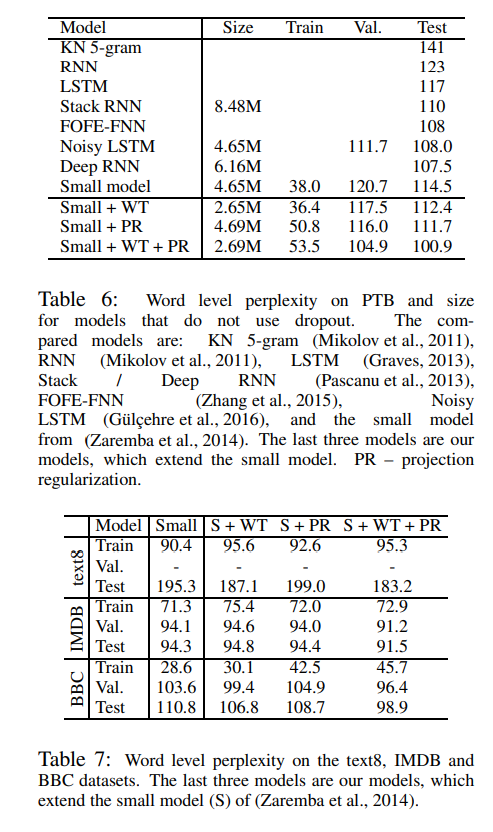
4.3 Neural Machine Translation