Pre-trained model 가장 윗 단에 쉽게 cache 역할을 추가할 수 있는 Neural Cache Model을 소개하는 논문입니다.
[Abstract]
해당 논문에서는 예측에 최근 정보를 활용할 수 있는 extension neural network language model을 소개합니다. 해당 모델은 hidden activation을 memory로 저장하고 current hidden activation과의 dot product로 접근하여 사용할 수 있도록해주는 memory augmented network의 단순화된 버전입니다.이는 매우 효율적이고 large memory size까지 크기를 늘릴 수 있습니다. 해당 논문은 또한 neural network에서 external memory를 사용하는 것과 count based language model에 사용하는 cache model 사이의 연관성을 도출했습니다.
1. Introduction
Language modeling은 NLP의 주된 task입니다. 전통적인 neural network language model은 SOTA성능을 보여왔지만 최근 history를 사용하지 못했기 때문에 dynamic environments에 적용하기에는 한계가 있었습니다. 이를 해결하기 위해 network에 external memory를 추가해주었습니다. External memory를 추가한 model은 external memory에 새로운 정보를 저장하고 환경 변화에 잘 적응할 수 있게되었습니다.
하지만 계산 비용이 너무 많이 든다는 단점이 있었습니다. 일반적으로 memory cell을 읽고 쓰는 과정에서 parametrizable mechanism을 학습해야만 했습니다. 그로인해 사용 가능한 memory size와 학습에 사용하는 data의 양을 제한할 수 밖에 없었습니다. 해당 논문에서는 가벼우면서 동시에 memory augmented network의 특징을 갖고 있어 dynamically한 변화에 대응할 수 있는 모델을 소개합니다. Memory의 연산을 최소화함으로써 해당 논문에서는 large memory와 많은 dataset을 활용할 수 있게되었습니다.
논문에서 소개하는 모델은 cache model으로 불리는 모델과 유사한 점을 지니고 있습니다. Cache model은 unigram의 형태인 최근 정보를 간단한 representation으로 저장하고 있으며 이를 예측에 활용합니다. 이런 contextual information은 저장하고 접근하는데 큰 비용이 들지 않습니다. 또한 학습이 필요하지 않고 어떠한 모델에도 적용할 수 있습니다.
해당 논문의 주된 기여는 Neural Cache Model이라는 cache model의 continuous version을 제안했다는 것입니다. Neural Cache Model은 어떠한 neural network language model에서도 사용할 수 있습니다. 해당 논문에서는 recent hidden activation을 저장하고 이를 context의 representation으로써 활용합니다. Current hidden activation과 dot-product 연산만을 통해서 예측에 중요한 정보를 전달하는 역할을 할 수도 있습니다.Neural Cache Model은 학습이 필요 없으며 어떠한 pre-trained neural network에서나 사용할 수 있습니다.
2. Language Modeling
Language modeling은 단어 sequence의 확률분포입니다.
- V : vocabularay의 크기
- x : word embedding vector, V차원
Chain rule에 의해 x_1 ~ x_T의 word sequence의 확률은 아래 식을 통해 구할 수 있습니다.

Language modeling은 과거 단어들이 주어졌을 때 현재 단어가 등장할 조건부 확률을 학습하는 task로 볼 수 있습니다.
이 조건부 확률값은 전통적으로 counting statistic 기반의 non-parametric model에 의해 근사되었었습니다. 대표적으로 smooothed N-gram model이 좋은 성능을 보였습니다. Parametric model에는 maximum entropy language model, feedforward network, recurrent network 등이 있습니다. 특히 recurrent network는 앞서 언급한 조건부 확률값을 가장 잘 근사할 수 있는 방법으로 알려져 있습니다.
Recurrent networks
h_t는 과거 정보 x_t ~ x_1을 encoding한 d차원 vector이고 이 때 단어 w의 조건부 확률은 아래 식과 같이 계산될 수 있습니다.

History vector h_t는 아래 식과 같은 형태의 계산을 recursive하게 적용하여 얻어질 수 있습니다.

Recurrent network에는 Elman network, LSTM, GRU 등이 있습니다. 가장 단순한 recurrent network인 Elman network는 아래 식과 같이 표현할 수 있습니다.
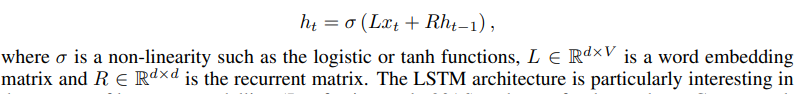
Recurrent neural network language model의 parameter들은 학습 data의 negative log-likelihood를 최소화하면서 학습할 수 있습니다. Objective function은 주로 SGD나 Adagrad 등의 방식을 통해 최소화됩니다. Gradient는 truncated backpropagated through time 알고리즘에 의해 계산됩니다.
Cache model
문서에서 일단 단어가 한 번 등장하게 되면, 또 다시 등장하는 경향이 있습니다. Cache model은 이런 단순한 성질을 활용하여 문서의 long-range dependency를 포착하여 n-gram language model을 발전시켰습니다. 좀 더 자세히는, 문서나 혹은 고정된 수의 단어들 안에서 등장한 단어를 포함하는 cache component를 model에 갖고 있습니다. Unigram이나 smoothed bigram model과 같은 simple language model은 cache의 단어들에 fit되고 기존 많은 양의 dataset으로 학습된 static language model과 interpolate됩니다. 이러한 방식은 몇 가지 이점을 지닙니다. 첫째, 새로운 domain에 language model을 효율적으로 적용할 수 있습니다. 둘째, 한 번 단어를 마주하면 OOV word들을 예측할 수 있습니다. 마지막으로 문서의 long-range dependency를 잡아낼 수 있습니다.
3. Neural Cache Model
Neural Cache Model은 neural network language model에 cache-like memory를 추가한 것입니다. 이 모델은 hidden representation h_t를 cache에 있는 단어들의 probability distribution을 정의하기위해 사용합니다.
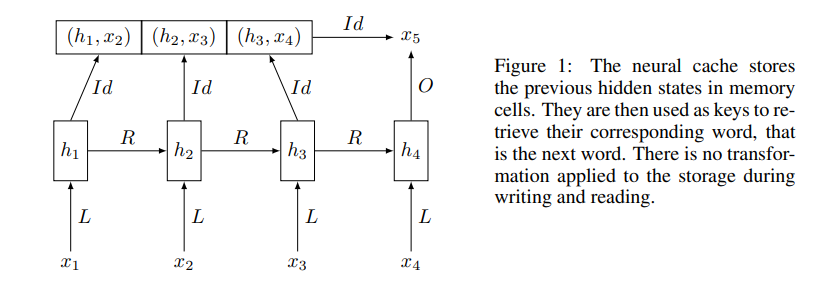
위 그림에서 볼 수 있듯, cache는 hidden representation와 이를 통해 만들어지는 단어인 (hi, x(i+1)) 쌍을 저장하고 있습니다. Time t에서 cache에 저장되어 있는 단어의 probability distribution을 저장되어 있는 hidden representation과 current hidden representation h_t를 통해서 아래 식과 같이 정의할 수 있습니다.

Memory-augmented neural network의 관점으로는 Neural Cache Model에 의해 주어지는 확률 pcache(w|h(1~t), x(1~t))는 query h_t가 주어졌을 때 memory로부터 단어 w를 찾는 확률로 해석할 수 있습니다. 이 때 w의 실제 답은 x(t+1)이 됩니다. 이전 hidden states를 keys로 사용한다면 memory lookup operator는 key와 query 사이의 dot product를 수행할 수 있습니다. 기존의 memory augmented neural network와 달리 Neural Cache Model은 memory lookup operator를 학습할 필요가 없습니다. 이런 cache는 pre-trained recurrent neural language model에 따로 fine-tuning 과정 없이 추가될 수 있으며 large size cache 역시 예측 시 계산 비용에 큰 영향을 미치지 않은 채 사용할 수 있습니다.
Neural cache language model
N-gram cache-based language model의 기본 예시에 따르면 단어의 최종 확률은 아래 식과 같이 cache language model과 regular language model의 liner interpolation으로 구할 수 있습니다.

Recurrent neural language model에 neural cache를 추가하는 것은 일반적인 cache-based model의 n-gram cache의 장점을 그대로 갖고 있습니다. 단어의 probability distribution은 문맥에 따라 update되고 OOV word는 recent history에서 한 번이라도 보게 된다면 예측할 수 있습니다. Neural cache는 또한 longer-term context를 modling한 recurrent neural network의 hidden state의 장점 역시 물려 받습니다.
Training procedure
먼저 recurrent neural network language model을 cache component 없이 학습을 합니다. Cache model은 test일 때만 적용하고 validation set에서 hyperparameter를 결정합니다. 논문의 모델의 큰 강점은 기존에 학습된 neural model에 쉽고 간편하게 적용할 수 있다는 점입니다.
4. Related Work
Cache Model
Adaptive Language models
Memory augmented Neural Networks
5. Experiments
모든 dataset에서 stsatic recurrent neural network language model을 LSTM unit을 사용하여 학습했습니다.
5.1 Small Scale Experiments


5.2 Medium Scale Experiments

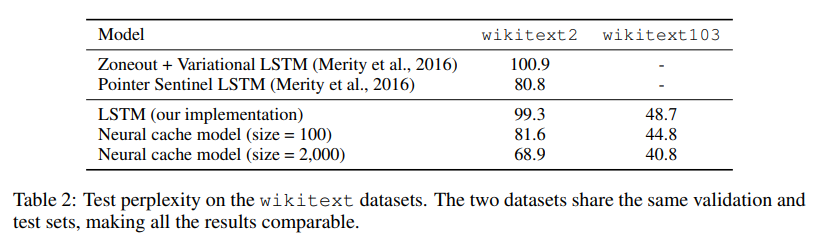
5.3 Experiments on the Lambada dataset
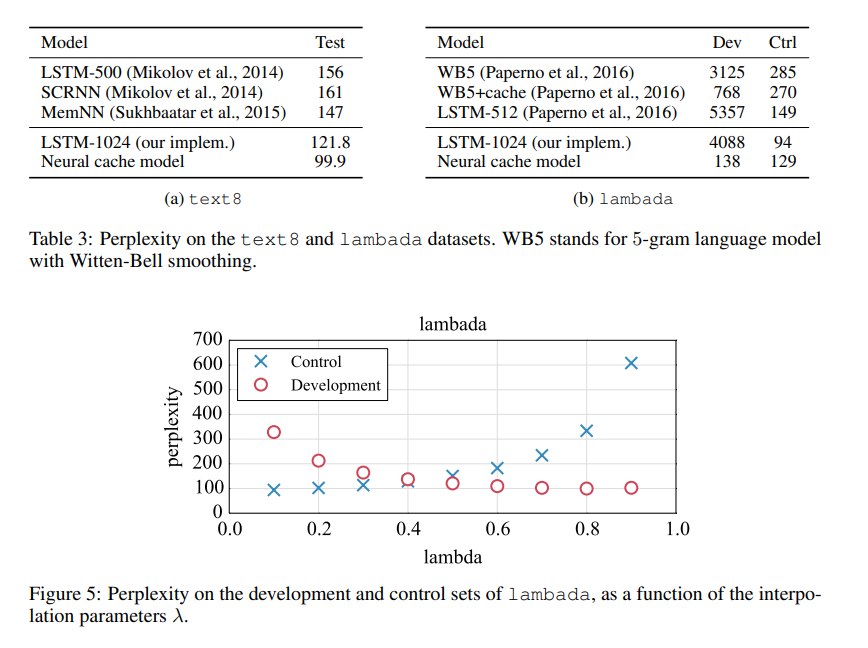
6. Conclusion
해당 논문에서는 neural language model을 long-term context를 기반으로 word probability를 dynamical하게 update하는 longer-term-memory를 갖도록 확장한 Neural Cache Model을 소개하였습니다. Neural Cache Model은 큰 비용없이 pre-trained language model 가장 윗단에 추가할 수 있습니다. 가장 큰 장점은 memory lookup component를 학습할 필요가 없다는 것입니다. 이를 통해 더욱 큰 cache size를 사용할 수 있고 전통적인 count-based cache에 쉽게 적용할 수 있습니다.
